3.3 Functions and The Stack
In the previous part, we’ve discussed how we can use special branching and jumping instructions (like BEQ and JMP) to skip over certain parts of code to implement if-else logic. In the lab, we’ve seen how we can use the same building blocks to build while and for loops.
In this part we will discuss how we can use jumping to implement functions, and some extra challenges that come with that.
Function calls
Let’s consider a very simple example of one C function calling another on the left, and the known assembly on the right (using line numbers instead of hexadecimal addresses for simplicity from now on):
1. void f1() {
2. f2();
3. int C = 10;
4. }
5. void f2() {
6. int D = 20;
7. return;
8. }
1.
2. JMPi line6
3. ADDd 0 10 C
4.
5.
6. ADDd 0 20 D
7. JMPi line3
8.
For the coming examples, we’ll always assume f1() is called automatically at the start of the program.
Logically, we know what we want the f2() function call to do: if it’s encountered, we want to stop executing the current function f1, and start executing the other function f2 from its start (line 6). Only when the other function is done (indicated by the return statement), do we want to return to f1. However, we don’t want to start f1 all over again (on line 2), we want to continue right after the function call (line 3).
As we can see above on the right, we can quite easily do this with JMPi, having the f2 jump “back” to f1 once it’s done. However, you there’s a problem with this particular approach? Can you see what it is?
Imagine a third function f3() that also calls f2().
9. void f3() {
10. f2();
11. int E = 50;
12. }
9.
10. JMPi line6
11. ADDd 0 50 E
12.
As a programmer, you expect the same logic as above: f2 gets called, and after that the execution of f3 continues on line 11. However, this is not what happens! This is because above, we’ve hardcoded f2 to “return” to the hardcoded address “line3” (which is in f1). As such, we would never go back into f3 to execute line 11, but instead execute part of the unrelated f1. That’s of course not good!
We can see that, in order to allow f2 to be called from anywhere, the address it JMPs to when it’s done needs to be dynamic. As hinted in the previous part, we will use JMP instead of JMPi for that. Instead of a direct address value to jump to like JMPi, JMP will instead take an address which it needs to read to get the real address to jump to. As we’re working with functions and we want to know where to jump to after “returning” from a function, this address is typically called the return adress.
Let’s change the example above to incorporate this idea. We choose a single location in memory (at address 0x07) to store the return address for both f1 and f3.
1. void f1() {
2. f2();
3. int C = 10;
4. }
5. void f2() {
6. int D = 20;
7. return;
8. }
9. void f3() {
10. f2();
11. int E = 50;
12. }
1. ADDd 0 line3 0x07 // store return address line3
2. JMPi line6
3. ADDd 0 10 C
4.
5.
6. ADDd 0 20 D
7. JMP 0x07 // jump to whatever address is stored in 0x07
8.
9. ADDd 0 line11 0x07 // store return address line11
10. JMPi line6
11. ADDd 0 50 E
12.
As you can see, we can now indeed correctly return to either f1 or f3 from f2, depending on which return address values they store in 0x07 before calling f2!
However, this is still not ideal… can you see the problem when f2 itself would want to call another function (for example f4)?
1. void f1() {
2. f2();
3. int C = 10;
4. }
5. void f2() {
6. f4();
7. return;
8. }
9. void f3() {
10. f2();
11. int E = 50;
12. }
13. void f4() {
14. int X = 29;
15. return;
16. }
1. ADDd 0 line3 0x07 // store return address line3
2. JMPi line6
3. ADDd 0 10 C
4.
5. ADDd 0 line7 0x07 // store return address line7
6. JMP line14 // call f4
7. JMP 0x07 // jump to whatever address is stored in 0x07 (this exact line...)
8.
9. ADDd 0 line6 0x07 // store return address line6
10. JMPi line6
11. ADDd 0 50 E
12.
13.
14. ADDd 0 29 X
15. JMP 0x07 // jump to whatever address is stored in 0x07
16.
In that case, f2 of course also needs to store a return address for f4 to return to. However, it can’t re-use 0x07, because that memory location already stores the return address for either f1 or f3, which would be overwritten and lost forever… This is what happens in the example above: f1 is called, stores line3 in 0x07, then calls f2. f2 then stores its own return address line7 in 0x07, overwriting the line3 value forever. It then calls f4, which is indeed able to correctly return to f2. However, then we have another problem: f2 tries to “return” to f1 via 0x07, but erroneously returns to itself, causing an infinite loop!
A naive solution to this problem of overwriting 0x07 would be to just choose a different storage location for f2’s return address, say 0x06. f4 can then just do JMP 0x06 and stuff works, right?
Sadly no… imagine what happens if f3 wants to call f4 as well. It would have to somehow know that it needs to use 0x07 when calling f2, but 0x06 when calling f4, or things won’t work. This is doable for a handful of functions, but you can imagine that this is not feasible for larger programs with hundreds of functions that could each call one another. It would also consume quite some of memory, as we basically would need a separate return address storage location for each function. It also wouldn’t support so-called “recursive functions” (see below).
In short, we cannot simply choose a single return address location (we want to call functions from inside functions), nor can we choose a separate one for each function (impractical). We clearly need something else… but before we figure out what the real solution might be, let’s first think about what functions need besides return addresses. Maybe we can end up designing a system that works for other things as well?
Passing parameters and returning values
As you probably know, the functions we had above were really the simplest possible ones. Real functions are typically more complex, as they also allow the use of function parameters and return values.
For example, below fY accepts two input parameters (A and B) and has a single output/return value result:
1. void fX() {
2. int A = 1;
3. int B = 2;
4. int C = fY(A, B);
5.
6. int D = C + 5;
7. }
8. int fY(int A, int B) {
9. int result = A + B;
10. return result;
11. }
1.
2. ADDd 0 1 A
3. ADDd 0 2 B
4. JMPi line7 // call fY
5. ADDi result 0 C // C = result
6. ADDi C 5 D
7.
8.
9. ADD A B result
10. JMPi line5 // return to fX
11.
Note: line 4 was split into two instructions: one JMP to call the function and one ADDi to assign the return value to C
As we can see above, we can both pass input parameters and receive outputs (return values) by using the same variable names across functions (A, B and result). However, this again is suboptimal. In essence we’re now using global variables! Imagine again fY would call another function fZ that also uses variables named A, B or result… then fZ would end up overwriting their values with new contents! With this approach, each variable and parameter in the entire codebase would need a unique name, which is of course almost impossible (and very impractical!).
To make this a bit better, we could again think of something similar to the return address, where fX places its parameters values in certain known memory locations (say 0x60 and 0x61) and fY places its return value in 0x80. However, this is really just the exact same problem again… whether we call the location A or 0x60, the concept remains exactly the same! We are still assuming that the same memory location is re-used across functions, which has the danger of it being overwritten.
So, let’s try to rephrase our problem in more general terms, now that we see that our issues with the return address, input parameters and output values are in essence the same single problem.
The core problem is thus that we want to pass one or more pieces of data from one function to another without functions overwriting each other’s data. The only way we can do this, is to place the data in certain memory locations.
That leaves us with two options:
-
Re-use the same memory locations.
For example:
- 0x07 is the return address for each function
- 0x60 - 0x79 are the addresses of the input parameters for each function (allowing up to 20 parameters)
- 0x80 holds the return value for each function
Positive: each function knows where to look for its data, how to return after execution, and where to put data it wants to pass to another
Negative: only allow us to call a single function at a time, otherwise we would overwrite the data
-
Have separate memory locations for each individual function.
For example:
- f1() would use 0x100 as return address, 0x101 - 0x120 for parameters, 0x121 for return value
- f2() would use 0x200 as return address, 0x201 - 0x220 for parameters, 0x221 for return value
- etc.
Positive: no risk over overwriting (except when using recursive functions, see exercises)
Negative: huge memory requirement. Each function needs to know which memory locations other functions will use before being able to call them.
As we’ve said above, option 2 is impractical. But option 1 would only allow us to call a single function at a time… or would it?
As we defined the problem above, the real problem is NOT re-using memory locations; it is potentially overwriting data in them.
As such, if we can find a way to re-use the same memory locations without overwriting them, we’ve found our solution!
How can we possibly re-use memory locations without overwriting the data contained within?
By first copying out the data before the memory locations are re-used, then afterwards copying the original data back in!
The Stack
The epiphany we had at the end of the last section should be quite easy to grasp: to prevent overwriting some data, we first copy that data to another location. Then, after the function call is done, we copy the data back to the original location.
Let’s illustrate this with the simple example where we only need to worry about the return address (stored at 0x07) being overwritten by f1 calling f2, which then calls f4:
1. void f1() {
2. f2();
3. int C = 10;
4. }
5. void f2() {
6. f4();
7.
8.
9. return;
10.}
11. void f4() {
12. int E = 50;
13. return;
14. }
// we start in f1() so 0x07 is empty at this time
1. ADDd 0 line3 0x07 // store return address line3
2. JMPi line5 // call f2
3. ADDd 0 10 C
4.
5. ADDi 0x07 0 0x500 // copy whatever is in 0x07 (return addres from caller f1) to 0x500
6. ADDd 0 line8 0x07 // put our own f2 return address (line8) in 0x07
7. JMPi line11 // call f4
8. ADDi 0x500 0 0x07 // copy 0x500 back to 0x07 (restore previous value)
9. JMP 0x07 // return from this function to caller f1
10.
11. // f4 doesn't call another function, so we don't need to put anything in 0x07
12. ADDd 50 0 E
13. JMP 0x07
14.
As we can see, all the magic happens in f2. Here, we first protect f1’s return address (which is in 0x07) by copying it to 0x500, before putting f2’s own return address into 0x07. As we can see, we are now indeed re-using the single memory location in each function, but without overwriting/losing data!
You might think that’s it, we’ve done it! However, let’s contemplate what happens if I have more than 3 functions. Let’s say f1 calls f2, which calls f3, which calls f4, which calls f5.
f2 can use 0x500 as temporary storage, but of course f3 cannot, or it would overwrite things again! So f3 would maybe use 0x600, f4 might use 0x700, etc.
We can see this is again not ideal… it’s better than our previous discussion, because here the calling function can choose which memory to use as temporary storage (as opposed to being hardcoded in the called function). However, this still has issues: how does f4 know that f2 is using 0x500 and that it itself should be using 0x700 instead? In other words:
How do we ensure functions don’t re-use each other’s temporary storage?
By having each function store its data directly after that of the previous function!
Instead of having each function decide its own temporary storage locations, we will just ensure they put their copied data after that of the previous function. As such, if f2 would use 0x500, then f3 would use the next free location after that, being 0x501. f4 then uses 0x502, etc. Conceptually, you can say that each function adds more temporary data on top of a large pile of memory. You can compare it to a stack of papers or books: you start with one on the bottom, then keep putting others on top whenever you need place to store a page/a book.
The opposite is also true: you can’t just grab the book at the bottom of the stack; you first need to remove other books from the top. Here, this means f4 can’t just immediately return to f2 (0x500), we of course first need to return to f3 (0x501) before we can do that.
As such, this approach of putting per-function data directly after each other in memory is typically called just that: the stack!
The Stack Pointer
Again, we of course don’t want to hardcode the addresses in the functions! We want to dynamically know which location the previous function used last, and then dynamically store our data after that.
We can do this by using just a single global variable (shared across all functions), which is called the stack pointer.
Let’s say this stack pointer lives at address 0x82. Its initial value is 0x500. f1 starts and places it return address (line3) into 0x07. This is the (partial) state of the RAM at this point:
| Address | Value | Comment |
|---|---|---|
| 0x07 | line3 | shared return address location |
| 0x82 | 0x500 | stack pointer |
| Address | Value | Comment |
|---|---|---|
| 0x500 | ||
| 0x501 | ||
| 0x502 | ||
| 0x503 |
When f2 is called, it loads the value that’s in 0x82 and finds it’s 0x500, which is the address where it can start storing its temporary data. It puts the return address of f1 (value in 0x07) in 0x500 and then, very importantly, increases the value of the stack pointer by one (one, because it has stored a single byte). The value of the stack pointer at 0x82 is now 0x501. f2 can now set its own return address (line8) in 0x07 and then call f3 as shown above. The RAM now looks like this:
| Address | Value | Comment |
|---|---|---|
| 0x07 | line8 | shared return address location |
| 0x82 | 0x501 | stack pointer |
| Address | Value | Comment |
|---|---|---|
| 0x500 | line3 | return address of f1, stored here by f2 |
| 0x501 | ||
| 0x502 | ||
| 0x503 |
f3 then wants to call f4, so it needs to store f2’s return address (currently in 0x07) on the stack. It loads the stack pointer at 0x82, finding that it has safe room to temporarily copy data at 0x501 and does so. f3 then, again very importantly, increases the value of the stack pointer by one (to 0x502, preparing it for use by f4), and stores its own return address (say line14) before actually calling f4. The RAM is now:
| Address | Value | Comment |
|---|---|---|
| 0x07 | line14 | shared return address location |
| 0x82 | 0x502 | stack pointer |
| Address | Value | Comment |
|---|---|---|
| 0x500 | line3 | return address of f1, stored here by f2 |
| 0x501 | line8 | return address of f2, stored here by f3 |
| 0x502 | ||
| 0x503 |
Note: because of how we’re drawing the diagrams above, the stack (starting at 0x500) is “upside down”, growing downward instead of upwards!
Now, let’s say it ends there: f4 does not call any other functions, just does its work and then returns back into f3. Now we’re really going to start to see the power of using the stack!
f4 did not do anything to 0x07, so it knows it can just use its current value (line14) as return address to get back into f3. After that, the RAM still looks the same as the last diagram from above.
Now, f3 needs to do some more work of course. It needs to figure out how to return to its caller (f2). It knows it has previously stored f2’s return address on the stack (via the stack pointer), and after that it had increased the stack pointer by one. As such, to figure out where it had stored f2’s return address, it needs to undo what it did. First, it reads the value of the stack pointer in 0x82, getting back 0x502. It then decrements that value by one, making it 0x501. It now knows that the return address of its caller (f2) is at 0x501 and can read that value, finding line8. It places that value back into 0x07. It now first cleans up after itself by clearing the value of 0x501, and then returns to f2 by JMPing to 0x07. The RAM now looks like this:
| Address | Value | Comment |
|---|---|---|
| 0x07 | line8 | shared return address location |
| 0x82 | 0x501 | stack pointer |
| Address | Value | Comment |
|---|---|---|
| 0x500 | line3 | return address of f1, stored here by f2 |
| 0x501 | ||
| 0x502 | ||
| 0x503 |
You will see this state of the RAM is exactly the same as that from before we called f3 in the first place. This is of course exactly as intended! The stack is only used as temporary storage, and as such should no longer be needed once we’re done executing all functions!
The same thing happens in f2: it reads the stack pointer, decrements it by 1, and finds 0x500. It places the value at 0x500 at 0x07, clears 0x500, and then returns to f1 with JMP 0x07. The RAM state is again the same as the one we started with above.
The Stack in Assembly
To be able to write the above sequence in Assembly, we actually need a new syntax. This is because we need to read the stack pointer’s value (at 0x82) and then use the value itself (example 0x501) as an address! We weren’t able to do this before, except when it was implied in the instruction’s way of working (for example, JMP does work like this implicitly!). If we want to do this for other instructions as well however (for example ADDi), we need some way to indicate that the read value should be treated as an address instead of an immediate. For this, we’ll take inspiration from C’s pointers:
If we write * before an address, it means we want to use the value at that address as a new address instead of as a value.
For example:
ADDd 3 5 0x10 : this means we store the value 8 at address 0x10.
ADDd 3 5 *0x10 : this means we read the value currently at address 0x10, interpret it as another address (say the value was 0x29), and write 8 to that address.
This is needed to be able to write to the free temporary memory address pointed to by the stack pointer:
ADDi 0x07 0 *0x82 : this adds 0 to the value of 0x07 (so it stays the same), and then stores the result not in 0x82, but in the address value stored in 0x82 (which is 0x500 at the start of our examples).
If we thus write the above sequence in Assembly, we get:
0.
1. void f1() {
2. f2();
3. int C = 10;
4. }
5. void f2() {
6.
7.
8. f3();
9.
10.
11. return;
12.}
13. void f3() {
14.
15.
16. f4();
17.
18.
19. return;
20. }
21. void f4() {
22. int E = 50;
23. return;
24. }
// we start in f1() so 0x07 is empty at this time
0. ADDd 0 0x500 0x82 // initialize the stack pointer (done by the OS)
1. ADDd 0 line3 0x07 // store return address line3
2. JMPi line5 // call f2
3. ADDd 0 10 C
4.
5. ADDi 0x07 0 *0x82 // store the contents of 0x07 (line3) on the stack (at 0x500)
6. ADDi 0x82 1 0x82 // increment the stack pointer value by one (is now 0x501)
7. ADDd 0 line9 0x07 // put our own f2 return address in 0x07
8. JMPi line13 // call f3
9. SUBi 0x82 1 0x82 // decrement the stack pointer value by one (is now 0x500)
10. ADDi *0x82 0 0x07 // store the value at the stack pointer address (at address 0x500) in 0x07
11. JMP 0x07 // return from this function to caller f1
12.
13. ADDi 0x07 0 *0x82 // store the contents of 0x07 on the stack (at 0x501)
14. ADDi 0x82 1 0x82 // increment the stack pointer value by one (is now 0x502)
15. ADDd 0 line17 0x07 // put our own f3 return address (line17) in 0x07
16. JMPi line22 // call f4
17. SUBi 0x82 1 0x82 // decrement the stack pointer value by one (is now 0x501)
18. ADDi *0x82 0 0x07 // store the value at the stack pointer address (at address 0x501) in 0x07
19. JMP 0x07 // return from this function to caller f2
20.
21. // f4 doesn't call another function, so we don't need to put anything new in 0x07
22. ADDd 50 0 E
23. JMP 0x07 // return from this function to caller f3
24.
One crucial thing you will notice is that the stack-specific code is exactly the same for both f2 and f3. This is the beauty of using a dynamic setup like the stack pointer: it doesn’t rely on hardcoded addresses or logic, and so the exact same code can be re-used!
Note also that the stack instructions are each other’s opposites: ADDi 0x07 0 *0x82 is undone by ADDi *0x82 0 0x07 and ADDi 0x82 1 0x82 is inverted by SUBi 0x82 1 0x82, creating a nice symmetry!
Push and Pop
You might also notice that this re-use of code makes it quite annoying to read/write, especially since each stack operation requires two instructions: one to actually move a value on/off the stack and one to increment/decrement the stack pointer.
For this reason, these operations are often represented by their own specific instructions, called PUSH and POP. PUSH adds a new value on top of the stack and increments the stack pointer by the size of that value (in our examples this has been 1, but soon we’ll see this can be any size). POP is the opposite: it removes the top value from the stack and decrements the stack pointer by the size of that value.
As such, the previous Assembly on the left becomes the new on the right, making it more readable and easier to write:
ADDi 0x07 0 *0x82
ADDi 0x82 1 0x82
...
SUBi 0x82 1 0x82
ADDi *0x82 0 0x07
PUSH 0x07 // push value in 0x07 on top of the stack
...
POP 0x07 // pop value from top of the stack and put it in 0x07
Note: for simplicity, we will assume PUSH and POP know where the stack pointer is stored (at 0x82 previously). In “real” Assembly, this is often a special address/memory location reserved for this purpose by convention and is always the same for all programs (we’ll see later how that’s possible with virtual memory without causing collisions).
The stack for parameters, return values, and local values
If you look back at how we introduced the need for the stack above, you’ll remember we talked not just about return addresses, but also function parameters and return values (remember function fY(int M, int N)?). We then said that these function features had exactly the same problems as the return addresses (risk of overwriting data across functions).
Now that we’ve solved the problem for return addresses, you’ll be happy to hear the same solution also works for parameters and return values! To reprise the example from before (but changing the variable names slightly to enforce our point), we would now write it as follows using the stack:
1. void fX() {
2. int A = 1;
3. int B = 2;
4.
5.
6.
7. int C = fY(A, B);
8.
9. int D = C + A;
10.}
11. int fY(int M, int N) {
12.
13.
14. int Q = M + N;
15.
16. return Q;
17. }
1.
2. ADDd 0 1 A
3. ADDd 0 2 B
4. ADDd 0 line8 0x07 // return address in 0x07
5. PUSH A // parameter 1
6. PUSH B // parameter 2
7. JMPi line12 // call fY
8. POP C // C = return value from fY
9. ADD C A D
10.
11.
12. POP N // B was pushed last, is now on top, corresponds to N
13. POP M // A was pushed first, was below B, corresponds to M
14. ADD M N Q
15. PUSH Q // put Q on top of the stack, so fX can POP it later to access the return value
16. JMP 0x07 // return to fX
17.
As you can see in the example, we no longer need to have global variable names/addresses! Variables that are passed via the stack don’t have a name, just a specific order on that stack. As such, we have no more danger of overwriting the parameters/return values if we were to call other functions, as PUSH/POP would change the stack pointer accordingly. Do note that this order is reversed in the called function (we first need to POP N and then M, while we PUSHed A and then B).
Note: we’re currently not storing the return address on the stack. Instead, we use 0x07 directly because we know there’s just two functions. With more functions, you of course do have to store it as well and think about the correct order. You’ll have to do this in one of the lab exercises!
Local values
As we can see in the examples above, the stack is a self-cleaning data structure. As long as you properly POP everything you’ve pushed, the stack is nicely reset to its previous state once a function returns! This also makes it a very powerful way to track memory usage and prevent memory leaks!
This is one of the main reasons why most programming languages don’t just store return addresses, input parameters and return values on the stack, but also most local variables!
In the example above, A, B, C, D and Q (variables that are declared without being direct function parameters), would in reality also be stored on the stack!
Consider again that this makes sense: say fX had chosen address 0x700 for A and 0x701 for B. How would fY know this? How would you prevent it from choosing 0x700 as well to store Q? You would have to keep track of all used memory and check if something was available for each variable you created!
Instead it’s much easier to just PUSH new local variables on the stack, as you know the stack is auto-increment/decremented with PUSH/POP and so you’ll never overwrite. Additionally, as we’ve said here, this automatically cleans up the local variables. After all, outside the function they are no longer needed. If they were, they would have been passed as input parameters or returned as a return value (also via the stack!)
We (intentionally) don’t really have the correct Assembly syntax here to easily represent storing local variables on the stack as well. After all, you’d have to be able to reference values on the stack by name/position without POPing them for the examples above. In real Assembly, this is typically done by using memory offsets within the stack to re-use values. That is however too advanced for this class (see later courses for that). For now, just assume all variables you declare somehow end up on the stack and are also automatically cleared from it when the function returns. This will be important when talking about stack memory usage and stack overflows in later classes!
Of course not everything is stored on the stack. There is of course a way to use memory outside of the stack and do its management yourself. As you’ll see later in this course, we call this the heap, and you will have to use special C functions (for example malloc/free) to use that memory, while you get the stack “for free” (the necessary Assembly is added by the C compiler so you don’t have to worry about it).
For the heap, the OS indeed tracks which memory is used and which is free, and it has to check this every time you try to reserve new memory. This is why most variables live on the stack (easier, less overhead) and why you will usually reserve larger chunks of heap memory at once (not just 1 byte, but tens or even thousands at once).
Cache and Registers
Finally, it should be said that our Von Neumann architecture was really a bit too high-level to (still) be realistic. Up until now, we’ve been pretending that everything is stored directly in RAM memory (both data and instructions) and that all instructions read/write directly from/to RAM. This is not true in practice, as that would be quite slow…
You see, RAM memory is very large nowadays, and we mean that in a physical sense. The physical area needed to store say 16 GB RAM (say 20 square centimeters) is several times that of your CPU chip. Additionally, we want to be able to easily replace/add RAM, so it’s usually stored separately from the CPU chip itself (e.g., separate memory banks on your motherboard), otherwise changing RAM would also mean changing the CPU!
While the physical distance between your RAM and CPU seems small (just a few centimeters), at the speeds your CPU is running (nano-second scale for each clock tick!), that distance is actually very large, as we’re limited by the theoretical speed of light, and practical metal conduction properties. As such, reading/writing data from RAM can take several hundreds to thousands of nano-scale CPU cycles, which is of course too slow to be practical.
As such, over time, smaller but faster pieces of memory have been added closer to the CPU. You probably know these as the cache memory and its several layers. L1 is close to the CPU and takes 5-10 cycles. L2 is a bit further away and takes tens of cycles. L3 is further still (and usually shared between several CPU cores) and can take +100 cycles. In the image below, 1 cycle is about 0.25 nano seconds (ns), so 50ns is +200 cycles for RAM (and a mechanical hard disk can take over 20 million cycles (50ms+)!!!!).
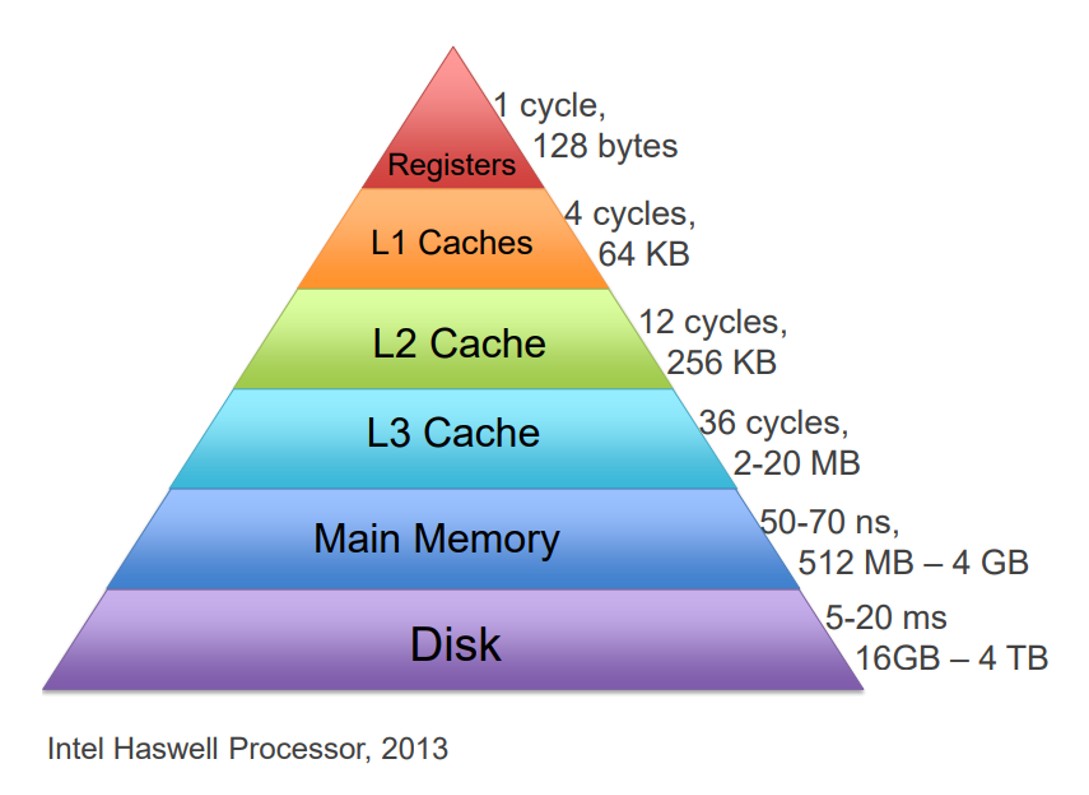
Image Source: http://www.cs.cornell.edu/courses/cs3410/2019sp/schedule/slides/12-caches-pre.pdf
But maybe you have not heard about the smallest but also fastest type of memory a CPU has, called registers. Registers are a very limited amount of memory locations (usually there are 32 to 256 registers, each of 32 to 64 bit) that are located very close to the ALU itself. Registers typically cost no (extra) CPU cycles to read/write and thus should be used as much as possible. However, since we have so few of them available, we have to be very clever which registers to use for what at what time, and also not to overwrite them with new values!
In practice, this is done by the compiler (and sometimes partly by the advanced CPU itself!). The compiler will generate assembly that properly loads data from the RAM into the registers (and caches), but that also writes data back to RAM/cache from the registers when it knows it won’t be needed soon. Deciding what should be kept in registers and what can be “spilled” to RAM is often a complex problem (somewhat understandably explained in this short video). This all means that real assembly is usually even more complex than what we’ve seen, with extra LOAD/STORE instructions in between.
Most real assembly instructions also don’t work on memory addresses directly, but instead on register numbers. For example, ADD would not take 3 RAM addresses, but rather 3 register numbers. If we wanted to ADD data from the RAM, we would first need LOAD instructions to get that into registers, then do the ADD on the registers, and then STORE the result back into RAM.
This might seem like a lot of overhead (didn’t we just say RAM access is slow?) until you recognize that most programs do lots of calculations with intermediate results (say A = B + C; D = A + E; F = D + G;), where we can keep all the intermediate values (A, D, F) just in registers; they often don’t need to be stored in the RAM until all the way at the end of the calculations/function! This in combination with the faster cache memories means this “layered memory architecture” actually gives a massive speedboost (compared to using RAM directly) in practice!
You will learn much more about real assembly, registers and cache memory in later courses. But for now, this will do ;)