6.6: Inter Thread communication
One raison d’être for multi-threaded applications is resource sharing. In the example that was given earlier a global variable ‘counter’ was used. No measures were taken for securing this approach and we got some unexpected results. The output of the example looks like shown below:
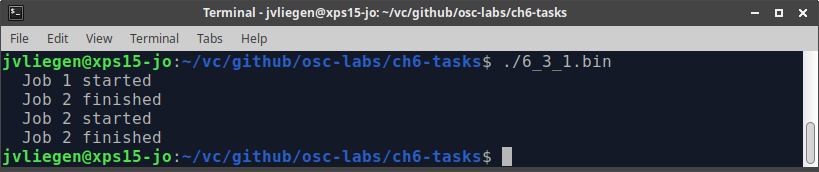
This probably came as a surprise 😃
It should be clear that what we wanted to see was Job 1 started followed by Job 1 finished and that this would be repeated again for job number 2.
The first of both threads that gets to its function increments the counter from 0 to 1. However, before this thread has finished its execution, the second thread has started and has incremented the counter from 1 to 2. By the time the first thread finishes, the counter value is 2, which is in contrast with the intended value of 1.
Critical Section and Race Conditions
At first glance, it might seem that this problem is easily solvable by copying the global counter to a local, per-thread variable for later use:
void* doSomeThing(void *arg) {
unsigned long i = 0;
int local_id; // new, per-thread variable
counter += 1;
local_id = counter; // make a local copy of counter for this thread
printf(" Job %d started\n", local_id);
for(i=0; i<(0xFFFFFFFF);i++);
printf(" Job %d finished\n", local_id);
return NULL;
}
If you tried to implement this, it would probably work… most of the time at least. As explained in the first section on threads, threads are not necessarily run in parallel all the time, especially not if the number of threads is larger than the number of CPU cores. In fact, there are many situations where given 2 threads, the first one will get some time to execute, is then paused to give the second one some time to execute, unpaused to get some time etc.
As such, if two Threads executing doSomeThing() would be running on a single CPU, the following sequence of actions could occur:
// Code that both threads will execute:
counter += 1;
local_id = counter;
// -----------------------------------
// Thread 1
counter += 1; // after this, counter == 1
// Before Thread 1 can execute local_id = counter, it is paused by the CPU
// Thread 2
counter += 1; // after this, counter == 2
local_id = counter; // thus, in Thread 2, local_id is correctly 2
// Here, the CPU switches back to Thread 1
// Thread 1
local_id = counter; // now, local_id is still 2, instead of 1... mission failed
We can see that the exact problem we were trying to prevent can still occur, but it depends on how the threads are scheduled by the OS. This is what makes multithreaded programming so difficult in practice: your program can execute without problems 99 times, but still fail the next. These bugs can be very hard to reproduce. They are often called race conditions, referring to e.g., a car/horse race where it’s not always the same contestant that wins, depending on the conditions of the racetrack. Note that this does not only occur in the case of multiple threads on the same core: similar problems can of course also happen if you have actual parallel threads as well.
In general, we can see that once multiple threads start accessing shared memory, things can go wrong. As such, these specific points in a multithreaded program are often referred to as the critical section: it’s of the highest importance (critical) that this section is executed by itself, without outside interference. Otherwise, race conditions can occur and we can introduce bugs.
To make this all a bit more tangible, we will be using an outside interactive tool, called Deadlock Empire. Instead of having you write correct code for a problem, this website challenges you to find bugs in existing code to show the many caveats of multithreaded programming. While the website uses the C# programming language and is a bit different from the C syntax we’re using, the high-level concepts are 100% the same.
Go to the Deadlock Empire website and do:
- Tutorial: Tutorial 1: Interface
- Unsynchronized Code: Boolean Flags Are Enough For Everyone
- Unsynchronized Code: Simple Counter
Atomic operations
Now that you have a feeling for race conditions and critical sections, it’s time to make things worse.
The example above isn’t only vulnerable through the “local_id = counter” code: the “counter += 1” code is also vulnerable to a race condition. This is because incrementing a variable (counter += 1) is not a so-called atomic operation. This means that internally, it is not implemented with a single CPU instruction, but rather composed out of a series of different operations/instructions.
For example, for counter += 1, the series of executed steps might look like this:
- Fetch value of counter from RAM and store it in the CPU cache memory
- Fetch value from CPU cache memory and store it in a CPU register for the calculation
- Add 1 to the register value
- Write the register value back to the CPU cache
- Write the cached value back to the RAM
Put differently: the CPU does not act on the value stored in memory directly, but rather a copy in a register. Copying from/to a register is not atomic, so bugs can occur. To make things simpler to reason about, we can boil this down to just two lines of code:
// In simple pseudocode, counter += 1 might look like this:
int temp = counter + 1; // temp is for example the CPU register here, and "counter" is the value in memory
counter = temp; // the register value is written back out to the memory
To the CPU, all of these steps are one or more instructions, each of which can also have a certain delay associated with them. As such, what can happen in practice is the following sequence of events:
// Code that both threads will execute:
int temp = counter + 1;
counter = temp;
// -----------------------------------
// Thread 1
int temp = counter + 1; // after this, Thread 1's temp register contains the value 1. The "counter" value in RAM is still 0.
// Before Thread 1 can actually store this temporary register result in memory, the CPU gives control to Thread 2
// Thread 2
int temp = counter + 1; // "counter" was still 0 in RAM, so Thread 2's temp register now also contains the value 1
counter = temp; // The "counter" value in RAM is now 1
// Here, the CPU switches back to Thread 1
// Thread 1
counter = temp; // The "counter" value in RAM is still 1
We can see that, even though two “counter += 1” lines of code were executed, the resulting value in memory is just 1 instead of 2. Again: you probably never saw this when testing the exercise in the lab, but theoretically it -could- happen, leading to randomly failing programmes.
Note that this is a direct consequence of the fact that threads have separate program counters and register values, as discussed in the first Section on threads. Once individual threads are started, even if they are executing the same code, they do so in a partially separated context.
Go to the Deadlock Empire website and do:
- Tutorial: Tutorial 2: Non-Atomic Instructions
- Unsynchronized Code: Confused Counter
You might now think that this can only happen if two threads execute the exact same code. However, you would be wrong, as illustrated by the following example from Wikipedia:
// Thread 1
// ... other code
b = x + 5;
// ... other code
// Thread 2
// ... other code
x = 3 + z;
// ... other code
Give a practical, numerical example of how, depending on CPU scheduling, b can end up with two very different values.
Mutexes and Locking
As we’ve seen in many examples, things can go wrong really quickly when dealing with shared memory. Making matters worse, simple solutions (such as making thread-local copies of shared memory) are also doomed to fail eventually.
As such, it should be clear that we need a way to secure the critical sections in a thread. We need a way to make sure the OS will not pause a thread during a critical section, to make sure that all instructions are done before another thread gets execution time. Put differently: we need a way to turn groups of non-atomic operations into a single big atomic block.
The simplest way of doing this, is by means of a mutex. This term is a portmanteau of Mutual Exclusion. The behaviour can be seen as the lock on a toilet door. If you are using the toilet, you lock the door. Others that want to occupy the toilet have to wait until you’re finished and you unlock the door (and get out, after washing your hands). Hence, the mutex has only two states: one or zero, on or off, locked or unlocked.
Internally, a mutex lock is typically implemented by means of a single, atomic CPU instruction. Otherwise, simply locking or unlocking the mutex would of course potentially lead to the problems it is trying to solve!
The concept of a mutex is implemented in the pthreads library as a new variable type: pthread_mutex_t. Locking and unlocking can be done through functions pthread_mutex_lock() and pthread_mutex_unlock(). As always, read the documentation for the exact usage of these functions.
The problematic example of the shared counter can be rewritten using a mutex:
int counter;
pthread_mutex_t counter_lock; /* THIS LINE HAS BEEN ADDED */
void* doSomeThing(void *arg) {
unsigned long i = 0;
int local_id; /* THIS LINE HAS BEEN ADDED */
pthread_mutex_lock(&counter_lock); /* THIS LINE HAS BEEN ADDED */
counter += 1;
local_id = counter; /* THIS LINE HAS BEEN ADDED */
pthread_mutex_unlock(&counter_lock); /* THIS LINE HAS BEEN ADDED */
printf(" Job %d started\n", local_id); /* THIS LINE HAS BEEN CHANGED */
for(i=0; i<(0xFFFFFFFF);i++);
printf(" Job %d finished\n", local_id); /* THIS LINE HAS BEEN CHANGED */
return NULL;
}
This solves the issue that was encountered above. Before the counter is accessed, the mutex is locked. This provides exclusive access to the following 2-line critical section untill the mutex is unlocked again. The counter is then incremented and copied in to variable local_id. Finally, the mutex is unlocked.
With this measure in place, the result is as was originally intended.
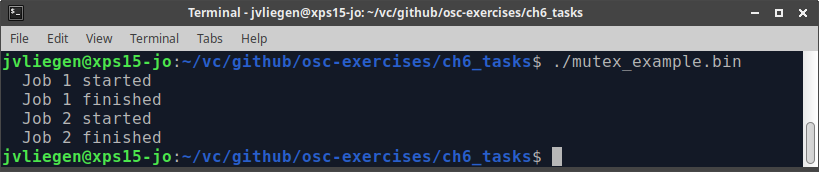
Note: The amount of code/instructions between locking and unlocking a mutex should of course be kept to a minimum. If you put a mutex around your entire threading function, you undo the entire possible benefit of using threads: the fact that they can run in parallel! As such, inter-thread communication via shared memory should be kept to a minimum, and only that should be protected using Mutexes/locks.
Go to the Deadlock Empire website and do:
- Locks: Insufficient lock
- Locks: Deadlock
Deadlocks
While locks help with many critical section problems, the Deadlock Empire examples above show that they are also not always trivial to apply correctly. This is especially the case if there is more than one shared resource/variable/memory region in play.
For example, a typical problem that can arise is when two threads need to obtain access to two different shared resources, but do so in opposite orders. This can for example happen in complex programs that often interact with outside peripherals like the hard disk and the network:
// Thread 1 wants to first read from the network, then write result to the hard disk
// Thread 2 wants to first read the contents of a file, then send it on the network
// Thread 1:
network.lock()
// CPU pauses Thread 1 and activates Thread 2
harddisk.lock()
// CPU pauses Thread 2 and activates Thread 1 again
harddisk.lock() // this will not complete, because Thread 2 is holding this lock already. Thread 1 has to wait
// CPU pauses Thread 1 because it has to wait and activates Thread 2 again
network.lock() // this will not complete, because Thread 1 is holding this lock already. Thread 2 has to wait
// Both threads are waiting endlessly AND also locking the network and the harddisk for any other threads that might arrive
Note: this example is not entirely realistic, as the network and harddisk can generally be used by multiple threads and processes concurrently. This is because the OS (or even the hardware itself) has layers of abstraction, but also complex ways of detecting and preventing deadlocks from happening (for extra information, see this presentation (this is not course material)). Still, you can pretty easily make this mistake in your own program when accessing multiple pieces of shared memory, so watch out!
Semaphores
While mutex locks are useful, the are also relatively simple and limited in what they can convey. As such, over time more advanced thread synchronization techniques have evolved that make it a bit easier to deal with often occurring scenarios. One such more advanced technique is a semaphore. A semaphore makes it easier to track how many threads are requesting access or have already been given access to a particular resource.
Producer-Consumer Problems
This technique is used in for example producer-consumer problems. There, one or more producer threads prepare data (in our exercises: prime numbers) and put it in a limited amount of shared memory spots (say an array of size 10), ready to be used by one or more consumers (in our exercises: a function that prints the prime numbers). This type of setup prevents us from having to allocate a large amount of memory up-front to communicate thread results (as we did in the solution to the last exercise in the previous lab).

A high-level visualization of a multi-producer + multi-consumer problem with a limited amount of shared memory in between.
In this setup, we don’t just want to lock access to the shared memory so only 1 producer or consumer can use it at a given time, we want to do more: we want the producers to only write data to the shared memory if there is an open spot. If not, they have to wait. Similarly, the consumers can only read data from shared memory if there is actually something there. If not, they have to wait.
Conceptually, we could do this by keeping track of a count of the amount of items currently in the shared array (items_in_array below), and increment/decrement that count inside a mutex lock when producing/consuming (similar to the global counter solution above):
// PSEUDOCODE!
mutex myLock;
int items_in_array = 0;
int* array = malloc(sizeof(int) * 10);
void* producer()
{
while (true)
{
bool itemStored = false;
Item item = produceItem();
while( !itemStored ) {
lock( myLock );
if( items_in_array < 10 ) {
array[ items_in_array ] = item;
items_in_array += 1;
itemStored = true;
}
unlock( myLock );
}
}
}
// PSEUDOCODE!
void* consumer()
{
while (true)
{
Item item = NULL;
lock( myLock );
if( items_in_array > 0 ) {
item = array[ items_in_array - 1 ];
items_in_array -= 1;
}
unlock( myLock );
if( item != NULL ) {
consumeItem(item);
}
}
}
This setup will work, however it is very inefficient: both the producers and the consumers are constantly trying to get a new lock on the array to check if they can produce/consume something, even if it’s only been a few milliseconds since they last checked (and found the array was full/empty and there was nothing to do). Imagine for example if the producers in the example are slow to produce new items, but the consumers are very fast: the consumers would constantly be re-locking the mutex to check if something new is available, even though there rarely is, causing the mutex to be almost immediately unlocked again. This type of behaviour is often called busy waiting or polling and is bad for performance as you’re doing a lot of unnecessary work.
Instead, a better solution would be that a thread that wants to read/write an item from/to the array can only do so if it is actually possible. If not, the thread should be paused until it’s sure that it can make progress, instead of constantly checking. To do this, we need a new type of lock that keeps track of who’s waiting for what to happen, which is called the semaphore.
Semaphore concepts
In essence, the semaphore is nothing more than a counter (the items_in_array from above), but one that can automatically pause/resume threads that use it if the counter is zero/becomes positive (while above, we had to do this manually).
This is typically done using three conceptual functions on the semaphore:
init( mySemaphore, count ): Start the semaphore value atcount(can be either 0 or a positive number).wait( mySemaphore ): Continues if mySemaphore is > 0 and decrements it by 1. If not, it pauses the current thread until mySemaphore becomes positive.post( mySemaphore ): Increments mySemaphore by 1. This then automatically causes 1 of the waiting threads (if any) to be unpaused.
As you can see, multiple threads can be waiting on the same semaphore (determined by the count passed in init()). For each time a post() is done however, only 1 of the waiting threads can of course be unpaused. The OS determines which thread is chosen from among the waiters and can do so in many different ways (for example thread that has been paused the longest, thread that has been paused the shortest, thread that was most recently started, the thread with the highest priority, etc.). More information on this is given in Chapter 7 (Scheduling).
To illustrate this, a semaphore can be thought of as a bowl with tokens. For example, in a child daycare there can be a room with toys:

A photo of Cafe Boulevard (courtesy of Tripadvisor)
Only 5 children are allowed in that room. Outside, there is a bowl with bracelets (init( braceletBowl, 5 )). When a child wants to enter the room to play, they need to take a bracelet and put it on (wait( braceletBowl )). When there are no more bracelets in the bowl, a child that also wants to play in the room has to wait (also wait( braceletBowl )) until another child leaves the room and places their bracelet back in the bowl (post( braceletBowl )).
Using semaphores then, we can more optimally re-write the producer-consumer setup from above. Note however that we can’t just use a single semaphore, since the wait/post functions really only allow us to wait if the value is 0, not if the value is for example 10 (the maximum size of the array). As such, we need two: one to indicate how much slots are filled, and one to indicate how many are empty:
// PSEUDOCODE!
mutex myLock;
semaphore fill_count;
init(fill_count, 0);
semaphore empty_count;
init(empty_count, 10);
int items_in_array = 0;
int* array = malloc(sizeof(int) * 10);
void* producer()
{
while (true)
{
Item item = produceItem();
wait( empty_count ); // THIS IS NEW!
lock( myLock );
array[ items_in_array ] = item;
items_in_array += 1;
unlock( myLock );
post( fill_count ); // THIS IS NEW!
}
}
// PSEUDOCODE!
void* consumer()
{
while (true)
{
Item item = NULL;
wait( fill_count ); // THIS IS NEW!
lock( myLock );
item = array[ items_in_array - 1 ];
items_in_array -= 1;
unlock( myLock );
post( empty_count ); // THIS IS NEW!
consumeItem(item);
}
}
It might seem strange to you that when using semaphores, we still ALSO need a mutex when actually writing to/reading from the shared array. Can you explain why this is needed? Can you explain why we’re using semaphores in the first place then, if they don’t even allow us to remove the mutex?
When using a Semaphore with an initial value higher than 1, multiple threads can still "enter" the semaphore at the same time (this is exactly one of the reasons to use a semaphore after all!). The amount of simultaneous threads is just limited by the Semaphore value.
As such, we still need to protect the critical section inside the semaphore block if it accesses shared memory, or we would again have race conditions!
We see that using semaphores is indeed not done to remove the mutex, but rather to remove the busy waiting while() loop and the custom checks if the array is full/empty. Compare the semaphore version with the pure-mutex version and you'll see we were able to actually get rid of quite some code + we're no longer constantly locking/unlocking the mutex!
Note that, if we initialize the Semaphore with a value of 1 (init( mySemaphore, 1 )), we basically get a mutex! After all, only a single thread can be active inside the semaphore at any given time then, leading to the same behaviour as a mutex. This is then typically referred to as a binary semaphore.
In this setup, we of course don’t need another mutex inside the semaphore block, since we’re already getting that guarantee from the binary semaphore.
This is sometimes used if the size of the shared memory is just a single item, often referred to as a “shelf” (see also later exercises and the threading assignment), to prevent having to keep a manual counter variable alongside a mutex (the binary semaphore is mutex and counter all-in-one!).
More info on the differences between a semaphore and a mutex are given here.
Go to the Deadlock Empire website and do:
- Semaphores: Semaphores
- Semaphores: Producer-Consumer
- Semaphores: Producer-Consumer (Variant)
Semaphores in C and pthreads
The pthreads library provides an API to program with semaphores in C (include semaphore.h to use). It contains the semaphore_t type and, amongst others, these functions (which are the same as discussed previously):
sem_init(): initialises a semaphore.sem_wait(): waits until the semaphore is positive, then decrements the number inside of the semaphore.sem_post(): increments the number inside of the semaphore and unpauses one of the waiting threads (if any). (note: in other programming languages, this operation is often calledsignalinstead ofpost)sem_destroy(): destroys the semaphore when it’s no longer needed.
There is also a “non-pausing” alternative to sem_wait: sem_trywait(). This variant will only decrement the semaphore if it’s positive. If it’s zero, it won’t pause the current thread. Additionally, this function returns the current value of the semaphore, which allows us to really use it as a replacement for a counter! See the manual pages and search Google for more info and the correct usage of this version!
Note that next to mutexes and semaphores, there are many other thread synchronization utilities and concepts (such as for example “conditional variables”, “monitors” and “barriers”). Especially more modern programming languages like Java, C#, Rust, and Go typically have highly advanced threading options built-in. Some of these you can (optionally) explore and experiment with using the exercises from Deadlock Empire that we skipped.