9.3: Paging
In the previous part, we have discussed both the benefits and problems with segmentation. One of the main issues was the fact that the segments could be of different sizes, making it difficult to find memory gaps of an appropriate size and adding overhead when doing so.
As such, the actual method used most commonly in practice is segmentation with all the segments being of the same size. This means that not only the segments, but also the gaps they leave, are always the same, predictable size. As such, any empty gap is immediately a good candidate for when a new segment is created, without having to actively look for a gap that is large enough (but not too large as to prevent external segmentation).
In practice, this approach is called paging, as each same-sized segment is called a page. In other sources, you might also find the term “frame”, as each logical page is mapped to a physical memory block of the same size, called a frame.
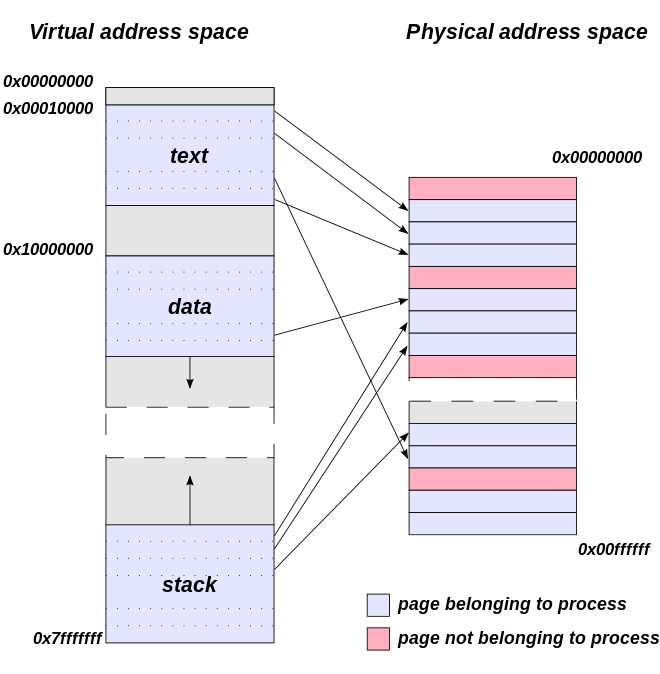
The pieces of memory with (logical) segmentation (left) and paging (right). Source: Wikipedia
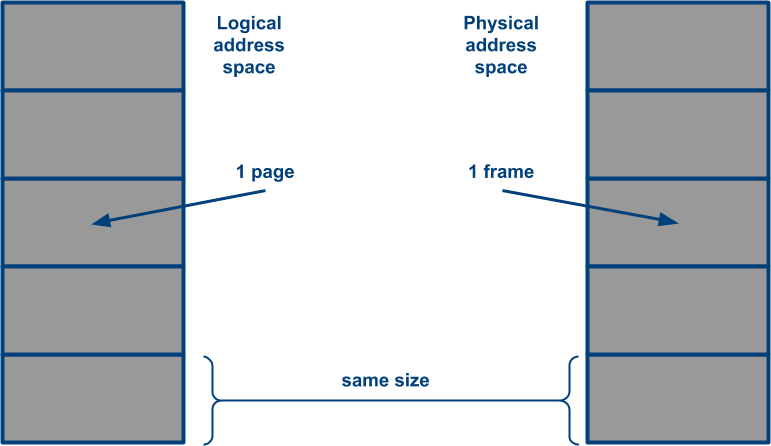
Each page has an equally sized frame in physical memory
Address binding
Paging of course retains most of the benefits of segmentation: it’s easy to perform address binding/memory mapping at execution time, making it highly flexible.
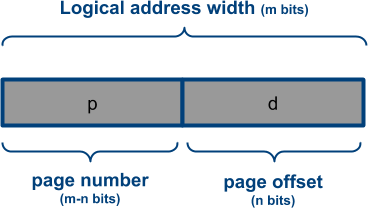
The way that logical addresses are transformed into physical addresses are also similar: the address' first part indicates the page number (p) (similar to the segment number from before) and the second pard is the page offset (d), that again indicates where exactly the address is in a given page. Instead of a segment table, we now have a page table that keeps track of where the pages actually start in memory.
Paged addresses
However, this is where things start to diverge between the two approaches, as the page table no longer needs to store the size of each page (the “limit”), as it’s always the same. However, the chosen page size still (implicitly) impacts how exactly the (p) and (d) parts of the single address are assigned. This is because the (p) part needs enough bits to identify each page individually, and the bits needed depends on the page size and the total amount of memory.
Put differently, if the size of the logical address space is defined as 2m, and a page size as 2n bytes, then the m-n left-most bits of the logical address define the page number (p), and the n remaining bits form the page offset (d).
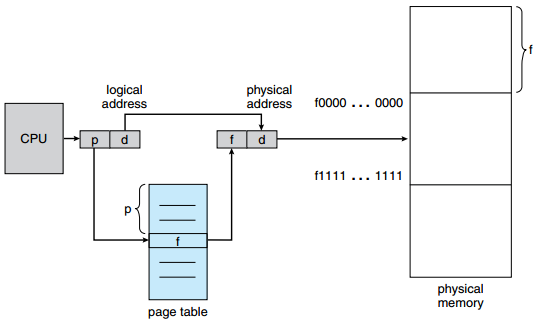
Paging hardware
<style>
p.dinobook { color: #7E7E7E; font-size: 14px; font-weight: 300; letter-spacing: -1px; padding-top: 0px; margin-top: -20px; text-align: center; }
source: SILBERSCHATZ, A., GALVIN, P.B., and GAGNE, G. Operating System Concepts. 9th ed. Hoboken: Wiley, 2013.
To make this more concrete, consider an example. In a hypothetical 4-bit system (each address is 4 bits long) the processor can address 24 different addresses. This gives us a maximum of 16 bytes of physical memory (physical addresses from 0x0 to 0xF). Say we choose a page size of 2 bytes. With the definitions as declared above, this comes down to:
- m = 4
- n = 1
- amount of pages = 16 / 2 = 8 pages (starting at physical addresses 0x0, 0x2, 0x4, 0x6, 0x8, 0xA, 0xC, 0xE)
- amount of bits needed to store page numbers (p): m - n = 3 (indeed, 23 is 8)
- amount of bits needed to indicate offset in page (d): n = 1 (indeed, 1 bit gives us two options: 0 and 1, enough to differentiate between the 2 bytes in each page)
- So, the first 3 bits of a logical address indicate (p), the last 1 (d)
Now let’s imagine that the (first half of the) page table would look like this: [5, 6, 1, 3]. This means that the page with nr/index 0 (first in the table) maps to physical “frame” 5. Frames are the same size as pages, so the page’s physical base address if frame 5 is: 5 x page size = 5 x 2 = 10 = 0xA.
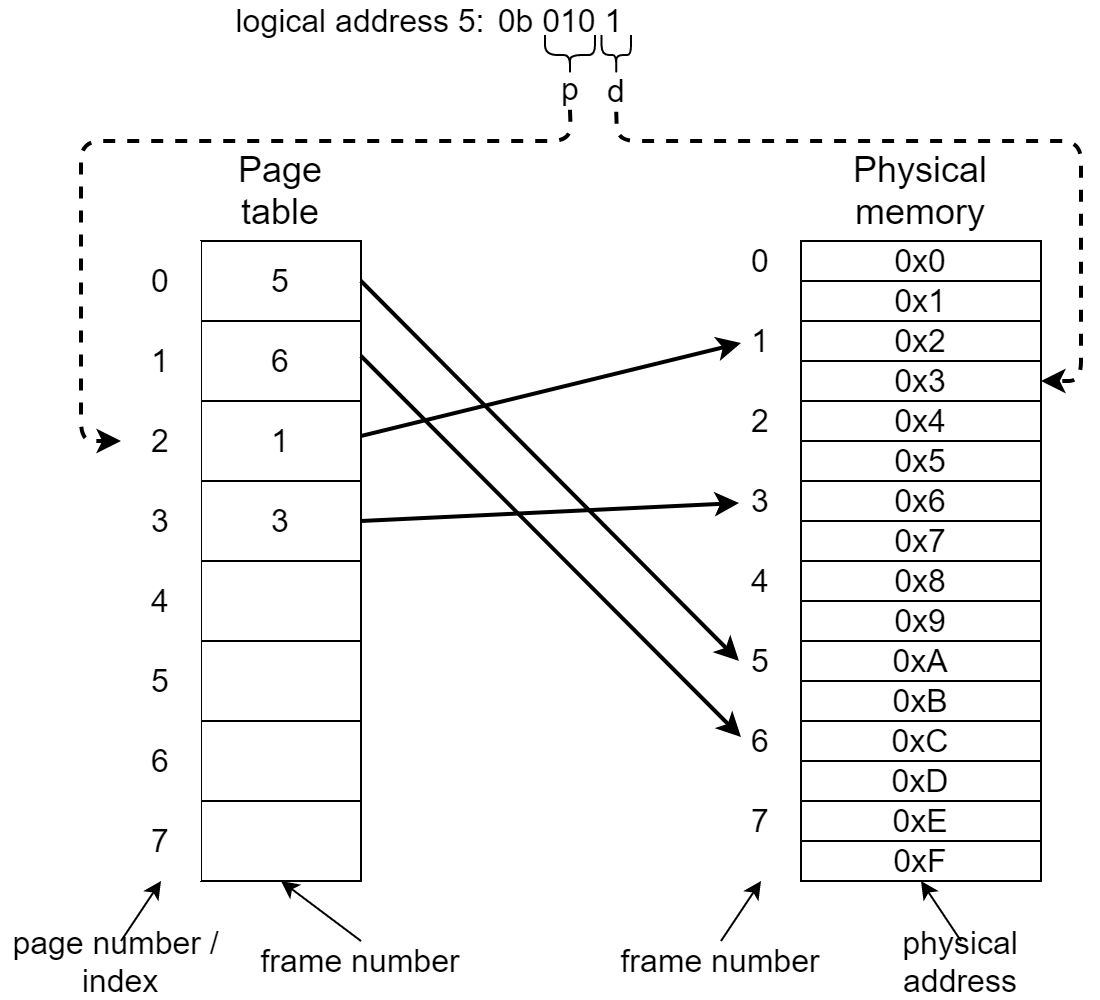
The page table maps page numbers to frame numbers, which in turn represent base-addresses of physical memory blocks.
Now let’s convert some logical addresses. The simplest one is logical address 0, which we can write with 4 bits as 0b0000. The first 3 bits (0b000) are the page table index (p), which is 0. As said above, this maps to frame 5, and the page’s base address 0xA. Now we need to add the offset (d), the last bit, which is 0, so the phyiscal byte we address is simply 0xA (0b1010).
Similarly, if we were to look up logical address 1, we get 0b0001. We see this only changes the offset (d) within frame 5, so we get phyiscal address 0xB (0b1011).
A bit more complex, consider logical address 5 (0b0101). The first 3 bits give 0b010 = page number 2. Page number/index 2 maps to physical frame 1 in the page table, which is physical address 0x2 (frame nr x page size = 1 x 2). The final bit indicates the offset, which is 1. So we need to do 0x2 (base) + 0x1 (offset) = physical address 0x3. We can see that logical address 5, which is higher than logical address 1, is stored “lower” in physical memory!
Given the hypothetical system as described above, what would be the corresponding physical addresses for the logical addresses 6, 3 and 15?
Logical address 6 = 0b0110 (page 3, offset 0) maps to frame 3 at physical address 0x6 [= (3 × 2) + 0]. By coincidence, the logical address is the same as the physical address!
Logical address 3 = 0b0011 (page 1, offset 1) maps to frame 6 at physical address 0xD [= (6 × 2) + 1]
Logical address 15 = 0b1111 (page 7, offset 1) doesn't map to a physical address, because page 7 is not yet mapped! We'll later see that this is a variation of what is called a "page fault". Can you already think of how/why this might happen and how to solve this problem?
Page table size
However, choosing this singular page size in an optimal way is not simple. As we will discuss below, we cannot simply choose too large a page size (say 10MB per page), since that might lead to leftover memory (called internal fragmentation). However, we also cannot choose a very small page size (say 1KB), since then we would need to keep a large amount of page numbers in our page table!
To understand this second aspect a bit better, let’s assume a single segment of 5MB. If this is stored in pages of 1KB each, we would need 5000 indidivual pages to represent this segment. While the segment table can just contain a single entry (segment number 0 starting at address 0x1111, with size of 5MB), the page table needs to contain 5000 entries (page number 0 at 0x1111, page number 1 at 0x1511, page number 2 at 0x1911, etc.). While looking up the page addressess will be fast in the page table, it will take up a lot of memory!
Lookup the default Linux page size (in bytes) by using the getconf PAGESIZE (or PAGE_SIZE) command
Let’s calculate how much memory we would need in a practical scenario: take a 32-bit processor that can address 232 different locations. Let’s also assume a a page size of 4kB (=212, = 4096 bytes).
In this more realistich scenario, calculate how many bits we need for the page number (p) and offset (d) in our logical addresses.
m = 32, n = 12. As such, we need 32-12 = 20 bits for the page number, and 12 for the offset.
-
The amount of pages is then: 232 / 212 = 232 - 12 = 220 entries (1048576 individual pages)
-
Since the page table maps page numbers to physical addresses, and physical addresses are 32-bits on this system, each page entry needs to be 32 bits in size (= 4 bytes, = 22).
- Note that in practice, this is a bit more complicated, as we’ve seen before that the page table stores frame numbers, not full 32-bit addresses. However, in practice, each page also stores a few additional status bits (see below), and the page table entries are rounded up to a power of 2, so we still get 4 bytes for each page entry.
-
As such, the total page table size = entries * size per entry = 220 * 22 = 222 bytes = 212 kB = 22 MB = 4 MB
Now, 4MB might not seem like a lot. However, consider that the page table is needed for each memory access! As such, you need to store it very close to the CPU executing instructions to keep the lookup latency overhead low. We cannot simply store it in RAM, since that is conceptually quite far from the CPU (remember that the speed decreases considerably from registers -> cache memory -> RAM -> disk). Typical register memory is at the order of a few (hundreds of)bytes, while cache memory is typically less than 8MB (and it needs to store much more than just the page table!). Also consider that for modern 64-bit setups, things are much, much worse. This requires 254 = 18.014.398.509.481.984 bytes, which can’t even fit on modern hard drives!
There are several options for dealing with this problem. Firstly, we can choose larger page sizes (say 2MB or even 1GB) to reduce the amount of entries needed. However, as we’ll see below, this is a trade-off with internal fragmentation. Secondly, we can use a multi-layered/hierarchical page-table, so that we don’t need to keep the full page table in memory all the time (as it’s unlikely all those 64-bit addresses are actually used!). However, this increases lookup time (as each layer needs to be traversed). Thirdly, we can have each process track its own page table individually and swap the page tables in/out when a process is scheduled/context switched. This means we only need memory for the pages that are actually used, but this increases context switch overhead.
In practice, all of these techniques are combined in clever ways on modern OSes to get the best of each. Full details of how this works would take us too far, but let’s consider one common approach.
Hierarchical page tables

A two-level page-table scheme
source: SILBERSCHATZ, A., GALVIN, P.B., and GAGNE, G. Operating System Concepts. 9th ed. Hoboken: Wiley, 2013.
One way to overcome large page tables is to use a two-level paging algorithm. This technique uses paging for page tables. The page number in the example above is 20 bits. Using the same technique again, the page number gets split into two 10-bit addresses.

With this setting, p1 is the index into the outer page. Similarly, p2 is the index into the inner page. When the physical address is to be searched from a logical address, first the outer table needs to be examined using p1. With the inner table index found, the base address can be searched for in the inner table using p2. Finally the page offset is added to the base address to end up with the mapped physical address.
The translation from logical to physical address happens from the outer table, inward. Therefore this scheme is known as a forward-mapped page table. The are also "inverted" and "hashed" approaches that do things differently.
In practice, this approach can be repeated at will, adding more and more lookup tables in between. For example, for a typical 64-bit system, a hierarchy of 4 page tables is used with page sizes of 4KB, where each page number pN is stored in 9 bits. This approach is chosen so that each page table nicely subdivides into 4KB pages itself, which allows them to be “swapped” as well (see below).
This approach can then be combined with per-process page tables and make them hierarchical as well (which is useful for processes that use a large amount of memory, such as for example databases).
These approaches can then also be implemented in the hardware MMU, which can for example keep a few per-process page tables in its local memory at a time, replacing them with others as new process are scheduled.
Modern hardware typically supports a number of different page sizes (typically 4KB, 2MB and 1GB) that allow some level of tweaking if the programmer knows the expected memory usage up front.
Internal fragmentation
As mentioned several times above, next to the large page table size, another problem with paging is internal fragmentation. Before, we’ve discussed external fragmentation (with segmentation), which means that memory -outside- of the processes gets fragmented. With paging however, the memory -assigned to the processes- can get fragmented as well. Consider for example the case where we have pages of 4KB each, but we now need to allocate space for an array of 5KB. We can’t allocate memory smaller than a page, so we need to reserve at least 2 pages of 4KB, wasting 3KB. In theory, this 3KB can be filled with other data of the same process, but that requires the memory allocator to keep track of such things (which doesn’t always happen for various reasons).
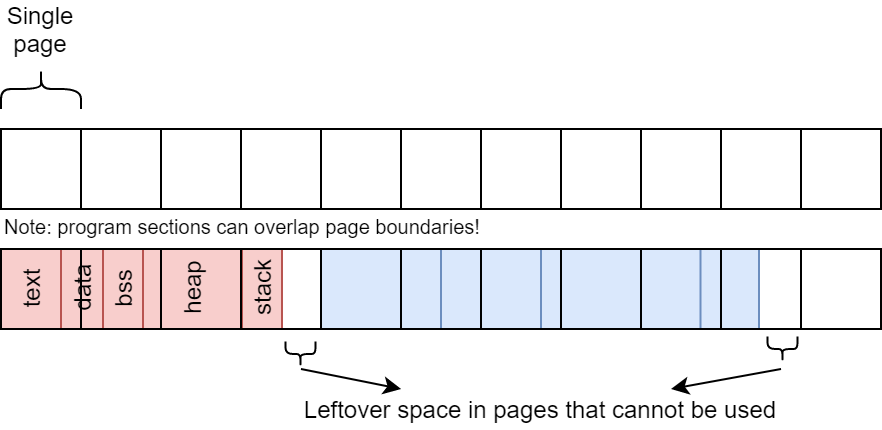
Each process can have some leftover memory, leading to internal fragmentation.
It should be obvious that, the larger the page size, the more risk of internal fragmentation occurs. Again: this is why we don’t just use 1GB pages for each process.
Added benefits of paging
As we’ve seen above, paging is a very flexible setup, but it requires quite a bit of work to tune/optimize for practical use. Once we’ve done that however, we get plenty of additional benefits from this approach. Let’s look at a few.
(Side note: we will now discuss some of the extra “status bits” that are kept for each page table entry, which as we’ve seen above (search “status bits”), force the page table to store more bits than required by the frame number alone, causing the page table size to increase).
Allocating more memory than is physically available
As you can imagine, no machine today has enough physical (RAM) memory to allow the use of the entire 64-bit address space at once. In reality, you typically “only” have 8 - 32 GB of RAM in your home PC, while large servers have 512 GB to 2 TB of RAM nowadays.
However, you can also easily imagine processes using up more than the available amount of memory, especially on your PC (have you ever run Google Chrome? Photoshop?). In that case, you wouldn’t be able to start new processes any more, until you’ve manually closed some others, even if you have a lot of processes that are idle/running in the background.
To prevent this from happening, modern OSes will use the harddisk storage as a semi-transparent extension to the RAM memory. If the main memory is full, pages that are not currently being used, can be stored on the hard disk for a while, making room for new pages in the RAM. If those stored pages are later again needed, the OS can again move other in-memory pages to disk, to make room to restore the previously “hibernated” pages. This process of storing pages to disk and restoring them to main memory at a later time is called swapping.
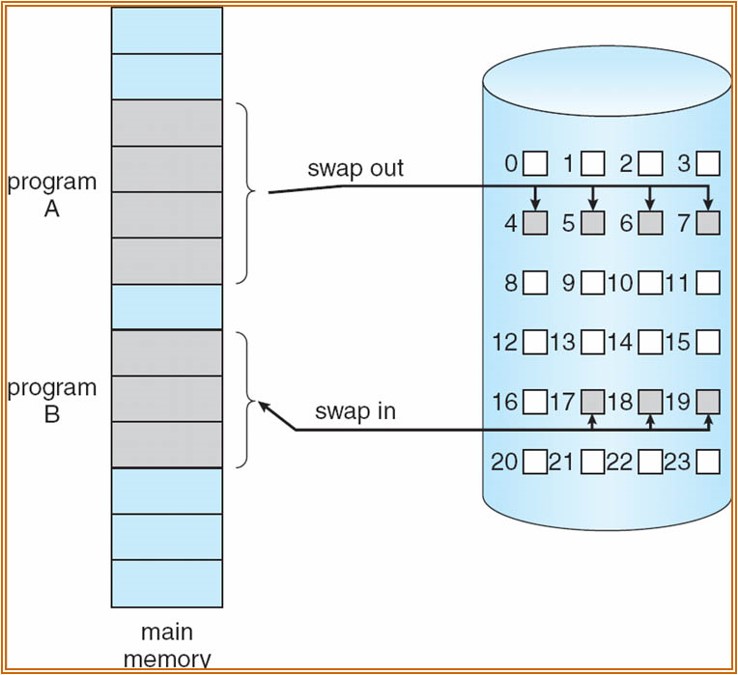
Pages can be swapped in/out to the harddisk to reduce main memory occupancy
source: SILBERSCHATZ, A., GALVIN, P.B., and GAGNE, G. Operating System Concepts. 9th ed. Hoboken: Wiley, 2013.
In practice, this all happens transparently for the programmer. For each page in the per-process page table, the OS tracks whether this page is currently in the main memory or not. This is done using a so-called valid/invalid bit. If the program attempts to access a page with the invalid bit set, the OS generates a page fault. Other than with a segmentation fault, the OS will not actually regard this as an error. Instead, a new page location (free gap in main memory) is found and the contents of the page are again read from disk into that space. If there are no free pages in main memory, old pages are first swapped out to disk for both.
Something very similar happens if we try to access a page that has never actually been allocated before (say with a new malloc()). In this case, the OS will look for a new page in main memory and allow the program to start using it (this is what we saw above when trying to use logical address 15, which was not mapped in the page table yet). It is even possible to take this one step further, and to not actually allocate memory for a given page until it is actually used/written to. For example, if you allocate 2GB of memory with malloc() (which you can certainly do), the OS won’t actually start reserving that much space in the memory. It will just add the necessary placeholders in the page table until you actually start writing to this 2GB of memory. Something similar happens if you start allocating lots of smaller blocks: you’re only storing the pointers to those blocks; the actual block memory is only converted to pages when data is written to them (this is why in some exercises in the previous chapter you can use a “logical” amount of memory of many hundreds of gigabytes before you actually run out of “real” memory). This approach can also be used to reduce the amount of code each process needs to load. In most programs, large parts of the code are never actually executed in normal executions of the program. As such, the OS can decide not to load pages in the text/code segment of the process until it actually needs to execute them, an approach called load-on-use.
As such, we can see that this allows us to, in theory, extend the size of the physical RAM to encompass our entire hard disk as well (e.g., going from 16GB of RAM to 2TB “extended” RAM). In practice, modern OSes reserve a fixed amount of hard disk space for swapping purposes (linux typically has a separate swap partition, while windows typically has a large file of 1x or 2x the RAM size it uses for swap space). It’s only when this extra space also runs out, that the OS will have to start shutting down processes to make room for more. This is something you still see today in mobile OSes such as Android and iOS, which occasionally will auto-close (long-idle or heavy) apps to make room for new ones.
However, there are of course also downsides to this approach. Hard disk memory (even if you’re using an SSD drive) is still much slower than using RAM directly. As such, every time a page needs to be swapped, this adds additional overhead, as memory needs to be copied to the RAM first before use. The OS tries to hide this overhead by scheduling other instructions while it’s waiting (up to even scheduling another process while waiting), and especially by being clever about which pages it keeps in memory and which it switches out. This can again be done with a variety of algorithms with descriptive names such as Least-Recently-Used (LRU), Not-Frequently-Used (NFU), First-In-First-Out (FIFO), Second Chance, etc. A final approach is by tracking whether a page that was previously stored to disk (and is currently still on disk), has actually been changed in main memory (this is done by using a modified bit (or “dirty” bit)). If the modified bit is not set for a page in main memory, we can simply overwrite it without first serializing it to disk, as we know the version already-on-disk is the same as the one in main memory, and we don’t loose any state by overwriting it. In general, the OS prevents the use of swapping as much as possible.
Optimized data sharing
Another common optimization is to allow multiple processes and threads to share individual pages amongst themselves. For example, we have seen that when fork()‘ing processes, they each get a new copy of the PCB and all the program segments. This is conceptually true, but in practice this would of course be quite wasteful, as the child will probably never change the text/data/bss segments and will probably keep re-using much of the same heap and stack data as the parent (at least in the beginning).
Instead, when fork()‘ing a new process or starting a new thread, the new task typically still just points to the old pages. This only changes when the new task tries to write to one of the shared pages: at this point, the copy-on-write approach is used, and the to-be-changed page is copied for the new task before it is changed. This is conceptually similar to the allocate-on-write approach discussed in the previous subsection.
Something similar happens for the previously mentioned (dynamically) loaded libraries, where code can be shared between many processes. In this case, the libraries’ pages can be marked with a special read-only bit, to make sure that processes don’t overwrite the library internals and mess up other processes that way.
Memory-Mapped I/O
As discussed before, no modern system actually has enough RAM/harddiks memory to back the full 64-bit address space, meaning that we always have quite a few addresses leftover, even under full load. Additionally, the concept of swapping has shown that we can view memory addresses as proxies to access -other- hardware (in that case, the harddisk) in an indirect way.
If we take this concept further, we can imagine also addressing other hardware in the same way, by exposing them as logical memory addresses that are mapped internally by the OS to something else than the RAM. This is generally called memory-mapped I/O and it is a very common technique.
For example, in Chapter 2, we’ve mentioned that Arduino CPU registers are accessible from C code in this way: they are assigned a logical address, which the OS maps not to the RAM/harddisk, but to the CPU registers for setting/reading them. Similarly, modern GPUs typically also have a large amount of “VRAM” (Video RAM), specifically for storing (graphical) data. Instead of addressing this VRAM in a completely separate way, the OS instead maps it to its own logical address space (pretending as if it’s “normal RAM”) which can be read/written using standard methods. Other examples include serial peripheral devices (for example mouse/keyboard/older modems/many sensor systems/…) that can be accessed by pretending their output can just be read from a memory region. Finally of course, we can also do this for “normal” files on the harddisk (and not just swapped pages).
While powerful, this technique can sometimes be tricky to get right, as in some cases the memory access is not immediately propagated directly to the other hardware, but instead the RAM is still used as intermediate storage. For example, have you ever wondered why you should eject a USB stick ? It might happen that you have written data to the USB stick, by writing to its memory-mapped addresses, but the data has not reached its destination yet. This is because the data is first written to RAM, and then transferred over time (by the OS) to the actual hardware. In these cases, the earlier mentioned dirty bit again comes into play. This is not just something that happens with memory-mapped I/O though: any intermediate memory layer has these issues, and this frequently shows up with CPU cache memory as well.
Security
Finally, let’s discuss security a bit more. As we’ve seen at the start of this Chapter, one of the main reasons for keeping track of chunks/segments/pages is to provide memory protection: to prevent process A from accessing process B’s memory. This is for example needed to prevent A from stealing passwords or sensitive data stored in B’s memory during execution.
However, in the first lab, we’ve also seen that this protection is rarely enough, and that there are plenty of ways for hackers to still mess with your system, even if it’s just within a single process. Over time, OSes and compilers have added many advanced techniques to help deal with these issues.
One such technique is called Address Space Layout Randomization (ASLR). A common attack vector is for the hacker to “escape” the stack/heap (e.g., through an array overflow, as we’ve seen). With that, they then attempt to overwrite code/data for a known vulnerable function in the program that allows for example execution of new code. This requires the hacker to reliably know where exactly this vulnerable function is in the logical address space. While pages can be randomly distributed inside the physical memory, without ASLR the logical address space would always look the same (starts at 0x00, text ends at 0x?? every time, since it’s always the same length, so data segment starts at a predictable location as well etc.). As such, ASLR randomizes the logical base address of the program, as well as the logical starting locations of the other segments as well, to make it more difficult (though far from impossible) for hackers to guess where certain code/data is located between different runs of the same program.
Even with all this, it’s still possible for attackers to steal data, albeit via very complex methods. For example, the Spectre and Meltdown make use of several advanced features of modern CPUs, such as out-of-order execution, speculative execution, caching and, -indeed-, also virtual addressing and paging. The details are far too complex to discuss here (that’s more 2nd master level), but one of the key parts in the attack is that the OS and CPU actually does not check the segment/page boundaries immediately when an access occurs. To speed things up, CPUs will allow out-of-bounds accesses to occur and they will load privileged data into cache memory. It is only when this memory is then being used/read that the check occurs and it is prevented. However, the fact that the data is loaded into (cache) memory allows the hacker to use other methods (“side-channel attacks”/“timing attacks”) to decipher the contents of the cache, thus stealing the protected memory, across process boundaries and even from inside the kernel! Spectre and Meltdown have been very impactful, often requiring changes at the OS and even hardware level, lowering performance by up to 20% in some cases!

Meltdown and Spectre - Two attacks that got access to other process's memory.
Finally, even if hackers can just stay within a single process, things can still go terribly wrong. For example, in the cloudbleed attack, the large content distribution network Cloudflare suffered massive data leaks. This is because they used a single Web server process to serve requests/responses from many different clients. Using a simple buffer overflow, this allowed the attacker to read not just their intended response, but also the responses to request from other clients (which were located on the same heap), which often contained passwords, banking information, etc. This is because, within a single process as we’ve seen, memory checks are typically absent. Making matters much worse, this could be triggered by requesting a specially crafted HTML page, causing some search engines like Google to actually cache the leaked passwords in their search results! As such, fixing the bug at the Cloudflare servers was not enough: many search engine caches also had to be purged manually!
As such, it should be clear that memory access protection is a complex topic, going far beyond what we’ve discussed, and still an active area of research and development.