6.4: Threads
In the previous three sections we have discussed that you can run multiple processes at the same time and how this is managed by the OS. This can be useful in two ways: either a) to use multiple programs at the same time (e.g., your Web browser and music player), or b) to make efficient use of multiple hardware CPUs or processing cores.
We have however also seen that this is not trivial: new processes need their own memory space and associated state (the PCB) and communication between processes is either flexible but complex (shared memory) or straightforward but limited (message passing).
Luckily, there is another way to split up processes into smaller subtasks and make more efficient use of multicore hardware without incurring as much overhead. This is accomplished using Threads.
A thread is an independent unit of execution within a process. Put differently, it’s a sequence of code instructions that can be executed independently from and, crucially, in parallel with other threads. As such, each thread can for example be assigned to a single CPU core for parallel processing.
What’s in a thread ?
Up until now all the processes that were discussed contained just one thread (sometimes called the main thread). Such a process is referred to as a single-threaded process:
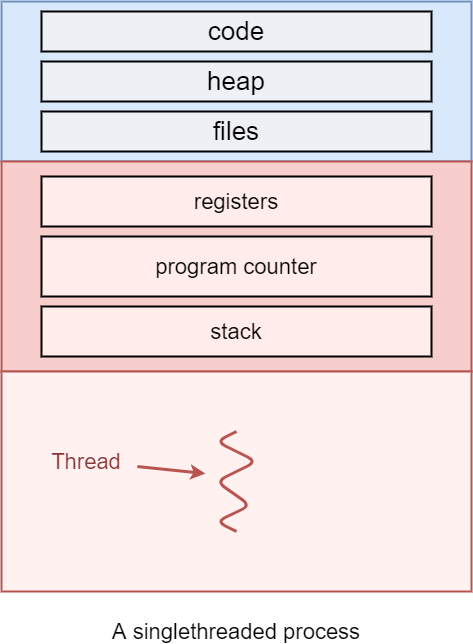
The single threaded process
Let’s examine the image above. On the top of this image the following segments are mentioned: code, heap, and (open) files, alongside the registers, program counter and the stack.
As we’ve seen, when multiple processes run at the same time, every individual process has separate and isolated instances of all these segments, like shown in the image below:
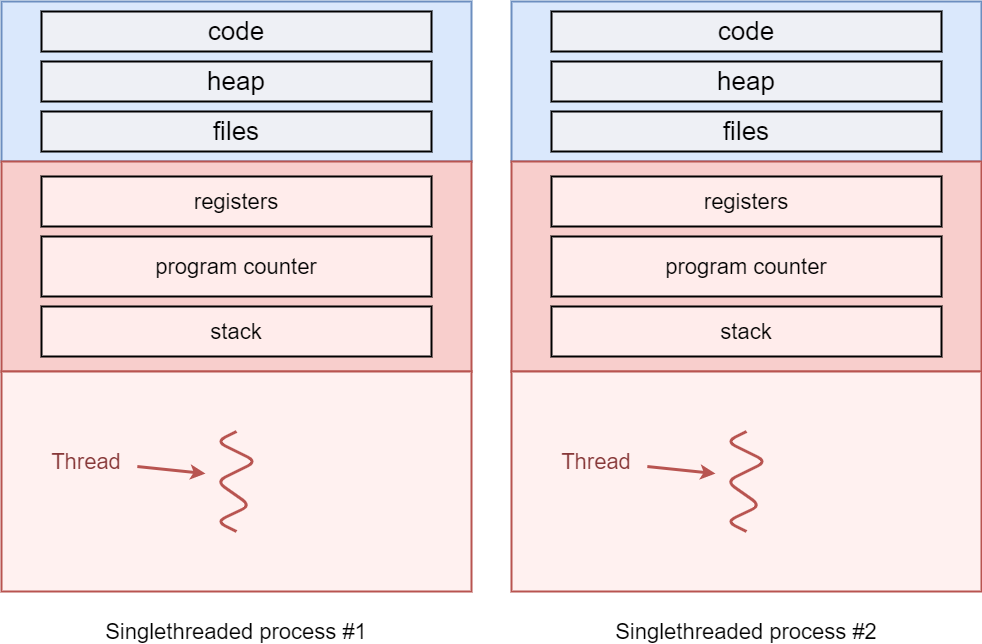
Two single threaded processes running in parallel
However, the name “single-threaded” of course also implies the existence of multi-threaded processes, which have more than one thread. Each of these threads can execute in parallel and as such also need their own copies of some of the segments: the register contents, current program counter and the full stack are now independent for each thread. You could say that each thread has its own “Thread Control Block” (in analogy with the PCB), which tracks this metadata. However, the main difference between parallel threads and parallel processes is that threads do still share many things: the copy of the code, the (open) files and the heap memory. This is one reason why threads are more lightweight than processes, as they don’t require copying these segments when new threads are created.
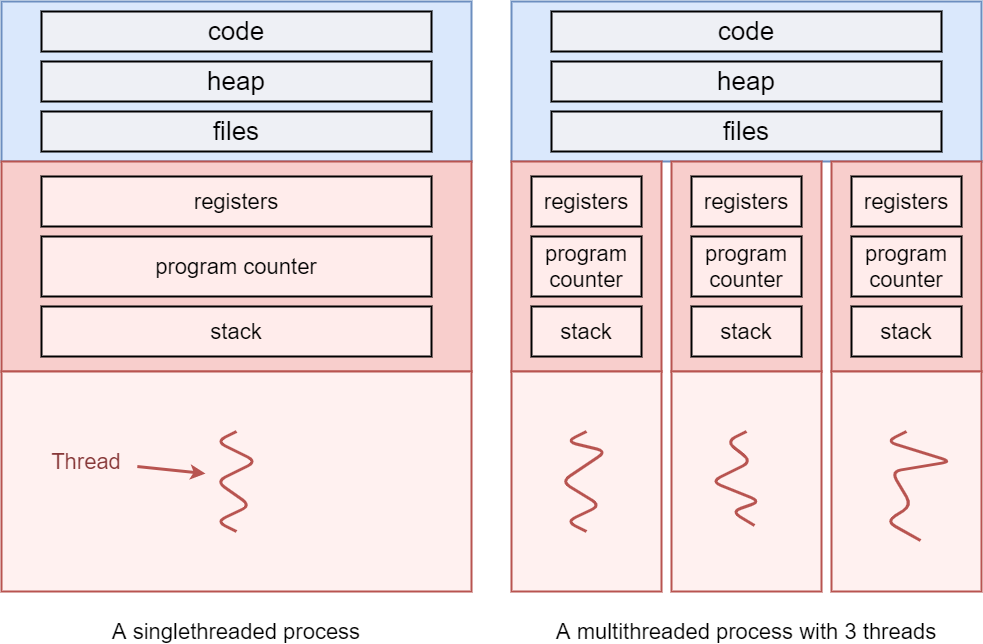
A single-threaded vs multi-threaded process
- the code segment
- the heap memory
- the list of open files
- register contents
- program counters
- stack memory
Why would we want multiple threads ?
There are 4 major benefits to working with multiple threads:
- Responsiveness: When a single program is broken down into multiple threads, the user experience feels more responsive. Dedicated threads can be created to handle user requests and give (visual) feedback, while other threads can for example process data in the background.
- Resource sharing: Programs that have multiple threads typically want some sort of communication between these threads. This is done more easily between threads than between processes, as threads implicitly share memory via their heap. This is discussed in detail in the next Section.
- Economy: Context switching becomes cheaper when switching between threads in comparison to switching between processes. This is because less per-thread state needs to be tracked, in comparison to more per-process state.
- Scalability: Multiple threads can run in parallel on multi-core systems in contrast to a single threaded process.
Although there are many advantages to multi-threaded programming, it requires skilled programming to cash in on these opportunities. Not all code can be easily parallelized and communication between threads is not trivial. We will focus on these aspects in the remainder of this chapter.
Amdahl’s law
While threading seems like the ideal, lightweight solution to make your programs run faster, it might be surprising to hear that program performance typically does not scale linearly with the amount of threads and/or amount of CPU cores. This is because typically not all code in a process can be parallelized (and thus run in separate threads): there are typically parts of code that need to aggregate results from the parallel computations, which can only be done in a serial fashion. This can be seen in the following image:
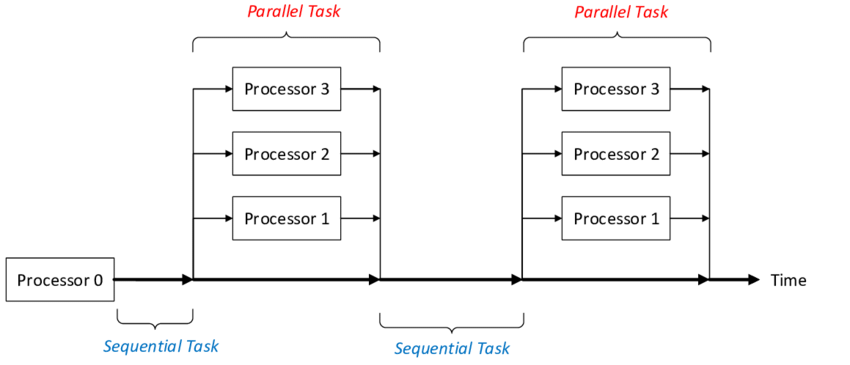
Parallel processing can lead to serial phases in a process. Source: J. Wolf et al. - Contribution to the Fluid-Structure Interaction Analysis of Ultra-Lightweight Structures using an Embedded Approach
A theoretical model for assessing the maximal gains from multithreading a program was developed by Gene Amdahl in 1967. His formula identifies potential performance gains from adding additional computing cores to an application that has both serial and parallel components:
\( speedup < { 1 \over { S + { (1-S) \over N } } } \)
In this formula S stands for the portion of the application that has to be run serially. N stands for the number of cores on which the parallel portion is spread. We can see that to maximize the speedup, we need to keep the divisor of the fraction as small as possible. This is done by keeping S as small as possible, and N as high as possible.
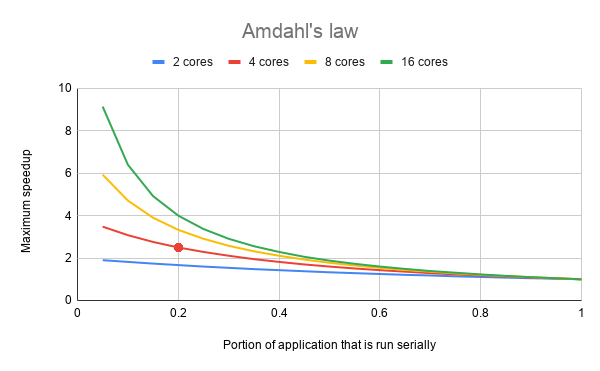
Source: Wikipedia
The graph above visualises Amdahl’s law. For example, as marked by the red dot, if a program has 80% of its code that can be run in parallel (and so 20% of the code has to be run serially), it can be run at maximum 2.5 times faster, using 4 cores. If only 50% of the code can be run in parallel, the amount of cores matters much less, with a maximum speedup of 2x being possible even with 16 cores.
However, as stated above, it requires a skilled programmer to achieve maximal speed-up even if a large part of the program can be parallelized. If the program needs a lot of data that needs to be communicated between the serial and parallel portions this becomes even harder to achieve, as this can also cause additional slowdowns.
User threads vs System threads
By now, you might still think that using threads is only useful if you have multiple processors, or, if you do have multiple CPU cores, that you should only use as many threads as you have cores. However, this is somewhat incorrect.
While it is true that you might not get a speedup if the number of threads is larger than the number of cores, that does not mean you cannot run tasks in a seemingly parallel fashion. Take for example the simplest case where you have two threads and just a single CPU core. Like with the processes, this does not mean that thread 1 will run fully before thread 2 can start. Instead, the OS will again schedule the threads, pausing one and (re-)starting the other several times in quick succession.
As processor speeds are many times what the typical human would notice, this often gives the illusion of parallel execution. A good example is the “Responsiveness” benefit mentioned above, achieved by using a separate thread for User input/User interface updates. Even if the program has a thread executing heavy calculations, the UI thread will get enough CPU time to listen to User input.
As such, there is often not a direct one-to-one mapping between threads and actual processor cores. Internally, the OS has a concept of Kernel threads that it schedules and divides between the processors. The threads we create, sometimes called User threads can be mapped onto those kernel threads in several different ways (e.g., one-to-one, one-to-many, many-to-many) and this mapping can also change over time (e.g., transferring a thread to a different CPU). The exact details are out of scope for this course, but it’s useful to know that you typically won’t control directly how your threads run. In a multi-process setup (which is typical for most OSes) you typically can’t even guarantee that all the threads for a given process are really all running in parallel, as other threads from other processes might also require CPU time. This makes it even more difficult in practice to measure and ensure the speedup from using multiple threads.
Creating threads
Before discussing how to communicate between threads however, we first look at how we can create threads in C.
In the previous sections on processes, multiple processes could be created through the fork and exec functions. These function wrap the OS system-calls that are required to achieve this. Therefore, this comes intrinsically with the OS.
Threads are of course also fully supported by the OS, but they typically require a more high-level API to easily work with. Most programming languages provide their own versions of these APIs, but they all internally call the OS-provided functionality. As we are working with Linux, we will be using the standard POSIX API library called pthreads.
Pthreads
A simple example for creating a new pthread is given below:
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
int counter;
void* startThreadJob() {
unsigned long i = 0;
counter += 1;
printf(" Job %d started\n", counter);
for(i=0; i<(0xFFFFFFFF); i++) {
// do nothing
// this is just here to keep the thread running for a while!
}
printf(" Job %d finished\n", counter);
return NULL;
}
int main(void) {
int i = 0, err;
pthread_t tid[2];
counter = 0;
while(i < 2) {
// pthread_create has 4 parameters:
// 1. pointer to pthread_t, needed to keep thread state
// 2. configuration arguments for the thread (passing NULL means we use the defaults here)
// 3. pointer to the function that will run in a separate thread
// 4. parameters to pass to the thread (no arguments for startThreadJob, so we pass NULL)
err = pthread_create( &(tid[i]), NULL, &startThreadJob, NULL );
if (err != 0) {
printf("\ncan't create thread :[%s]", strerror(err));
}
i++;
}
// pthread_join pauses the current thread until the thread in the first argument is terminated
// Note that the "main" function automatically also executes in a thread, which we often call the "main thread".
// If the joined thread was already terminated, pthread_join returns immediately
// The second argument can be used to store the return value of the thread
// Our thread currently doesn't return anything, so we pass NULL
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
return 0;
}
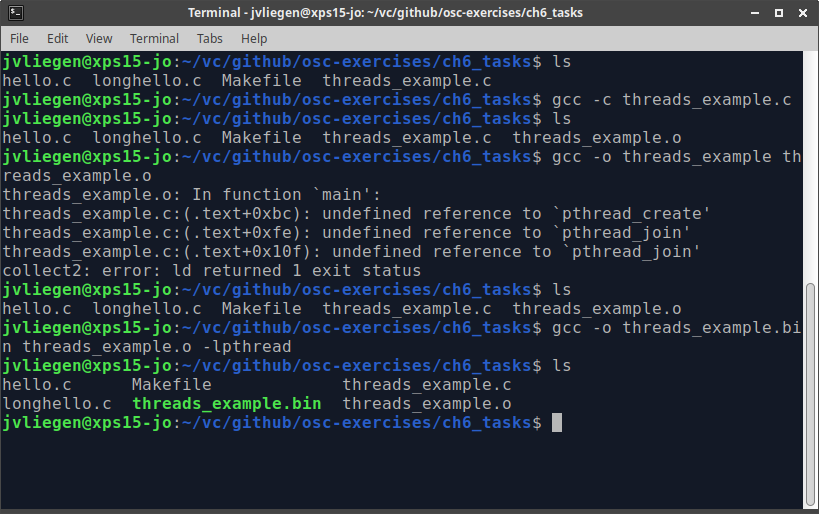
When the code above gets compiled, the pthread library has to be used. This library contains the object files that implemented the functions pthread_create() and pthread_join(). Compilation can be done because of the #include <pthread.h> line. For linking however, you have to separately tell gcc to use the pthread library as well by adding -lpthread (e.g., gcc -o program program.c -lpthread).
The example above is quite simple and doesn’t show a few of the more complex aspects of dealing with threads, particularly passing data into and out of the thread function (parameters and return value). The following example shows how you can pass a single parameters to the thread and how you can handle a return value. Note that we use (void*) as a type here, since the parameters can be anything and pthread_create can’t know which type they will be. As such, you as the programmer need to first cast to (void*) when creating the thread, then cast the (void*) back into what you really want it to be in the thread.
Something similar happens for the return value in pthread_join. Can you figure out why this needs a (void**), even though the thread function returns a (void*)? (or look it up online if you can’t?)
#include <stdio.h>
#include <string.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
void* threadWithParameter(void* textInput) {
char* text = (char*) textInput;
unsigned long i = 0;
printf("In thread %s: Thread started\n", text);
for(i=0; i<(0xFFFFFFFF); i++) {
// do nothing
// this is just here to keep the thread running for a while!
}
printf("In thread %s: Thread finished\n", text);
return text;
}
int main(void) {
int i = 0, err;
pthread_t tid[2];
while(i < 2) {
if ( i == 0 ) {
err = pthread_create( &(tid[i]), NULL, &threadWithParameter, "nr 1" );
}
else if( i == 1 ) {
err = pthread_create( &(tid[i]), NULL, &threadWithParameter, "nr 2" );
}
if (err != 0) {
printf("\ncan't create thread :[%s]", strerror(err));
}
i++;
}
char* returnValue = NULL;
pthread_join(tid[0], (void **) &returnValue);
printf(" In main thread: Thread %s returned!\n", returnValue);
pthread_join(tid[1], (void **) &returnValue);
printf(" In main thread: Thread %s returned!\n", returnValue);
return 0;
}