6.7: Inter-Thread communication (lab)

Source: G.I.
Good Morning, Sire
Polite servants, impolite king
Extend this incomplete C-program. As you can see, the program has one king thread and N servant threads, but they don’t really do anything yet. Implement the following using one or more semaphores:
- The king thread sleeps (using the
sleep()function) for a random amount of time (a few seconds). - When the king thread awakes, it signals the servant threads.
- All servant threads politely say Good Morning, sire (using
printf()) together with their servant ID. - The king thread goes to sleep again.
Take note of these things as well:
- You can find some concrete code examples of pthread semaphores in the code on the bottom of Assignment 3!
- Every servant needs to greet the king once (no more, no less)
- The king doesn’t wait for the servant greetings before he goes back to sleep
- You do not need to make sure that the servants always reply in the same order
- Repeat the wake-greet cycle at least 10 times
- Tip: use the
rand()function to get random numbers
Polite king
REVISIT, WITH A TWEAK Change the previous king-servant setup with a single change: now, the king does explicitly wait for the greetings of all his servants before he goes back to sleep.
Think about if you need additional semaphores/mutexes for this and why.
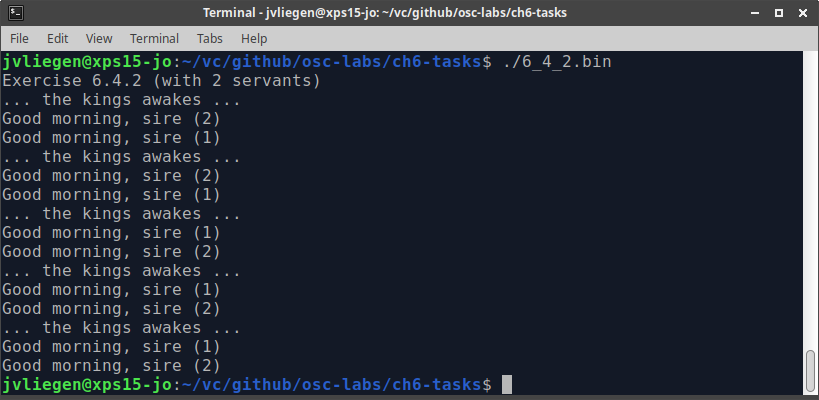
An example output
Deadlock Empire: The Endgame
- Go to the Deadlock Empire website and complete these two exercises:
- The Final Stretch: Dragonfire
- The Final Stretch: Triple Danger
Producer-Consumer V1 : Single mutex
In the prime-number exercises in the previous labs, we were actually implementing the basics of a producer-consumer problem, without really knowing it! In our example solution, we bypassed the shared memory issue by assigning each producer (the calculatePrimes function) a separate block of memory only they could use/access to place their results. As you know now, this is highly inefficient and a waste of memory. As such, it’s time to make our prime-number into a proper producer-consumer setup with a single shared memory array of a limited size!
We will do this in several steps, starting with a somewhat sub-optimal mutex-based solution and ending up with a more complex semaphore-based one!
Start from the provided solution to the last prime-number exercise (6_5_3_primethreads.c). Change it so:
- All 4 producer threads write their results to a single shared array instead of the 4 separate
resultsarrays (note: this single array will still be quite large, say 20000 integers). - Make a new
printPrimes()function that acts as the consumer. Usepthread_createinmainto start a single instance of the consumer. Make sure this function prints newly produced primes as soon as possible/as soon as they’re put in the shared array (meaning: we’re no longer waiting for all the producers to be done before starting to print the results inmain()).
For this, you should use a single mutex to prevent the producers/consumers from having race conditions on the single shared array.
- Tip: use a global
write_indexvariable to manipulate the shared array
Note: in this setup, the primes will no longer be printed in-order from smallest to largest. That’s fine ;) Can you explain why though??? And can you imagine a possible solution where they -are- still printed in-order?
Producer-Consumer V2 : Proper close
One thing you might/should have noticed in the previous exercise, is that it’s no longer easy to determine when the consumer should stop printing/when it has printed all produced primes.
In the original solution 6_5_3_primethreads.c, we had the producers write the number 0 at the end of their result array to signal they were done (because 0 is not a prime). In the new setup however, we can’t use this anymore, because not all producers end at the same time, and so new “real” primes might be written after a 0 from the first finished producer!
As such, we need a new way to determine when we’re done: keep a count of producers that are done. Then, the consumer can check if this “done count” is equal to the number of producers. If so, it can safely exit without having to rely on the 0 sentinel value.
- Extend your previous code to keep a thread-safe “done count” of the number of finished producers.
- Make sure your consumer properly checks this “done count” (again in a thread-safe way!) and that it also properly exits/returns when all primes are printed.
Keeping the “done count” thread safe can be done in two main ways. Choose one:
- Use a count variable and a mutex
- Use a semaphore as a counter. (tip: here it might help to use the
sem_getvalue()function. Look up online what that does and how to use it).
Producer-Consumer V3 : Multiple consumers
In the previous two versions, we had only a single consumer. To get maximum performance, we of course would like to not just have multiple producers, but also multiple consumers!
Extend your previous solution to:
- Create at least 2
printPrimesconsumer threads (ideally more!), that all read from the shared array and print the produced primes. Of course you need to make sure no primes are printed twice (= thread-safe access to the shared array from all consumers)!!!
Note: this can again be done in several ways. The simplest/best way however, doesn’t even require you to define a new mutex here; you can just re-use the one from the V1 above. Tip for this: previously we just had a global write_index, now we also need another type of global index ;)
Producer-Consumer V4 : Semaphores
Up until now, you’ve used (should have been using?) mainly mutexes to access a single (huge) shared array. Because the array is so large, we didn’t have the typical mutex problems like busy waiting, because there was always room for newly produced primes to be placed in the shared memory (unless we had very high limits for the prime generation).
To forcibly show the usefulness of semaphores when we don’t have “unlimited” shared memory, you will now adapt your previous code to:
- Use semaphores instead of mutexes (at least for the main shared memory, you can still use a mutex for the “done count” if you did that)
- Use only the minimal amount of shared memory. Put differently: the shared array is now only a single integer in size instead of say 20000. All producers and all consumers can only use this single shared “memory location” to pass individual primes from one to the other. Consequently, this single “shelf” needs to be ultra-thread-safe!
Tip: These changes shouldn’t be too large (though also not tiny ;)). Nor should they be very different from the producer-consumer semaphore examples shown in the course text.
Note: think about if you still need a mutex inside of your semaphore(s) as well. Why (not)? Look up the discussion on “binary semaphores” in the course text. Is this the same/a similar situation or not?
Note: this exercise is a mandatory part of Assignment 3. While the assignments are individual, you CAN (and should) collaborate on this exercise! The solution will be posted only after the deadline for assignment 3 however.