Tuning
De latency is de tijd die er nodig is tussen het starten van een operatie en het verkrijgen van het resultaat.
De throughput is de hoeveelheid bits die een operatie verwerkt in een gegeven tijdseenheid.
De cost is de kost van een ontwerp. Hoe meer componenten, hoe meer oppervlakte er ingenomen wordt op chip, en hoe duurder het ontwerp wordt.
Het kritische pad is het langste combinatorische pad tussen 2 registers/flip-flops.
Design in de Hack Processor
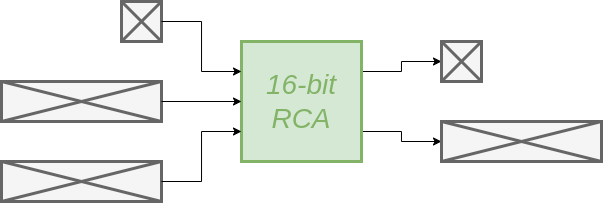
De latency is 1 clock cycle. Als we aannemen dat het kritische pad de ripple carry is en dat de minimale klok periode 2 ns is, dan is de latency = 2ns.
Aangezien er iedere clock cycle een optelling gedaan kan worden, is
de througput = 8 Gbps (= 16 bits / 1CC = 16 bits / 2 ns = 16 / (2 * 10-9) bits/s = 8 x 109 bits / s )
Halvering van de breedte
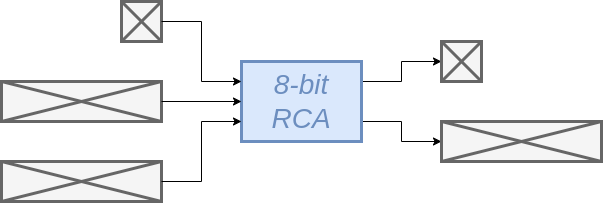
De latency is 1 clock cycle. Als we aannemen dat het kritische pad de ripple carry lineair mee krimpt, wordt de minimale klok periode 1 ns is en dan is de latency = 1ns.
Aangezien er iedere clock cycle een optelling gedaan kan worden, is
de througput = 8 Gbps (= 8 bits / 1CC = 8 bits / 1 ns = 8 x 109 bits / s )
Unrolled
De latency is 1 clock cycle. Als we aannemen dat het kritische pad de ripple carry niet wijzigt, dan is de latency = 2ns.
Aangezien er iedere clock cycle een optelling gedaan kan worden, is
de througput = 8 Gbps (= 16 bits / 1CC = 16 bits / 2 ns = 16 / (2 * 10-9) bits/s = 8 x 109 bits / s )
Pipelined
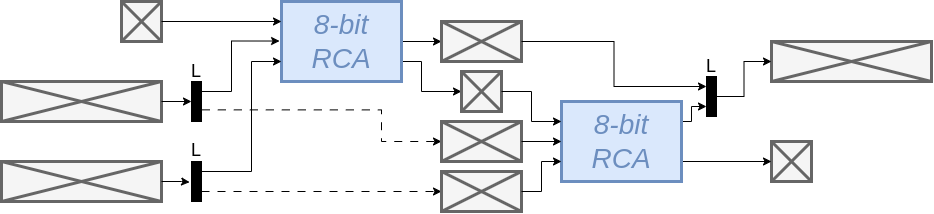
De latency is 2 clock cycles. Als we aannemen dat het kritische pad de ripple carry lineair mee krimpt, wordt de minimale klok periode 1 ns is en dan is de latency = 2ns.
Aangezien er, bij een volled pipeline, iedere clock cycle een optelling gedaan kan worden, is
de througput = 16 Gbps (= 16 bits / 1CC = 16 bits / 1 ns = 16 / (1 * 10-9) bits/s)
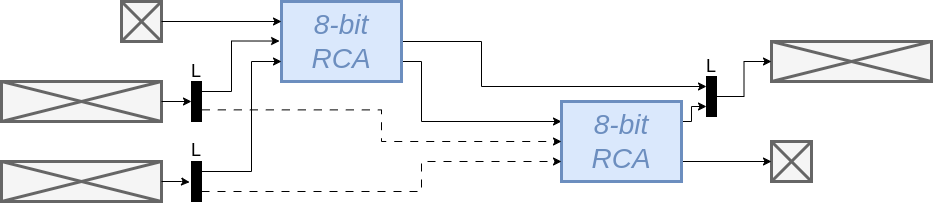
Sequential
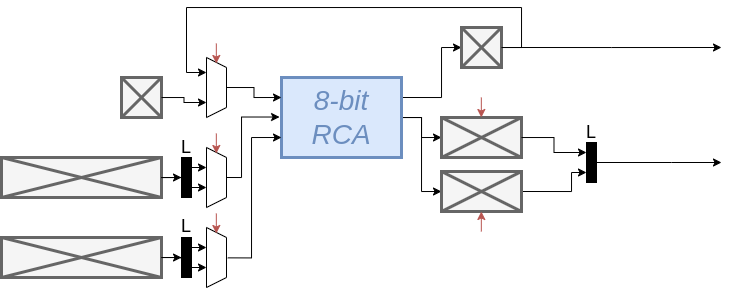
De latency is 2 clock cycles. Als we aannemen dat het kritische pad de ripple carry lineair mee krimpt, wordt de minimale klok periode 1 ns is en dan is de latency = 2ns.
Aangezien er iedere 2 clock cycles een optelling gedaan kan worden, is
de througput = 8 Gbps (= 16 bits / 2CC = 16 bits / 2 ns = 16 / (2 * 10-9) bits/s = 8 x 109 bits / s )
Samenvatting
| 16-bit | 8-bit | Unrolled | Pipelined | Sequential | |
|---|---|---|---|---|---|
| Tmin [ns] | 2 | 1 | 2 | 1 | 1 |
| Latency [CC] | 1 | 1 | 1 | 2 | 2 |
| Latency [ns] | 2 | 1 | 2 | 2 | 2 |
| Throughput [Gbps] | 8 | 8 | 8 | 16 | 8 |
| Aantal FF | 3x16 + 2x1 = 50 | 3x8 + 2x1 = 26 | 3x16 + 2x1 = 50 | (3x16 + 2x1) + (3x8 + 1x1) = 75 | 2x16 + 2x1 + 2x8 = 50 |
| Kan 16-bit optelling | ✓ | ✗ | ✓ | ✓ | ✓ |
| Extra controle pad | ✗ | ✗ | ✗ | ✓ | ✓ |
| Fmax [MHz] | 500 | 1000 | 500 | 1000 | 1000 |
- De resultaten van de 8-bit versie zijn louter voor de volledigheid;
- Unrolled geeft geen meerwaarde in dit geval
- Pipelined geeft betere throughput en klok snelheid, ten kosten van extra oppervlakte
- Sequential geeft betere klok snelheid, ten kosten van extra controle-logica
Functionaliteit, kost, performantie … Je kan voor maximaal 2 prioriteiten optimaliseren, maar niet voor alle prioriteiten.