In dit opleidingsonderdeel (SES) leer je de nodige skills om een softwareproject op de wereld te brengen volgens de regels van de kunst en met het aandacht voor de courante industriële praktijk.
We besteden aandacht aan software development tools en de moderne software development lifecycle, alsook programmeer- en ontwerpvaardigheden.
Het eerste deel van dit vak (software development tools and practices) wordt ook gevolgd door de studenten elektronica (EA) als deel van het vak Electronic Engineering Skills (EES).
Cursusmateriaal
We trachten al het cursusmateriaal voor deze cursus te bundelen op deze website.
Deze wordt doorheen het jaar aangevuld.
Voor sommige delen vind je ook nog slides op Toledo.
Deel 1: Software Development Tools and Practices (SES+EES)
In dit deel leer je werken met enkele moderne tools en onmisbare praktijken voor software-ontwikkeling:
Terminal en IDE (Linux/WSL, VS Code)
Versie- en issuebeheer (Git en GitHub)
Dependency Management en build tools (gradle, makefiles)
Test-Driven Development (TDD) en debugging
Continuous integration en continuous deployment (CI/CD)
Processen (SCRUM)
Deel 2: Programmer- en ontwerpvaardigheden (SES)
In dit deel scherpen we je programmeervaardigheden verder aan, verderbouwend op Software-ontwerp in Java.
Advanced Java
Hier behandelen we enkele geavanceerde (en recent toegevoegde) concepten uit Java.
Gelijkaardige concepten bestaan vaak ook in andere programmeertalen.
Records
Generics
Lambda-functies
Streams
Recursie en backtracking
Recursie en backtracking zijn krachtige tools om complexe problemen op te lossen.
We leren hoe na te denken over recursie, alsook templates voor typische backtracking-problemen.
Specificatie en contracten
In dit hoofdstuk bekijken we hoe je softwaregedrag precies kan beschrijven los van de concrete code:
specificaties, contracten (pre- en postcondities), invarianten, en de link met testen en formele redeneringen.
Software ontwerpprincipes
We bekijken enkele software ontwerpprincipes die helpen om grotere projecten goed te structureren,
zodat het onderhouden ervan eenvoudiger wordt.
Syllabus
Lesgevers:
Coördinerend Verantwoordelijke: Prof. dr. ir. Koen Yskout
Onderwijsassistent: ing. Arne Duyver
Voor EES: Prof. dr. ing. Kris Myny
Kantoor: Technologiecentrum Diepenbeek, Groep ACRO.
Het materiaal op deze website bouwt voort op materiaal van Dr. ing. Wouter Groeneveld en Prof. dr. Kris Aerts.
Vereiste voorkennis
Het vak ‘Software Ontwerp in Java’ (INF1) dient eerst gevolgd te worden. We gaan uit van een basiskennis Java en object-georiënteerd programmeren. Een snelle opfrissing van Java kan je vinden in de bijlagen.
Beoordeling en evaluatie
Schriftelijke evaluatie tijdens onderwijsperiode: 50%.
Zie elke sectie ‘meer leermateriaal’ voor extra materiaal per thema.
Dit extra materiaal wordt aangeboden ter illustratie of verdieping voor de geïnteresseerde student, en is geen deel van de leerstof.
De inhoud van deel 1 wordt gevolgd door de studenten SES en EES.
1. Windows Subsystem for Linux en VSCode
In deze cursus gebruiken we Windows Subsystem for Linux (WSL) als besturingssysteem en Visual Studio Code (VSCode) als code-editor. Dit zorgt ervoor dat iedereen met dezelfde tools werkt. Al het lesmateriaal en alle opdrachten zijn gebaseerd op deze omgeving.
Subsecties van 1. Windows Subsystem for Linux en VSCode
Windows Subsystem for Linux (WSL)
Besturingssystemen: introductie
Voor we met de echte materie kunnen starten moeten we eerst wat meer kennis vergaren over hoe computers juist werken. Je zal dit nog met meer diepgang bespreken in het vak ‘Besturingssystemen en C’, maar we geven toch al een korte intro zodat je weet waar we mee bezig zijn.
Wat is een besturingssysteem? (Besturingssysteem = Operating System = OS)
Een besturingssysteem (OS) is een essentieel onderdeel van de computerarchitectuur dat fungeert als een brug tussen de hardware van een computer en de gebruiker. Het beheert de hardwarebronnen van de computer en biedt een omgeving waarin applicaties kunnen draaien. Zonder een besturingssysteem zou een computer niet functioneel zijn voor de meeste gebruikers.
Het besturingssysteem voert verschillende cruciale taken uit:
hardwarecomponenten (CPU, geheugen …) besturen;
een platform voorzien waar software/applicaties op kunnen draaien;
een gebruikersinterface voorzien;
beheren van processen;
input en output apparaten beheren;
applicaties beheren;
veiligheid beheren.
Dit betekent dat het OS bijvoorbeeld bepaalt welke processen toegang hebben tot welke bronnen en wanneer. Dit beheer is essentieel om ervoor te zorgen dat de computer efficiënt en effectief werkt. We gaan vooral even dieper in hoe het OS applicaties beheert en kan starten/stoppen.
Daarnaast biedt het besturingssysteem een gebruikersinterface, die kan variëren van een command-line interface (CLI) tot een grafische gebruikersinterface (GUI). Deze interface stelt gebruikers in staat om met de computer te interageren. Je bent waarschijnlijk al zeer bekend met de GUI. Tijdens de lessen SES gaan we ons echter focussen op het interageren met de computer via de CLI.
Nog ander belangrijk aspect van een besturingssysteem is het beheer van bestanden. Het OS organiseert en bewaart bestanden op een manier die gemakkelijk toegankelijk en veilig is. Dit omvat het beheren van lees- en schrijfrechten, het organiseren van bestanden in mappen en het zorgen voor gegevensintegriteit. Dit komt later nog aan bod wanneer we het hebben over het beheer van applicaties en het commando chmod.
Zoals hierboven al vermeld, biedt het besturingssysteem een platform voor het uitvoeren van applicaties. Het zorgt ervoor dat applicaties de benodigde bronnen krijgen en dat ze geïsoleerd zijn van elkaar om conflicten en beveiligingsproblemen te voorkomen. Dit maakt het mogelijk om meerdere applicaties tegelijkertijd te draaien zonder dat ze elkaar storen.
In samenvatting, een besturingssysteem is een complex maar essentieel onderdeel dat de functionaliteit en bruikbaarheid van computers mogelijk maakt.
Voorbeelden van besturingssystemen:
Windows
Linux
Mac OS
FreeRTOS
Van de voorbeelden hierboven kunnen Linux en Mac OS nog gegroepeerd worden tot de zogenaamde UNIX-besturingssystemen omdat ze beide gebaseerd zijn op de principes en architectuur van het oorspronkelijke UNIX-systeem. De CLI werkt bij zowel Linux als Mac OS gelijkaardig, en dit is grotendeels te danken aan hun gemeenschappelijke UNIX-basis.
De CLI is een tekstgebaseerde interface waarmee gebruikers commando’s kunnen invoeren om taken uit te voeren op een computer. In tegenstelling tot GUI’s, waarbij gebruikers met muis en vensters werken, vereist de CLI dat gebruikers tekstcommando’s typen.
Hoewel GUI’s tegenwoordig veel gebruiksvriendelijker zijn voor de meeste gebruikers, blijft de CLI een krachtig hulpmiddel voor specifieke taken zoals taken die efficiëntie, automatisering en flexibiliteit vereisen.
Info
Daarenboven bestonden in de beginjaren van de computertechnologie nog geen GUI’s. Computers werden voornamelijk bediend via de CLI. Dit was de standaard manier om met computers te communiceren, omdat de hardware en software van die tijd niet krachtig genoeg waren om grafische interfaces te ondersteunen. Dus zeker in low-end devices blijft de CLI een essentiële tool.
Volgende termen houden verband met de CLI en worden soms (incorrect) door elkaar gebruikt:
Terminal: Een terminal is een apparaat of softwaretoepassing die communicatie tussen de gebruiker en het besturingssysteem mogelijk maakt via de CLI. In de context van moderne computers is een terminal meestal een softwaretoepassing die een CLI-omgeving biedt.
Terminal Emulator: Een terminal emulator is een softwaretoepassing die de functionaliteit van een traditionele hardwareterminal nabootst. Het stelt gebruikers in staat om een terminalsessie te openen binnen een grafische omgeving en zorgt voor een omgeving waarin een shell kan draaien. Voorbeelden van terminal emulators zijn GNOME Terminal, Konsole en Terminator.
Shell: Een shell is een programma dat de CLI biedt en de interpretatie van de ingevoerde commando’s verzorgt. Het fungeert als een interface tussen de gebruiker en het besturingssysteem. De shell ontvangt commando’s van de gebruiker, voert ze uit en geeft de output terug.
Bash: Bash (Bourne Again Shell) is een veelgebruikte UNIX-shell die vaak standaard wordt geleverd met Linux-distributies. Bash biedt krachtige scriptingmogelijkheden en een breed scala aan ingebouwde commando’s, waardoor het een populaire keuze is voor zowel systeembeheer als ontwikkeling.
Zsh: Zsh (Z Shell) is een andere UNIX-shell die bekend staat om zijn uitgebreide functies en configuratiemogelijkheden. Het biedt verbeterde autocompletion, betere scriptingmogelijkheden en een meer aanpasbare omgeving in vergelijking met Bash. Veel gebruikers kiezen voor Zsh vanwege de extra functionaliteit en flexibiliteit.
PowerShell: PowerShell is een shell ontwikkeld door Microsoft voor Windows. Het combineert de traditionele CLI met een krachtige scriptingtaal gebaseerd op .NET. PowerShell is ontworpen voor systeembeheer en automatisering, en biedt uitgebreide mogelijkheden voor het beheren van Windows-systemen.
De verschillende shells gebruiken vaak ook verschillende commando’s voor een gelijkaardige functionaliteit. Zo kan je met het commando pwd de inhoud van een folder/directory weergeven in Bash, terwijl in vroegere versies van PowerShell het commando dir voor gebruikt werd.
Verschillende terminal emulators hebben bijvoorbeeld verschillende manieren om tekst te copy en pasten in de terminal.
Software programma’s / applicaties
Enkele belangrijke termen:
Hardware: Hardware is de fysieke machine.
Software: Software is een programma dat op hardware draait.
Programma: Een programma is een reeks instructies (in alle vormen en maten). Een software programma is dus een reeks computer instructies.
Proces: Een proces is een programma dat in het geheugen is geladen van het computersysteem en wordt beheert door het besturingssysteem.
Applicatie: Een programma dat is ontworpen voor de eindgebruiker voor een specifiek doel. Sommige programma’s zijn algemeen van aard, zoals een besturingssysteem, anderen hebben een specifiek doel zoals tekstverwerking (Word) of draaien niet voor de eindgebruiker maar op de achtergrond (zoals een applicatie dat de hardware monitort).
In het dagelijkse leven is een gebruiker dus vooral aan het interageren met verschillende applicaties op de computer. Je kan applicaties installeren, updaten of deïnstalleren.
Als ingenieur of software ontwikkelaar zal je zelf programma’s schrijven of zelfs volledige applicaties en kan het soms nodig zijn om dieper in te gaan in de processen die bezig zijn op je computer.
Hoe een applicatie installeren?
Ten eerste zal je voor de meeste applicaties administrator rechten nodig hebben om een applicatie te installeren. Via een GUI krijg je dan vaak een pop-up, met behulp van de CLI kan je in Windows bijvoorbeeld simpelweg PowerShell met administrator rechten starten. In Linux kan je een commando uitvoeren als “super user” met het commando sudo wat staat voor “super user do”.
1. Executables downloaden
De meeste onder jullie hebben ooit al wel een applicatie gedownload en geïnstalleerd op je computer. Hiervoor heb je waarschijnlijk een .exe file gedownload van het internet op Windows. Dubbelklikken op die file start een process dat alle nodige bestanden installeert met het belangrijkste bestand dat op zichzelf weer een .exe file is. EXE staat dan ook voor “executable” of “iets dat uitgevoerd kan worden”. Door op die laatste file te klikken start je dan meestal je applicatie. Menu iconen en Desktop iconen zijn dan meestal gewoon een link naar die specifieke .exe file die op een speciale plaats op je computer is opgeslagen.
2. Een package manager gebruiken
In een CLI omgeving gaan we echter nergens op kunnen klikken. We gaan hier dan vaak gebruik maken van een package manager die in een online repository op zoek gaat naar de gewilde applicatie en hier dan automatisch de correcte bestanden van gaat downloaden op de juiste plaats. Een package manager is een softwaretool die helpt bij het installeren, updaten, configureren en verwijderen van softwarepakketten op een computer. Voordelen van een package manager zijn:
Efficiëntie: Bespaart tijd en moeite bij het installeren en beheren van software.
Betrouwbaarheid: Zorgt ervoor dat alle benodigde afhankelijkheden correct worden geïnstalleerd.
Beveiliging: Helpt bij het up-to-date houden van software, wat belangrijk is voor beveiligingspatches en bugfixes.
Gemak: Maakt het eenvoudig om software te vinden, installeren en verwijderen met eenvoudige commando’s. Je kan namelijk met één commando alle applicaties op je computer updaten naar de nieuwste versie.
Populaire package managers zijn:
Apt voor Ubuntu (Linux)
Homebrew voor Mac OS
Chocolatey voor Windows
3. Een fully contained package gebruiken
Er bestaan ook volledig voorverpakte software bestanden. In dat geval zit alles wat nodig is om de applicatie te runnen in één bestand. Dit worden ook wel mobiele applicaties genoemd omdat je ze makkelijk op een usb stick kan zetten en op verschillende computers kan gebruiken zonder dat een volledige installatie nodig is. Een voorbeeld hiervan is “Balena Etcher”. Snap packages en flatpacks zijn hiervan voorbeelden voor Linux.
4. Een applicatie bouwen vanuit de bronbestanden
Je kan ook de bronbestanden/broncode van sommige software downloaden en dan de applicatie zelf bouwen. Hiervoor heb je echter de juiste build tools voor nodig, de juiste dependecies, moet je de bestanden op de juiste plaats zetten … Dit kost veel moeite voor de gebruiker en leidt vaak tot errors waardoor we deze manier liefst niet gebruiken. Soms is er echter geen andere mogelijkheid.
Waar worden de nodige bestanden voor de applicatie bewaard?
Een applicatie bestaat vaak uit meerdere onderdelen/bestanden die tijdens het installeren op je computer gezet worden (behalve in fully contained packages, want daar zitten juist alle nodige bestanden in één bestand), maar waar worden deze dan gezet zodat je deze later kan gebruiken?
In Windows heb je waarschijnlijk al eens gekeken in C:\\Program Files, wat meestal de default locatie is voor applicaties. In deze directory wordt er per applicatie meestal een map aangemaakt waar de nodige bestanden inkomen. In Linux worden de meeste executables geplaatst in /usr/bin of /usr/local/bin. In Mac OS worden applicaties meestal geïnstalleerd in de Applications-map, die zich in de root van het bestandssysteem bevindt.
Hoe een applicatie starten?
Je kan natuurlijk gewoon dubbelklikken op het icoontje of de executable file zoals je waarschijnlijk altijd al gedaan hebt in een GUI. Dit kan wel weer niet in een CLI omgeving. Hiervoor gebruiken we de naam van de executable file. Als ik in mijn huidige directory een executable heb staan met de naam myprogram, dan kan ik deze applicatie/dit commando simpelweg uitvoeren door de naam in te typen in de CLI. Ik kan echter ook applicaties starten met hun commandonaam die niet in deze specifieke folder zitten. Het OS heeft namelijk een lijst met alle folders waar die moet gaan zoeken naar commando’s. Die lijst staat opgeslagen in de PATH-variabele.
Virtual Machines en WSL
Een virtual machine (VM) is een software-emulatie van een fysieke computer die een besturingssysteem en applicaties kan draaien alsof het een echte machine is. VM’s maken gebruik van hypervisors om de hardwarebronnen van een fysieke hostmachine te verdelen en te isoleren, waardoor meerdere virtuele machines tegelijkertijd op dezelfde fysieke hardware kunnen draaien.
Normal computer (left) VS VM's on host (right)
Het principe van virtual machines bestaat al lange tijd en kan soms ingewikkeld zijn om op te zetten, vooral op Windows. Daarom heeft Windows onlangs een ingebouwde oplossing geïntroduceerd genaamd het Windows Subsystem voor Linux (WSL). WSL biedt een Linux-omgeving binnen Windows, waarbij WSL 2 gebruikmaakt van een lichte virtuele machine met een volledige Linux-kernel, wat zorgt voor betere prestaties en integratie dan traditionele VM’s.
Wij gaan de Linux distributie Ubuntu versie 24.04 gebruiken in deze cursus. Een Linux distributie is een complete verzameling van software die een Linux-kernel bevat, samen met een reeks tools, bibliotheken en applicaties die nodig zijn om een volledig functioneel besturingssysteem te vormen. Elke distributie is samengesteld en geoptimaliseerd voor verschillende doeleinden en gebruikersgroepen. Linux distributies verschillen van elkaar op gebied van verschillende aspecten, waaronder: package manager, desktop omgeving, vooraf geïnstalleerde software en tools … Populaire Linux distributies zijn: Ubuntu, Debian, Pop OS, Fedora, Debian, Linux Mint, Arch Linux …
Wij kiezen voor Ubuntu voor de gebruiksvriendelijkheid, community en ondersteuning, softwarebeschikbaarheid, regelmatige update.
Voor Windows 10 version 2004 en hoger is het commando wsl normaal al geïnstalleerd. Je kan dit testen door Terminal of PowerShell te openen en het commando wsl --version in te geven. Krijg je een antwoord terug zonder error dan werk WSL. Je kan nu het volgende commando gebruiken om Ubuntu 24.04 te installeren: wsl --install -d Ubuntu-24.04. Na de installatie wordt je meteen in de VM gegooid en moet je een username en password meegeven. Zorg ervoor dat je deze onthoudt! Je kan via WSL meerdere WMs tegelijkertijd installeren op je computer, daarom zetten we Ubuntu even als de default via het commando wsl --set-default Ubuntu-24.04. Wanneer je nu de Windows applicatie WSL opent zal je rechtstreeks in de CLI omgeving van Ubuntu terecht komen. Hier gaan we voorlopig het grootste deel van onze tijd doorbrengen.
Klik hier om voorbeeld output te zien/verbergen🔽
PS C:\Users\u0158802> wsl --install -d Ubuntu-24.04
Installing: Ubuntu 24.04 LTS
Failed to install Ubuntu-24.04 from the Microsoft Store: The Windows Subsystem for Linux instance has terminated.
Attempting web download...
Downloading: Ubuntu 24.04 LTS
Installing: Ubuntu 24.04 LTS
Ubuntu 24.04 LTS has been installed.
Launching Ubuntu 24.04 LTS...
Installing, this may take a few minutes...
Please create a default UNIX user account. The username does not need to match your Windows username.
For more information visit: https://aka.ms/wslusers
Enter new UNIX username: arne
New password:
Retype new password:
passwd: password updated successfully
Installation successful!
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root"for details.
Welcome to Ubuntu 24.04 LTS (GNU/Linux 5.15.167.4-microsoft-standard-WSL2 x86_64) * Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/pro
System information as of Mon Feb 10 17:20:37 CET 2025 System load: 0.62 Processes: 53 Usage of /: 0.1% of 1006.85GB Users logged in: 0 Memory usage: 12% IPv4 address for eth0: 172.29.161.86
Swap usage: 0%
This message is shown once a day. To disable it please create the
/home/arne/.hushlogin file.
arne@LT3210121:~$
WSL starten, stoppen
Je kan WSL ook starten vanuit een Windows CLI tool zoals Terminal of Powershell met het commando wsl. Om dan uit je WSL te raken en terug in de host versie van de CLI gebruik je het commando exit.
Overzicht commando’s:
>wsl--version>wsl--install-d[distributie naam]>wsl--set-default[distributie naam]# binnenin WSL gebruik je `exit` om terug naar de host te keren$exit
Connectie tussen host en VM
Eén van de handige functies van het WSL is de naadloze integratie tussen de WSL-omgeving en de Windows-host. Dit betekent dat je eenvoudig bestanden kunt bekijken en bewerken die zich op je Windows-bestandssysteem bevinden vanuit de WSL-omgeving, en omgekeerd.
filesystem Windows vs Linux
Er is nog een vrij groot verschil tussen het bestandssysteem van Windows en Linux en kan invloed hebben op hoe je met bestanden en mappen werkt.
De root/hoofd directory in Windows is meestal een specifieke schijf, zoals C:\. Elke schijf of partitie heeft zijn eigen root, bijvoorbeeld D:\ voor een tweede schijf.In Linux is er één enkele root directory aangeduid met /.
Windows gebruikt backslashes ‘' om directories te scheiden, bijvoorbeeld C:\Users\Gebruiker\Documents. Linux gebruikt forward slashes ‘/’ voor hetzelfde doel, bijvoorbeeld /home/gebruiker/documents.
In Windows zijn bestandsnamen niet hoofdlettergevoelig. Document.txt en document.txt worden als hetzelfde bestand beschouwd. Linux is wel hoofdlettergevoelig.
In Windows worden schijven en partities aangeduid met letters zoals C:\, D:\. In Linux worden schijven en partities gekoppeld aan directories binnen het filesystem, zoals /mnt/c voor de C-schijf.
Info
Een directory is een locatie op een filesystem waar bestanden (= files) en andere directories (subdirectories) kunnen worden opgeslagen. Het fungeert als een container die helpt bij het organiseren en structureren van bestanden op een computer.
Hoewel er kleine verschillen kunnen zijn tussen de volgende termen, in de context waarin deze termen worden gebruikt, verwijzen ze allemaal naar hetzelfde concept: een locatie op een bestandssysteem waar bestanden en andere mappen kunnen worden georganiseerd: directory, folder, map.
files van VM op host en files van de host op de VM
Binnenin File Explorer (Verkenner) in Windows kan je de files van de WSL terugvinden op de locatie \\wsl$\Ubuntu-24.04 zoals op onderstaande afbeelding te zien is.
WSL bestandslocatie in File Explorer
In WSL vind je de bestanden van de Windows host in de directory /mnt/c.
De CLI gebruiken: essentiële UNIX commands
Dan kunnen we nu eindelijk aan het praktische deel beginnen. Dingen doen binnen in je WSL Ubuntu met behulp can CLI-commando’s. We gaan een reeks van veelgebruikte commando’s overlopen en bekijken. We gaan echter niet alle commando’s zien omdat er gewoon teveel zijn en ook niet voor elk commando elke optie die mogelijk is. Maar met alles wat we gaan overlopen zou je het grootste deel van je taken als een ingenieur in de CLI moeten kunnen uitvoeren.
We gebruiken een bash shell.
pwd - ‘print working directory’: Met dit commando output je je huidige directory in de terminal.
$ pwd# Voorbeeldarne@LT3210121:~$ pwd/home/arne
Je huidige directory is ook steeds terug te vinden tussen de : en de $ in de terminal. In het voorbeeld hierboven zie je dat de directory ~ is aangegeven. Dit is een synoniem voor de /home/$USER directory. (Voor de @ staat de ingelogde usernaam en tussen de @ en de : staat de naam van het apparaat)
echo: Met dit commando toon je de opgegeven tekst in de terminal.
Je kan op twee manieren een directory opgeven, namelijk met een relatief pad of een absoluut pad:
Een absoluut pad geeft de volledige locatie van een directory of bestand vanaf de root directory van het bestandssysteem. Het begint altijd met een / en specificeert de exacte locatie, ongeacht de huidige werkdirectory. (bijvoorbeeld: /home/arne/test)
Een relatief pad geeft de locatie van een directory of bestand ten opzichte van de huidige werkdirectory. Het begint niet met een /, maar met de naam van de directory of bestand. Relatieve paden zijn handig voor het navigeren binnen de huidige directorystructuur zonder de volledige padnaam te hoeven opgeven. (bijvoorbeeld: arne/test als je je in de /home directory bevindt) Bovendien zijn er nog twee speciale symbolen die je in padnamen kan gebruiken . en ..:
. verwijst naar de huidige directory. (bijvoorbeeld: ./arne/test als je je in de /home directory bevindt)
.. verwijst naar de bovenliggende directory (= parent directory). (bijvoorbeeld: ./arne/../arne/test als je je in de /home directory bevindt, waarbij je met .. terug naar de /home verwijst, de parent directory van /home/arne)
Voor de meeste commando’s kan je de tab-toets gebruiken om automatisch je text of commando’s te laten vervolledigen. Bijvoorbeeld voor directory of file namen … Als er meerdere mogelijkheden voor autocomplete zijn moet je tweemaal op de tab-toets drukken en dan krijg je een lijst te zien met alle mogelijkheden.
ls - ’list files’: Met dit commando lijst je de bestanden en directories in de huidige directory op.
$ ls
# Voorbeeldarne@LT3210121:~$ ls
test
Je kan meestal je commando meer specificeren met behulp van options en flags om extra functionaliteit toe te voegen of de uitvoer aan te passen. Bijvoorbeeld, het ls-commando in Linux wordt gebruikt om de inhoud van een directory weer te geven. Door opties en flags toe te voegen, kun je de uitvoer van ls aanpassen aan je behoeften. Zo geeft ls -l een gedetailleerde lijst weer met extra informatie zoals bestandsrechten, eigenaar en grootte, terwijl ls -a ook verborgen bestanden toont die normaal gesproken niet zichtbaar zijn. Je kunt ook meerdere opties combineren, zoals ls -la, om zowel een gedetailleerde lijst als verborgen bestanden weer te geven. Deze flexibiliteit maakt het mogelijk om commando’s nauwkeurig af te stemmen op specifieke taken en vereisten. Je hebt verder ook de optie om aan het ls commando een specifiek directory mee te geven waardoor het de inhoud van de meegegeven directory toont.
Klik hier om voorbeeld output te zien/verbergen🔽
# Voorbeeldarne@LT3210121:~$ ls -l
total 4drwxr-xr-x 2 arne arne 4096 Feb 10 23:01 test# Voorbeeldarne@LT3210121:~$ ls -a
. .aws .bash_history .bashrc .docker .profile .sudo_as_admin_successful
.. .azure .bash_logout .cache .motd_shown .skip-cloud-init-warning test# Voorbeeldarne@LT3210121:~$ ls -la
total 36drwxr-x--- 5 arne arne 4096 Feb 11 14:26 .
drwxr-xr-x 4 root root 4096 Feb 10 17:21 ..
lrwxrwxrwx 1 arne arne 26 Feb 11 14:26 .aws -> /mnt/c/Users/u0158802/.aws
lrwxrwxrwx 1 arne arne 28 Feb 11 14:26 .azure -> /mnt/c/Users/u0158802/.azure
-rw------- 1 arne arne 9 Feb 10 17:27 .bash_history
-rw-r--r-- 1 arne arne 220 Feb 10 17:21 .bash_logout
-rw-r--r-- 1 arne arne 3771 Feb 10 17:21 .bashrc
drwx------ 2 arne arne 4096 Feb 10 17:21 .cache
drwxr-xr-x 5 arne arne 4096 Feb 11 14:26 .docker
-rw-r--r-- 1 arne arne 0 Feb 11 14:26 .motd_shown
-rw-r--r-- 1 arne arne 807 Feb 10 17:21 .profile
-rw-r--r-- 1 arne arne 0 Feb 11 14:26 .skip-cloud-init-warning
-rw-r--r-- 1 arne arne 0 Feb 10 22:20 .sudo_as_admin_successful
drwxr-xr-x 2 arne arne 4096 Feb 10 23:01 test# Voorbeeldarne@LT3210121:~$ ls /mnt
c wsl wslg
In de output bovenaan van het commando ls -l krijg je meer info te zien over het bestandstype (d = directory, - = file …) en de eigenaarsrechten (r = can read, w = can write, x = can execute). De output bevat verschillende kolommen met belangrijke informatie.
De eerste kolom toont de bestandsrechten, die aangeven wie lees-, schrijf- en uitvoerrechten heeft voor het bestand (bijvoorbeeld -rw-r--r--). De rechten komen in 3 groeperingen van 3 waarvan de meest linkse de rechten van de eigenaar zijn, de middelste groepering de rechten van alle users in dezelfde groep als de eigenaar en de meest rechtse groepering de rechten van alle gebruikers op het systeem.
De tweede kolom geeft het aantal harde links naar het bestand weer.
De derde en vierde kolommen tonen respectievelijk de eigenaar en de groep waartoe het bestand behoort.
De vijfde kolom geeft de bestandsgrootte in bytes weer. De zesde kolom toont de datum en tijd van de laatste wijziging.
De laatste kolom geeft de naam van het bestand of de directory weer.
man - ‘manual’: Dit commando is een krachtig hulpmiddel in Linux om gedetailleerde informatie over andere commando’s en hun opties te vinden.
$ man [commando]# Voorbeeldarne@LT3210121:~$ man ls
LS(1) User Commands LS(1)NAME
ls - list directory contents
SYNOPSIS
ls [OPTION]... [FILE]...
DESCRIPTION
List information about the FILEs (the current directory by default). Sort entries alphabetically if none of
-cftuvSUX nor --sort is specified.
Mandatory arguments to long options are mandatory for short options too.
-a, --all
do not ignore entries starting with .
-A, --almost-all
do not list implied . and ..
--author
with -l, print the author of each file
-b, --escape
print C-style escapes for nongraphic characters
--block-size=SIZE
with -l, scale sizes by SIZE when printing them; e.g., '--block-size=M'; see SIZE format below
Manual page ls(1) line 1(press h forhelp or q to quit)
Door man te gebruiken gevolgd door de naam van een commando, zoals man ls, krijg je toegang tot de handleidingspagina voor dat commando (gebruik de pijltjes toetsen om te navigeren en ‘q’ om dit menu te sluiten). Deze pagina bevat uitgebreide informatie over wat het commando doet, welke opties en flags beschikbaar zijn, en hoe je ze kunt gebruiken. Bijvoorbeeld, door man ls in te voeren, zie je een lijst van alle beschikbare opties voor het ls-commando, zoals -l voor een gedetailleerde lijstweergave en -a om verborgen bestanden te tonen. Dit maakt het man-commando een onmisbaar hulpmiddel voor zowel beginners als gevorderde gebruikers om de volledige functionaliteit van Linux-commando’s te ontdekken en effectief te benutten.
touch: Met dit commando maak je een nieuw, leeg bestand aan of update je de timestamp van een bestaand bestand.
$ touch [bestandsnaam]# Voorbeeldarne@LT3210121:~$ touch test.txt
arne@LT3210121:~$ ls
test test.txt
rm - ‘rm [bestand]’: Met dit commando verwijder je het opgegeven bestand. Gebruik de -R (recursive) flag to delete entire directories.
$ rm [bestandsnaam]$ rm -R [directorynaam]# Voorbeeldarne@LT3210121:~$ ls
test test.txt
arne@LT3210121:~$ rm test.txt
arne@LT3210121:~$ ls
testarne@LT3210121:~$ rm -R testarne@LT3210121:~$ ls
arne@LT3210121:~$
nano: Met dit commando open je het opgegeven bestand in de nano-teksteditor. Aangezien nano een CLI teksteditor is, kan je niet gewoon klikken om de cursor te verplaatsen, op te slaan of te exitten. Gebruik hiervoor de pijltjestoetsen, Ctrl+o (= save, write out), Ctrl+x (= exit). Indien het bestand bestaat kan je het aanpassen en indien het bestand niet bestaat wordt het on save aangemaakt.
vim: Met dit commando open je het opgegeven bestand in de vim-teksteditor. Dit is een zeer speciale editor. Het belangrijkste dat je moet weten is dat je kan exiten met :q!+enter. Soms moet je eerst tweemaal op esc drukken. Meer info vind je hier.
$ vim [bestandsnaam]# Voorbeeldarne@LT3210121:~$ vim test.txt
...
cat - ‘cat [bestand]’: Met dit commando toon je de inhoud van het opgegeven bestand in de terminal.
$ cat [bestandsnaam]# Voorbeeldarne@LT3210121:~$ cat test.txt
Dit is een test file.
copy en paste: Dit zal voor verschillende terminal emulators anders zijn. In Windows terminal kan je simpelweg Ctrl+c en Ctrl+v gebruiken, in WSL kan je Ctrl+c gebruiken voor copy en rechtermuisklik voor paste en een andere veel gebruikte toetsencombinatie is Ctrl+Shift+c en Ctrl+Shift+v.
chown - ‘change ownership’: Met dit commando verander je de eigenaar van het opgegeven bestand.
$ sudo chown [gebruiker]:[groep][bestandsnaam]# Voorbeeldarne@LT3210121:~$ chown root:root test.txt
chown: changing ownership of 'test.txt': Operation not permitted
arne@LT3210121:~$ sudo chown root:root test.txt
[sudo] password for arne:
arne@LT3210121:~$ ls -l
total 8drwxr-xr-x 2 arne arne 4096 Feb 11 14:55 test-rw-r--r-- 1 root root 22 Feb 11 14:52 test.txt
Belangrijk
sudo - ‘sudo [commando]’: Met dit commando voer je een ander commando uit met verhoogde (superuser) rechten.
export: Met dit commando kun je omgevingsvariabelen instellen die beschikbaar zijn voor de huidige shell-sessie en alle sub-processen die vanuit deze shell worden gestart.
$ export[VARIABELENAAM]=[waarde]# Voorbeeldarne@LT3210121:~$ exportTEST=testwaarde
arne@LT3210121:~$ echo$TESTtestwaarde
# Er zijn ook al voorgedefinieerde variabelen zoals de huidige user ($USER)arne@LT3210121:~$ echo$USERarne
chmod - ‘change mode’: Met dit commando verander je de bestandsrechten van het opgegeven bestand. (+r,+w,+x,-r,-w,-x)
$ chmod [rechten][bestand]# Voorbeeldarne@LT3210121:~$ ls -l
total 8drwxr-xr-x 2 arne arne 4096 Feb 11 14:55 test-r--r--r-- 1 arne arne 22 Feb 11 14:52 test.txt
arne@LT3210121:~$ chmod -w test.txt
arne@LT3210121:~$ ls -l
total 8drwxr-xr-x 2 arne arne 4096 Feb 11 14:55 test-r--r--r-- 1 arne arne 22 Feb 11 14:52 test.txt
arne@LT3210121:~$ chmod +x test.txt
arne@LT3210121:~$ ls -l
total 8drwxr-xr-x 2 arne arne 4096 Feb 11 14:55 test-r-xr-xr-x 1 arne arne 22 Feb 11 14:52 test.txt
mv - ‘move’: Met dit commando verplaats of hernoem je een bestand of directory.
$ mv [bron][doel]# Voorbeeldarne@LT3210121:~$ mv ./test.txt ./test/test.txt
arne@LT3210121:~$ ls -l ./test
total 4-rw-r--r-- 1 arne arne 22 Feb 11 14:52 test.txt
cp - ‘cp [bron] [doel]’: Met dit commando kopieer je een bestand of directory naar een nieuwe locatie.
$ mv [bron][doel]# Voorbeeldarne@LT3210121:~$ cp ./test/test.txt ./test.txt
arne@LT3210121:~$ ls -l ./test
total 4-rw-r--r-- 1 arne arne 22 Feb 11 14:52 test.txt
arne@LT3210121:~$ ls -l
total 8drwxr-xr-x 2 arne arne 4096 Feb 11 16:27 test-rw-r--r-- 1 arne arne 22 Feb 11 16:29 test.txt
sudo apt update - APT staat voor Advanced Packaging Tool: Met dit commando vernieuw je de lijst van beschikbare applicatie packages en hun versies, maar installeert of verwijdert geen packages. sudo apt upgrade: Met dit commando installeer je de nieuwste versies van alle geïnstalleerde applicatie packages die kunnen worden bijgewerkt, zonder nieuwe packages te verwijderen. apt install: Met dit commando installeer je het opgegeven pakket op een Debian-gebaseerd systeem.
$ sudo apt install [packagenaam]# Voorbeeldarne@LT3210121:~$ sudo apt install curl
[sudo] password for arne:
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
curl is already the newest version (8.5.0-2ubuntu10.6).
curl set to manually installed.
The following package was automatically installed and is no longer required:
libllvm17t64
Use 'sudo apt autoremove' to remove it.
0 upgraded, 0 newly installed, 0 to remove and 2 not upgraded.
apt search - ‘apt search [pakket]’: Met dit commando zoek je naar een pakket in de pakketbronnen.
$ sudo apt search [zoekterm]# Voorbeeldarne@LT3210121:~$ sudo apt search curl
Sorting... Done
Full Text Search... Done
ario/noble 1.6-1.2build4 amd64
GTK+ client for the Music Player Daemon (MPD)ario-common/noble 1.6-1.2build4 all
GTK+ client for the Music Player Daemon (MPD)(Common files)cht.sh/noble 0.0~git20220418.571377f-2 all
Cht is the only cheat sheet you need
cl-curry-compose-reader-macros/noble 20171227-1.1 all
...
apt remove: Met dit commando verwijder je het opgegeven pakket van het systeem.
$ sudo apt remove [packagenaam]# Voorbeeldarne@LT3210121:~$ sudo apt remove curl
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following packages were automatically installed and are no longer required:
libcurl4t64 libllvm17t64
Use 'sudo apt autoremove' to remove them.
The following packages will be REMOVED:
curl ubuntu-wsl
0 upgraded, 0 newly installed, 2 to remove and 2 not upgraded.
After this operation, 551 kB disk space will be freed.
Do you want to continue? [Y/n] y
(Reading database ... 40775 files and directories currently installed.)Removing ubuntu-wsl (1.539.2) ...
Removing curl (8.5.0-2ubuntu10.6) ...
Processing triggers for man-db (2.12.0-4build2) ...
sleep: Met dit commando pauzeer je de uitvoering van commando’s voor het opgegeven aantal seconden.
commando’s aaneenschakelen met ; of &&: je kan ze gebruiken om meerdere commando’s aan elkaar te schakelen, maar ze werken op verschillende manieren. De ; operator voert de commando’s sequentieel uit, ongeacht of het vorige commando succesvol was of niet. De && voert operator het tweede commando alleen uit als het eerste commando succesvol is (d.w.z. een exitstatus van 0 heeft). Dit maakt && nuttig voor het uitvoeren van afhankelijkheden, waar het tweede commando alleen zinvol is als het eerste commando slaagt.
# Voorbeeld ;arne@LT3210121:~$ cat test.txt;echo"two"Dit is een test file.
two
arne@LT3210121:~$ cat onbestaand.txt;echo"two"cat: onbestaand.txt: No such file or directory
two
# Voorbeeld &&arne@LT3210121:~$ cat test.txt &&echo"two"Dit is een test file.
two
arne@LT3210121:~$ cat onbestaand.txt &&echo"two"cat: onbestaand.txt: No such file or directory
»: Met deze operator voeg je de output van een commando toe aan het einde van een bestand.
$ [commando met output] >> [bestand]# Voorbeeldarne@LT3210121:~$ cat test.txt
Dit is een test file.
arne@LT3210121:~$ echo"Hello" >> test.txt
arne@LT3210121:~$ cat test.txt
Dit is een test file.
Hello
>: Met deze operator operator kun je de output van een commando naar een bestand sturen, waarbij de inhoud van het bestand wordt overschreven als het bestand al bestaat.
$ [commando met output] >> [bestand]# Voorbeeldarne@LT3210121:~$ cat test.txt
Dit is een test file.
arne@LT3210121:~$ echo"Hello" > test.txt
arne@LT3210121:~$ cat test.txt
Hello
Wildcards (*): Met de wildcard operator kun je patronen specificeren die overeenkomen met meerdere bestanden of directories in één keer. Dit is vooral handig bij het uitvoeren van bewerkingen op groepen bestanden zonder dat je elk bestand afzonderlijk hoeft te specificeren. Bijvoorbeeld kopieer alle bestanden met een bepaalde extensie naar een map: cp *.txt doelmap/
EXTRA: hier nog een lijst van nuttige commando’s en principes die we voorlopig niet verder in diepgang gaan bespreken, maar wel handig kunnen zijn in je ingenieurs carrière:
grep
het principe van piping |
ssh
het principe van background processes met & of Ctrl+z
fg
curl
ping
het principe van de bashrc-file
source
fancy printouts
het principe van signal interrupts
regular expressions
Shell scripts
Een shell script is een tekstbestand dat een reeks commando’s bevat die door een Unix-shell worden uitgevoerd. Shell scripts worden vaak gebruikt om taken te automatiseren, zoals systeembeheer, batchverwerking en het uitvoeren van complexe commando’s. Een belangrijk onderdeel van een shell script is de shebang (#!), die aangeeft welke interpreter moet worden gebruikt om het script uit te voeren. Voor een Bash-script wordt vaak de volgende shebang gebruikt: #!/bin/bash. Dit vertelt het systeem dat het script moet worden uitgevoerd met de Bash-shell.
Voorbeeld van een eenvoudig shell script: test.sh
#!/bin/bash
# Dit is een eenvoudig shell script dat een begroeting weergeeft en een lijst van bestanden in de huidige directory toont.echo"Hallo, wereld!"echo"Hier is een lijst van bestanden in de huidige directory:"ls -l
Om een shell script uitvoerbaar te maken, moet je het bestand de juiste permissies geven met het chmod-commando. Dit doe je door de uitvoerbare permissie toe te voegen met chmod +x. Dan kan je het shell script uitvoeren met de naam van het .sh-bestand.
Variabelen in een Shell Script
In een shell script kun je variabelen gebruiken om gegevens op te slaan en te manipuleren. Variabelen worden zonder spaties gedefinieerd en kunnen later in het script worden opgeroepen door een $-teken voor de variabelenaam te plaatsen.
Voorbeeld van een shell script met variabelen:
#!/bin/bash
# Dit script gebruikt variabelen om een begroeting weer te geven.NAAM="Alice"echo"Hallo, $NAAM! Welkom bij het shell scripting."
Opties meegeven en/of input uitlezen
Je kunt een shell script zo schrijven dat het invoer van de gebruiker accepteert via de commandline of tijdens de uitvoering van het script. Hier is een voorbeeld van beide methoden:
Voorbeeld: Invoer via de commandline
#!/bin/bash
# Dit script accepteert een naam als argument en geeft een begroeting weer.NAAM=$1echo"Hallo, $NAAM! Welkom bij het shell scripting."
Om dit script uit te voeren, geef je de naam op als argument:
./script.sh Alice
Merk op dat $0 het commando zelf is!
Voorbeeld: Invoer tijdens de uitvoering
#!/bin/bash
# Dit script vraagt de gebruiker om een naam in te voeren en geeft een begroeting weer.echo"Voer je naam in:"read NAAM
echo"Hallo, $NAAM! Welkom bij het shell scripting."
Voorbeeld: conditional statements
#!/bin/bash
# Dit script controleert de waarde van een variabele en geeft een bericht weer op basis van de waarde.echo"Voer een getal in:"read getal
if[$getal -lt 10];thenecho"Het getal is kleiner dan 10."elif[$getal -eq 10];thenecho"Het getal is precies 10."elseecho"Het getal is groter dan 10."fi
#!/bin/bash
# Dit script gebruikt een for-loop om een reeks bestanden te maken met oplopende getallen in de bestandsnamen.# Beginwaarde van het getalstart=1# Eindwaarde van het getaleind=5# Gebruik een for-loop om door de reeks getallen te itererenfor((i=start; i<=eind; i++));dobestandsnaam="bestand_$i.txt" touch "$bestandsnaam"echo"Bestand aangemaakt: $bestandsnaam"done
Merk op dat je eindigt met done
Voorbeeld: while-loop
#!/bin/bash
# Dit script gebruikt een while-loop om een getal te verhogen en weer te geven totdat het een bepaalde waarde bereikt.# Beginwaarde van het getalgetal=1# Eindwaarde van het getaleind=5# Gebruik een while-loop om het getal te verhogen en weer te gevenwhile[$getal -le $eind];doecho"Huidig getal: $getal"getal=$((getal +1))done
Het doel van deze informatie is dat je vlot je weg kan vinden in een OS met behulp van enkel een CLI. Je hoeft geen theorie te kennen, maar je moet wel simpele commando’s kunnen gebruiken en kennen zoals: Met welk commando navigeer je naar de directory /home/arne/test door gebruik te maken van een relatief pad wanneer je je in de directory /home/arne bevindt? OPLOSSING: $ cd test of $ cd ./test.
Heb je nog meer vragen over hoe de commando’s werken, gebruik dan het man-commando of zoek de documentatie op op het internet.
Oefeningen op de CLI
De gegeven oplossingen zijn EEN mogelijke oplossing, soms zijn meerdere mogelijkheden juist. Is het gewenste gedrag bereikt, dan is je oplossing correct!
Oefeningenreeks 1
Toon het pad van de huidige werkdirectory.
Solution:$ pwd
Maak een nieuw leeg bestand genaamd nieuwbestand.txt.
Solution:$ touch nieuwbestand.txt
Maak een nieuwe directory genaamd testmap.
Solution:$ mkdir testmap
Verwijder een bestand genaamd nieuwbestand.txt.
Solution:$ rm nieuwbestand.txt
Voeg de tekst “Hallo, wereld!” toe aan de terminaloutput.
Solution:$ echo "Hallo, wereld!"
Navigeer naar je home directory.
Solution:$ cd ~
Wis de output van je terminal.
Solution:$ clear
Bekijk de handleiding voor het commando dat bestanden en directories weergeeft.
Solution:$ man cd
Toon de inhoud van de huidige directory.
Solution:$ ls
Open het bestand nieuwbestand.txt in een teksteditor en voeg de tekst “Dit is een test.” toe. Sla het bestand op en sluit de editor.
Solution:
$ nano nieuwbestand.txt
# save met Ctrl+o en Enter. Exit met Ctrl+x
Toon de inhoud van nieuwbestand.txt in de terminal.
Solution:$ cat nieuwbestand.txt
Maak een nieuw directory genaamd project, navigeer naar deze directory, en maak een nieuw bestand genaamd README.md.
Solution:
$ mkdir project
$ cd ./project
$ touch ./README.md
Maak een nieuw bestand genaamd info.txt, voeg de tekst “Dit is een informatief bestand.” toe, en toon de inhoud van het bestand.
Solution:
$ nano info.txt
$ cat info.txt
Maak een nieuw directory genaamd backup, kopieer het bestand info.txt naar de backup-directory, en verwijder vervolgens het originele info.txt-bestand.
Zoek naar een softwarepakket met de naam ’neofetch'.
Solution:$ sudo apt search neofetch
Installeer een softwarepakket genaamd ’neofetch'.
Solution:$ sudo apt install neofetch
Verwijder een geïnstalleerd softwarepakket genaamd ’neofetch'.
Solution:$ $ sudo apt remove neofetch
Wijzig de permissies van een bestand genaamd nieuwbestand.txt zodat de eigenaar lees-, schrijf- en uitvoerrechten heeft, en de groep en anderen alleen lees- en uitvoerrechten hebben.
Solution:$ sudo chmod 755 nieuwbestand.txt
Voer twee commando’s na elkaar uit, ongeacht of het eerste commando succesvol is.
Solution:$ cat nieuwbestand.txt; echo "De file bestaat of niet"
Voer een tweede commando alleen uit als het eerste commando succesvol is.
Solution:$ cat nieuwbestand.txt && echo "De file bestaat"
Schrijf de uitvoer van een commando naar een bestand genaamd output.txt, waarbij de bestaande inhoud van het bestand wordt overschreven.
Solution:$ ls > output.txt
Voeg de uitvoer van een commando toe aan het einde van een bestand genaamd output.txt, zonder de bestaande inhoud te verwijderen.
Solution:$ echo "Einde bestand" >> output.txt
Zoek naar een softwarepakket genaamd curl, installeer het pakket.
Solution:
$ sudo apt search curl
$ sudo apt install curl
Verwijder alle bestanden in je map met de extensie .txt.
Solution:$ rm *.txt
Maak een bestand genaamd config.txt en voeg wat tekst toe. Maak een kopie van een bestand genaamd config.txt naar een nieuwe locatie met de naam backup_config.txt, wijzig de eigenaar van backup_config.txt naar de gebruiker root, en voeg de tekst “Backup voltooid” toe aan een logbestand genaamd log.txt.
Maak een directorystructuur aan met de volgende paden: project/src, project/bin, en project/docs.
Navigeer naar de src-directory.
Maak een nieuw bestand genaamd main.c in de src-directory.
Kopieer het bestand main.c naar de bin-directory.
Toon de inhoud van de bin-directory.
Solution:
$ mkdir -p project/src project/bin project/docs
$ cd project/src
$ touch main.c
$ cp main.c ../bin/
$ ls ../bin/
Oefening 2:
Maak een nieuwe directory genaamd backup in je thuismap.
Maak een subdirectory genaamd 2025 in de backup-directory.
Maak een nieuw bestand genaamd data.txt in de 2025-directory.
Voeg de tekst “Backup data voor 2025” toe aan data.txt.
Toon de inhoud van data.txt in de terminal.
Solution:
$ mkdir ~/backup
$ mkdir ~/backup/2025
$ touch ~/backup/2025/data.txt
$ echo"Backup data voor 2025" > ~/backup/2025/data.txt
$ cat ~/backup/2025/data.txt
Oefening 3:
Zoek naar een softwarepakket genaamd htop.
Installeer het htop-pakket.
Maak een directorystructuur aan met de volgende paden: tools/monitoring.
Start het programma htop via het absolute pad naar de htop executable file.
Solution:
# vergeet voor het installeren van software packages geen update te doen...$ sudo apt-get update
$ sudo apt-get install -y htop
$ mkdir -p tools/monitoring
# Een kleine zoektocht toont met dat de `htop` executable file zich bevindt in de `/bin` folder$ /bin/htop
Oefening 4:
Maak een directorystructuur aan met de volgende paden: website/css, website/js, en website/images.
Navigeer naar de css-directory.
Maak een nieuw bestand genaamd styles.css in de css-directory.
Voeg de tekst “body { background-color: #f0f0f0; }” toe aan styles.css.
Unzip dat bestand met het unzip-commando naar je home folder.
Solution:$ unzip ~/sample-1.zip -d ~/
Oefenreeks 4
Oefening 1: Maak een shell script dat aan de gebruiker een absoluut pad van een directory vraagt en het aantal .txt bestanden in die directory teruggeeft.
Solution:
#!/bin/bash
# Vraag de gebruiker om een absoluut pad van een directoryread -p "Voer het absolute pad van de directory in: " DIR_PATH
# Controleer of de directory bestaatif[ -d "$DIR_PATH"];thenCOUNT=0# Gebruik wildcards om alle .txt files in de directory op te vragenfor FILE in "$DIR_PATH"/*.txt;do# Controleer of de file bestaatif[ -f "$FILE"];thenCOUNT=$((COUNT +1))# vergeet de `fi` nietfi# vergeet de `done` niet voor de for loopdoneecho"Aantal .txt bestanden in $DIR_PATH: $COUNT"elseecho"De directory $DIR_PATH bestaat niet."fi
Oefening 2: Maak een shell script dat het ls commando nadoet met de opties -l en -a in de huidige directory. Je kan enkel de opties apart meegeven of als combinatie -la. Je hebt dus maximum 1 flag die je meegeeft aan je shell script waaruit je afleidt hoe je het ls commando moet uitvoeren.
Solution:
#!/bin/bash
if["$1"=="-l"];then ls -l
elif["$1"=="-a"];then ls -a
elif["$1"=="-la"];then ls -la
else ls
fi
Oefening 3: Maak een shell script genaamd make.sh dat 4 mogelijke opties kan meekrijgen:
Als je de optie start meegeeft vraagt het script de gebruiker naar een projectnaam en maakt dan volgende directories aan: ./projectnaam/src en ./projectnaam/build.
Als je de optie build meegeeft worden alle bestanden in de ./projectnaam/src directory gekopieerd naar de ./projectnaam/build directory.
Als je de optie clean meegeeft worden alle bestanden in de ./projectnaam/build directory gewist.
Als je de optie run meegeeft worden alle bestanden in ./projectnaam/build van alle .txt bestanden een na een getoond.
Solution:
#!/bin/bash
if["$1"=="start"];thenecho"creating project directory ..."read -p "Geef een naam voor je project: " PROJECT_NAME
mkdir -p ./$PROJECT_NAME/src ./$PROJECT_NAME/build
elif["$1"=="build"];thenread -p "Geef je projectnaam: " PROJECT_NAME
echo"building files to build directory ..." cp -r ./$PROJECT_NAME/src/* ./$PROJECT_NAME/build
elif["$1"=="clean"];thenread -p "Geef je projectnaam: " PROJECT_NAME
echo"cleaning build directory ..." rm -R ./$PROJECT_NAME/build/*
elif["$1"=="run"];thenread -p "Geef je projectnaam: " PROJECT_NAME
echo"running program ..."for FILE in ./$PROJECT_NAME/build/*.txt ;doif[ -f "$FILE"];then cat $FILEfidoneelseecho"Wrong command, choose: 'start', 'build', 'clean', or 'run'."fiecho"Done"
VSCode
Heb je speciale tools nodig als software engineer?
Je kan in principe code schrijven puur met nano en andere command line tools, maar dat is niet altijd even handig. Hoewel nano en vergelijkbare tools lichtgewicht en eenvoudig te gebruiken zijn, missen ze veel van de geavanceerde functies die moderne ontwikkelaars nodig hebben om efficient aan software engineering te doen. Denk hierbij aan syntax highlighting, code completion, debugging, en geïntegreerde versiebeheer. Deze functies kunnen het programmeren aanzienlijk efficiënter en minder foutgevoelig maken.
Daarom bestaan er Integrated Development Environments (IDE’s) die het programmeren vergemakkelijken op verschillende manieren. IDE’s bieden een uitgebreide set tools en functies binnen één enkele applicatie. Ze ondersteunen vaak meerdere programmeertalen, bieden geavanceerde debugging-mogelijkheden en hebben ingebouwde ondersteuning voor versiebeheer zoals Git. Bovendien bieden ze vaak een visuele interface (GUI) voor het beheren van projecten en dependencies, wat het ontwikkelproces stroomlijnt.
De nadelen van IDE’s zijn echter dat ze vaak zwaar en traag kunnen zijn, vooral op oudere of minder krachtige hardware. Ze kunnen ook een steile leercurve hebben vanwege de vele functies en configuratiemogelijkheden. Dit kan overweldigend zijn voor beginners of voor ontwikkelaars die snel aan de slag willen zonder veel tijd te besteden aan het leren van een nieuwe tool.
Als je dit vergelijkt met een lichtgewicht code/text editor zoals Notepad++ of Visual Studio Code (VSCode), zie je dat deze editors een goede balans bieden tussen functionaliteit en prestaties. Ze zijn sneller en minder resource-intensief dan volledige IDE’s, maar bieden toch veel van de functies die ontwikkelaars nodig hebben.
VSCode biedt een mooie middenweg omdat je via extensies het gedrag van de editor kunt aanpassen aan je eigen wensen. Met duizenden beschikbare extensies kun je functies toevoegen zoals linting, debugging, versiebeheer, en ondersteuning voor vrijwel elke programmeertaal. Dit maakt VSCode zeer flexibel en aanpasbaar, waardoor het een populaire keuze is onder ontwikkelaars van alle niveaus.
VSCode installeren
Om Visual Studio Code (VSCode) op Windows te installeren, volg je deze stappen:
Vink tijdens de installatie de optie aan om VSCode aan je PATH toe te voegen tijdens de installatie en om directories te openen met VSCode.
Na de installatie kun je VSCode starten vanuit het Startmenu of door code in de command line te typen.
Inloggen met je Microsoft- of GitHub-account in VSCode biedt verschillende voordelen. Door in te loggen, kun je je instellingen, thema’s en extensies synchroniseren over meerdere apparaten. Dit betekent dat je dezelfde ontwikkelomgeving hebt, ongeacht waar je werkt. Bovendien kun je eenvoudig samenwerken met anderen via GitHub, waarbij je toegang hebt tot je repositories en pull requests direct vanuit VSCode. Het is echter niet verplicht.
Ingebouwde menus
VSCode komt out-of-the-box met een breed scala aan functionaliteiten die het programmeren en ontwikkelen aanzienlijk vergemakkelijken:
Bestandenviewer: De ingebouwde bestandenviewer biedt een overzichtelijke manier om door je projectbestanden en mappen te navigeren. Je kunt eenvoudig bestanden openen, verplaatsen, hernoemen en verwijderen zonder de editor te verlaten.
Zoekfunctie: De krachtige zoekfunctie in VSCode stelt je in staat om snel door je codebase te zoeken naar specifieke termen of patronen. Je kunt zoeken binnen een enkel bestand of door je hele project, en zelfs gebruik maken van reguliere expressies (regex) voor geavanceerde zoekopdrachten.
Ingebouwd versiebeheer: VSCode heeft ingebouwde ondersteuning voor versiebeheer, zoals Git. Je kunt je code rechtstreeks vanuit de editor beheren, inclusief het maken van commits, het bekijken van de geschiedenis, en het oplossen van conflicten. Dit maakt het samenwerken met anderen en het bijhouden van wijzigingen in je code veel eenvoudiger.
Debugger: De ingebouwde debugger in VSCode ondersteunt verschillende programmeertalen en biedt functies zoals breakpoints, stap-na-stap uitvoering en het inspecteren van variabelen.
Extensies: Daarnaast kun je zoals al eerder vermeld met extensies de functionaliteit van VSCode verder uitbreiden. Of je nu ondersteuning nodig hebt voor een specifieke programmeertaal, linting, formattering, of integratie met andere tools, er is vrijwel altijd een extensie beschikbaar die aan je behoeften voldoet.
Shortcuts: Verder kan je ook zeer gepersonaliseerde shortcuts aanmaken die bij jouw specifieke workflow passen.
Instellingen
Je kunt op verschillende niveaus instellingen aanpassen in Visual Studio Code (VSCode), wat je de flexibiliteit geeft om de editor precies naar jouw wensen te configureren. Hier zijn de belangrijkste niveaus waarop je instellingen kunt aanpassen:
Gebruikersniveau: Instellingen die op gebruikersniveau worden aangepast, gelden voor alle projecten en werkruimten die je opent in VSCode. Deze instellingen worden opgeslagen in een JSON-bestand dat je kunt openen en bewerken via de Command Palette door te zoeken naar “Preferences: Open Settings (JSON)”.
Workspace niveau: Instellingen op workspace niveau gelden alleen voor de specifieke werkruimte of het project dat je hebt geopend. Dit is handig als je verschillende configuraties nodig hebt voor verschillende projecten. Workspace-instellingen worden opgeslagen in een .vscode-map binnen je projectdirectory.
Directory niveau: Binnen een werkruimte kun je ook instellingen aanpassen voor specifieke mappen. Dit kan nuttig zijn als je een project hebt met meerdere mappen die elk hun eigen configuratie vereisen.
Je kan extenties ook op die verschillende niveaus enablen/disablen.
De command pallette
De Command Palette in VSCode is een krachtige tool die je toegang geeft tot vrijwel alle functies en instellingen van de editor via een eenvoudige interface. Je kunt de Command Palette openen door Ctrl+Shift+p (Windows/Linux) of Cmd+Shift+p (Mac) te gebruiken. In de Command Palette kun je commando’s invoeren om taken uit te voeren zoals het openen van bestanden, het wijzigen van instellingen, het installeren van extensies, en nog veel meer. Het biedt een snelle manier om acties uit te voeren zonder door menu’s te hoeven navigeren, wat je workflow aanzienlijk kan versnellen. De Command Palette ondersteunt ook fuzzy search, waardoor je snel kunt vinden wat je zoekt, zelfs als je de exacte naam van het commando niet weet.
Connectie maken met WSL
Om connectie te maken met je WSL in VSCode heb je de extensie WSL nodig. Daarna kan je onderaan links op de blauwe of groene knop met >< pijlen klikken om connectie te maken met je WSL, op die manier kan je (de meeste) van je extensies behouden wanneer je connectie maakt met je wsl instantie. Je kan dan ook native de bestanden aanpassen, nieuwe bestanden/directories maken, etc. alsof vscode in de WSL omgeving zou zitten.
Enkele nuttige algemene extensies
Prettier: Coder formatter
TODO Tree: Hiervan gaan we in de lessen gebruik maken om oefeningen aan te geven binnen in bronbestanden.
Een ontwikkelomgeving opstellen voor de gewenste programmeertaal/het gewenste framework
Pad naar interpreter/compiler instellen: In de instellingen kan je voor specifieke programmeertalen het pad naar de correcte interpreter of compiler instellen. Op die manier kan je ook met de play-knop code uitvoeren in VSCode
Nuttige extenties voor elk framework/elke programmeertaal:
Syntax highlighter: Het zorgt ervoor dat verschillende elementen van de code, zoals sleutelwoorden, variabelen, strings en opmerkingen, verschillende kleuren krijgen. Dit helpt ontwikkelaars om de structuur en betekenis van de code sneller te begrijpen.
Code suggestions/completion: ook bekend als IntelliSense, biedt intelligente code-aanvullingen terwijl je typt.
Debugger: De ingebouwde debugger in VSCode helpt ontwikkelaars om hun code te testen en fouten op te sporen. Het biedt functies zoals breakpoints, stap-voor-stap uitvoering, en het inspecteren van variabelen. Dit versnelt de cyclus van bewerken, compileren en debuggen, waardoor ontwikkelaars efficiënter kunnen werken.
Linter: analyseert de code op semantische en stilistische problemen. Het helpt bij het identificeren en corrigeren van subtiele programmeerfouten en coding practices die tot fouten kunnen leiden.
Formatter: maakt de broncode gemakkelijker leesbaar door mensen door bepaalde regels en conventies af te dwingen, zoals lijnspatiëring, inspringing en spatiëring rond operators.
Code navigation shortcuts: VSCode biedt verschillende sneltoetsen om efficiënt door je code te navigeren.
(code templates)
Deze zijn meestal programmeertaal specifiek en moet je dus voor elke taal apart instellen. Soms kan je ook pakketten van extensies downloaden
Enkele development environments:
C development environment
Om broncode in C te runnen op je WSL ga je een aantal prerequisites nodig hebben:
gcc: Install via sudo apt install gcc -y. De GNU Compiler Collection is een verzameling van compilers voor verschillende programmeertalen zoals C, C++, Objective-C, Fortran, Ada, en meer.
make: Install via sudo apt install make -y. Dit is een tool die de bouw van softwareprojecten automatiseert door gebruik te maken van een Makefile om rules en dependencies te definiëren.
Verder kunnen volgende VSCode extensies handig zijn om je development proces te optimaliseren:
C C++ Extension Pack: dit bevat volgende extensies
C/C++: The C/C++ extension adds language support for C/C++ to Visual Studio Code, including editing (IntelliSense) and debugging features.
C/C++ Themes
CMake Tools: CMake Tools provides the native developer a full-featured, convenient, and powerful workflow for CMake-based projects in Visual Studio Code.
Java development environment
Om Javacode te runnen en te compileren op je WSL ga je een aantal prerequisites nodig hebben:
java: Install via sudo apt install default-jre -y. De Java Runtime Environment (JRE) is een softwarelaag die nodig is om Java-applicaties uit te voeren. Het bevat de Java Virtual Machine (JVM), kernbibliotheken en andere componenten die nodig zijn om Java-programma’s te draaien.
javac: Install via sudo apt install default-jdk -y. De Java Development Kit (JDK) is een softwaredeveloperskit die de tools en bibliotheken bevat die nodig zijn om Java-applicaties te ontwikkelen en te compileren. Het omvat de Java Runtime Environment, een compiler (javac), en andere hulpmiddelen zoals een debugger en documentatiegenerator.
gradle: Install via sudo snap install gradle --classic. Gradle is een open-source build automation tool die wordt gebruikt voor het ontwikkelen van softwareprojecten. Het ondersteunt het bouwen, testen, en implementeren van applicaties en is vooral populair in Java- en Android-ontwikkeling vanwege zijn flexibiliteit en krachtige configuratiemogelijkheden.
create gradle project in directory: gradle init
update gradle version per project: gradle wrapper --gradle-version x.x.x.
Verder kunnen volgende VSCode extensies handig zijn om je development proces te optimaliseren:
Extension Pack for Java: dit bevat volgende extensies
Language Support for Java(TM) by Red Hat: Java Linting, Intellisense, formatting, refactoring, Maven/Gradle support and more… Java Linting, Intellisense, formatting, refactoring, Maven/Gradle support and more… Provides Java ™ language support via Eclipse ™ JDT Language Server, which utilizes Eclipse ™ JDT, M2Eclipse and Buildship.
Debugger for Java: A lightweight Java Debugger based on Java Debug Server which extends the Language Support for Java by Red Hat. It allows users to debug Java code using Visual Studio Code (VS Code).
Test Runner for Java: A lightweight extension to run and debug Java test cases in Visual Studio Code.
Maven for Java: Maven extension for VS Code. It provides a project explorer and shortcuts to execute Maven commands, improving user experience for Java developers who use Maven.
Gradle for Java: This VS Code extension provides a visual interface for your Gradle build. You can use this interface to view Gradle Tasks and Project dependencies, or run Gradle Tasks as VS Code Task. The extension also offers better Gradle file (e.g. build.gradle) authoring experience including syntax highlighting, error reporting and auto completion.
Project Manager for Java: A lightweight extension to provide additional Java project explorer features. It works with Language Support for Java by Red Hat.
IntelliCode: The Visual Studio IntelliCode extension provides AI-assisted development features for Python, TypeScript/JavaScript and Java developers in Visual Studio Code, with insights based on understanding your code context combined with machine learning.
Python development environment
Om Pythoncode te runnen (en te compileren) op je WSL ga je een aantal prerequisites nodig hebben:
python3: Install via sudo apt install python3 -y. Het package python3 heb je nodig om Python 3 scripts en programma’s uit te voeren. Het bevat de interpreter en de standard libraries die essentieel zijn voor het draaien van Python 3 code.
pip: Install via sudo apt-get install python3-pip. Pip is een package manager voor Python die wordt gebruikt om Python-packages te installeren en te beheren.
update pip via pip install --upgrade pip
pyinstaller: Install via pip install pyinstaller (--break-system-packages). PyInstaller is een tool dat Python-scripts bundelt tot stand-alone executables voor Windows, macOS en Linux. Het maakt het mogelijk om Python-applicaties te distribueren zonder dat gebruikers een Python-omgeving hoeven te installeren.
Verder kunnen volgende VSCode extensies handig zijn om je development proces te optimaliseren:
Python: A Visual Studio Code extension with rich support for the Python language (for all actively supported Python versions), providing access points for extensions to seamlessly integrate and offer support for IntelliSense (Pylance), debugging (Python Debugger), formatting, linting, code navigation, refactoring, variable explorer, test explorer, and more!
Python Debugger: A Visual Studio Code extension that supports Python debugging with debugpy. Python Debugger provides a seamless debugging experience by allowing you to set breakpoints, step through code, inspect variables, and perform other essential debugging tasks. The debugpy extension offers debugging support for various types of Python applications including scripts, web applications, remote processes, and multi-threaded processes.
Pylance: Pylance is an extension that works alongside Python in Visual Studio Code to provide performant language support. Under the hood, Pylance is powered by Pyright, Microsoft’s static type checking tool. Using Pyright, Pylance has the ability to supercharge your Python IntelliSense experience with rich type information, helping you write better code faster.
2. Versie- en issuebeheer
Wat is de beste manier om source code te bewaren?
Wat is versiebeheer of source control?
Source Control is een sleutelbegrip voor ontwikkelteams. Het stelt iedereen in staat om aan dezelfde source file te werken zonder bestanden op- en neer te sturen, voorziet backups, maakt het mogelijk om releases en branches uit te rollen, …
Een versiebeheer systeem bewaart alle wijzigingen aan (tekst)bestanden. Dat betekent dat eender welke wijziging, door wie dan ook, teruggedraaid kan worden. Zonder versiebeheer is het onmogelijk om code op één centrale plaats te bewaren als er met meerdere personen aan wordt gewerkt. Zelfs met maar één persoon is het toch nog steeds sterk aan te raden om te werken met versionering. Fouten worden immers snel gemaakt. Een bewaarde wijziging aan een bestand is permanent op je lokale harde schijf: de volgende dag kan je niet het origineel terug boven halen. Er wordt samen met delta’s ook veel metadata bewaard (tijdstippen, commit comments, gebruikers, bestandsgroottes, …)
Zonder versionering stuurt iedereen e-mail attachments door naar elkaar, in de verwachting een aangepaste versie terug te ontvangen. Maar, wat gebeurt er met:
Conflicten? (iemand wijzigt iets in dezelfde cel als jij)
Meerdere bestanden? (je ontvangt verschillende versies, welke is nu relevant?)
Nieuwe bestanden? (je ontvangt aparte bestanden met nieuwe tabbladen)
Bestandstypes? (iemand mailt een .xslx, iemand anders een .xls)
…
Het wordt al snel duidelijk dat het delen van celdata beter wordt overgelaten aan Google Sheets, waar verschillende mensen tegelijkertijd gegevens in kunnen plaatsen. Hetzelfde geldt voor source code: dit wordt beter overgelaten aan een versiebeheer systeem.
What is “version control”, and why should you care? Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later
Pro Git
Subsecties van 2. Versie- en issuebeheer
Lokaal versiebeheer: Git
Git installeren
Het versiebeheer systeem dat we in dit opleidingsonderdeel zullen gebruiken is Git. ‘Git’ staat voor Global Information Tracker of met andere woorden Git wordt gebruikt om informatie over bestanden te volgen.
Via volgende link kan je alle up-to-date informatie terugvinden over hoe je Git op je besturingssysteem kan istalleren: Installatie procedure Git
Je kan checken of Git al geïnstalleerd is op je WSL door de versie ervan op te vragen via de CLI met git --version. Indien je geen error krijgt, is Git klaar voor gebruik. Als Git nog niet geïnstalleerd zou zijn kan je dit eenvoudig installeren met sudo apt install git.
Git gui en Git bash
Het is ook mogelijk een GUI voor Git te installeren, maar deze gaan we niet gebruiken. Dit is overigens ook nog niet mogelijk aangezien we enkel een CLI interface hebben voor onze WSL.
De git-gui app is een beginner vriendelijke omgeving om gemakkelijk met versiebeheer aan de slag te gaan. In de SES-lessen willen we je echter de ‘correcte’ manier aanleren om als software ontwikkelaar overweg te kunnen met verschillende handige tools zoals Git. Ook daarom gaan we de grafische interface van Git niet gebruiken.
Info
We gaan gebruik maken van de Git commands in een CLI om aan versiebeheer te doen. Windows gebruikers kunnen hiervoor best gebruik maken van det Git Bash applicatie die gelijktijdig met git geïnstalleerd werd. Mac OS en Linux gebruikers kunnen gebruik maken van hun eigen terminal applicatie.
De git workflow
Notitie
SVN, RCS, MS SourceSafe, CVS, … zijn allemaal version control systemen (VCS). Merk op dat Git géén klassieke “version control” is maar eerder een collaboratieve tool om met meerdere personen tegelijkertijd aan verschillende versies van een project te werken. Er is geen revisienummer dat op elkaar volgt zoals in CVS of SVN (v1, v2, v3, v’), en er is geen logische timestamp. (Zie git is not revision control).
Ook, in tegenstelling tot bovenstaande tools, kan je Git ook compleet lokaal gebruiken, zonder ooit te pushen naar een upstream server. Het is dus “self-sufficient”: er is geen “server” nodig: dat is je PC zelf.
In Git doorloopt een bestand verschillende statussen tijdens zijn levenscyclus. Wanneer een bestand voor het eerst wordt aangemaakt, is het untracked, wat betekent dat Git het nog niet volgt. Zodra je het bestand toevoegt aan de repository met git add, wordt het staged. Dit betekent dat het klaar is om gecommit te worden. Als je het bestand daarna bewerkt, wordt het modified. Om deze wijzigingen op te nemen in de volgende commit, moet je het bestand opnieuw stagen met git add. Wanneer je tevreden bent met de wijzigingen, gebruik je git commit om de wijzigingen definitief vast te leggen (commit) in de repository. Als je een bestand niet langer nodig hebt, kun je het verwijderen met git rm, waardoor het bestand uit de repository wordt verwijderd en de status van het bestand verandert. Gedurende deze cyclus kan een bestand ook de status unmodified hebben, wat betekent dat er geen wijzigingen zijn aangebracht sinds de laatste commit.
Git correct configureren
Om van start te kunnen gaan, moeten we Git eerst nog correct configureren. Dit doen we via de volgende commando’s:
We gaan in de volgende les een account aanmaken op een cloudplatform waarmee we ons versiebeheer gaan kunnen uitbreiden met cloud opslag en de mogelijkheid om samen te werken aan hetzelfde project. Hiervoor gaan we een gratis account moeten aanmaken met een emailadres en een username. Dit moeten dezelfde worden als de gegevens die je zojuist hebt geconfigureerd. Je kan deze gegevens later nog aanpassen.
Soms ga je een text editor moeten gebruiken om bijvoorbeeld een boodschap mee te geven bij elke nieuwe ‘versie’ die we gaan opslaan. Standaard wordt hier Vim voor gebruikt, maar aangezien dit niet zo beginnersvriendelijk is, veranderen we de default liever naar iets anders zoals Nano. Dit doe je via het volgende commando:
$ git config --global core.editor nano
Een directory initialiseren als een Git directory
Om van een directory een git directory te maken en alle veranderingen beginnen tracken gebruiken we het commando:
$ git init
Er verschijnt een verborgen folder in je directory genaamd .git. In die folder zal git alles bewaren om de veranderingen te tracken en een geschiendenis van alle versies bij te houden.
Checking, staging and committing changes
Met het commando $ git status kan je controleren in welke staat alle files/directories zich bevinden. Een file/folder kan zich in één van drie toestanden bevinden:
Modified: de file is aangepast maar nog niet gestaged.
Staged: de file is gestaged en klaar om gecommit te worden.
Committed: de file is sinds zijn laatste commit niet meer aangepast.
(Untracked: dit geldt enkel voor files/folders die juist aangemaakt zijn en nog nooit gecommit werden)
Een voorbeeld output ziet er als volgt uit:
arne@LT3210121:~/gittest$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached ..." to unstage)
new file: eenfile.txt
Changes not staged for commit:
(use "git add ..." to update what will be committed)
(use "git restore ..." to discard changes in working directory)
modified: eenfile.txt
Untracked files:
(use "git add ..." to include in what will be committed)
filetwee.txt
Met het commando $ git diff kan je de verschillen zien tussen de huidige staat van je files/folders versus de staat van de files/folders in de laatste commit.
Met het commando $ git add <filenaam> kan je afzonderlijk modified files naar de staging area ‘verplaatsen’. Volgens een goede version control strategy, is dit de manier om wijzigingen te stagen. Op die manier kan je gerichte commits maken die over een bepaald onderwerp gaan. In de praktijk wordt er soms echter voor snelheid gekozen. Zo kan je met $ git add . alle wijzigingen en nieuwe files in een keer stagen.
Met het commando $ git commit kan je alle files committen die gestaged zijn. Je teksteditor opent en je wordt gevraagd een message mee te geven met de commit. Probeer steeds een concrete boodschap mee te geven met elke commit bv. “Bug opgelost waarbij alles vetgedrukt stond”. Probeer elke commit message zo zinvol mogelijk te maken. Dit maakt het later makkelijk om terug te keren naar een belangrijke ‘versie’ van je broncode. Elke commit krijgt ook een specifieke hash zodat je gemakkelijk naar een specifieke ‘versie’ (commit) kan refereren.
Alle modified files stagen met 1 commando: $ git add .
Onmiddellijk een commit message meegeven binnenin het commit commando: $ git commit -m "mijn commit message"
combinatie van de twee bovenstaande commando’s: $ git commit -a -m "mijn commit message"
Opgelet Met $ git commit -a worden nieuwe files niet toegevoegd. Gebruik hier dus nog $ git add voor.
Undo changes
git status geeft je ook informatie over hoe je files/folders kan unstagen en zelfs de veranderingen van files kan terugbrengen naar hoe ze eruit zagen tijdens de laatste commit.
Gebruik: git rm --cached <file>... om te unstagen en git restore <file>... om wijzigingen terug te draaien (te discarden).
Bekijk de version tree (log)
Het commando $ git log wordt gebruikt om een lijst te zien van all je commits in chronologische volgorde, startend bij de laatste commit. Dat commando geeft veel informatie mee voor elke commit. Wil je liever een korter overzicht? Gebruik dan $ git log --oneline. (Met de --graph flag kan je ook de boomstructuur weergeven waar we zo dadelijk op terugkomen)
Met de flag --all kan je ervoor zorgen dat je zeker ben dat je alle branch information en tags te zien krijgt
Teruggaan naar vorige ‘versies’
Er bestaan commando’s die we kunnen gebruiken om naar een vroegere commit terug te keren. Ze werken echter op een verschillende manier en het is belangrijk dat je deze verschillen goed kent.
$ git reset <hash van de commit>: hiermee ga je terug naar een vorige commit en worden alle commits die erna gebeurden verwijderd.
$ git checkout <hash van de commit>: hiermee kan je tijdelijk terugkeren naar een vorige commit. Je zit hier dan in een soort virtuele omgeving waar je ook commits kan aanbrengen. Om dan terug te keren naar de HEAD van de versiegeschiedenis gebruik je:
$ git switch -c <branchname> : om je nieuwe virtuele commits op te slaan in een echte nieuwe branch.
$ git switch - : om terug te keren zonder je nieuwe virtuele commits bij te houden.
Snel een extra wijziging aanbrengen aan een vorige commit
Soms ga je snel te werk en heb je een commit gedaan, maar is er nog een kleine wijziging die eigenlijk ook nog best tot die commit hoort. In de plaats van een volledig nieuwe commit te doen kan je via git commit --amend je nieuwe gestagede files/folders toevoegen aan de laatste commit en de commit message eventueel wijzigen.
Dit is ook een handige manier om incrementeel en regelmatig een commit te doen, ook al denk je dat je werk nog geen volwaardige commit vereist. Je blijft gewoon stap na stap delen toevoegen tot je tevreden bent.
Waarschuwing
Het git commit --amend commando kan je remote repository in de war sturen, wanneer een commit bijvoorbeeld gepushed is naar de remote en daarna lokaal nog geamend wordt.
Branching
Het fijne aan Git is dat je parallel aan verschillende versies van je project kan werken door gebruik te maken van branching. Je start letterlijk een nieuwe tak waar je eigen commits kan aan toevoegen. Zo kan elk teamlid bijvoorbeeld zijn eigen branch aanmaken. Of je kan een brach aanmaken om aan een nieuwe feature te werken zonder dat je schrik moet hebben om problemen te creëren op de main branch.
Je maakt een nieuwe branch aan met het commando: $ git branch <branchnaam>
Je kan de verschillende branches oplijsten met: $ git branch
Het * symbool duidt de actieve branch aan.
Je kan naar een bepaalde branch gaan met: $ git checkout <branchnaam>
Je kan een branch deleten met: $ git branch -d <branchnaam>
Om een grafische voorstelling van de braches te laten printen bij het log commando gebruik je de --graph flag.
Merging
Je kan de commits van een zijtak nu terug toevoegen aan de historie van een andere tak. Dit doe je met het commando $ git merge <branchname>. Wil je bijvoorbeeld de wijzigingen van de new_feature branch mergen met de main branch, dan moet je eerst zien dat je je in de main branch bevindt en dan gebruik je het volgende commando: $ git merge new_feature
Merge conflicts
Wanneer je op twee verschillende branches echter commits heb die verschillende aanpassingen maken aan hetzelfde stukje code in je project dan ontstaat er een merge conflict. Je zal dan beide versies voorgeschoteld krijgen en jij moet dan de versie verwijderen die je niet wilt behouden. Dan pas kan de ‘merge’ succesvol afgerond worden.
.gitignore
Soms wil je dat een file niet wordt bijgehouden door git. Hier komen we in het gedeelte over remote repositories op terug. De files/folders die niet getracked mogen worden, moeten we in het bestand .gitignore toevoegen.
Klik hier om een voorbeeld .gitignore file te zien/verbergen🔽
# Negeert het bestand secret.txt in de root directory.
/secret.txt
# Negeert alle bestanden in de node_modules directory.
node_modules/
# Negeert de gehele directory build en alle subdirectories.
/build/
# Negeert alle bestanden met de extensie .log.
*.log
# Negeert alle bestanden in de temp directory, maar niet de subdirectories.
/temp/*
# Negeert alle .tmp bestanden in alle directories en subdirectories.
**/*.tmp:
# Negeert alle bestanden in de logs directory.
/logs/*
# Negeert NIET het bestand debug.log in de logs directory.
!/logs/debug.log:
# Negeert alle bestanden die beginnen met een tilde (~).
~*
Tagging
Om bepaalde belangrijke commits snel terug te vinden, kan je gebruik maken van tags.
Je kan de bestaande tags oplijsten met: $ git tag
Je kan de huidige commit taggen met bijvoorbeeld: $ git tag vX.X
Je kan een specifieke commit taggen met bijvoorbeeld: $ git tag vX.X <hashcode commit>
Je kan tags deleten met bijvoorbeeld: $ git tag -d vX.X
**Eens een commit een tag heeft gekregen kan je er ook naar refereren via de tag.
Indien je een bestaande tag wil verplaatsen, moet je ze eerst deleten en daarna toevoegen aan de nieuwe commit.
Belangrijk
We hebben hier enkel de basis commando’s aangehaald met een paar van de meest gebruikte manieren waarop ze gebruikt worden. Voor meer diepgang en achtergrond van alle git commando’s verwijs ik naar het Pro Git handboek. Vooral hoofdstuk 1 t.e.m. 3 zijn voor jullie interessant.
Oefeningen
Maak een git directory aan
Voeg één of meerdere tekstbestanden toe aan deze directory. Maak eventueel subfolders …
Gebruik $ git status om te zien wat er allemaal gecommit kan worden.
Commit deze veranderingen.
Maak aanpassingen aan de tekstbestanden en commit.
Keer terug naar de eerste commit via $ git reset
Bestudeer de output van $ git log
Maak een nieuwe branch en checkout naar die nieuwe branch
Voeg in deze branch nieuwe textbestanden toe en commit de verandering in die nieuwe branch.
Open File Explorer en doe een checkout terug naar de main branch. Zie je de nieuwe files verdwijnen/verschijnen wanneer je tussen de twee branches wisselt?
Merge je nieuwe branch met de main branch.
Maak veranderingen in de main branch en commit.
Switch terug naar je andere branch en maak op dezelfde plaats veranderingen en commit. Zo ga je een merge conflict opwekken.
Probeer nu weer je nieuwe branch te mergen met je main branch. Je zal eerst het merge conflict moeten oplossen
Tag je eerste commit met v1.0 en tag je laatste commit met v2.0.
Doe een git checkout naar je eerste commit door gebruik te maken van je nieuwe tags.
Probeer van alle bovenstaande stappen een schets te maken om zo na te gaan of je alle commando’s goed begrijpt.
Indien niet afgewerkt in het applicatiecollege, gelieve thuis af te werken tegen volgende les.
Hoe Git onder de motorkap werkt
Git behandelt een repository niet als een verzameling losse mappen en submappen met afzonderlijke geschiedenissen, maar als één ondeelbare momentopname (snapshot) van de volledige projecttoestand. Bij elke commit legt Git de complete staat van alle getrackte bestanden vast. Het is dus niet zo dat Git een specifieke map of enkel een gewijzigd bestand afzonderlijk opslaat; elke commit verwijst naar een volledige boomstructuur die het hele project representeert. Conceptueel werkt Git daarom altijd met het volledige project als één consistente eenheid.
In tegenstelling tot klassieke versiebeheersystemen slaat Git wijzigingen niet primair op als verschillen (diffs) tussen opeenvolgende versies. Hoewel Git verschillen kan berekenen en tonen wanneer dat nodig is, is het interne opslagmodel snapshot-gebaseerd. Wanneer een bestand wijzigt, wordt een nieuwe versie van de inhoud opgeslagen als een nieuw object. Ongewijzigde bestanden worden niet opnieuw gekopieerd, maar simpelweg opnieuw gerefereerd. Hierdoor kan elke commit worden gezien als een volledige projecttoestand, terwijl opslagruimte efficiënt wordt benut door hergebruik van identieke objecten.
Intern gebruikt Git een eenvoudig maar krachtig key-value opslagmodel. Alle data wordt opgeslagen als objecten die geïdentificeerd worden door een cryptografische hash van hun inhoud (traditioneel SHA-1, steeds vaker SHA-256). De hash fungeert als sleutel, de inhoud als waarde. Er zijn vier hoofdtypes objecten: blobs (bestandsinhoud), trees (mapstructuren), commits (momentopnames met metadata en verwijzingen naar een tree en eventuele ouders) en tags. Een tree-object bevat geen bestandsdata zelf, maar koppelt bestandsnamen aan blob-hashes en mapnamen aan andere tree-hashes. Op die manier vormt de volledige repositorygeschiedenis een gerichte acyclische graaf (DAG) van onveranderlijke, content-addressed objecten, waarbij elke commit via een root-tree de volledige projectstructuur definieert.
Info
Jiujutsu (JJ), the new kid on the block, is een modern versiecontrolesysteem dat ontwikkeld wordt bij Google en ontworpen is als een gebruiksvriendelijker alternatief voor Git. Het biedt een eenvoudiger en consistenter command-model, met krachtige mogelijkheden voor het herschrijven en beheren van geschiedenis. Onder de motorkap gebruikt Jujutsu echter gewoon Git als opslagbackend, waardoor het compatibel blijft met bestaande Git-repositories en infrastructuur.
Wildcards en commando’s aaneenschakelen
Wildcards kunnen gebruikt worden om naar meerdere files tegelijk te verwijzen. Zo kan je de wildcard ‘_’ gebruiken om naar alle files die eindigen op ‘.txt’ te verwijzen.Bijvoorbeeld: **$ git add _.txt**
Je kan commando’s ook aaneenschakelen met ‘;’ zodat meerdere commando’s onmiddellijk na elkaar uitgevoerd wordenBijvoorbeeld: $ git add . ; git commit -m "initial commit"
Extra bronnen
Pro Git handboek, vooral hoofdstuk 1 tot en met 3.
Wil je meer inzicht in hoe git achter de schermen precies werkt? Lees dan zeker dit artikel en deze webpagina eens! Die geeft je op een toegankelijke manier uitleg over hoe git wijzigingen opslaat, wat de staging area precies is, etc. (Opmerking: het artikel begint met een vergelijking met SVN; dat is een ander/ouder versiecontrolesysteem.)
Remote repositories: Github
Types van versiebeheer systemen
Git is een gedecentraliseerd versiebeheer systeem waarbij de hele repository inclusief historiek lokaal wordt geplaatst zodra een clone commando wordt uitgevoerd. Oudere gecentraliseerde systemen zoals SVN en CVS bewaren (meta-)data op één centrale plaats: de version control server. Voor dit vak wordt resoluut voor git gekozen.
Info
Een repository (of repo) is een opslagplaats waar alle bestanden en hun geschiedenis van een project worden bewaard. In de context van Git is een repository een verzamelplaats voor alle projectbestanden, inclusief hun revisiegeschiedenis. Dit betekent dat elke wijziging die je aanbrengt in de bestanden wordt bijgehouden, zodat je altijd kunt terugkeren naar een eerdere versie als dat nodig is.
Onderstaande Figuur geeft het verschil weer tussen een gecentraliseerd versioneringssysteem, zoals SVN, CVS en MS SourceSafe, en een gedecentraliseerd systeem, zoals Git. Elke gebruiker heeft een kopie van de volledige repository op zijn lokale harde schijf staan. Bij SVN communiceren ‘working copies’ met de server. Bij Git communiceren repositories (inclusief volledige history) met eender welke andere repository. ‘Toevallig’ is dat meestal een centrale server, zoals Github.com, Gitlab.com of BitBucket.com.
Andere populaire platformen zijn Gitlab, Codeberg, Gitea (self-hosted), … Deze software platformen voorzien een extra laag bovenop Git (de web UI) die het makkelijk maakt op via knoppen acties uit te voeren. Het voegt ook een social media esque aspect toe: comments, requests, issues, …
Notitie
SVN, RCS, MS SourceSafe, CVS, … zijn allemaal version control systemen (VCS). Merk op dat Git géén klassieke “version control” is maar eerder een collaboratieve tool om met meerdere personen tegelijkertijd aan verschillende versies van een project te werken. Er is geen revisienummer dat op elkaar volgt zoals in CVS of SVN (v1, v2, v3, v’), en er is geen logische timestamp. (Zie git is not revision control).
Ook, in tegenstelling tot bovenstaande tools, kan je Git ook compleet lokaal gebruiken, zonder ooit te pushen naar een upstream server. Het is dus “self-sufficient”: er is geen “server” nodig: dat is je PC zelf.
Remote repository met Github
“… GitHub is a website and cloud-based service that helps developers store and manage their code, as well as track and control changes to their code. …”
source
Cloud based storage is zeer populair geworden en voor goede redenen:
Je hebt een backup van al je data.
Je kan op meerdere verschillende pc’s aan hetzelfde project werken zonder met een USB-stick dingen te copy pasten.
Je kan met meerdere personen aan hetzelfde project werken zonder doorsturen van verschillende file versies via mail.
Github is zeer populair en wordt door veel softwareontwikkelaars en bedrijven gebruikt. Wij zullen dit platform dan ook gebruiken in dit opleidingsonderdeel en het is ook aangeraden dit in de toekomst voor je softwareprojecten te gebruiken.
GitHub is nu eigendom van Microsoft en is closed source software. Je kan wel de meeste features volledig gratis gebruiken. Wil je later toch liever een open source alternatief gebruiken? Dan is Gitlab een goed alternatief en werkt zeer gelijkaardig aan Github. Gitea is een goed self-hosted optie
Een account aanmaken, 2FA instellen, SSH key toevoegen
Voordat we van start kunnen gaan moeten we eerst een gratis account aanmaken. Verder moeten we ook nog een aantal belangrijke instellingen veranderen voordat we van de services gebruik kunnen maken.
Aangezien het stappenplan voor het aanmaken van een account en de gewenste instellingen wel eens kan wijzigen refereren we hieronder naar de officiële bronnen die door de ontwikkelaar up-to-date gehouden worden:
Account aanmaken op Github (Let op! gebruik hetzelfde email adres en dezelfde username die je hebt geconfigureerd in je lokale Git om het process zo vlot mogelijk te laten verlopen)
Repositories clonen en veranderingen fetchen, pullen & pushen
Je kan via de webinterface van Github nieuwe repositories aanmaken. Github geeft je dan alle nodige instructies/commando’s om oftewel die remote repo te koppelen aan een bestaande lokale Git directory of een nieuwe lege repo lokaal te clonen.
Vanaf nu bestaat er een link tussen de lokale repository en de remote repository.
Je kan nieuwe aanpassingen van je remote repository pullen naar (≈ synchroniseren met) je lokale repo met:
$ git pull: Dit haalt alle veranderingen binnen en past ze onmiddelijk toe
$ git fetch: Dit haalt alle veranderingen binnen maar zo worden nog niet gemerged met jouw lokale versie. Dit doe je met $ git merge. (git pull is dus eigenlijk een aaneenschakeling van git fetch en git merge)
Je kan nieuwe aanpassingen van je lokale repository pushen naar je remote repo met:
$ git push origin: Dit pusht enkel je huidige branch.
$ git push origin --all: Dit pusht de wijzigingen op alle branches.
$ git push origin --tags: Dit pusht alle tags die nog niet aanwezig zijn op de remote repo.
Waarschuwing
Voeg files met gevoelige informatie zoals wachtwoorden onmiddellijk toe aan je .gitignore-file VOORDAT je een push doet naar de remote repository. Eens een bestand eenmaal gepushed is naar de remote zal er namelijk altijd een kopie van op het internet te vinden zijn en dat wil je natuurlijk niet als het gaat over je wachtwoord of api-key bijvoorbeeld.
Collaboration made easy
Door een teamgenoot als collaborator toe te voegen aan je remote repository kan hij/zij de repo lokaal clonen en ook wijzigingen via pushen en pullen. Door dit te combineren met branching waarbij elke collaborator bijvoorbeeld een eigen branch aanmaakt, kan je een zeer efficiënte online workflow creëren om remote te kunnen samen werken aan software projecten.In principe kan iedereen een public remote repository clonen, maar ze gaan geen veranderingen kunnen pushen. (Hiervoor gebruik je fork en pull requests)
Collaborative workflow: to minimize merge conflicts and other problems
Regularly pull all changes into your local directory.
Regularly keep your branch up-to-date by merging master branch into it.
(Merge the changes on your branch to the master branch when nessecary)
Regularly push to remote directory.
Forking en pull requests
Je kan een public repository waar je geen collaborator van bent forken (≈ kopiëren) naar je eigen Github. Zo kan je toch nieuwe aanpassingen pushen naar ‘jouw kopie’ van de repository. Github houd echter bij vanwaar jouw fork afkomstig is. Op die manier kan je een pull request aanvragen aan de eigenaar van de originele repo. Die persoon kan jouw aanpassingen dan nakijken en toevoegen aan zijn/haar repo door de pull request te accepteren en mergen.
Een waarheidsgetrouw voorbeeld ziet er als volgt uit:
Je wil een kleine software developer helpen door een bug op te lossen.
Je forked de repository van de software.
Je fixed de bug, commit en pushed de aanpassing naar jouw fork van de software repo.
Je dient een pull request in bij de originele repo van de software.
De eigenaar vindt jouw oplossing geweldig en merged hem met zijn eigen repo.
Op deze manier kan je zeer gemakkelijk je steentje bijdragen aan de wereld van open source software en dit maakt het principe van open source ook juist mede zo aantrekkelijk.
Oefeningen
Maak in je Github een repository aan voor je Git directory uit de vorige oefenreeks.
Koppel je lokale repo aan je remote repo en push je versiegeschiedenis naar Github.
Push ook je tags mee naar de remote repo en controleer of ze te zien zijn bij versions
Clone op een andere plaats op je computer je remote repository
Maak veranderingen aan de files, commit en push
Fetch of pull nu die veranderingen in de originele directory.
Denk na over het verschil tussen fetch en pull.
Bestudeer de online user interface van Github voor het beheren van je remote repositories
Voeg een medestudent toe als collaborator aan het project.
Laat die student je repo clonen, veranderingen aanbrenge, committen en pushen.
Pull nu de veranderingen van je teamgenoot in je eigen local repository
Laat je als collaborator verwijderen
Fork nu de repository van je medestudent, maak aanpassingen en submit een pull request.
Bestudeer nu grondig de git log van je repository. Kan je alle veranderingen volgen?
(Submit een issue in je eigen remote repository, los de issue op met een commit en gebruik de issuenummer met het sleutelwoord ‘Close’ (Close #<issuenummer>) om de issue automatisch op te lossen)
Extra
De Git workflow
Een typische workflow is als volgt:
git clone [url]: Maakt een lokale repository aan die je op Github hebt gecreëerd. Het commando maakt een subdirectory aan.
Doe je programmeerwerk.
git status en git diff: Bekijk lokale changes voordat ze naar de server gaan.
git add [.]: Geef aan welke changes staged worden voor commit
git commit -m [comment]: commit naar je lokale repository. Wijzingen moeten nu nog naar de Github server worden gesynchroniseerd.
git push: push lokale commits naar de Github server. Vanaf nu kan eender wie die meewerkt aan deze repository de wijzigingen downloaden op zijn lokaal systeem.
git pull: pull remote changes naar je lokale repository. Wijzigingen moeten altijd eerst gepushed worden voordat iemand anders kan pullen.
Ik zie niet alle branches lokaal die wel op Github staan, hoe komt dat?
Een git pull commando zal soms in de console ’new branch [branchnaam]’ afdrukken, maar toch zal je deze niet tot je beschikking hebben met het git branch commando. Dat komt omdat branches dan ook nog (lokaal) getracked moeten worden:
Controleer welke branch je lokaal wilt volgen met git branch -r
Selecteer een bepaalde branch, waarschijnlijk origin/[naam]
Track die branch lokaal met git branch --track [naam] origin/[naam]
Vanaf nu kan je ook switchen naar die branch, controleer met git branch
Merk op dat een branch verwijderen met git branch -d enkel gaat bij lokale branches. Een remote branch verwijderen wordt niet met het branch subcommando gedaan, maar met git push origin --delete [branch1] [branch2] ....
Bug tracking met Github
Enkele ‘kleine probleempjes’ in software worden al snel een hele berg aan grote problemen als er niet op tijd iets aan wordt gedaan. Bedrijven beheren deze problemen (issues) met een bug tracking systeem, waar alle door klant of collega gemeldde fouten van het systeem in worden gelogd en opgevolgd. Op die manier kan een ontwikkelaar op zoek naar werk in deze lijst de hoge prioritaire problemen identificeren, oplossen, en terug koppelen naar de melder.
graph LR;
Bug[Bug discovery]
Report[Bug report]
Backlog[Bug in backlog met issues]
Prio[Bug in behandeling]
Fix[Bug fixed]
Bug --> Report
Report --> Backlog
Backlog --> Prio
Prio --> Fix
De inhoud van deze stappen hangt af van bedrijf tot bedrijf, maar het skelet blijft hetzelfde. Bugs worden typisch gereproduceerd door middel van unit testen op een bepaalde git branch om de bestaande ontwikkeling van nieuwe features niet in de weg te lopen. Wanneer het probleem is opgelost, wordt deze branch gemerged met de master branch:
Github Issues is een minimalistische feature van Github die het mogelijk maakt om zulke bugs op te volgen. Een nieuw issue openen en een beschrijving van het probleem meegeven (samen met stappen om het te reproduceren), maakt een nieuw item aan dat standaard op ‘open’ staat. Dit kan worden toegewezen aan personen, en daarna worden ‘closed’, om aan te geven dat ofwel het probleem is opgelost, ofwel het geen echt probleem was. Issues kunnen worden gecategoriseerd door middel van labels.
Versiebeheer met je favoriete IDE
Sommige IDE’s komen met built-in tools of plug-ins om gemakkelijk gebruik te maken van Version Control en remote repositories. Ik raad je echter aan eerst voldoende te oefenen met de command line tools zodat je altijd weet wat je aan het doen bent. Op die manier ga je beter en vooral sneller problemen kunnen oplossen. Indien je de ‘hard’ way onder de knie hebt, kan je natuurlijk overschakelen naar eender welke tool jij het handigste vindt.
Github Classroom
GitHub Classroom is een hulpmiddel waarmee docenten eenvoudig programmeeropdrachten kunnen beheren en beoordelen via GitHub. Met deze tool kunnen docenten repositories aanmaken voor studenten, opdrachten automatisch toewijzen en versiebeheer integreren in het leerproces. Studenten werken in hun eigen repository, waardoor docenten de voortgang kunnen volgen en feedback kunnen geven op basis van commits en pull requests. Dit vereenvoudigt het beheer van opdrachten en stimuleert het gebruik van professionele ontwikkelpraktijken in het onderwijs.
Opdracht: zie opdrachten
3. Build systems and Makefiles
Hoe ga je van broncode naar een werkende software applicatie
In de wereld van software engineering vormt de compiler een essentieel hulpmiddel dat de kloof overbrugt tussen de door ontwikkelaars geschreven broncode en de uitvoerbare machinecode die door de computer wordt begrepen. Wanneer programmeurs een programma schrijven, doen zij dit vaak in een hoog-niveau taal die leesbaar en begrijpelijk is voor mensen. De compiler vertaalt deze code vervolgens naar een lager-niveau, binaire instructies die specifiek zijn voor de hardware (CPU architecture) waarop het programma draait.
Het compilatieproces bestaat doorgaans uit verschillende stappen die gezamenlijk zorgen voor een correcte en efficiënte omzetting van de broncode.
Allereerst vindt een lexicale analyse plaats, waarbij de broncode wordt opgesplitst in basiselementen, of tokens.
Vervolgens controleert de parser of deze tokens in de juiste volgorde staan volgens de grammaticale regels van de taal, waardoor een abstracte syntaxisboom ontstaat.
Hierna volgt een semantische analyse om te verifiëren dat de code logisch en consistent is.
Optimalisatiefasen kunnen daarna ingrijpen om de prestaties te verbeteren, waarna de codegenerator de uiteindelijke machinecode produceert.
Ten slotte wordt deze code vaak gekoppeld/gelinkt met externe bibliotheken en modules, zodat er een volledig functioneel uitvoerbaar bestand ontstaat, ook wel een executable of binary genoemd.
Naast de technische vertaalslag biedt het gebruik van een compiler ook andere belangrijke voordelen.
Zo kan de compiler programmeerfouten al vroeg in het ontwikkelproces opsporen, zoals syntaxis- of typefouten, waardoor deze sneller gecorrigeerd kunnen worden.
Tevens zorgt de optimalisatie tijdens de compilatie ervoor dat de uiteindelijke applicatie efficiënter draait, wat cruciaal is in productieomgevingen.
Deze scheiding tussen broncode en machinecode maakt het bovendien mogelijk voor ontwikkelaars om zich te richten op de logica en architectuur van hun programma, terwijl de compiler de complexe taak van vertalen en optimaliseren op zich neemt.
Build systems
Naast het compileren en linken van code, kunnen build-systems het manuele werk aanzienlijk vereenvoudigen voor developers. Build-systems automatiseren niet alleen het proces van compileren en linken, maar beheren vaak ook dependencies, voeren tests uit en zorgen voor een consistente en reproduceerbare build-omgeving. Dit betekent dat ontwikkelaars niet langer handmatig complexe commando’s hoeven uit te voeren voor elke stap in het buildproces.
Door alleen de gewijzigde onderdelen opnieuw te compileren, optimaliseren build-systems de efficiëntie en verminderen ze de kans op menselijke fouten. Bovendien dragen ze bij aan een gestandaardiseerde workflow, wat vooral binnen teams zorgt voor een soepelere samenwerking en minder integratieproblemen.
In de volgende onderdelen leer je hoe dit er praktisch uitziet voor verschillende programmeertalen
Subsecties van 3. Build systems and Makefiles
Cmdline C Compiling
C programma’s compilen
Source code en header files
De ontwikkeling begint met het schrijven van de broncode in .c-bestanden en het definiëren van functies en variabelen in header files (.h-bestanden). Header files bevatten vaak declaraties van functies en macro’s die in meerdere bronbestanden worden gebruikt.
De preprocessor voert tekstvervangingen uit voordat de daadwerkelijke compilatie begint. Dit omvat het verwerken van #include-directives, het vervangen van macro’s en het uitvoeren van voorwaardelijke compilatie.
De #ifndef-directive staat voor “if not defined” en wordt gebruikt om te voorkomen dat een header file meerdere keren wordt ingeladen, wat kan leiden tot dubbele declaraties en andere problemen. Dit wordt ook wel een include guard genoemd.
Compiler
De compiler vertaalt de preprocessed broncode naar assembly code. Dit is een laag-niveau representatie van de code die specifiek is voor de CPU-architectuur.
gcc -c main.c header.c
Assembler
De assembler vertaalt de assembly code naar objectbestanden (.o-bestanden). Deze objectbestanden bevatten machinecode die door de processor kan worden uitgevoerd, maar zijn nog niet zelfstandig uitvoerbaar.
Linker
De linker neemt de objectbestanden en eventuele bibliotheken en combineert deze tot een enkel uitvoerbaar bestand. De linker lost symbolen op (zoals functie- en variabelenamen) en zorgt ervoor dat alle verwijzingen correct zijn. Bijvoorbeeld:
gcc -o output.bin main.o header.o
Libraries
Libraries bevatten vooraf gecompileerde code die kan worden hergebruikt in verschillende programma’s. Er zijn statische bibliotheken (.a-bestanden) en dynamische bibliotheken (.so-bestanden). Hier komen we later bij dependency management nog op terug.
De Binary
Het eindresultaat is een binary executable die direct door het besturingssysteem kan worden uitgevoerd. Dit bestand bevat de machinecode, evenals alle benodigde symbolen en verwijzingen naar bibliotheken. Je kan je programma runnen met volgende commando:
./output.bin
Door die stappen te doorlopen, wordt de broncode omgezet in een uitvoerbaar programma dat op de doelmachine kan draaien.
C compilation proces
De GNU Compiler Collection: gcc
GCC is een krachtige en veelzijdige compiler die wordt gebruikt voor het compileren van verschillende programmeertalen zoals C, C++, Objective-C, Fortran, Ada en meer. GCC is een essentieel onderdeel van de GNU-toolchain en wordt veel gebruikt in de open-source gemeenschap vanwege zijn flexibiliteit en robuustheid. Het biedt uitgebreide optimalisatiemogelijkheden, foutdetectie en ondersteuning voor verschillende architecturen.
compileren naar .o files: gcc -c ./src/main.c -o ./build/main.o
linken van de .o files: gcc -o program.bin ./build/*.o
Info
Hier enkele veelgebruikte flags voor gcc:
-Wall: Deze flag schakelt de meeste waarschuwingen in, zodat je tijdens het compileren meldingen krijgt over mogelijke problemen in je code. Dit helpt om fouten en onbedoelde gedragingen op te sporen.
-Wextra:Met deze flag worden extra waarschuwingen ingeschakeld die niet door -Wall worden gedekt. Hierdoor krijg je nog meer informatie over potentiële problemen of verbeterpunten in je code.
-std=c11:Deze flag geeft aan dat de compiler de C-standaard uit 2011 (C11) moet gebruiken. Dit zorgt ervoor dat je code voldoet aan de specificaties en functionaliteiten die in deze standaard zijn gedefinieerd.
Automatiseren met een shell script
Het handmatig compileren van bronbestanden kan tijdrovend en foutgevoelig zijn, vooral bij grotere projecten met veel bestanden. Daarom geven we de voorkeur aan het automatiseren van dit proces. Dit kan je eventueel doen met behulp van een Shell script.
Door een script te gebruiken, kunnen we ervoor zorgen dat alle stappen consistent en correct worden uitgevoerd, zonder dat we elke keer dezelfde commando’s hoeven in te typen. Dit vermindert de kans op menselijke fouten, zoals het vergeten van een bestand of het verkeerd typen van een commando. Bovendien maakt automatisering het eenvoudiger om het compilatieproces te herhalen, wat handig is bij het ontwikkelen en testen van software. Het gebruik van scripts verhoogt de efficiëntie en betrouwbaarheid van het ontwikkelproces, waardoor ontwikkelaars zich kunnen concentreren op het schrijven van code in plaats van op het compileren ervan.
Oefening
Extract alle files in dit zip bestand naar een directory naar keuze OF clone de repository. Schrijf een shell script met de naam make.sh dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de /build-directory en maakt de binary game.bin in de root directory
clean: Verwijdert de binary en de object files in de build directory
run : Voert de binary uit (bouwt eerst als die nog niet bestaat) en geeft eventuele flags door (bv --hp 12)
Solution: Klik hier om de code te zien/verbergen🔽
#!/bin/bash
# Dit script ondersteunt drie commando's:# compile: Compileert de bronbestanden en maakt de binary# run: Voert de binary uit (bouwt eerst als die nog niet bestaat)# clean: Verwijdert de binary en de build directory# Variabelen (hardcoded voor eenvoud)SRC_DIR="src"BUILD_DIR="build"TARGET="game.bin"CFLAGS="-Wall -Wextra -std=c11"# Zorg dat er minstens één argument is meegegevenif["$#" -lt 1];thenecho"Gebruik: $0 {compile|run|clean} [--hp <waarde>]"exit1fiCOMMAND=$1# Shift the parameters so the second becomes the first etc.shiftif["$COMMAND"="compile"];thenecho"Bouwen van het project..."# Maak de build-directory als deze nog niet bestaatif[ ! -d "$BUILD_DIR"];then mkdir -p "$BUILD_DIR"fi# Compileer main.c en game.c naar objectbestanden in build/echo"Compileren van $SRC_DIR/main.c..." gcc $CFLAGS -c "$SRC_DIR/main.c" -o "$BUILD_DIR/main.o"echo"Compileren van $SRC_DIR/game.c..." gcc $CFLAGS -c "$SRC_DIR/game.c" -o "$BUILD_DIR/game.o"# Link de objectbestanden naar de uiteindelijke binary in de rootecho"Linken naar $TARGET..." gcc $CFLAGS -o "$TARGET""$BUILD_DIR/main.o""$BUILD_DIR/game.o"echo"Build succesvol: $TARGET is aangemaakt."elif["$COMMAND"="run"];then# Bouw de binary als deze niet bestaatif[ ! -f "$TARGET"];thenecho"Binary niet gevonden, eerst bouwen..." sh "$0" build "$@"fiecho"Uitvoeren van $TARGET..." ./"$TARGET""$@"elif["$COMMAND"="clean"];thenecho"Opruimen..."# Verwijder de binary en de build-directory rm -rf "$BUILD_DIR/*" rm -f "$TARGET"echo"Opruimen voltooid."elseecho"Onbekend commando: $COMMAND"echo"Gebruik: $0 {compile|run|clean} [--hp <waarde>]"exit1fi
Moeilijkheden
Bij het handmatig compileren van projecten kunnen er verschillende tekortkomingen optreden:
Een van de grootste uitdagingen is het beheren van afhankelijkheden tussen bestanden. Wanneer een bronbestand wordt gewijzigd, moeten alle gerelateerde bestanden opnieuw worden gecompileerd, wat moeilijk bij te houden is zonder een gestructureerd systeem.
Daarnaast kan het handmatig invoeren van compilatie- en linkcommando’s voor elk bestand tijdrovend en foutgevoelig zijn.
De if-else syntax voor de verschillende opties is ook niet zo een gracieuze oplossing.
Beter, een build system: Makefiles
Makefiles proberen een antwoord te bieden op de tekortkomingen van shell scripts door een gestructureerde en efficiënte manier te bieden om afhankelijkheden en compilatiestappen te beheren. Ze maken gebruik van regels en doelen om automatisch te bepalen welke bestanden opnieuw moeten worden gecompileerd wanneer een bronbestand wordt gewijzigd. Dit voorkomt onnodige hercompilatie en bespaart tijd. Bovendien kunnen Makefiles complexe build-processen eenvoudig beheren door verschillende taken zoals compileren, linken, testen en opruimen te automatiseren. Ze bieden ook flexibiliteit door het gebruik van variabelen en conditionele statements, waardoor dezelfde Makefile kan worden gebruikt voor verschillende configuraties en platformen.
Hoe zijn makefiles opgebouwd?
Makefiles zijn opgebouwd uit een reeks regels die beschrijven hoe verschillende bestanden in een project moeten worden gecompileerd en gelinkt. Elke regel in een makefile bestaat uit drie hoofdonderdelen: doelen, afhankelijkheden en commando’s.
Doelen (Targets): Dit zijn de bestanden die je wilt genereren, zoals objectbestanden of een uitvoerbaar bestand. Een doel kan ook een alias zijn voor een groep commando’s, zoals all of clean.
Afhankelijkheden (Dependencies): Dit zijn de bestanden waarvan het doel afhankelijk is. Als een van deze bestanden wordt gewijzigd, weet make dat het doel opnieuw moet worden gegenereerd.
Commando’s (Commands): Dit zijn de shell-commando’s die worden uitgevoerd om het doel te genereren. Ze MOETEN beginnen met een tab en worden uitgevoerd in de volgorde waarin ze zijn geschreven.
Het doel program hangt af van main.o en header.o. Als een van deze objectbestanden wordt gewijzigd, wordt program opnieuw gegenereerd.
De regel compile specificeert hoe de nodige .c-bestanden moeten worden gecompileerd naar de respectievelijke .o-bestanden.
Het doel clean verwijdert de gecompileerde bestanden, wat handig is voor een schone hercompilatie.
Syntax en Flow
Een ’naïve’ make file zou er kunnen uitzien zoals hieronder, met wat leuke syntax zoals variabelen:
# Declareer variabelen
SRCDIR= ./src
BUILDDIR= ./build
TARGET= program.bin
# Je kan zoals in de commando's simpelweg wildcards gebruiken
compile: gcc -c $(SRCDIR)/header.c -o ./build/header.o
gcc -c ./src/main.c -o ./build/main.o
gcc -o $(TARGET) ./build/*.o
clean: rm -rf program.bin $(BUILDDIR)/*
# @ suppresses outputting the command to the terminal
run: @echo "Running program ..." ./program.bin
Info
In Makefiles, you can use certain symbols as prefixes to control the behavior of commands:
@: Suppresses the command echo, so the command itself won’t be printed to the terminal.
-: Ignores errors from the command, allowing the Makefile to continue even if the command fails.
+: Forces the command to be executed even if make is run with options that normally prevent command execution (like -n, -t, or -q).
Hiermee bereiken we echter niets meer mee dan een gewoon shell script daarom gaan we van de rule en dependecy met wat syntactische suiker om de kracht van Makefiles te unlocken:
# Declareer variabelen kan met `=`, `:=` of `::=`
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
SRCDIR= ./src
BUILDDIR= ./build
# declareer alle .c files
CFILES=$(SRCDIR)/main.c $(SRCDIR)/header.c
# declareer de corresponderende .o files
OBJECTS=$(BUILDDIR)/main.o $(BUILDDIR)/header.o
TARGET= program.bin
# Het is een good practice om altijd een `all` rule te implementeren
# In dit geval is de `all` afhankelijk van onze TARGET
all:$(TARGET)# Maar waar is onze TARGET afhankelijk van ...
# van alle object files, want enkel dan kunnen we linken tot een binary
$(TARGET):$(OBJECTS)$(CC) -o $@ $^
# Hierboven verwijzen we met $@ naar alles links van de `:` en met $^ alle elementen er rechts van
# Maar onze OBJECTS zijn op hun beurt weer afhankelijk van hun corresponderende .c files ...
# we gebruiken hier regular expressions waardoor % een wildcard is
$(BUILDDIR)/%.o:$(SRCDIR)/%.c$(CC)$(CFLAGS) -c -o $@ $<
# Hierboven verwijzen we met $@ naar alles links van de `:` en met $< (het corresponderende element) er rechts van
compile:$(TARGET)clean: rm -rf $(TARGET)$(OBJECTS)run:$(TARGET) ./$(TARGET)
We declareren als eerst de all-rule omdat wanneer je standaard geen command meegeeft aan make, de eerste rule uitgevoerd zal worden.
Met deze structuur zal er wanneer je make run ingeeft enkel gecompileerd worden wat gewijzigt is! Voor mog meer info kan je hier terecht
Maar we kunnen nog beter
Nu moeten we nog manueel alle source-files gaan benoemen, maar hier bestaat echter ook wat makefile ‘magic’ voor om dit te automatiseren: zie voorbeeld hieronder:
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
SRCDIR= ./src
BUILDDIR= ./build
# declareer alle .c files en gebruik de * wildcard om simpelweg alle .c bestanden te selecteren in de SRCDIR
CFILES=$(wildcard $(SRCDIR)/*.c)# declareer de corresponderende .o files via subsititutie en renaming
OBJECTS=$(patsubst $(SRCDIR)/%.c,$(BUILDDIR)/%.o,$(CFILES))TARGET= program.bin
all:$(TARGET)$(TARGET):$(OBJECTS)$(CC) -o $@ $^
$(BUILDDIR)/%.o:$(SRCDIR)/%.c$(CC)$(CFLAGS) -c -o $@ $<
compile:$(TARGET)clean: rm -rf $(TARGET)$(OBJECTS)run:$(TARGET) ./$(TARGET)
Nog steeds niet perfect maar buiten scope van deze cursus
Makefiles blijven een aantal beperkingen hebben waaronder dat wanneer je een CONSTANT in een header file aanpast, make niet noodzakelijk doorheeft dat je de file die gebruik maakt van de constant moet updaten. Dit valt op te lossen met wat ’elbow grease’ aan de make-syntax maar dat valt buiten de scope van deze cursus. Later gaan we toch ook gebruik maken van meer advanced build systems.
Oefening
Maak nu een Makefile voor de game van hierboven die dezelfde functionaliteit biedt als je gemaakte shell script.
Solution: Klik hier om de code te zien/verbergen🔽
# Directories
SRC_DIR= src
BUILD_DIR= build
# Doel binary
TARGET= game.bin
# Compiler en flags
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
# Alle bronbestanden en objectbestanden
SRCS=$(wildcard $(SRC_DIR)/*.c)OBJS=$(patsubst $(SRC_DIR)/%.c,$(BUILD_DIR)/%.o,$(SRCS))# Standaard doel: bouw de binary
all:$(TARGET)# Link de objectbestanden tot de uiteindelijke binary
$(TARGET):$(OBJS)$(CC)$(CFLAGS) -o $(TARGET)$(OBJS)# Compileer .c naar .o en plaats deze in de build map
$(BUILD_DIR)/%.o:$(SRC_DIR)/%.c|$(BUILD_DIR)$(CC)$(CFLAGS) -c $< -o $@# Zorg dat de build map bestaat
$(BUILD_DIR): mkdir -p $(BUILD_DIR)# Geef ook de optie om 'compile' als een commando mee te geven
compile:$(TARGET)# Voer de binary uit. Eventuele argumenten meegegeven met ARGS worden doorgegeven.
run:$(TARGET) ./$(TARGET)$(ARGS)# run as `make run ARGS="--your-flags"`
# Verwijder de binary en de build directory
clean: rm -f $(TARGET) rm -rf $(BUILD_DIR)
Breid de functionaliteit van je spel verder uit, door nieuwe Monsters te spawnen wanneer je een monster verslaat. Hou dan ook bij hoeveel monsters je verslagen hebt. Dat is je uitendelijke score wanneer je sterft.
Zoek op hoe je de library cJSON downloaden, toevoegen aan je applicatie en kan gebruiken in de main.c file.
Laat wanneer je sterft de applicatie de naam van de speler vragen en een JSON object aanmaken van de speler met naam en score en dit toevoegen aan een /resources/highscore.json bestand.
Voeg aan het begin van de game toe dat de huidige highscores van de json file geladen worden en getoond worden aan de speler.
(Geniet hierbij van het feit dat je een gemakkelijke makefile hebt om snel wijzigingen aan de code te testen.)
De cJSON-library is een voorbeeld van een dependency, we gaan hier nog dieper over in in het deel rond ‘Dependency management’
Klik hier om de code te zien/verbergen van een voorbeeld main.c programma dat gebruik maakt van cJSON🔽
#include<stdio.h>#include<stdlib.h>#include<string.h>#include"cJSON.h"// Function to read the JSON file
char*read_file(constchar*filename){FILE*file=fopen(filename,"rb");if(!file){returnNULL;}fseek(file,0,SEEK_END);longlength=ftell(file);fseek(file,0,SEEK_SET);char*data=(char*)malloc(length+1);fread(data,1,length,file);data[length]='\0';fclose(file);returndata;}// Function to write the JSON file
voidwrite_file(constchar*filename,constchar*data){FILE*file=fopen(filename,"wb");if(!file){perror("File opening failed");return;}fwrite(data,1,strlen(data),file);fclose(file);}intmain(){constchar*filename="scores.json";// Read the JSON file
char*json_data=read_file(filename);cJSON*root;if(!json_data){// File does not exist, create a new JSON object
root=cJSON_CreateArray();}else{// Parse the existing JSON data
root=cJSON_Parse(json_data);if(!root){printf("Error parsing JSON data\n");free(json_data);return1;}free(json_data);}// Create a new JSON object to add
cJSON*new_entry=cJSON_CreateObject();cJSON_AddStringToObject(new_entry,"name","Jane Doe");cJSON_AddNumberToObject(new_entry,"score",95);// Add the new entry to the JSON array
cJSON_AddItemToArray(root,new_entry);// Convert JSON object to string
char*updated_json_data=cJSON_Print(root);// Write the updated JSON data back to the file
write_file(filename,updated_json_data);// Clean up
cJSON_Delete(root);free(updated_json_data);return0;}
Dit is in principe iets wat je in het INF1 vak onbewust reeds uitvoerde door op de groene “Compile” knop te drukken van je NetBeans/IntelliJ IDE. Het is belangrijk om te weten welke principes hier achter zitten net als in C. Hieronder volgt dus een kort overzicht over het compileren van Java programma’s zonder een buildtool, later gaan we hier meestal een buildtool voor gebruiken om ons leven gemakkelijk te maken.
de Java Runtime Environment (JRE) om het commando java te gebruiken om gecompileerde Java programma’s te kunnen runnen.
de Java Development Kit (JDK) om het commando javac te gebruiken om Java broncode (.java-files) te compileren (en verzamelen in een jar-file.)
De Java Virtual Machine (JVM)
Waarom heb je nu toch een extra stukje software nodig om Java-applicaties te runnen? In C hebben we echter gezien dat we juist willen compileren naar een binary zodat we dit native kunnen uitvoeren. Java wil namelijk een oplossing bieden voor de ‘flaw’ in hoe C-programma’s werken. Zoals daar aangehaald compileer je een C-programma naar een bepaalde architectuur, daarom kan je een C-programma dat gecompileerd is voor een x86-cpu niet runnen op een arm-cpu bijvoorbeeld. Java lost dit probleem op door te compileren naar een speciale bytecode, die dan door de Java Virtual Machine (JVM) kan worden uitgevoerd op de onderliggende architectuur. De JVM vormt dus een laag tussen je bytecode en de hardware. Op die manier moet de gebruiker enkel één programma specifiek voor zijn/haar architectuur downloaden (de JVM) en kunnen de Java-binaries hetzelfde blijven. Je hoeft dan als developer geen meerdere verschillende binaries meer te voorzien. TOP!
LET OP: de Student klasse leeft in package student—die op zijn beurt wordt geïmporteerd in Main.java. Dat betekent dat we Student.java moeten bewaren in de juiste subfolder ofwel package. Dit zou je moeten herkennen vanuit INF1, waar de structuur ook src/main/java/[pkg1]/[pkg2] is. We hebben nu dus twee bestanden:
Alle files apart compileren levert .class files op in diezelfde folders. java Main zoekt dan nog steeds de student/Student.class file vanwege de import. Dit betekent dat je je programma moeilijker kan delen met anderen: er zijn nu twee bestanden én een subdirectory met juiste naamgeving vereist.
Gelukkig kan je met de juiste argumenten alle .class files in één keer genereren en die in een aparte folder—meestal genaamd build—plaatsen:
$ javac -d ./build *.java
$ cd build
$ ls
Main.class student
$ java Main
Heykes Jos
Java programma’s packagen
Omdat het vervelend is om verschillende bestanden te kopiëren naar andere computers worden Java programma’s typisch verpakt in een .jar bestand: een veredelde .zip met metadata informatie zoals de auteur, de java versie die gebruikt werd om te compileren, welke klasse te starten (die de main() methode bevat), … Indien deze metadata, in de META-INF subfolder, niet bestaat, worden defaults aangemaakt. Zie de JDK Jar file specification voor meer informatie.
We gebruiken een derde commando, jar, om, na het compileren naar de build folder, alles te verpakkken in één kant-en-klaar programma:
‘c’ voor “create” (aanmaken van een nieuwe JAR-file)
‘v’ voor “verbose” (gedetailleerde uitvoer)
‘f’ voor “file” (de naam van de JAR-file die je wilt maken).
Nu kunnen we programma.jar makkelijk delen. De vraag is echter: hoe voeren we dit uit, ook met java? Ja, maar met de juiste parameters, want deze moet nu IN het bestand gaan zoeken naar de juiste .class files om die bytecode uit te kunnen voeren: (In het onderstaande commando staat de -cp-flag voor Classpath. Hier geef je dus aan waar het java commando mag gaan zoeken naar .class-files naar de klasse die je wil uitvoeren)
$ java -cp "programma.jar" Main
Heykes Jos
Waarschuwing
Java classpath separators zijn OS-specifiek! Unix: : in plaats van Windows: ;.
Vanaf nu kan je programma.jar ook uploaden naar een Maven repository of gebruiken als dependency in een ander project. Merk opnieuw op dat dit handmatig aanroepen van javac in de praktijk wordt overgelaten aan de gebruikte build tool—in ons geval, gaan we dit eerst automatiseren met een Makefile.
Jar files inspecteren
Mocht je jar ooit niet goed werken kan het handig zijn om te inspecteren wat er juist allemaal in de jar-package zit. Je kan hier het volgende commando voor gebruiken: jar -tf naam.jar
Voorbeeld:
arne@LT3210121:~/ses/java-met-cli/build$ jar -tf programma.jar
META-INF/
META-INF/MANIFEST.MF
Main.class
student/
student/Student.class
Nu je de structuur ziet kan je ook makkelijk de main methode oproepen van de Student.class in de jar(als die methode zou bestaan) met java -cp "programma.jar" student.Student
Main class instellen
Merk op dat als je de jar wil runnen zonder een specifieke klasse mee te geven dan ga je nu een error krijgen in de vorm van no main manifest attribute, in programma.jar. We kunnen er wel voor zorgen dat automatisch de klasse Main gebruikt wordt. Hiervoor moeten we het attribuut Main-Class in de MANIFEST.MF file de waarde van de klassenaam meegeven (eventueel met packages ervoor).
Met het volgende commando kunnen we inspecteren hoe die MANIFEST file er nu uit ziet. unzip -q -c programma.jar META-INF/MANIFEST.MF. Voorlopig bestaat dat attribuut dus nog niet.
Met jar cvfe programma.jar Main * waar de ’e’ nu staat voor “entry point” (de Main-Class die je wilt specificeren).
Nu kan je je jar simpel runnen met java -jar programma.jar:
arne@LT3210121:~/ses/java-met-cli/build$ java -jar programma.jar
Hekyes Jos
Oefening
Extract alle files in dit zip bestand naar een directory naar keuze OF clone de repository. Schrijf een simpele makefile dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de /build-directory
jar : packaged alle klassen naar een jar genaamd ‘app.jar’ in de ‘build’-directory met entrypoint de ‘App’-klasse.
run : Voert de jar file uit
clean: Verwijdert de ‘.class’-bestanden en het ‘.jar’-bestand uit de ‘build’-directory
In tegenstelling tot programmeertalen waarvan de broncode eerst gecompileerd moet worden om te runnen (zoals Java en C), is Python een interpreted programming language. Dit betekent dat de broncode van Python direct wordt uitgevoerd door een interpreter, zonder dat er een aparte compilatiestap nodig is. De interpreter (de python software die je geïnstalleerd moet hebben) leest de broncode regel na regel en voert deze direct uit, wat het ontwikkelproces vaak sneller en flexibeler maakt. Dit komt omdat fouten direct tijdens het uitvoeren van de code kunnen worden opgespoord en gecorrigeerd, zonder dat de hele applicatie opnieuw gecompileerd hoeft te worden.
Het verschil met compiled languages is dat bij deze talen de broncode eerst wordt omgezet in machinecode door een compiler voordat de code kan worden uitgevoerd. Dit proces, bekend als compilatie, genereert een uitvoerbaar bestand dat direct door de computer kan worden uitgevoerd. Hoewel dit een extra stap toevoegt aan het ontwikkelproces, kan het resulteren in snellere uitvoeringstijden van de uiteindelijke applicatie, omdat de machinecode direct door de hardware wordt uitgevoerd zonder tussenkomst van een interpreter.
Een tussenoplossing tussen interpreted en compiled languages is Just-In-Time (JIT) compiling. JIT-compiling combineert aspecten van beide benaderingen door de broncode tijdens de uitvoering te compileren naar machinecode. Dit betekent dat de code aanvankelijk wordt geïnterpreteerd, maar dat veelgebruikte delen van de code tijdens de uitvoering worden gecompileerd naar machinecode om de prestaties te verbeteren. Talen zoals Java en C# maken gebruik van JIT-compiling om een balans te vinden tussen de flexibiliteit van interpreted languages en de snelheid van compiled languages.
Compilen naar .bin
Iedereen kan dus in principe door het python-commando te gebruiken je python bronbestanden runnen. We willen het de eindgebruiker echter zo simpel mogelijk maken, daarom gaan we met behulp van pinstaller al onze python files kunnen “compileren” naar een single binary, dat je dan kan runnen.
Je kan pyinstaller installeren met: sudo pip install pyinstaller --break-system-packages
Je kan nu met een simpel command je python applicatie compileren naar een binary: pyinstaller --onefile --name app.bin app.py
Je ziet meteen dat pyinstaller een build/<appname>-directory aanmaakt waar pyinstaller alle files zet die nodig zijn voor de omvorming tot een binary. Een tweede belangrijke file die aangemaakt wordt is de <appname>.spec, hierin kan je verschillende eigenschappen aanpassen zoals de targeted architecture bijvoorbeeld (target_arch)
Test nu eens je binary in de ./dist-directory met ./dist/app.bin.
Oefening
Extract alle files in dit zip bestand in een directory naar keuze OF clone de repository. Schrijf een simpele makefile dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de single ‘monstergame.bin’ file
Dependency management is een essentieel onderdeel van softwareontwikkeling. Het verwijst naar het beheren van alle externe libraries, modules, externe broncode … die een project nodig heeft om correct te functioneren. Deze dependencies (= afhankelijkheden) kunnen variëren van kleine hulpprogramma’s tot grote frameworks die een groot deel van de functionaliteit van een applicatie leveren.
Er zijn verschillende uitdagingen verbonden aan dependency management:
Versieconflicten: Wanneer verschillende dependencies verschillende versies van dezelfde bibliotheek vereisen, kunnen er conflicten ontstaan. Dit kan leiden tot bugs of zelfs het failen van de build.
Transitive dependencies: Dit zijn dependencies van dependencies. Het kan moeilijk zijn om bij te houden welke bibliotheken indirect worden geïmporteerd en of ze compatibel zijn met de rest van het project.
Beveiligingsrisico’s: Het gebruik van externe bibliotheken kan beveiligingsrisico’s met zich meebrengen, vooral als deze bibliotheken niet regelmatig worden bijgewerkt.
Compatibiliteit: Het kan een uitdaging zijn om ervoor te zorgen dat alle dependencies compatibel zijn met elkaar en met de gebruikte programmeertaal of runtime.
Tools zoals Gradle helpen bij het automatiseren en vereenvoudigen van dependency management. Hier zijn enkele redenen waarom we deze tools gebruiken:
Automatisering: tools zoals Gradle kunnen het proces van het downloaden en beheren van dependencies automatiseren. Dit betekent dat ontwikkelaars zich kunnen concentreren op het schrijven van code in plaats van het handmatig beheren van bibliotheken.
Versiebeheer: tools zoals Gradle bieden vaak geavanceerde mogelijkheden voor versiebeheer, waardoor het eenvoudiger wordt om versieconflicten op te lossen en ervoor te zorgen dat de juiste versies van bibliotheken worden gebruikt.
Transitive dependency management: vaak worden door deze tools transitieve dependencies automatisch beheerd, wat betekent dat het alle benodigde bibliotheken en hun dependencies downloadt en configureert.
Configuratiebeheer: het stelt ontwikkelaars ook vaak in staat eenvoudig verschillende configuraties in te stellen voor verschillende omgevingen (bijvoorbeeld ontwikkel-, test- en productieomgevingen) en/of verschillende architecturen en operating systems.
Reproduceerbaarheid: door een tool zoals Gradle wordt je software gebouwd met steeds dezelfde versies van bibliotheken, onafhankelijk van wat (en welke versies) op de machines van de ontwikkelaars geïnstalleerd werd. Dat maakt het makkelijker om bestaande software opnieuw te bouwen op een willekeurige machine.
Voorbeeld
Stel je voor dat je een project hebt dat afhankelijk is van een logging-library en een JSON-parser. De logging-library heeft op zijn beurt een specifieke versie van een utility-library nodig.
Met een dependency management tool (bv. Gradle) hoef je alleen maar de logging-library en de JSON-parser te specificeren in je buildscript, en de tool zorgt ervoor dat alle benodigde dependencies, inclusief de transitieve dependency (de utility-library) worden gedownload en correct worden geconfigureerd.
Door zo’n tools te gebruiken, kunnen we de complexiteit van dependency management dus aanzienlijk verminderen en ervoor zorgen dat onze projecten betrouwbaar en veilig blijven.
Tools voor dependency management
Enkele bekende tools voor dependency management zijn:
Gradle, Maven, Ant voor Java
(C/Q)Make (custom config) voor C/C++
npm, yarn, grunt, gulp, (in JS) … voor JS (nodejs)
pip voor Python
nuget (custom config, XML) voor .NET
In de volgende delen gaan we dieper in op deze concepten en er ook praktisch mee aan de slag. We bestuderen meer bepaald Gradle (Java), CMake (C) en pip (Python).
Subsecties van 4. Dependency Management
In Java (met Gradle)
Een voorbeeld
Een dependency, of afhankelijkheid, is een externe bibliotheek die wordt gebruikt tijdens de ontwikkeling van een toepassing. Tijdens het vak ‘Software ontwerp in Java’ zijn reeds de volgende externe libraries gebruikt:
Het vertrouwen op zo’n library houdt in dat een extern bestand, zoals een .jar of .war bestand, gedownload en gekoppeld wordt aan de applicatie. In Java koppelen we externe libraries door middel van het CLASSPATH: dat is een lijst van folders en jars die de compiler (bij het compilen) en de Java runtime (bij het uitvoeren) gebruikt om te zoeken naar de implementatie van de gebruikte klassen.
Laten we bijvoorbeeld eens kijken naar het gebruik van de Gson library om Json te genereren vanuit Java.
Serialisatie met behulp van Gson kan op deze manier:
Als we bovenstaande Main.java compileren zonder meer, krijgen we echter de volgende fout:
arne@LT3210121:~/ses/depmanag$ javac Main.java
Main.java:1: error: package com.google.gson does not exist
import com.google.gson.Gson; ^
Main.java:6: error: cannot find symbol
Gson gson= new Gson(); ^
symbol: class Gson
location: class Main
Main.java:6: error: cannot find symbol
Gson gson= new Gson(); ^
symbol: class Gson
location: class Main
3 errors
De klasse Arrays die we importeren is deel van de standaard Java-omgeving. Die zorgt dus niet voor problemen.
Maar de klasse com.google.gson.Gson hebben we niet zelf gemaakt, en willen we importeren uit een library.
We moeten de library daarom eerst downloaden.
(Je kan de jar ook rechtstreeks downloaden met behulp van curl via $ curl https://repo1.maven.org/maven2/com/google/code/gson/gson/2.12.1/gson-2.12.1.jar --output gson-2.12.1.jar. Indien je curl nog niet geïnstalleerd hebt doe dat dan eerst!)
Het programma compileren kan nu met javac -cp gson-2.12.1.jar Main.java. We geven de gedownloade jar mee aan het classpath (via de -cp optie). Dat zorgt ervoor dat de compiler de geïmporteerde klasse Gson nu wel kan terugvinden, en het compileren slaagt.
Om het programma uit te voeren, gebruiken we java -cp "gson-2.12.1.jar:." Main. Merk op dat er nu 2 zaken aan het classpath worden meegegeven: de Google jar, maar ook de huidige directory (.) om Main.class terug te vinden.
Opgelet!
Java classpath separators zijn OS-specifiek! Unix: : in plaats van Windows: ;.
Dit programma kan schematisch worden voorgesteld als volgt:
graph LR;
A["Main klasse"]
C["Gson 2.12.1"]
A -->|depends on| C
De dependency in bovenstaand voorbeeld is gson-2.12.1.jar. Een gemiddelde Java applicatie heeft echter meer dan 10 dependencies! Het beheren van deze bestanden en de verschillende versies (major, minor, revision) geeft vaak conflicten die beter beheerd kunnen worden door tools dan door de typische vergeetachtigheid van mensen. Dit kluwen aan afhankelijkheden, dat erg snel onhandelbaar kan worden, noemt men een Dependency Hell. Er zijn varianten: DLL Hell sinds 16-bit Windows versies, RPM Hell voor Redhat Linux distributies, en JAR Hell voor Java projecten.
De eenvoudigste manier om een library te gebruiken is de volgende procedure te volgen:
Navigeer naar de website van de library en download de jar in een bepaalde map, zoals /lib.
Importeer de juiste klasses met het import statement.
Compileer de code door middel van het -cp lib/dependency1.jar argument.
Voor kleine programma’s met slechts enkele libraries is dit meer dan voldoende. Het kost echter redelijk veel moeite om de juiste versie te downloaden: stap 1 kost meestal meer dan 5 minuten werk.
Notitie
Merk op dat jar files in een submap steken de syntax van de -cp parameter lichtjes wijzigt: bij compileren wordt het javac -cp "lib/*" Main.java en bij uitvoeren wordt het java -cp "lib/*:." Main. Zonder de toegevoegde punt (.) bij het java commando wordt de main methode in Main zelf niet gevonden. Wildcards zijn toegestaan. Zie ook Understanding the Java Classpath. In de praktijk worden build tools als Gradle gebruikt om projecten automatisch te builden, inclusief het doorgeven van de juiste parameters/dependencies.
Als er een nieuwe versie van de library verschijnt die je wil gebruiken (bv. met een nieuwe feature of een bugfix), moet je dat eerst en vooral zelf nagaan, de jar van de nieuwe versie downloaden, je classpath aanpassen, en alles opnieuw compileren.
Ook bij de uitvoering moet je zorgen dat je de nieuwe versie gebruikt.
Apache Maven
Maven is een build tool van de Apache Foundation om de software te compileren en afhankelijkheden te beheren. Maven is de voorloper van Gradle en bestaat reeds 15 jaar.
Een Maven project heeft een pom.xml bestand (Project Object Model), waarin in XML formaat wordt beschreven hoe de structuur er uit ziet, welke libraries men gebruikt, en zo voort:
Maven is erg populair in de Java wereld, waardoor er verschillende servers zijn die deze pom bestanden samen met hun libraries beheren, zoals de Central Maven Repository en de Google Maven Repository mirrors. De syntax van het configuratiebestand is echter erg onoverzichtelijk, en er zijn ondertussen betere alternatieven beschikbaar, zoals Gradle.
We gaan in deze cursus dus geen gebruik maken van Maven, maar je zal wel verwijzingen naar de Maven repositories tegenkomen bij het gebruik van Gradle.
Gradle
Gradle is, net zoals Maven, een build tool voor de Java wereld (en daarbuiten) die de automatisatie van releasen, builden, testen, configureren, dependencies en libraries managen, … eenvoudiger maakt. Kort gezegd: het maakt het leven van een ontwikkelaar eenvoudiger.
Gradle bouwt verder op de populariteit van Maven door bijvoorbeeld compatibel te zijn met de Repository servers, maar de grootste pijnpunten wegneemt: een moeilijk leesbaar configuratiebestand in XML en complexe command-line scripts.
In een config bestand genaamd build.gradle schrijft men met Groovy, een dynamische taal bovenop de JVM (Java Virtual Machine), op een descriptieve manier hoe Gradle de applicatie moet beheren.
Je build-file is dus een uitvoerbaar (Groovy) script dat gebruik maakt van Gradle-specifieke functies.
Info
Gradle configuratiebestanden kunnen ook in Kotlin geschreven worden (build.gradle.kts) in plaats van Groovy.
Deze optie wint aan populariteit, en is sinds Gradle 8.2 (2023) de default, maar we gebruiken in deze cursus nog de Groovy syntax. De verschillen zijn klein.
Voordelen van Gradle
De grootste voordelen van een build en dependency management tool zoals Gradle zijn onder andere:
Een kleine voetafdruk van de broncode (repository). Het is niet nodig om zelf alle jars van libraries te downloaden en bij te houden in een lib/ folder: Gradle doet dit immers voor jou.
Een project bootstrappen in luttele seconden: download code, voer de Gradle wrapper uit, en alles wordt vanzelf klaargezet (de juiste Gradle versie, de juiste library versies, …)
Een project bootstrappen betekent het opzetten of initialiseren van een project vanaf het begin, vaak met behulp van een tool of framework dat de basisstructuur en configuratie voor je genereert. Dit proces helpt je snel aan de slag te gaan zonder dat je alles handmatig hoeft in te stellen.
Platform- en machine-onafhankelijk projecten bouwen en uitvoeren: een taak uitvoeren via een build tool op mijn PC doet exact hetzelfde als bij jou, dankzij de beschrijving van de stappen in de config file.
Om een library als Gson te kunnen gebruiken, moet je dus niet zelf de jar-bestanden aanleveren; het volstaat simpelweg om twee regels in de gradle-configuratie toe te voegen.
Gradle installeren
Je kan Gradle op je WSL installeren met het commando sudo snap install gradle --classic. (Zie ook Gradle Docs: installing manually) Dit installeert echter niet altijd de nieuwste versie van Gradle, in dit geval v7.2, maar dat is geen probleem (hier komen we zo dadelijk op terug).
Er zijn ook andere manieren om Gradle te installeren, bijvoorbeeld met SDKMAN!. Dit is een tool om allerhande (Java-gebaseerde) Software Development Kits (SDKs) op je systeem te installeren en beheren, en eenvoudig te wisselen tussen versies. Eens SDKMAN! geïnstalleerd is, kan je eenvoudig de laatste versie van gradle installeren met sdk install gradle.
Gradle in VSCode
Je kan ondersteuning toevoegen voor Gradle in VSCode met de juiste extensie, zie Java development environment in VSCode.
In het bijzonder voor Gradle is de Gradle for Java plugin van Microsoft aangewezen.
Deze is deel van het Extension Pack for Java, waarmee je ineens ook andere nuttige extensies voor Java-ontwikkeling installeert.
Deze extensie geeft je extra ondersteuning voor het editeren van je gradle.build bestand (syntax highlighting, code completion).
Bovendien kan je voor je projecten ook de verschillende Gradle-taken bekijken en uitvoeren, alsook nagaan welke dependencies er in welke configuratie (compile, runtime, test) geactiveerd zijn — wat dat precies inhoudt, komt zodadelijk aan bod.
# Gradle vraagt eerst welk soort project je wil aanmaken, we kiezen voor 2. applicationSelect type of project to generate:
1: basic
2: application
3: library
4: Gradle plugin
Enter selection (default: basic)[1..4]2# Nu vraagt Gradle welke programmeertaal we willen gebruiken, we kiezen voor 3. JavaSelect implementation language:
1: C++
2: Groovy
3: Java
4: Kotlin
5: Scala
6: Swift
Enter selection (default: Java)[1..6]3# Nu vraagt Gradle te kiezen tussen een het soort project, we kiezen voor 1. only one application projectSplit functionality across multiple subprojects?:
1: no - only one application project
2: yes - application and library projects
Enter selection (default: no - only one application project)[1..2]1# Nu vraagt Gradle te kiezen tussen programmeertalen voor ons build script (de taal waarmee we onze build.gradle file gaan programmeren), we kiezen voor 1. GroovySelect build script DSL:
1: Groovy
2: Kotlin
Enter selection (default: Groovy)[1..2]1# Nu vraagt Gradle te kiezen tussen een testframework, we kiezen voor 1. JUnit 4Select test framework:
1: JUnit 4 2: TestNG
3: Spock
4: JUnit Jupiter
Enter selection (default: JUnit Jupiter)[1..4]1# Nu vraagt Gradle een projectnaam, default is dit de directorynaam. Vul niets in en druk op enter om de default te gebruiken.Project name (default: gradletest):
# Als laatste vraagt Gradle je de naam van de source package te kiezen. Gelijkaardig als in INF 1 kiezen we voor be.ses.<app_name>Source package (default: gradletest): be.ses.my_application
Gradle vraagt ons tijdens de init een aantal opties te kiezen. Alhoewel we in deze lessen 90% van de tijd de opties kiezen zoals hierboven getoond in het voorbeeld, kan je hieronder toch een overzicht terugvinden met enkele andere opties:
Select type of build to generate: opties - Application - Library (gaan we niet verder op in) - Gradle Plugin (gaan we niet verder op in) - Basic
Application: Dit type is geconfigureerd om een volwaardige uitvoerbare applicatie te bouwen. Het bevat extra configuraties en plugins, zoals de application plugin, die helpt bij het definiëren van de hoofdmethode en het maken van uitvoerbare JAR-bestanden. Geschikt voor het ontwikkelen van volledige applicaties die je kunt uitvoeren en distribueren. (99% van de tijd gaan we dit type gebruiken)
Basic: Dit is een eenvoudig project zonder specifieke plugins of configuraties. Het bevat alleen de minimale structuur en bestanden die nodig zijn om een Gradle-project te starten. Je kan dan enkel nog de projectnaam kiezen en de programmeertaal voor Gradle.
Select implementation language: Je ziet dat Gradle dus ook voor andere programmeertalen gebruikt kan worden. Wij kiezen hier echter voor Java.
Select application structure: opties - 1. only one application project - application and library projects
Only one application project: Dit type project is gericht op het bouwen van één enkele applicatie. De projectstructuur is eenvoudig en bevat meestal alleen de bronbestanden en configuratiebestanden die nodig zijn om de applicatie te bouwen en uit te voeren. Geschikt voor kleinere projecten of wanneer er geen behoefte is aan herbruikbare componenten.
Application and library project: Dit type project is opgesplitst in meerdere modules, waaronder een applicatiemodule en een of meer bibliotheekmodules. De bibliotheekmodules bevatten herbruikbare code die door de applicatiemodule kan worden gebruikt. Deze structuur bevordert modulariteit en hergebruik van code, wat vooral nuttig is voor grotere projecten of wanneer je van plan bent om delen van je code in andere projecten te gebruiken.
Info
Je kan al die opties ook als flags meegeven aan het init-commando. Voor het voorbeeld hierboven wordt dat:
Bij het aanmaken van je project maakt Gradle een aantal folders en bestanden aan. We overlopen hieronder de functionaliteit van de belangrijkste onderdelen.
Ontleding van een Gradle project mappenstructuur
Als we kijken naar de bestanden- en mappenstructuur van een voorbeeld Gradle project, vinden we dit terug:
Broncode (.java bestanden) van het app subproject in src/main/java en src/test/java, met productie- en testcode gescheiden.
Eventueel resources (bv. afbeeldingen, html en css voor webapplicaties …)
Gecompileerde code (.class bestanden) in de build/ (of ook wel out) folder.
Een gradle map, met daarin de Gradle-wrapper en bijhorende configuratie (hier komen we zodadelijk op terug). Deze folder hoor je toe te voegen aan je versiebeheersysteem (git).
Twee executables (gradlew.bat voor Windows en een gradlew-shell script voor Linux/Unix). Ook deze twee executables voeg je toe aan git.
Twee Gradle configuratie-bestanden:
settings.gradle voor het project als geheel. Hierin kan je de projectnaam aanpassen: rootProject.name = 'new_name'. Je lijst hier ook de verschillende subprojecten op: include('app').
build.gradle: eentje per subproject (hier enkel app). Hierin specifieer je de dependencies en andere instellingen om dat specifieke subproject te bouwen.
Later kan er ook een verborgen .gradle map verschijnen. De inhoud hiervan hoort niet thuis in je versiebeheersysteem!
Gradle wrapper (gradlew)
Wanneer je een Gradle project aanmaakt, creëert Gradle vanzelf ook een wrapper. Dat is een soort lokale executable in de vorm van een ./gradlew-executable (of gradlew.bat voor op Windows).
Dit wrapper-script zal, wanneer het uitgevoerd wordt, een specifieke versie van Gradle downloaden in de gradle-map.
Dit heeft enkele voordelen:
Consistentie: Het zorgt ervoor dat iedereen die aan het project werkt dezelfde versie van Gradle gebruikt, ongeacht de versie die lokaal is geïnstalleerd. (Door steeds de gradlew in de projectdirectory te gebruiken)
Gemak: Gebruikers hoeven Gradle niet apart te installeren, omdat de wrapper automatisch de juiste versie downloadt en gebruikt. Enkel om initieel een project aan te maken heb je een lokale versie van Gradle nodig.
Automatisering: Het maakt het eenvoudiger om build-scripts en CI/CD-pijplijnen te configureren (zie een later hoofdstuk), omdat de wrapper de benodigde Gradle-versie beheert.
De specifieke versie van Gradle die je gebruikt hangt (onder andere) af van de Java-versie die je gebruikt in je project.
Hier vind je een overzicht van de minimum-versies van Gradle die compatibel zijn met welke Java-versies (JVM provided by JRE or JDK).
Eens je weet welke versie van Gradle je wil gebruiken, kan je de lokale gradlew updaten met het volgende commando: ./gradlew wrapper --gradle-version x.x (bijvoorbeeld 8.13 voor Java versies 23 of ouder).
Kijk na of je de gewenste versie gebruikt met ./gradlew --version.
Tip
Soms is je Java-versie te nieuw om een oude Gradle-wrapper uit te voeren en de Gradle-versie te updaten (bijvoorbeeld JDK 17 met Gradle 6.7 in plaats van 7.0 of nieuwer). Je krijgt dan een foutmelding zoals General error during conversion: Unsupported class file major version 65 of Could not initialize class `org.codehaus.groovy.reflection.ReflectionCache` .
Om dit op te lossen, kan je de te gebruiken versie van Gradle ook rechtstreeks specifiëren in gradle/wrapper/gradle-wrapper.properties, door het versienummer in de distributionUrl aan te passen.
Gradle laat je soms zelf ook wel weten naar welke versie je moet updaten aan de hand van je gebruikte Java code.
Bij het uitvoeren van gradlew gebeurt hetvolgende:
De wrapper downloadt de juiste versie van Gradle zelf (dus installatie van Gradle via snap/SDKMAN!/… is niet nodig voor een bestaand Gradle-project), afhankelijk van de specificaties in de properties file.
Vervolgens downloadt Gradle de juiste libraries om het project te kunnen compilen en uitvoeren.
Aan deze wrapper kan je commando’s meegeven (gradle tasks, zie later). Bijvoorbeeld, ./gradlew run om je programma (te compileren en) uit te voeren:
Dit is exact hetzelfde als in een IDE zoals IntelliJ het project runnen met de knop ‘Run’ (play-knop):
Ontleding van build.gradle
De belangrijkste file voor Gradle is de build.gradle file die zich in de ./app directory bevindt. Die ziet er als volgt:
/* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Java application project to get you started.
* For more details take a look at the 'Building Java & JVM projects' chapter in the Gradle
* User Manual available at https://docs.gradle.org/7.2/userguide/building_java_projects.html
*/plugins{// Apply the application plugin to add support for building a CLI application in Java.
id'application'}repositories{// Use Maven Central for resolving dependencies.
mavenCentral()}dependencies{// Use JUnit test framework.
testImplementation'junit:junit:4.13.2'// This dependency is used by the application.
implementation'com.google.guava:guava:30.1.1-jre'}application{// Define the main class for the application.
mainClass='be.ses.my_application.App'}
Met de Groovy syntax definiëren we verschillende configuratie-blokken als bloknaam { ... }. We onderscheiden volgende blokken:
plugins: hier kan je plugins voor Gradle toevoegen, je voegt ze toe op basis van id
id 'application': de plugin voor Java (stand-alone) applicaties. Dit voegt taken toe zoals build en test voor je applicatie.
repositories: hiermee specificeer je waar de dependencies in de dependencies functie gezocht en gedownload moeten worden. Meestal gebruik je hier de default, namelijk de standaard maven central repository (ingebouwde URL).
dependencies: hiermee specificeer je de dependencies voor je project. Dependencies worden toegevoegd met een zogenaamde dependency configuration, die aangeeft wanneer ze nodig zijn. De meest voorkomende zijn:
implementation (productie dependencies): deze dependencies zijn beschikbaar bij het compileren en uitvoeren van alle code.
testImplementation (test dependencies): deze dependencies zijn enkel beschikbaar bij het compileren en uitvoeren van test-code.
runtimeOnly: deze dependencies worden enkel gebruikt bij het uitvoeren van de applicatie.
Als argument moet je de dependency opgeven in de vorm groep:naam:versie. Je vindt deze meestal makkelijk terug op de gebruikte repository.
application: met mainClass = 'be.ses.my_application.App' geef je aan welke main-methode van welke klasse moet gerund worden wanneer je je applicatie wil runnen. (Dit is dus het entrypoint van je applicatie)
Dependencies toevoegen
In het kort volg je volgende procedure als je Gradle je dependencies laat beheren:
Bij het uitvoeren van gradle downloadt Gradle automatisch de juiste opgegeven versie van de Gson library en gebruikt die om je applicatie te compileren en uit te voeren.
De download komt niet terecht in je project maar in een gedeelde cache-folder, zodat elke versie van een library slechts éénmaal gedownload wordt op je systeem.
Die cache-folder staan in een submap van je home folder: ~/.gradle. Dit kan je controleren door ls ~/.gradle/caches/modules-2/files-2.1/, waar je nu dus ook de com.google.code.gson-directory terug vindt. Met tree ~/.gradle/caches/modules-2/files-2.1/com.google.code.gson kan je eens inspecteren hoe die directory er juist uitziet. (Indien je tree nog niet geïnstalleerd hebt doe dat dan eerst!)
Deze cache-folder kan groeien naarmate je meer met Gradle werkt en meer versies van libraries downloadt. Je mag deze cache-folder gerust verwijderen van je systeem; de volgende keer zullen de nodige dependencies gewoon opnieuw gedownload worden.
De voordelen van het gebruik van Gradle voor dependencies zijn dus:
Het zoeken van libraries beperkt zich tot één centrale (Maven Repository) website, waar alle verschillende versies duidelijk worden vermeld.
Het downloaden van libraries beperkt zich tot één centrale locatie op je harde schijf (~/.gradle/caches/modules-2/files-2.1/): 10 verschillende Java projecten die gebruik maken van Gson vereisen linken naar dezelfde gradle bestanden. Je hebt dus geen 10 kopieën nodig van de Gson.jar.
Het beheren van dependencies en versies beperkt zich tot één centraal configuratiebestand: build.gradle. Dit is (terecht) een integraal deel van het project!
Er bestaan twee types van dependencies: directe (soms ook harde dependency genoemd) en transitieve (zachte dependency).
Een directe dependency is een afhankelijkheid die het project nodig heeft, zoals het gebruik van Gson, waarbij dit in de dependencies {} config zit.
Een transitieve of indirecte dependency is een dependency van een dependency. In een van de oefeningen hieronder maken we een project (1) aan, dat een project (2) gebruikt, dat Gson gebruikt. In project 1 is project 2 een directe dependency, en Gson een transitieve. In Project 2 is Gson een directe dependency (en komt project 1 niet voor):
graph LR;
A[Project 1]
B[Project 2]
C[Gson]
A --> B
B --> C
A -.-> C
Deze transitieve dependencies worden afgehandeld door Groovy. Het is niet nodig om ze toe te voegen aan je dependencies {} configuratie.
Meer zelfs, als je fouten krijgt gerelateerd aan dependencies, is het geen goed idee om de zachte (transitieve) dependency (stippellijn) te veranderen in een harde, door die als directe dependency toe te voegen in de configuratie. Gradle biedt hier betere alternatieven voor.
Gradle tasks
./gradlew tasks --all voorziet een overzicht van alle beschikbare taken voor een bepaald Gradle project, opgesplitst per fase (build tasks, build setup tasks, documentation tasks, help tasks, verification tasks). Gradle plugins voorzien vaak extra tasks, zoals bijvoorbeeld de maven plugin om te publiceren naar repositories.
Belangrijke taken zijn onder andere:
test: voer alle unit testen uit. Een rapport hiervan is beschikbaar op build/reports/tests/test/index.html. (Hier komen we zeker nog op terug in het hoofdstuk rond test-driven development)
clean: verwijder alle binaries en metadata.
build: compile en test het project.
publish: (maven plugin) publiceer de gebouwde versie naar een repository.
jar: compile en package in een jar bestand
javadoc: (plugin) genereert HTML javadoc. Een rapport hiervan is beschikbaar op build/docs/javadoc/index.html.
Onderstaande screenshot is een voorbeeld van een Unit Test HTML rapport dat gegenereerd wordt elke keer de test task uitgevoerd wordt:
Compile to JAR
Zoals we in het hoofdstuk rond build systems in Java gezien hebben kan je alle bestanden groeperen in een .jar bestand om er een ’executable’ van te maken die door iemand anders uitgevoerd kan worden op een JVM. Om zo’n jar te maken gebruik je het commando ./gradlew jar. Er wordt dan een main_classname.jar aangemaakt in je /app/build/libs directory.
Zonder extra opties in je build.gradle wordt er echter geen 'Main-Class'-attribuut toegevoegd aan de MANIFEST file van je jar. Daarom kan je volgende optie instellen in je build.gradle waarbij application.mainClass een referentie is naar de value die je daar hebt ingesteld:
jar{manifest{attributes('Main-Class':application.mainClass// dit maakt een verwijzing naar de mainClass eigenschap die je in het application {} blok hebt ingesteld
)}archiveBaseName='myJarName'// enkel als je de naam van de gegenereerde jar wil wijzigen
}
Weetje
We kunnen ook zelf een kleine task coderen in Groovy die simpelweg de ‘group’ van ons project uitprint:
taskexample{printlnproject.group}
We gebruiken deze dan via ./gradlew example.
Fat jars (shadow jars)
Merk op dat een typisch project dat gebouwd of uitgevoerd wordt via Gradle geen jars van de dependencies bevat. Die worden immers automatisch door Gradle gedownload en in de juiste map (de Gradle cache) geplaatst.
Bij het maken van een jar van je applicatie zal Gradle standaard de dependencies dus niet mee in jouw jar file steken. Dat is logisch: Gradle geeft de voorkeur aan het scheiden van de applicatiecode en de dependencies. Hierdoor blijft de jar file kleiner en wordt het eenvoudiger om dependencies te beheren en bij te werken.
Wil je nu toch dat een (eind)gebruiker bijvoorbeeld niet zelf aan dependency management via Gradle moet doen, dan is het mogelijk om ook toch de applicatie en alle dependencies te bundelen in één grote jar file. Dit wordt een uber jar, fat jar, of shadow jar genoemd. De gebruiker heeft dan alles om je code uit te voeren zolang hij/zij over de juiste versie van de JVM beschikt.
Je kan Gradle zo een shadowJar laten aanmaken op deze manier:
Voeg de Shadow plugin toe aan je build.gradle bestand:
Bouw je project met de shadow jar taak: ./gradlew shadowJar
Hieronder zie je het verschil tussen compileren tot een shadowJar of een gewone jar:
arne@LT3210121:~/ses/depgradle/app/build/libs$ ls
app-1.0-SNAPSHOT-shadow.jar app-1.0-SNAPSHOT.jar
# Trying to run normal jar via cli manuallyarne@LT3210121:~/ses/depgradle/app/build/libs$ java -jar app-1.0-SNAPSHOT.jar
Exception in thread "main" java.lang.NoClassDefFoundError: com/google/gson/Gson
at be.ses.depgradle.App.main(App.java:10)Caused by: java.lang.ClassNotFoundException: com.google.gson.Gson
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:641) at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:188) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:526) ... 1 more
# Trying to run shadowJar via cli manuallyarne@LT3210121:~/ses/depgradle/app/build/libs$ java -jar app-1.0-SNAPSHOT-shadow.jar
1
Aangezien we toch meestal gebruik gaan maken van build tools zoals Gradle die steeds zelf de nodige dependecies download en toevoegt is het gebruik van de shadowJar in deze cursus echter beperkt
Meer output
De standaard output geeft enkel weer of er iets gelukt is of niet:
Je kan meer informatie krijgen met de volgende parameters:
--info, output LogLevel INFO. Veel irrelevante info wordt ook getoond.
--warning-mode all, toont detail informatie van warning messages
--stacktrace, toont de detail stacktrace bij exceptions
Repositories
Zoals eerder vermeld gebruikt Gradle Maven-repositories om de bestanden (denk: de .jar) van alle opgelijste dependencies op te halen.
We bekijken hier hoe je extra repositories kan toevoegen, wat in zo’n repository zit, en hoe je zelf kan publiceren naar een repository.
Extra repositories toevoegen
Veelgebruikte libraries zijn eenvoudig te vinden via de Central Maven Repository. Wanneer echter een eigen library werd gecompileerd, die dan in andere projecten worden gebruikt, schiet deze methode tekort: interne libraries zijn uiteraard niet op een publieke server gepubliceerd.
mavenCentral(), jcenter(), en google() zijn ingebouwde repositories. Eigen Maven folders en URLs toevoegen kan ook.
Tenslotte kan je ook een lokale folder toevoegen:
repositories{flatDir{dirs'lib'}}
Door nu de nodige .jar files toe te voegen aan de folder ./app/lib kunnen de juiste dependencies ook gevonden worden. Indien de ./app/lib directory nog niet bestaat, ga je die eerst moeten toevoegen.
Deze laatste manier is vooral handig wanneer je een library (.jar) wil gebruiken die niet via een repository beschikbaar zijn. Zo kan je deze dependencies toch nog via Gradle beheren.
Een jar uit zo’n flatDir repository als dependency toevoegen doe je als volgt:
Klik op ‘View All’ bij de Gson module op de MVN Central Repo om te inspecteren welke bestanden typisch worden aangeleverd in een Maven repository:
De library zelf, in een bepaalde versie (gson-2.12.1.jar).
Eventueel de javadoc en/of sources als aparte jars (gson-2.12.1-javadoc.jar, gson-2.12.1-sources.jar).
Een .pom XML bestand (gson-2.12.1.pom).
metadata over het build-proces(gson-2.12.1.buildinfo)
checksums (md5 en sha1) en digitale handtekeningen (asc) op alle vorige bestanden
Het .pom XML bestand beschrijft welke afhankelijkheden deze module op zich heeft. Zo kan een hele dependency tree worden opgebouwd! Het beheren van alle afhankelijkheden is complexer dan op het eerste zicht lijkt, en laat je dus beter over aan deze gespecialiseerde tools. Google heeft voor Gson enkel Junit als test dependency aangeduid:
Grote projecten kunnen makkelijk afhankelijk zijn van tientallen libraries, die op hun beurt weer afhankelijk zijn van meerdere andere libraries.
Hieronder een voorbeeld van een dependency tree voor een typische grote webapplicatie geschreven in Java:
Je kan deze opvragen via Gradle met de de task dependencies: ./gradlew dependencies. Detailinformatie voor specifieke dependencies kunnen worden opgevraagd met de dependencyInsight task. Zie ook: Viewing and debugging dependencies in de Gradle docs.
Publiceren naar een Maven Repository
Gradle voorziet een plugin genaamd ‘maven-publish’ die bovenvermelde bestanden automatisch aanmaakt, zodat je jouw project kan uploaden naar een online repository, zoals Maven central, of een lokale maven repository. Op die manier kunnen andere projecten jouw project dan weer als dependency gaan gebruiken. Activeer de plugin en voeg een publishing block toe met de volgende eigenschappen:
plugins{id'java'id'maven-publish'// toevoegen!
}group='be.ses'version='1.0-SNAPSHOT'publishing{publications{maven(MavenPublication){groupId=project.group.toString()version=versionartifactId='projectnaam'fromcomponents.java}}repositories{maven{url="/home/arne/local-maven-repo"// gebruik je eigen home-folder!
}}}
Indien die directory nog niet bestaat wordt deze aangemaakt!
Windows-gebruikers dienen in de url value te werken met dubbele backslashes (\\) in plaats van forward slashes (/) om naar het juiste pad te navigeren.
Deze uitbreiding voegt de target publish toe aan Gradle. Dus: ./gradlew publish publiceert de nodige bestanden in de aangegeven folder.
De aangemaakte lokale Maven repository ziet er nu zo uit:
Een Gradle project dat nu gebruik wilt maken van de libraries in die lokale Maven repository dient enkel een tweede Maven repository plaats te definiëren:
repositories{mavenCentral()maven{url="/home/arne/local-maven-repo"// gebruik je eigen home-folder!
}}
In de praktijk ga je natuurlijk eerder een gedeelde (al dan niet interne) locatie gebruiken als repository, en geen map op je eigen harde schijf.
Dat laatste doet immers veel van de voordelen van het gebruik van Gradle teniet.
Oefeningen
Oefening 1: Hoger lager
Maak een nieuw Gradle project aan met de naam: higher_lower en gebruik de packagenaam be.ses.higher_lower.
Hint
Om een packagenaam in te stellen in recentere versies van gradle, moet je het --package argument meegeven:
gradle init --package be.ses.higher_lower.
Delete de test in app/src/test/java/be/ses/higher_lower/App.java. Anders zal je je project niet kunnen runnen.
Aangezien we input aan de gebruiker gaan vragen moeten we een extra optie instellen in de app/build.gradle:
run{standardInput=System.in}
Kopieer onderstaande code voor de klasse app/src/main/java/be/ses/higher_lower/App.java:
App.java (klik om te tonen)
packagebe.ses.higher_lower;importjava.util.Random;importjava.util.Scanner;publicclassApp{publicstaticvoidmain(String[]args){Scannerscanner=newScanner(System.in);Randomrandom=newRandom();System.out.println("Welcome to the Higher or Lower game!");System.out.println("Guess if the next number will be higher or lower.");intcurrentNumber=random.nextInt(100)+1;booleanplaying=true;intscore=0;while(playing){System.out.println("Current number: "+currentNumber);System.out.print("Will the next number be higher or lower? (h/l): ");Stringguess=scanner.next().toLowerCase();intnextNumber=random.nextInt(100)+1;if((guess.equals("h")&&nextNumber>currentNumber)||(guess.equals("l")&&nextNumber<currentNumber)){System.out.println("Correct! The next number was: "+nextNumber);score++;}else{System.out.println("Wrong! The next number was: "+nextNumber);playing=false;}currentNumber=nextNumber;}System.out.println("Game over! Your final score: "+score);scanner.close();}}
Test je programma: Aangezien we input vragen via de scanner moeten we ook op een speciale manier ons project runnen: gebruik ./gradlew --console plain run (of ./gradlew -q --console plain run om helemaal geen output van gradle tasks ertussen te zien.)
Maak een jar via Gradle.
Copy de app/build/libs/app.jar-file naar een andere directory en hernoem naar higherLower.jar.
Run de jar via de terminal: java -jar higherLower.jar. Je krijgt een foutmelding gerelateerd aan het niet vinden van een main-klasse. Los die op (zie de uitleg hierboven) en probeer opnieuw.
Oefening 2: Scorebord-library
Ontwerp een eenvoudige library genaamd ‘scorebord’ die scores kan bijhouden voor bordspelletjes. Deze library kan dan gebruikt worden door toekomstige digitale Java bordspellen (en zal gebruikt worden door onze hoger-lager app).
In een Scorebord kan je spelers toevoegen door middel van een naam en een score. Er is een mogelijkheid om de huidige score van een speler op te vragen, en de winnende speler. Deze gegevens worden met behulp van Gson in een json bestand bewaard, zodat bij het heropstarten van een spel de scores behouden blijven.
packagebe.ses.scorebord;importjava.io.IOException;importjava.nio.file.Files;importjava.nio.file.Path;importjava.util.ArrayList;importjava.util.Comparator;importjava.util.List;importjava.util.NoSuchElementException;importcom.google.gson.Gson;publicclassScorebord{privateList<SpelerScore>spelerScores=newArrayList<>();publicvoidsetScore(Stringname,intcurrentScore){spelerScores.add(newSpelerScore(name,currentScore));spelerScores.sort(Comparator.comparing(ss->ss.getScore()));}publicintgetScoreOf(Stringname){for(vars:spelerScores){if(s.getName().equals(name)){returns.getScore();}}thrownewNoSuchElementException("No player with that name");}publicStringgetWinner(){SpelerScorewinner=null;for(varss:spelerScores){if(winner==null||ss.getScore()>winner.getScore()){winner=ss;}}returnwinner.getName();}@OverridepublicStringtoString(){Stringresult="";for(varss:spelerScores){result+=ss.getName()+": "+ss.getScore()+"\n";}returnresult;}publicvoidsaveToJson(Stringfilename)throwsIOException{vargson=newGson();varjson=gson.toJson(this);Files.write(Path.of("scorebord.json"),json.getBytes());}publicstaticScorebordgetScorebordFromJson(Stringfilename)throwsIOException{if(!Files.exists(Path.of(filename))){returnnewScorebord();}vargson=newGson();varjson=Files.readString(Path.of("scorebord.json"));varscorebord=gson.fromJson(json,Scorebord.class);returnscorebord;}}
De klasse SpelerScore is een intern hulpmiddel om te serialiseren van/naar JSON. Deze klasse wordt gebruikt in de implementatie van Scorebord.
Maak via de CLI een nieuw Gradle - Java project. Groupid: be.ses. Geef je project de naam: scorebord.
Configureer Gradle zodat het commando gradlew jar een bestand scorebord-1.0.jar creëert in de build/libs folder.
Tip: je update best je gradle wrappen naar versie 8.13 of hoger.
Oefening 3: Hoger lager met scorebord
Voeg dat bovenstaand scorebord project als een library toe aan higher_lower-applicatie uit de eerste oefening. Kopieer de scorebord-1.0.jar-jarfile lokaal in een ./app/lib folder in je higher_lower project en instrueer Gradle zo dat dit als flatDir repository wordt opgenomen (zie boven). Update nu ook de App klasse in de higher_lower-applicatie:
Nieuwe App.java
packagebe.ses.higher_lower;importjava.io.IOException;importjava.util.Random;importjava.util.Scanner;importbe.ses.scorebord.Scorebord;publicclassApp{publicstaticvoidmain(String[]args)throwsIOException{Scannerscanner=newScanner(System.in);Randomrandom=newRandom();Scorebordscorebord=Scorebord.getScorebordFromJson("highscores.json");System.out.println("Welcome to the Higher or Lower game!");System.out.println("This is the current leaderboard: \n"+scorebord+"\n\n");System.out.println("Guess if the next number will be higher or lower.");intcurrentNumber=random.nextInt(100)+1;booleanplaying=true;intscore=0;while(playing){System.out.println("Current number: "+currentNumber);System.out.print("Will the next number be higher or lower? (h/l): ");Stringguess=scanner.next().toLowerCase();intnextNumber=random.nextInt(100)+1;if((guess.equals("h")&&nextNumber>currentNumber)||(guess.equals("l")&&nextNumber<currentNumber)){System.out.println("Correct! The next number was: "+nextNumber);score++;}else{System.out.println("Wrong! The next number was: "+nextNumber);playing=false;}currentNumber=nextNumber;}System.out.println("Game over! Your final score: "+score);System.out.println("What is your name?");Stringname=scanner.next();scorebord.setScore(name,score);System.out.println("This is the new leaderboard: \n"+scorebord+"\n\n");scorebord.saveToJson("highscores.json");scanner.close();}}
Als de dependencies goed liggen, kan je een nieuw Scorebord aanmaken, en herkent VSCode dit met CTRL+Space. Hieronder een voorbeeld van Gson:
Gradle extention for VSCode Ctrl+space
Als we het project uitvoeren, werkt dit echter niet: we krijgen een foutmelding bij het opslaan.
Dat komt omdat we een library gebruiken (scorebord), die op zijn beurt een library gebruikt (Gson).
Maar de Gson dependency is niet in onze huidige Gradle file gedefinieerd.
Om dit op te lossen, hebben we 3 opties:
zelf een dependency naar Gson toevoegen. Dat is echter ten zeerste af te raden, omdat we zo het automatische dependencybeheer via Gradle omzeilen.
een shadow jar/fat jar maken van scorebord. Dat is echter ook niet de meest aangewezen manier, opnieuw omdat we ingaan tegen de bedoeling van Gradle.
overschakelen naar een lokale Maven repository waarnaar we onze scorebord-library publiceren (zie eerder). Dan worden ook transitieve dependencies automatisch ingeladen. Verwijder de flatDir en voeg een lokale maven URL toe. Publiceer het scorebord project naar diezelfde URL volgens de instructies van de maven-publish plugin.
Denkvragen
Hoe zou je transitieve dependencies handmatig kunnen beheren? Wat zijn de voor- en nadelen?
Wat gebeurt er als project1-1.0 afhankelijk is van lib1-1.0 en lib1-2.0, en lib1-1.0 van lib2-1.0 - een oudere versie dus?
Als ik publiceer naar een lokale folder, welke bestanden zijn dan absoluut noodzakelijk voor iemand om mijn library te kunnen gebruiken?
In C (met CMake)
CMake
CMake is een open-source tool dat wordt gebruikt voor het beheren van de build processen van softwareprojecten in C en C++. Het biedt een platformonafhankelijke manier om build configuraties te genereren, wat betekent dat het kan worden gebruikt op verschillende besturingssystemen zoals Windows, macOS en Linux. CMake maakt gebruik van eenvoudige configuratiebestanden, genaamd CMakeLists.txt (soms meerdere van deze files in je project, je kan namelijk in meerdere directories zo een CMakeLists.txt file aanmaken), waarin de projectstructuur en de dependencies worden gedefinieerd. Deze configuratiebestanden worden vervolgens gebruikt om platformspecifieke buildsystemen te genereren, zoals Makefiles op Unix-achtige systemen (of Visual Studio-projectbestanden op Windows).
Een van de belangrijkste voordelen van CMake ten opzichte van het gebruik van alleen Makefiles is de verbeterde ondersteuning voor dependency management. Met Makefiles moet je handmatig de afhankelijkheden tussen bestanden en bibliotheken beheren, wat foutgevoelig en tijdrovend kan zijn. CMake automatiseert dit proces door dependencies automatisch te detecteren en te beheren. Dit zorgt ervoor dat alleen de noodzakelijke onderdelen opnieuw worden opgebouwd wanneer er wijzigingen worden aangebracht, wat de build tijd aanzienlijk kan verkorten.
Daarnaast biedt CMake een aantal geavanceerde functies die het beheren van dependencies verder vereenvoudigen. Zo ondersteunt CMake het gebruik van externe packages en libraries via de find_package-functie, waarmee je eenvoudig externe afhankelijkheden kunt integreren in je project. Ook biedt CMake ondersteuning voor moderne C++-functionaliteiten zoals target-gebaseerde builds, waarbij je specifieke build opties en dependencies kunt toewijzen aan individuele targets in plaats van aan het hele project. Hierdoor wordt het beheer van complexe projecten met meerdere componenten een stuk eenvoudiger en overzichtelijker. Deze functionaliteiten vallen echter buiten de scope van deze cursus.
Kortom, CMake biedt een krachtig en flexibel alternatief voor traditionele Makefiles, met name op het gebied van dependency management. Het automatiseert en vereenvoudigt het beheer van dependencies.
Je kan CMake simpel installeren op je WSL met behulp van volgend commando: sudo apt install cmake -y.
‘CMakeLists.txt’ en project structure
CMake werkt op basis van een CMakeLists.txt. Daarin specificeer je bepaalde instellingen over de structuur van je project en hoe je project juist gebuild en gelinkt moet worden. Verder kan je net als in Makefiles ook gebruik maken van variabelen om het proces nog meer te automatiseren. Je maakt volgens conventie ook een ./build directory aan waarin dan alle build-files terecht zullen komen. Een van die build-files in een door CMake gegenereerde make file waarmee je dan simpelweg via het commando make je project effectief kan builden naar een binary die je kan uitvoeren. Hieronder bekijken we hoe zo een ‘CMakeLists.txt’ eruit ziet in de root van je project en welke functionaliteiten je hebt.
We starten met een zeer simpel project met een main.c-file, een helloworld.c-file en een helloworld.h-file:
Klik hier om de code te zien/verbergen voor het kleine voorbeeld🔽
Een van de eenvoudigste CMakeLists.txt ziet er dan als volgt uit:
# Specify the minimum required version of CMake you need to use with this project. (Simply use your own version of CMake)cmake_minimum_required(VERSION 3.28)# Specify the project nameproject(myproject)# Specify: the name of the binary to build, the source files needed to build the binaryadd_executable(myproject.bin main.c helloworld.c)
Nu voeren we volgens conventie het cmake commando uit in de build-directory zodat alle nodige build files, waaronder de Makefile aangemaakt worden in die directory: cd ./build && cmake ..
Dat resulteert in volgende files en folders in de build-directory waarvan we eigenlijk enkel geinteresserd zijn in de Makefile:
Klik hier om de code te zien/verbergen voor de contents in de Makefile. Het fijne is nu dat je niet perfect moet weten wat er gebeurt omdat we die verantwoordelijkheid nu bij CMake gelegd hebben🔽
# CMAKE generated file: DO NOT EDIT!
# Generated by "Unix Makefiles" Generator, CMake Version 3.28
# Default target executed when no arguments are given to make.
default_target:all.PHONY :default_target# Allow only one "make -f Makefile2" at a time, but pass parallelism.
.NOTPARALLEL:#=============================================================================
# Special targets provided by cmake.
# Disable implicit rules so canonical targets will work.
.SUFFIXES:# Disable VCS-based implicit rules.
% : %,v# Disable VCS-based implicit rules.
% :RCS/%
# Disable VCS-based implicit rules.
% :RCS/%,v# Disable VCS-based implicit rules.
% :SCCS/s.%
# Disable VCS-based implicit rules.
% :s.%
.SUFFIXES: .hpux_make_needs_suffix_list# Command-line flag to silence nested $(MAKE).
$(VERBOSE)MAKESILENT= -s
#Suppress display of executed commands.
$(VERBOSE).SILENT:# A target that is always out of date.
cmake_force:.PHONY :cmake_force#=============================================================================
# Set environment variables for the build.
# The shell in which to execute make rules.
SHELL= /bin/sh
# The CMake executable.
CMAKE_COMMAND= /usr/bin/cmake
# The command to remove a file.
RM= /usr/bin/cmake -E rm -f
# Escaping for special characters.
EQUALS==# The top-level source directory on which CMake was run.
CMAKE_SOURCE_DIR= /home/arne/ses/cmake_example
# The top-level build directory on which CMake was run.
CMAKE_BINARY_DIR= /home/arne/ses/cmake_example/build
#=============================================================================
# Targets provided globally by CMake.
# Special rule for the target edit_cache
edit_cache: @$(CMAKE_COMMAND) -E cmake_echo_color "--switch=$(COLOR)" --cyan "No interactive CMake dialog available..." /usr/bin/cmake -E echo No\ interactive\ CMake\ dialog\ available.
.PHONY :edit_cache# Special rule for the target edit_cache
edit_cache/fast:edit_cache.PHONY :edit_cache/fast# Special rule for the target rebuild_cache
rebuild_cache: @$(CMAKE_COMMAND) -E cmake_echo_color "--switch=$(COLOR)" --cyan "Running CMake to regenerate build system..." /usr/bin/cmake --regenerate-during-build -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR).PHONY :rebuild_cache# Special rule for the target rebuild_cache
rebuild_cache/fast:rebuild_cache.PHONY :rebuild_cache/fast# The main all target
all:cmake_check_build_system$(CMAKE_COMMAND) -E cmake_progress_start /home/arne/ses/cmake_example/build/CMakeFiles /home/arne/ses/cmake_example/build//CMakeFiles/progress.marks
$(MAKE)$(MAKESILENT) -f CMakeFiles/Makefile2 all
$(CMAKE_COMMAND) -E cmake_progress_start /home/arne/ses/cmake_example/build/CMakeFiles 0.PHONY :all# The main clean target
clean:$(MAKE)$(MAKESILENT) -f CMakeFiles/Makefile2 clean
.PHONY :clean# The main clean target
clean/fast:clean.PHONY :clean/fast# Prepare targets for installation.
preinstall:all$(MAKE)$(MAKESILENT) -f CMakeFiles/Makefile2 preinstall
.PHONY :preinstall# Prepare targets for installation.
preinstall/fast:$(MAKE)$(MAKESILENT) -f CMakeFiles/Makefile2 preinstall
.PHONY :preinstall/fast# clear depends
depend:$(CMAKE_COMMAND) -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 1.PHONY :depend#=============================================================================
# Target rules for targets named myproject.bin
# Build rule for target.
myproject.bin:cmake_check_build_system$(MAKE)$(MAKESILENT) -f CMakeFiles/Makefile2 myproject.bin
.PHONY :myproject.bin# fast build rule for target.
myproject.bin/fast:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/build
.PHONY :myproject.bin/fasthelloworld.o:helloworld.c.o.PHONY :helloworld.o# target to build an object file
helloworld.c.o:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/helloworld.c.o
.PHONY :helloworld.c.ohelloworld.i:helloworld.c.i.PHONY :helloworld.i# target to preprocess a source file
helloworld.c.i:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/helloworld.c.i
.PHONY :helloworld.c.ihelloworld.s:helloworld.c.s.PHONY :helloworld.s# target to generate assembly for a file
helloworld.c.s:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/helloworld.c.s
.PHONY :helloworld.c.smain.o:main.c.o.PHONY :main.o# target to build an object file
main.c.o:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/main.c.o
.PHONY :main.c.omain.i:main.c.i.PHONY :main.i# target to preprocess a source file
main.c.i:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/main.c.i
.PHONY :main.c.imain.s:main.c.s.PHONY :main.s# target to generate assembly for a file
main.c.s:$(MAKE)$(MAKESILENT) -f CMakeFiles/myproject.bin.dir/build.make CMakeFiles/myproject.bin.dir/main.c.s
.PHONY :main.c.s# Help Target
help: @echo "The following are some of the valid targets for this Makefile:" @echo "... all (the default if no target is provided)" @echo "... clean" @echo "... depend" @echo "... edit_cache" @echo "... rebuild_cache" @echo "... myproject.bin" @echo "... helloworld.o" @echo "... helloworld.i" @echo "... helloworld.s" @echo "... main.o" @echo "... main.i" @echo "... main.s".PHONY :help#=============================================================================
# Special targets to cleanup operation of make.
# Special rule to run CMake to check the build system integrity.
# No rule that depends on this can have commands that come from listfiles
# because they might be regenerated.
cmake_check_build_system:$(CMAKE_COMMAND) -S$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 0.PHONY :cmake_check_build_system
Nu gaan we van die Makefile gebruik maken om met het make-commando de binary effectief te builden: make. (zorg er natuurlijk wel voor dat je in de ./build-directory zit!)
Er is nu een binary verschenen in de ./build-directory met de naam zoals gespecificeerd in de CMakeLists.txt-file, die je onmiddellijk kan uitvoeren.
Dependency management met CMake en variables
We kunnen nu de CMake file aanpassen zodat de binary automatisch de naam van het project gebruikt door standaard variabelen te gebruiken:
Je kan CMake ook wat zelf wat extra info text laten printen met
message("Hallo vanuit CMake je CMAKE_PROJECT_NAME is '${CMAKE_PROJECT_NAME}'")
Verder kunnen we de helloworld.c en helloworld.h files beschouwen als een kleine internal dependency en kunnen we deze dus best in een soort ./libs/helloworld-directory steken. Dan moeten we ook wel onze CMakeLists.txt-file aanpassen en BELANGRIJK in die ./libs/helloworld-directory moeten we ook een eigen CMakeLists.txt-file aanmaken waarin je definieert hoe die dependency juist gebuild en gelinkt moet worden. Onze project folder ziet er nu dan als volgt uit:
Klik hier om de code te zien/verbergen voor ./CMakeLists.txt🔽
# Specify the minimum required version of CMake you need to use with this project. (Simply use your own version of CMake)cmake_minimum_required(VERSION 3.28)# Specify the project nameproject(myproject)# Add the helloworld directory to the projectadd_subdirectory(libs/helloworld)# Specify: the name of the binary to build, the source files needed to build the binary# You don't need to specify the helloworld.c file here anymore, see belowadd_executable(${CMAKE_PROJECT_NAME}.bin main.c)message("Hallo vanuit CMake je CMAKE_PROJECT_NAME is '${CMAKE_PROJECT_NAME}'")# Link internal library 'helloworld' to the main binarytarget_link_libraries(${CMAKE_PROJECT_NAME}.bin PRIVATE helloworld)
Belangrijk: Merk op dat we de directory naar de library moeten toevoegen via add_subdirectory(), we niet langer de helloworld.c moeten vermelden bij de add_executable()-functie omdat we dit nu aangeven met de functie target_link_libraries():
target_link_libraries: Dit is een CMake-commando dat wordt gebruikt om libraries te koppelen aan een specifieke target. Een target kan een executable of een library zijn die je wilt builden.
${CMAKE_PROJECT_NAME}.bin: Dit is de naam van de target waaraan je de library wilt koppelen. ${CMAKE_PROJECT_NAME} is een variabele die de naam van het project bevat, en .bin is een extension die aangeeft dat het om een executable/binary bestand gaat.
PRIVATE: Dit is een eigenschap die aangeeft hoe de gekoppelde library zichtbaar is voor andere targets. In dit geval betekent PRIVATE dat de library alleen zichtbaar is voor de target ${CMAKE_PROJECT_NAME}.bin en niet voor andere targets die afhankelijk zijn van deze target. Dit helpt om de dependencies te beperken en de build configuratie overzichtelijk te houden. Andere opties buiten ‘PRIVATE’ zijn: ‘PUBLIC’ en ‘INTERFACE’.
PUBLIC: Wanneer je een library met de PUBLIC-eigenschap koppelt, betekent dit dat de library zichtbaar is voor zowel de target zelf als voor alle targets die afhankelijk zijn van deze target. Dit is handig wanneer je wilt dat de dependency doorgegeven wordt aan andere targets die deze target gebruiken.
INTERFACE: Deze eigenschap geeft aan dat de library alleen zichtbaar is voor targets die afhankelijk zijn van de target, maar niet voor de target zelf. Dit is nuttig voor het definiëren van interface-afhankelijkheden die alleen relevant zijn voor afhankelijke targets.
PRIVATE: Alleen zichtbaar voor de target zelf.
helloworld: Dit is de naam van de library die je wilt koppelen aan de target. In dit geval is helloworld waarschijnlijk een library die je hebt gedefinieerd of geïmporteerd in je project.
./libs/helloworld/CMakeLists.txt
Klik hier om de code te zien/verbergen voor ./libs/helloworld/CMakeLists.txt🔽
# Specify the minimum required version of CMake you need to use with this project. (Simply use your own version of CMake)cmake_minimum_required(VERSION 3.28)# Create a sort of temp project that compiles so it can be linked to the main project AND specify it is a C projectproject(Helloworld C)# Now add the compiled project binary as a libraryadd_library(helloworld helloworld.c)# Include this directory's binary as a binary that can be used by the main project to link withtarget_include_directories(helloworld PUBLIC ${CMAKE_CURRENT_SOURCE_DIR})
Belangrijk: Deze CMakeLists.txt file bevat essentiële instructies die samen zorgen dat de interne dependency correct wordt opgebouwd en bruikbaar is voor het main project. Allereerst definieert de project(Helloworld C) regel een nieuw project met de naam “Helloworld” en specificeert dat het in de programmeertaal C is geschreven, waardoor CMake de juiste compiler en instellingen selecteert. Met add_library(helloworld helloworld.c) wordt een statische of dynamische bibliotheek aangemaakt op basis van de broncode in “helloworld.c”, zodat deze gecompileerde code later in het hoofdproject gelinkt kan worden. Tenslotte zorgt target_include_directories(helloworld PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}) ervoor dat de directory waarin deze CMakeLists.txt en de headers staan, toegevoegd wordt aan de include-paden van alle targets die de “helloworld” library gebruiken. Hierdoor weet het main project waar de benodigde headers te vinden zijn, wat essentieel is voor een correcte compilatie en koppeling tussen de modules.
Voorbeeld met externe library
Voor dit hoofdstuk is er geen oefening voorzien, maar wel een voorbeeld analoog aan de oefening rond dependency management in Java. In dit geval hebben we een “Higher Lower C” project waarbij we de volgende structuur hebben. De entrypoint van onze applicatie is de main.c-file, de scorebord.c en scorebord.h kunnen gezien worden als een interne library en cJSON is een externe library/dependency. Hieronder vind je dan een mogelijke structuur voor ons project terug. Je kan dit project en bijhorende files ook downloaden met volgende github link.
Wil je de content van de source files bekijken, kan je dat hieronder. Het is in dit hoofdstuk vooral belangrijk dat je begrijpt wat de regels in de verschillende CMakeLists.txt betekenen en wat het voordeel is om het op deze manier te doen.
source code: files in root
Klik hier om de code te zien/verbergen voor CMakeLists.txt🔽
cmake_minimum_required(VERSION 3.28)project(HogerLagerC)# Gebruik de C99-standaardset(CMAKE_C_STANDARD 99)set(CMAKE_C_STANDARD_REQUIRED ON)add_subdirectory(external/cJSON)# Voeg de scorebord library toeadd_subdirectory(internal/scorebord)# Maak de executable van het speladd_executable(hoger_lager main.c)# Link de externe JSON-librarytarget_link_libraries(hoger_lager PRIVATE scorebord cjson)
Klik hier om de code te zien/verbergen voor main.c🔽
/* main.c - Hoger Lager spel */#include<stdio.h>#include<stdlib.h>#include<time.h>#include"scorebord.h"intmain(void){srand((unsigned)time(NULL));Scorebord*scorebord=load_scorebord("highscores.json");printf("Welkom bij het Hoger Lager spel!\n");printf("Dit is de huidige ranglijst:\n");print_scorebord(scorebord);printf("\nRaad of het volgende getal hoger of lager zal zijn.\n");intcurrentNumber=rand()%100+1;intscore=0;charchoice;while(1){printf("Huidig getal: %d\n",currentNumber);printf("Zal het volgende hoger (h) of lager (l) zijn? ");scanf(" %c",&choice);intnextNumber=rand()%100+1;if((choice=='h'&&nextNumber>currentNumber)||(choice=='l'&&nextNumber<currentNumber)){printf("Correct! Het volgende getal was: %d\n",nextNumber);score++;}else{printf("Fout! Het volgende getal was: %d\n",nextNumber);break;}currentNumber=nextNumber;}printf("Game over! Jouw eindscore: %d\n",score);printf("Wat is je naam? ");charname[50];scanf("%49s",name);add_score(scorebord,name,score);save_scorebord("highscores.json",scorebord);free_scorebord(scorebord);return0;}
source code: files in ./internal/scorebord
Klik hier om de code te zien/verbergen voor ./internal/scorebord/CMakeLists.txt🔽
cmake_minimum_required(VERSION 3.28)project(Scorebord C)include(FetchContent)FetchContent_Declare( cjson
GIT_REPOSITORY https://github.com/DaveGamble/cJSON.git
GIT_TAG v1.7.14 # Specify the version you want to use)FetchContent_MakeAvailable(cjson)add_library(scorebord scorebord.c)# Ensure cJSON include directories are correctly settarget_include_directories(scorebord PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}${cjson_SOURCE_DIR}${cjson_BINARY_DIR})# Link cJSON library to scorebordtarget_link_libraries(scorebord PRIVATE cjson)
Klik hier om de code te zien/verbergen voor ./internal/scorebord/scorebord.h🔽
#ifndef SCOREBORD_H
#define SCOREBORD_H
#include"player.h"typedefstruct{Player*players;intcount;intcapacity;}Scorebord;// Laadt de scorebordgegevens vanuit een JSON-bestand.
Scorebord*load_scorebord(constchar*filename);// Slaat de scorebordgegevens op in een JSON-bestand.
voidsave_scorebord(constchar*filename,Scorebord*sb);// Voegt een nieuwe score toe aan het scorebord.
voidadd_score(Scorebord*sb,constchar*name,intscore);// Print het scorebord naar de standaard output.
voidprint_scorebord(Scorebord*sb);// Geeft het geheugen van het scorebord vrij.
voidfree_scorebord(Scorebord*sb);#endif // SCOREBORD_H
Klik hier om de code te zien/verbergen voor ./internal/scorebord/scorebord.c🔽
#include<stdio.h>#include<stdlib.h>#include<string.h>#include"scorebord.h"#include"cJSON.h" // Externe JSON-library: cJSON// Hulpfunctie: maakt een nieuw Scorebord aan
staticScorebord*create_scorebord(){Scorebord*sb=malloc(sizeof(Scorebord));if(sb){sb->count=0;sb->capacity=10;// begin met ruimte voor 10 spelers
sb->players=malloc(sb->capacity*sizeof(Player));}returnsb;}Scorebord*load_scorebord(constchar*filename){FILE*fp=fopen(filename,"r");if(!fp){// Bestaat niet? Geef een nieuw scorebord terug.
returncreate_scorebord();}// Lees het hele bestand in een buffer
fseek(fp,0,SEEK_END);longfsize=ftell(fp);fseek(fp,0,SEEK_SET);char*data=malloc(fsize+1);fread(data,1,fsize,fp);fclose(fp);data[fsize]='\0';cJSON*json=cJSON_Parse(data);free(data);Scorebord*sb=create_scorebord();if(json){intarraySize=cJSON_GetArraySize(json);for(inti=0;i<arraySize;i++){cJSON*item=cJSON_GetArrayItem(json,i);cJSON*name=cJSON_GetObjectItem(item,"name");cJSON*score=cJSON_GetObjectItem(item,"score");if(cJSON_IsString(name)&&cJSON_IsNumber(score)){add_score(sb,name->valuestring,score->valueint);}}cJSON_Delete(json);}returnsb;}voidsave_scorebord(constchar*filename,Scorebord*sb){cJSON*json=cJSON_CreateArray();for(inti=0;i<sb->count;i++){cJSON*item=cJSON_CreateObject();cJSON_AddStringToObject(item,"name",sb->players[i].name);cJSON_AddNumberToObject(item,"score",sb->players[i].score);cJSON_AddItemToArray(json,item);}char*rendered=cJSON_Print(json);FILE*fp=fopen(filename,"w");if(fp){fputs(rendered,fp);fclose(fp);}free(rendered);cJSON_Delete(json);}voidadd_score(Scorebord*sb,constchar*name,intscore){if(sb->count>=sb->capacity){sb->capacity*=2;sb->players=realloc(sb->players,sb->capacity*sizeof(Player));}// Kopieer de naam (maximaal 49 karakters) en voeg de score toe
strncpy(sb->players[sb->count].name,name,sizeof(sb->players[sb->count].name)-1);sb->players[sb->count].name[sizeof(sb->players[sb->count].name)-1]='\0';sb->players[sb->count].score=score;sb->count++;}voidprint_scorebord(Scorebord*sb){// Eenvoudige weergave; je kunt hier sorteren op score toevoegen indien gewenst.
for(inti=0;i<sb->count;i++){printf("%s: %d\n",sb->players[i].name,sb->players[i].score);}}voidfree_scorebord(Scorebord*sb){if(sb){free(sb->players);free(sb);}}
Klik hier om de code te zien/verbergen voor ./internal/scorebord/player.h🔽
Dependency management in Python kan efficiënt worden afgehandeld met pip en venv. Deze tools helpen ervoor te zorgen dat je projecten de benodigde libraries hebben en dat verschillende projecten elkaar niet verstoren door conflicting dependencies.
pip is de package manager voor Python. Hiermee kun je extra libraries en dependencies installeren en beheren die niet zijn opgenomen in de standaardbibliotheek. Om een pakket te installeren met pip, kun je de volgende command prompt gebruiken:
pip install <package_name>
Je kunt ook de versie van het pakket specificeren die je wilt installeren:
pip install package_name==1.2.3
Om de dependencies van je project bij te houden, kun je een requirements.txt-bestand maken waarin alle packages en hun versies worden vermeld. Dit bestand kan worden gegenereerd met:
pip freeze > requirements.txt
Om de dependencies in requirements.txt dan ergens te installeren, kun je het volgende commando gebruiken:
pip install -r requirements.txt
venv is een module die ondersteuning biedt voor het maken van lichte, geïsoleerde Python-omgevingen. Je installeer de module opt je WSL via sudo apt install python3.12-venv -y. Venv is vooral handig wanneer je meerdere projecten hebt met verschillende dependencies en zeker bij meerdere projecten met verschillende versies van dezelfde dependencies. Om een virtuele omgeving (virtual environment = venv) te maken, kun je de volgende opdracht gebruiken (dit hoeft niet specifiek in de directory van je prject te zijn):
python3 -m venv <myenv_name>
Hiermee wordt een directory genaamd myenv_name gemaakt die een kopie van de Python-interpreter en een pip-executable bestand bevat. Om de virtuele omgeving te activeren, gebruik je:
source <myenv_name>/bin/activate
Info
Je kan venv ook op Windows gebruiken maar dan gebruik je het commando: <myenv_name>\Scripts\activate om de virtual environment te activeren.
Zodra de virtuele omgeving is geactiveerd, worden alle packages die met pip worden geïnstalleerd beperkt tot deze omgeving, zodat de dependencies van je project geïsoleerd blijven van andere projecten. Om de virtuele omgeving te deactiveren, voer je eenvoudigweg volgend commando uit:
deactivate
Je zal dan zien dat je CLI je dan ook toont in welke ‘venv’ je je bevindt:
(<myenv_name>) arne@LT3210121:~/myproject$
Door pip en venv te combineren, kun je effectief dependencies beheren, meerdere projectomgevingen simpel onderhouden en conflicten tussen verschillende projecten vermijden. Deze aanpak zorgt ervoor dat je projecten reproduceerbaar blijven en eenvoudig op verschillende systemen kunnen worden opgezet.
Voorbeeld ‘hoger lager’
Hieronder staat een voorbeeld van hoe je het ‘hoger lager’-project kunt inrichten als een Python-project met een virtual environment, een requirements.txt-file voor de externe JSON-library (via simplejson) en met de scorebord.py als interne dependency in een libs-directory. De projectstructuur ziet er dan als volgt uit:
Requirements.txt bevat nu enkel volgende regel: simplejson==3.20.1 en kan je installeren in de ‘venv’ met pip install -r requirements.txt.
Je app.py ziet er dan als volgt uit, waarbij de if __name__ == '__main__': een indicatie geeft dat deze file de entrypoint tot onze applicatie is:
Klik hier om de code te zien/verbergen voor app.py🔽
importrandomfromlibs.scorebordimportScoreboarddefmain():# Laad het scorebord vanuit het JSON-bestand (als het bestaat)sb=Scoreboard.load_from_json('highscores.json')print("Welcome to the Higher or Lower game!")print("This is the current leaderboard:\n",sb,"\n")print("Guess if the next number will be higher or lower.")current_number=random.randint(1,100)score=0playing=Truewhileplaying:print("Current number:",current_number)guess=input("Will the next number be higher or lower? (h/l): ").lower().strip()next_number=random.randint(1,100)if(guess=='h'andnext_number>current_number)or(guess=='l'andnext_number<current_number):print("Correct! The next number was:",next_number)score+=1else:print("Wrong! The next number was:",next_number)playing=Falsecurrent_number=next_numberprint("Game over! Your final score:",score)name=input("What is your name? ")sb.add(name,score)print("This is the new leaderboard:\n",sb,"\n")Scoreboard.save_to_json('highscores.json',sb)if__name__=='__main__':main()
Bestand: libs/init.py
Dit bestand kan leeg zijn, maar het zorgt ervoor dat Python de map libs als package herkent.
Info
Wil je meer info over de conventies over het werken met interne libraries in python projecten, bekijk dan deze video.
Interne dependency: scorebord.py
Dit is de interne dependency die het scorebord beheert. Hierin gebruiken we de externe JSON-library (simplejson) om de gegevens op te slaan en te laden.
Klik hier om de code te zien/verbergen voor ./libs/scorebord.py🔽
importsimplejsonasjsonclassScoreboard:def__init__(self):self.scores=[]defadd(self,name,score):self.scores.append({'name':name,'score':score})deftotal_score(self,name):returnsum(player['score']forplayerinself.scoresifplayer['name']==name)defget_winner(self):ifnotself.scores:return"No players yet"returnmax(self.scores,key=lambdaplayer:player['score'])['name']def__str__(self):# Sorteer de scores aflopend en formatteer de outputsorted_scores=sorted(self.scores,key=lambdaplayer:player['score'],reverse=True)return"\n".join(f"{player['name']}: {player['score']}"forplayerinsorted_scores)@staticmethoddefsave_to_json(filename,scoreboard):withopen(filename,'w')asf:json.dump(scoreboard.scores,f,indent=4)@staticmethoddefload_from_json(filename):sb=Scoreboard()try:withopen(filename,'r')asf:scores=json.load(f)ifscoresisnotNone:sb.scores=scoresexcept(FileNotFoundError,json.JSONDecodeError):# Bestand bestaat niet of is ongeldig, geef een nieuw scorebord terug.passreturnsb
Info
Meer info over het gebruik van classes in Python vind je hier.
Builden/runnen
Je zou dit project nu kunnen laten compileren tot een binary met bijvoorbeeld pyinstaller zoals we gezien hebben in build tools voor python, maar we kunnen het project ook simpelweg uitvoeren met python via:
python3 ./app.py
De bronbestanden voor dit voorbeeld kan je ook in deze github repo terugvinden. Merk op dat in dit project de ‘venv’ niet is opgenomen in het versiebeheer via de higher_lower_venv/ in de ./.gitignore-file wat de conventie is.
5. Test Driven Development
Wat is de beste manier om het aantal bugs in code te reduceren?
Test-Driven Development
TDD (Test-Driven Development) is een hulpmiddel bij softwareontwikkeling om minder fouten te maken en sneller fouten te vinden, door éérst een test te schrijven en dan pas de implementatie. Die (unit) test zal dus eerst falen (ROOD), want er is nog helemaal geen code, en na de correcte implementatie uiteindelijk slagen (GROEN).
graph LR;
T{"Write FAILING<br/> test"}
D{"Write<br/> IMPLEMENTATION"}
C{"Run test<br/> SUCCEEDS"}
S["Start Hier"]
S --> T
T --> D
D --> C
C --> T
Testen worden opgenomen in een build omgeving, waardoor alle testen automatisch worden gecontroleerd bij bijvoorbeeld het compileren, starten, of packagen van de applicatie. Op deze manier krijgt men onmiddellijk feedback van modules die door bepaalde wijzigingen niet meer werken zoals beschreven in de test.
Soorten van Testen
Er zijn drie grote types van testen:
1. Unit Testing (GROEN)
Een unit test test zaken op individueel niveau, per klasse dus. De meeste testen zijn unit testen. Hoe kleiner het blokje op bovenstaande figuur, hoe beter de F.I.R.S.T. principes kunnen nageleefd worden. Immers, hoe meer systemen opgezet moeten worden voordat het assertion framework zijn ding kan doen, hoe meer tijd verloren, en hoe meer tijd de test in totaal nodig heeft om zijn resultaat te verwerken.
2. Integration Testing (ORANJE)
Een integratie test test het integratie pad tussen twee verschillende klasses. Hier ligt de nadruk op interactie in plaats van op individuele functionaliteit, zoals bij de unit test. We willen bijvoorbeeld controleren of een bepaalde service wel iets wegschrijft naar de database, maar het schrijven zelf is op unit niveau bij de database reeds getest. Waar wij nu interesse in hebben, is de interactie tussen service en database, niet de functionaliteit van de database.
Typische eigenschappen van integration testen:
Test geïntegreerd met externen. (db, webservice, …)
Test integratie twee verschillende lagen.
Trager dan unit tests.
Minder test cases.
3. End-To-End Testing (ROOD)
Een laatste groep van testen genaamd end-to-end testen, ofwel scenario testen, testen de héle applicatie, van UI tot DB. Voor een GUI applicatie bijvoorbeeld betekent dit het simuleren van de acties van de gebruiker, door op knoppen te klikken en te navigeren doorheen de applicatie, waarbij bepaalde verwachtingen worden afgetoetst. Bijvoorbeeld, klik op ‘voeg toe aan winkelmandje’, ga naar ‘winkelmandje’, controleer of het item effectief is toegevoegd.
Typische eigenschappen van end-to-end testen:
Test hele applicatie!
Niet alle limieten.
Traag, moeilijker onderhoudbaar.
Test integratie van alle lagen.
In plaats van dit in (Java) code te schrijven, is het ook mogelijk om de Selenium IDE extentie voor Google Chrome of Mozilla Firefox te gebruiken. Deze browser extentie laat recorden in de browser zelf toe, en vergemakkelijkt het gebruik (er is geen nood meer aan het vanbuiten kennen van zulke commando’s). Dit wordt in de praktijk vaak gebruikt door software analisten of testers die niet de technische kennis hebben om te programmeren, maar toch deel zijn van het ontwikkelteam.
Recente versies van de Selenium IDE plugin bewaren scenario’s in .side bestanden, wat een JSON-notatie is. Oudere versies bewaren commando’s in het .html formaat. deze bestanden bevatten een lijst van je opgenomen records:
Gebruik Selenium IDE om een test scenario op te nemen van het volgende scenarios op de website https://www.saucedemo.com/. :
Log in met “locked_out_user” en wachtwoord “secret_sauce” en verifieer dat je een error boodschap krijgt.
Log in met “standard_user” en wachtwoord “secret_sauce”, klik op het eerste item, voeg toe aan je winkelmandje, ga naar je winkelmandje. Verifieer dat er een product inzit.
Log in met “standard_user” en wachtwoord “secret_sauce” en test of de afbeeldingen van de producten verschillend zijn.
Log in met “problem_user” en wachtwoord “secret_sauce” en test of de afbeeldingen van de producten verschillend zijn. (Deze test moet nu falen omdat je je voordoet als een user die een bug ervaart.)
Je zal voor deze opgave dus de Selenium (Chromium/Firefox) plugin moeten installeren: zie hierboven.
Belangrijk
In de volgende delen wordt er dieper ingegaan op de verschillende concepten die komen kijken bij Test Driven Development. We gaan de theoretische concepten echter enkel aanhalen in de tekst rond TDD in Java, maar die zijn natuurlijk wel van toepassing op alle talen zoals Python en C. We halen later bij de pagina’s rond TDD in Python en C die theoretische kant niet zo zwaar meer boven en houden ons daar meer bezig met de praktische kant.
Subsecties van 5. Test Driven Development
Debugger tools
De wie, wat en waarom van debugger tools
Een debugger in een geïntegreerde ontwikkelomgeving (IDE) is een tool waarmee je stap voor stap door je code kan gaan, je kan code uitvoeren en de toestand van variabelen en van het programma als geheel bekijken tijdens het uitvoeren van je programma. Hier zijn de voordelen van het gebruik van een debugger ten opzichte van het handmatig uitprinten van waarden:
Interactieve stapsgewijze uitvoering: Met een debugger kunnen ontwikkelaars hun code uitvoeren en pauzeren bij specifieke punten, zoals breakpoints of fouten. Ze kunnen de code stap voor stap doorlopen om te zien hoe de waarden van variabelen veranderen en om eventuele fouten te identificeren.
Breakpoints: Ontwikkelaars kunnen breakpoints instellen op specifieke regels in hun code, waardoor het programma pauzeert wanneer het deze regels bereikt. Dit stelt ontwikkelaars in staat om de staat van het programma te onderzoeken op een specifiek punt in de uitvoering, wat handig is voor het debuggen van specifieke problemen.
Variabele inspectie: Ontwikkelaars kunnen variabelen inspecteren terwijl ze door de code stappen. Dit stelt hen in staat om de waarden van variabelen te bekijken en te begrijpen hoe deze veranderen tijdens de uitvoering van het programma, wat nuttig is bij het debuggen van complexe problemen.
Dynamische wijziging van variabelen: Sommige debuggers bieden de mogelijkheid om variabelen dynamisch te wijzigen tijdens het debuggen. Dit kan handig zijn om te testen hoe verschillende waarden van variabelen van invloed zijn op de uitvoering van het programma, zonder de code opnieuw te hoeven compileren en uitvoeren.
Call stack en uitvoeringspad: Een debugger biedt informatie over de call stack en het uitvoeringspad van het programma. Dit helpt ontwikkelaars om te begrijpen welke functies worden aangeroepen en in welke volgorde, wat kan helpen bij het opsporen van bugs die zich voordoen als gevolg van onverwachte uitvoeringspaden.
Over het algemeen biedt een debugger een krachtige set van tools voor het effectief debuggen van code, waardoor ontwikkelaars efficiënter problemen kunnen oplossen en complexe codebases beter kunnen begrijpen. Het is een essentiële tool voor elke software developper.
Debuggen met VSCode
VSCode biedt voor verschillende talen (eventueel met behulp van extensies) de mogelijkheid om programma’s te debuggen met een geïntegreerde debugger.
TDD in Java
Een TDD Scenario
Stel dat een programma een notie van periodes nodig heeft, waarvan elke periode een start- en einddatum heeft, die al dan niet ingevuld kunnen zijn. Een contract bijvoorbeeld geldt voor een periode van bepaalde duur, waarvan beide data ingevuld zijn, of voor gelukkige werknemers voor een periode van onbepaalde duur, waarvan de einddatum ontbreekt:
We wensen aan de Periode klasse een methode toe te voegen om te controleren of periodes overlappen, zodat de volgende statement mogelijk is: periode1.overlaptMet(periode2).
1. Schrijf Falende Testen
Voordat de methode wordt opgevuld met een implementatie dienen we na te denken over de mogelijke gevallen van een periode. Wat kan overlappen met wat? Wanneer geeft de methode true terug, en wanneer false? Wat met lege waardes?
Het standaard geval: beide periodes hebben start- en einddatum ingevuld, en de periodes overlappen.
Merk op dat de namen van de testen zeer descriptief zijn. Op die manier wordt in één opslag duidelijk waar er problemen opduiken in je code.
… Er zijn nog tal van mogelijkheden, waarvan voornamelijk de extreme gevallen belangrijk zijn om de kans op bugs te minimaliseren. Immers, gebruikers van onze Periode klasse kunnen onbewust null mee doorgeven, waardoor de methode onverwachte waardes teruggeeft.
De testen compileren niet, omdat de methode overlaptMet() nog niet bestaat. Voordat we overschakelen naar het schrijven van de implementatie willen we eerst de testen zien ROOD kleuren, waarbij wel de bestaande code nog compileert:
De aanwezigheid van het skelet van de methode zorgt er voor dat de testen compileren. De inhoud, die een UnsupportedOperationException gooit, dient nog aangevuld te worden in stap 2. Op dit punt falen alle testen (met hopelijk als oorzaak de voorgaande exception).
2. Schrijf Implementatie
Pas nadat er minstens 4 verschillende testen werden voorzien (standaard gevallen, edge cases, null cases, …), kan met een gerust hart aan de implementatie worden gewerkt:
Deze eerste aanzet verandert de deprimerende rode kleur van minstens één test naar GROEN. Echter, lang niet alle testen zijn in orde. Voer de testen uit na elke wijziging in implementatie totdat alles in orde is. Het is mogelijk om terug naar stap 1 te gaan en extra test gevallen toe te voegen.
4. Pas code aan (en herbegin)
De cyclus is compleet: red, green, refactor, red, green, refactor, …
Wat is ‘refactoring’?
Structuur veranderen, zonder de inhoud te wijzigen.
Als de overlaptMet() methode veel conditionele checks bevat is de kans groot dat bij elke groene test de inhoud stelselmatig ingewikkelder wordt, door bijvoorbeeld het veelvuldig gebruik van if statements. In dat geval is het verbeteren van de code, zonder de functionaliteit te wijzigen, een refactor stap. Na elke refactor stap verifiëer je de wijziging door middel van de testen.
Voel jij je veilig genoeg om grote wijzigingen door te voeren zonder te kunnen vertrouwen op een vangnet van testen? Wij als docenten alvast niet.
Naamgeving van testen en projectstructuur
Om testen op een correcte manier uit te voeren wordt aan een bepaalde structuur vastgehouden.
Notitie
We maken gebruik van CamelCase en snake_case om alle testen de vorm te geven van gegevenDit_wanneerDezeMethodeEropToegepastWordt_danMoetDitDeUitkomstZijn.
Unit Tests
Wat is Unit Testing
Unit testen zijn stukjes code die productie code verifiëren op verschillende niveau’s. Het resultaat van een test is GROEN (geslaagd) of ROOD (gefaald met een bepaalde reden). Een collectie van testen geeft ontwikkelaars het zelfvertrouwen om stukken van de applicatie te wijzigen met de zekerheid dat de aanwezige testen rapporteren wat nog werkt, en wat niet. Het uitvoeren van deze testen gebeurt meestal in een IDE zoals IntelliJ voor Java, of Visual Studio voor C#, zoals deze screenshot:
Elke validatieregel wordt apart opgelijst in één test. Als de validate() methode 4 regels test, zijn er minstens 4 testen geimplementeerd. In de praktijk is dat meestal meer omdat edge cases - uitzonderingsgevallen zoals null checks - ook aanzien worden als een apart testgeval.
Eigenschappen van een goede test
Elke unit test is F.I.R.S.T.:
Fast. Elk nieuw stukje functionaliteit vereist nieuwe testen, waarbij de bestaande testen ook worden uitgevoerd. In de praktijk zijn er duizenden testen die per compile worden overlopen. Als elke test één seconde duurt, wordt dit wel erg lang wachten…
Isolated. Elke test bevat zijn eigen test scenario dat géén invloed heeft op een andere test. Vermijd ten allen tijden het gebruik van het keyword static, en kuis tijdelijk aangemaakte data op, om te vermijden dat andere testen worden beïnvloed.
Repeatable. Elke test dient hetzelfde resultaat te tonen, of die nu éénmalig wordt uitgevoerd, of honderden keren achter elkaar. State kan hier typisch roet in het eten gooien.
Self-Validating. Geen manuele inspectie is vereist om te controleren wat de status van de test is. Een falende foutboodschap is een duidelijke foutboodschap.
Thorough. Testen moeten alle scenarios dekken: denk terug aan edge cases, randgevallen, het gebruik van null, het opvangen van mogelijke Exceptions, …
Het Raamwerk van een test
Bij het aanmaken van het project met Gradle, heeft Gradle je al een heel stuk geholpen om het testraamwerk op te stellen. Testen over een bepaalde klasse bundel je namelijk in een file onder de test-directory. Zorg er ook voor dat de testfile zich in dezelfde package onder de testdiretory bevindt. De conventie is dat we de testfile dezelfde naam geven als de klasse die we willen testen met Test achter. In principe is dit ook gewoon een javaklasse die we op een speciale manier gaan gebruiken. Bij het aanmaken van je project voorziet Gradle zelfs al een test. De structuur van de app/src-directory van je project ziet er dus als volgt uit:
./app/src
├── main
│ ├── java
│ │ └── be
│ │ └── ses
│ │ └── App.java
│ └── resources
└── test
├── java
│ └── be
│ └── ses
│ └── AppTest.java
└── resources
Test Libraries bestaande uit twee componenten
Een test framework, zoals JUnit voor Java, MSUnit/NUnit voor C#, of Jasmine voor Javascript, bevat twee delen:
1. Het Test Harnas
Een ‘harnas’ is het concept waar alle testen aan worden opgehangen. Het harnas identificeert en verzamelt testen, en het harnas stelt het mogelijk om bepaalde of alle testen uit te voeren. De ingebouwde Test UI in VSCode fungeert hier als visueel harnas. Elke test methode, een public void methode geannoteerd met @Test, wordt herkent als mogelijke test.
Gradle en het JUnit harnas verzamelen data van testen in de vorm van HTML rapporten.
Hiervoor dient dus de dependency testImplementation libs.junit in onze gradle.build-file.
2. Het Assertion Framework
Naast het harnas, dat zorgt voor het uitvoeren van testen, hebben we ook een verificatie framework nodig, dat fouten genereert wanneer nodig, om te bepalen of een test al dan niet geslaagd is. Dit gebeurt typisch met assertions, die vereisten dat een argument een bepaalde waarde heeft. Is dit niet het geval, wordt er een AssertionError exception gegooid, die door het harnas herkent wordt, met als resultaat een falende test.
Assertions zijn er in alle kleuren en gewichten, waarbij in de oefeningen de statische methode assertThat() wordt gebruikt, die leeft in org.assertj.core.api.Assertions. AssertJ is een plugin library die ons in staat stelt om een fluent API te gebruiken in plaats van moeilijk leesbare assertions:
Het tweede voorbeeld leest als een vloeiende zin, terwijl de eerste AssertEquals() vereist dat als eerste argument de expected value wordt meegegeven - dit is vaak het omgekeerde van wat wij verwachten!
Je kan simpelweg de dependency testImplementation "org.assertj:assertj-core:3.11.1" in de gradle.build-file toevoegen. En de import van import static org.junit.Assert.*; in de test file veranderen naar import static org.assertj.core.api.Assertions.*;
Een populair alternatief voor AssertJ is bijvoorbeeld Hamcrest. De keuze is aan jou: alle frameworks bieden ongeveer dezelfde fluent API aan met ongeveer dezelfde features.
Messages meegeven aan Testresultaten
Je kan ook extra messages meegeven aan testresultaten die afhankelijk kunnen zijn van het resultaat, bekijk hiervoor de documentatie van AssertJ.
Testen op Exceptions
Info
Je kan testen met AssertJ op exceptions op de volgende manier:
@TestpublicvoidmyTest(){// whenThrowablethrown=catchThrowable(()->{// ...});// thenassertThat(thrown).isInstanceOf(Exception.class).hasMessageContaining("/ by zero");}@TestpublicvoidmyTest(){assertThatExceptionOfType(Exception.class).isThrownBy(()->{// ...}).withMessageContaining("Substring in message");}
Arrange, Act, Assert
De body van een test bestaat typisch uit drie delen:
Arrange. Het klaarzetten van data, nodig om te testen, zoals een instantie van een klasse die wordt getest, met nodige parameters/DB waardes/…
Act. Het uitvoeren van de methode die wordt getest, en opvangen van het resultaat.
Assert. Het verifiëren van het resultaat van de methode.
Setup, Execute, Teardown
Wanneer de Arrange stap dezelfde is voor een serie van testen, kunnen we dit veralgemenen naar een @Before methode, die voor het uitvoeren van bepaalde of alle testen wordt uitgevoerd. Op dezelfde manier kan data worden opgekuist na elke test met een @After methode - dit noemt men de teardown stap.
JUnit 4 en JUnit 5 verschillen hierin op niveau van gebruik. Vanaf JUnit 5 werkt men met @BeforeEach/@BeforeAll. Raadpleeg de documentatie voor meer informatie over het verschil tussen each/all en tussen v4/v5.
Demo: Calculator app unit testen
Om testen op de correcte manier uit te kunnen voeren gaan we starten met de juiste dependencies in te stellen in onze build.gradle file:
dependencies{// Use JUnit 4 for testing.
testImplementationlibs.junittestImplementation"org.assertj:assertj-core:3.11.1"// This dependency is used by the application.
implementationlibs.guava}
Vervolgens maken we een Calculator klasse aan in ons gradle project in het package be.ses.
packagebe.ses;publicclassCalculator{}
Omdat we goede developers zijn maken we ook meteen een CalculatorTest klasse aan in de overeenkomstige package in de app/src/test directory. En voegen hier al de nodige imports aan toe. hier zullen al onze testen in geschreven worden als public void methodes:
We willen aan onze calculator een divide-methode toevoegen die 2 parameters meekrijgt teller en noemer.
We gaan volgens de correcte principes dus EERST testen schrijven die de onze method gaan testen voordat we de implementatie ervan gaan uitschrijven. (En aangezien het kan zijn dat er door 0 gedeeld wordt, gaan we dit ook testen):
Nu kunnen we aan onze implementatie werken en proberen alle testen te laten slagen:
packagebe.ses;publicclassCalculator{publicCalculator(){}publicfloatdivide(floatteller,floatnoemer){if(noemer==0){thrownewArithmeticException("/ by zero");}returnteller/noemer;}}
Oefening
Breid je Calculator klasse uit om ook add, subtract en multiply te doen. En schrijf natuurlijk eerst enkel tests.
Voeg eigen messages toe aan je testen om nog beter te kunnen kijken wat eventueel misloopt.
Integration testen
Test Doubles
Stel dat we nu een andere klasse hebben Doubler die een methode heeft doubleCalculator. Die methode neemt 3 parameters: operation,x,y en voert dus de gekozen operatie uit met de Calculator klasse en verdubbeld gewoon het resultaat.
Hoe testen we de doubleCalculator() methode, zonder de effectieve implementatie van Calculator te moeten gebruiken? Want testen moeten geïsoleerd zijn.
Door middel van test doubles.
Zoals Arnie in zijn films bij gevaarlijke scenes een stuntman lookalike gebruikt, zo gaan wij in onze code een Calculator lookalike gebruiken, zodat de Doubler-klasse dénkt dat hij Calculator-methoden aanroept, terwijl dit in werkelijkheid niet zo is. Daarvoor gaan we Mocks gebruiken. (Je kan ook een interface CalculatorInterface voorzien zodat je overal waar je Calculator wil gebruiken ook een eigen CalculatorMock-klasse kan gebruiken met dezelfde methodes maar waar je een aantal testscenarios gewoon hardcode, dit gaan we hier niet voordoen.)
Fakes are objects that have working implementations. On the other hand, mocks are objects that have predefined behavior. Lastly, stubs are objects that return predefined values. When choosing a test double, we should use the simplest test double to get the job done.
Mockito is verreweg het meest populaire Unit Test Framework dat bovenop JUnit wordt gebruikt om heel snel Test Doubles en integratietesten op te bouwen.
Het ideale gedrag dat we met zo een mock willen bekomen is dat overal waar we een andere klasse gebruiken met new in onze testen dat we dit kunnen onderscheppen en in de plaats onze “Test Double” kunnen meegeven. Dit kon vroeger gedaan worden met PowerMocks. Dit kan lukt echter niet meer in de nieuwere versies van de Java JVM en met goede reden.
Wanneer je binnen een bepaald klasse een andere klasse wil gebruiken, maak je best gebruik van Dependency Injection, wat wil zeggen dat je niet in een methode een instantie aanmaakt van een andere klasse, maar op voorhand een object aanmaakt van die klasse en dan als parameter aan de methode of datamember van de klasse meegeeft. Op die manier kunnen we ook veel simpeler testen. Als we nu de methode oproepen kunnen we als parameter simpelweg onze Test Double meegeven in plaats van een echt object.
We gaan hiervoor dus Mockito gebruiken om in onze testen. Hiervoor heb je volgende dependency nodig:
packagebe.ses;importorg.junit.Test;import staticorg.assertj.core.api.Assertions.*;import staticorg.mockito.Mockito.*;publicclassDoublerTest{@TestpublicvoidgegevenOperationDivideX2Y1_wanneerDoubleCalculator_danResultIs4(){CalculatorcalculatorMock=mock(Calculator.class);when(calculatorMock.divide(2f,1f)).thenReturn(2.0f);Doublerdoubler=newDoubler();floatresult=doubler.doubleCalculator(calculatorMock,"divide",2,1);assertThat(result).isEqualTo(4.0f).withFailMessage("result was "+result+" but expected 4.0.");verify(calculatorMock).divide(2f,1f);}}
Merk op dat we met de laatste regel nog even dubbel checken dat wel zeker de Test Double (calculatorMock) gebruikt werd met de juiste methode en parameters.
Oefening
Breid de Doubler klasse uit om ook add, subtract en multiply te doen. En schrijf natuurlijk eerst enkele tests en gebruik correct Test Doubles/Mocks.
Als je nu de Gradle task test gebruikt om je testen uit te voeren, wordt er door Gradle automatisch een interactief verslag in de vorm van een webpagina gegenereerd in de build/reports/test/test-directory. Je vind hier een file index.html. Deze file openen in de browser geeft bijvoorbeeld volgend verslag:
Extra oude Opgaven: geen verplichting
Klik hier om de opgaven te bekijken🔽
Opgave 1
De Artisanale Bakkers Associatie vertrouwt op uw technische bekwaamheid om hun probleem op te lossen.
Er wordt veel Hasseltse Speculaas gebakken, maar niemand weet
precies wat de beste Speculaas is. Schrijf een methode die speculaas beoordeelt op basis van de ingrediënten.
De methode, in de klasse Speculaas, zou er zo uit moeten zien:
publicintbeoordeel(){// TODO ...}
De functie geeft een nummer terug - hoe hoger dit nummer, hoe beter de beoordeling en hoe gelukkiger de bakker. Een speculaas kan de volgende ingrediënten bevatten: kruiden, boter, suiker, eieren, melk, honing, bloem, zout. Elke eigenschap is een nummer dat de hoeveelheid in gram uitdrukt.
Het principe is simpel: hoe meer ingrediënten, hoe beter de beoordeling.
Kijk naar een voorbeeld test hoe de methodes te hanteren. Er zijn al enkele testen voorzien. Die kan je uitvoeren met IntelliJ door op het groen pijltje te drukken, of met Gralde: ./gradlew test. Dit genereert een test rapport HTML bestand in de build/test map.
We zijn dus geïnteresseerd in edge cases. Probeer alle mogelijkheden te controleren. Denk bij het testen aan de volgende zaken:
Hoe zit het met een industriële speculaas, zonder kruiden of boter?
Wat doet de functie beoordeel als het argument null is?
Wat als een speculaas wordt meegegeven zonder ingrediënten?
Er is een foutje geslopen in de login module, waardoor Abigail altijd kan inloggen, maar jos soms wel en soms niet. De senior programmeur in ons team heeft de bug geïdentificeerd en beweert dat het in een stukje oude code zit,
maar hij heeft geen tijd om dit op te lossen. Nu is het aan jou. De logins.json file bevat alle geldige login namen die mogen inloggen. Er kan kunnen geen twee gebruikers met dezelfde voornaam zijn.
(Andere namen die moeten kunnen inloggen zijn “James”, “Emma”, “Isabella” …)
(Andere namen die niet mogen kunnen inloggen zijn “Arne”, “Kris”, “Markske” …)
Deze methode geeft true terug als Abigail probeert in te loggen, en false als Jos probeert in te loggen. Hoe komt dit? Schrijf éérst een falende test!
B. URL Verificatie fouten
Een tweede bug wordt gemeld: URL verificatie features werken plots niet meer. Deze methode faalt steeds, ook al zijn er reeds unit testen voorzien. Het probleem is dat HTTPS URLs met een SSL certificaat niet werken. Je onderzocht de URL verificatie code en vond de volgende verdachte regels:
De code blijkt reeds unit testen te hebben, dus schrijf éérst een falende test (in VerifierTests).
Opgave 3
Info
Dit is een vervolgopgave van de code van Opgave 1. Werk verder op dat bestaand project, in diezelfde repository!
Een verkoopster werkt in een (goede) speculaasfabriek. De verkoopster wilt graag 2 EUR aanrekenen per speculaas die de fabriek produceert.
Echter, als de klant meer dan 5 stuks verkoopt, mag er een korting van 10% worden aangerekend. In dit voorbeeld gaan we ervan uit dat een fabriek een willekeurig aantal speculaas per dag maakt en dat de klant steeds alle speculazen koopt. De verkoop gebeurt in de Verkoopsterklasse en het bakken van de speculazen gebeurt in de SpeculaasFabriek. Als we nu willen testen of onze verkoop methode uit de Verkoopster-klasse werkt, dan willen we dit isolated doen. We willen dus de onzekerheid van de Fabriek weghalen door specifieke gevallen aan te halen. Dit kan echter niet via de standaard SpeculaasFabriek. Daarom gaan we een test double gebruiken. Hiervoor gaan we deze keer een mock gebruiken zoals verder duidelijk wordt.
publicdoubleverkoop(){vargebakken=speculaasFabriek.bak();// TODO ...}
Je ziet aan bovenstaande code dat de speculaasfabriek instantie wordt gebruikt. We hebben dus eigenlijk geen controle op de hoeveelheid speculaas die deze fabriek produceert.
Unit testen
Hoe kunnen we dan toch nog testen wat we willen testen? Mogelijke scenario’s:
De fabriek produceert niets. De klant betaalt niets.
De fabriek produceert minder dan 5 speculaasjes. De klant betaalt per stuk, 2 EUR.
De fabriek produceert meer dan 5 stuks. De klant krijgt 10% korting op zijn totaal.
TDD in Python
Unit tests
Je zou simpelweg de ingebouwde assert functie in Python kunnen gebruiken om testen te schrijven zoals hieronder is weergegeven. Je kan de testfile dan runnen met python3 calculator_test.py en wanneer een assert niet klopt zal je een AssertionError krijgen.
Dit geeft echter niet zo een mooie output zoals we in Java met Junit hebben gezien en Python komt standaard met een testmodule genaamd unittest. We kunnen onze testfile dan uitvoeren met python3 -m unittest calculator_test.py. Unittest beschouwd onze functie echter nog niet als een test, hiervoor moeten we een aantal dingen wijzigen aan onze testfile:
Een testklasse aanmaken genaamd die erft van de klasse unittest.TestCase: TestCalculator(unittest.TestCase)
De testen als klasse methodes definiëren
De methoden moeten beginnen met test_
Je moet asserten met self.assert... (self verwijst hierbij naar de klasse zelf)
De main methode van unittest oproepen: unittest.main()
importunittestfromcalculatorimportdivideclassTestCalculator(unittest.TestCase):deftest_gegevenTeller2Noemer1_wanneerDivide_danResult2(self):result=divide(2,1)self.assertEqual(result,1)# Let op: 2/1 = 2, dus deze test zal falen!if__name__=="__main__":unittest.main()
Nu krijgen we bij het runnen van deze testfile een mooiere output:
arne@LT3210121:~/ses/tddpythondemo/src$ python3 -m unittest calculator_test.py
.
----------------------------------------------------------------------
Ran 1test in 0.000s
OK
We kunnen onze testfile nu uitbreiden net zoals we dat in Java gedaan hebben:
Er bestaan ook nog andere modules om testen uit te voeren in Python. Een zeer populaire module is Pytest. Deze module biedt onder andere een iets mooiere output met groene en rode highlights voor respectievelijk geslaagde en gefaalde testen.
Setting up VSCode for Python testing
Je kan de built-in VSCode tool gebruiken voor debugging (gecombineerd met de juiste extensies) om een mooie Gui interface te hebben voor de testen. Hiervoor klik je op onderstaande view panel en configureer je het juiste Testing framework, de plaats waar VSCode moet zoeken naar de test files en hoe de test files noemen.
Test suite for VSCode
Nadat je alles correct geconfigureerd hebt zouden je testen er als volgt moeten uitzien:
Voorbeeld testoutput Python
Integration tests
Net zoals in Java kunnen we Mocks hiervoor gebruiken om Test Doubles aan te maken. Gelukkig is ‘mocken’ een functionaliteit die rechtstreeks in unittest is ingebouwd. De doubler.py-file en doubler_test.py-file analoog aan het voorbeeld in integration testen in Java:
doubler.py: We geven nu een referentie naar de functie mee als parameter om te voldoen aan het principe van Dependency Injection.
importunittestfromunittest.mockimportpatchfromdoublerimportdouble_calculatorclassTestCalculator(unittest.TestCase):@patch("doubler.divide")# Mock de geïmporteerde `divide` functie in `doubler.py`deftest_gegevenOperationDivideX2Y1_wanneerDoubleCalculator_danResultIs4(self,mock_divide):# Arrange# De mock werd meegegeven als parameter en je stelt nu de return value inmock_divide.return_value=2.0# Actresult=double_calculator(mock_divide,2,1)# Assertself.assertEqual(result,4.0)# Verifieer dat `divide` werd aangeroepen met (2, 1)mock_divide.assert_called_once_with(2,1)if__name__=="__main__":unittest.main()
Onderstaande Python file bevat een aantal functies die getest worden met een testfile. Er zijn echter een heel deel testen die nog falen. Verbeter nu de python functies zodat alle testen slagen:
Dit is een stuk complexer en wordt ook net iets minder gebruikt dan in de higher level languages zoals Python en Java, maar nog altijd zeer handig. Je moet echter de juiste instellingen voor je compiler en dergelijke instellen. Om die reden laten we dit als zelfstudie voor de student die hierin geïnteresseerd is en refereren naar een video die gebruik maakt van CMake en Gtests om TDD in C mogelijk te maken.
Waarschuwing
Hoewel dat de tutorial gemaakt is rond C++ files, maakt dit niet uit omdat je hier ook gewoon C functies kan gebruiken. Het is echter wel waar dat de testen zelf WEL in een .cpp-file (C++) geschreven moeten zijn! In de oude cursus Besturingssystemen & C kan je ook nog eens de nodige info terugvinden indien gewenst.
Hieronder toch al een klein voorbeeld waar je mee van start kan gaan:
Unit testen in C met CMake
We maken een klein C‑project en schrijven twee eenvoudige unit testen. We maken een klein calculatorvoorbeeld dat vergelijkbaar is met wat je eerder in Java hebt gezien.
Installeren van de benodigde tools (normaal gezien al ok)
Net zoals in Java willen we controleren of onze functie correct werkt. C heeft geen ingebouwd testframework zoals JUnit, maar we kunnen de assert macro gebruiken zoals in Python. Wanneer een assert faalt, stopt het programma met een foutmelding.
cmake_minimum_required(VERSION3.16)project(CalculatorCC)set(CMAKE_C_STANDARD11)# Testing ondersteuning activeren
enable_testing()# Library target
add_library(calculatorsrc/calculator.c)target_include_directories(calculatorPUBLICinclude)# Test executable
add_executable(test_calculatortests/test_calculator.c)target_link_libraries(test_calculatorPRIVATEcalculatorm)# Test registreren
add_test(NAMEcalculator_testsCOMMANDtest_calculator)
Builden en testen
We builden het project zoals we gewend zijn met cd build && cmake .., daarna builden we met make en runnen de testen met make test. Zo simpel kan het zijn
Een voorbeeld output van de testen geeft: (Als alle testen slagen)
ubuntu@DESKTOP-4KP0M1C:~/tdd/ctest/build$ make testRunning tests...
Test project /home/ubuntu/tdd/ctest/build
Start 1: calculator_tests
1/1 Test #1: calculator_tests ................. Passed 0.00 sec100% tests passed, 0 tests failed out of 1Total Test time(real)= 0.00 sec
Of volgende output als er testen falen:
ubuntu@DESKTOP-4KP0M1C:~/tdd/ctest/build$ make testRunning tests...
Test project /home/ubuntu/tdd/ctest/build
Start 1: calculator_tests
1/1 Test #1: calculator_tests .................Subprocess aborted***Exception: 0.02 sec0% tests passed, 1 tests failed out of 1Total Test time(real)= 0.02 sec
The following tests FAILED:
1 - calculator_tests (Subprocess aborted)Errors while running CTest
Output from these tests are in: /home/ubuntu/tdd/ctest/build/Testing/Temporary/LastTest.log
Use "--rerun-failed --output-on-failure" to re-run the failed cases verbosely.
make: *** [Makefile:71: test] Error 8
Merk op dat met deze simpele manier alles faalt zodra 1 test faalt, aangezien de hele main functie faalt met de asser. Voor meer granulariteit kan je dus best de Google Test Suite gebruikem.
Meer leermateriaal
Extra leermateriaal
Lees de volgende artikels om een beter inzicht te krijgen in de capaciteiten van de Test-Driven benadering:
Het softwareontwikkel proces is een continu proces: als een eerste versie van het product klaar is, en wordt overgemaakt aan klanten, volgt het onderhoud en een mogelijke volgende versie. Elke wijziging maakt potentiëel dingen kapot (geminimaliseerd met TDD), of introduceert nieuwe features. Dat betekent dat bij elke wijziging, een computer het hele build proces moet doorlopen om te controleren of er niets stuk is. Dit noemen we het “integreren” van nieuwe code, vandaar de naam.
De CI Server
In de praktijk worden aparte servers verantwoordelijk gesteld om regelmatig de hele codebase te downloaden, alles te compileren, en testen uit te voeren. Als iets niet compileert, of een test faalt, rapporteert dit systeem via diverse kanalen aan de ontwikkelaars. Niemand wilt dit in de achtergrond op zijn eigen machine een tweede build systeem geïnstalleerd hebben, die CPU kracht afsnoept van je eigen PC. De volgende Figuur verduidelijkt de flow (bron):
Dit hele proces verloopt volledig automatisch: niemand drukt op een “build” knop, maar door middel van ingecheckte code wijzigingen (1) start dit systeem. De CI server haalt wijzigingen op (2), build (3) en test (4) om te kunnen rapporteren of dit lukte of niet (5), via verschillende kanalen (6).
De Source Control server, zoals Github.com of een lokale git server, werd reeds besproken in labo ‘versiebeheer’. Er zijn voor Java verschillende populaire CI software systemen:
Travis—de eerste CI die naadloos met GitHub integreerde, maar nu betalend is
CirlceCi—een populair hosted alternatief voor Travis
Jenkins—een ondertussen oudere speler op de CI markt
Drone—een nieuwe speler met focus op Docker module integratie
Dagger—een CI/CD engine die in containers runt en programmeerbaar in plaats van configureerbaar is
Deze systemen zijn configureerbaar en beschikken over een UI, zoals bijvoorbeeld zichtbaar in de TeamCity screencast. Betalende systemen zoals TeamCity en Bamboo zijn erg uitgebreid, en er zijn ook een aantal gratis alternatieven zoals CircleCI. CircleCI is eenvoudig configureerbaar door middel van een .yml bestand en het gratis plan integreert naadloos met GitHub. Wij gaan echter rechtstreeks via Github Actions werken aangezien dit rechtstreeks via Github kan geconfigureerd worden en op zeer gelijkaardige manier werkt zoals bovenstaande services.
De flow van een CI server
Je Github Actions moeten gedefinieerd worden in de folder .github/workflows in een .yml-bestand. Github helpt je echter om snel veelgebruikte actions op te stellen op basis van je code in de repository.
Via het Actions tabblad worden enkele voorstellen gedaan. Je kan gebruik maken van de Gradle test template. Je .yml-bestand wordt automatisch aangemaakt en zie er uit zoals op onderstaande figuur is weergegeven
Let op: de yml-syntax is zeer gevoelig aan het juiste gebruik van tabs en spaces (gelijkaardig aan python)
1. on
Onder de on sectie ga je definiëren bij welke specifieke acties de onderstaande jobs uitgevoerd moeten worden.
2. Setup Environment
In de jobs sectie kunnen we dan verschillende jobs oplijsten. In het begin van elke job moeten we vermelden op welk besturingssysteem we onze job willen uitvoeren. (Bv. Windows, Mac, Linux).
Je kan jobs ook automatisch op meerdere besturingssystemen laten uitvoeren.
We moeten er natuurlijk ook voor zorgen dat alle applicaties aanwezig zijn om onze code te kunnen compileren en runnen. Daarvoor moeten we de nodige tools installeren in deze virtuele omgeving!
3. Build Code
Nu kunnen we simpelweg gebruik maken van de Gradle tasks.
4. Package Code & Upload Artifact
Zodra één stap mis gaat (zoals een falende test), worden volgende stappen niet uitgevoerd. Als alles goed gaat is de output van het builden de binary die we het artifact noemen, die de huidige buildstamp draagt (meestal een datumcode).
Alle gebuilde artifacts kunnen daarna worden geupload naar een repository server, zoals de Central Maven Repository, of onze eigen artifact server, waar een historiek wordt bijgehouden. (Dit gaan we niet doen in deze cursus)
5. Publish Results
In de README.md van je repository kan je een Github Badge plaatsen die de status van je action snel weergeeft.
Bij de opdrachten zal je repository onder de organisatie KULeuven-Diepenbeek staan, en niet onder je eigen username.
2. Continuous Deployment (CD)
Automatisch code compileren, testen, en packagen, is slechts één stap in het continuous development proces. De volgende stap is deze package ook automatisch deployen, of installeren. Op deze manier staat er altijd de laatste versie op een interne development website, kunnen installaties automatisch worden uitgevoerd op bepaalde tijdstippen, …
Modules van moderne CI systemen zoals hier boven vermeld, bijvoorbeeld Dagger/Drone Deployment
Eigen scripts gebaseerd op CI systemen
Cloud deployment systemen (Amazon AWS, Heroku, Google Apps, …)
Automatisch packagen en installeren van programma’s stopt hier niet. Een niveau hoger is het automatisch packagen en installeren van hele omgevingen: het virtualiseren van een server. Infrastructuur automatisatie is een vak apart, en wordt vaak uitgevoerd met behulp van tools als Puppet, Docker, Terraform, Ansible of Chef. Dit valt buiten de scope van deze cursus.
2.1. De flow van deployment en releases beheren
Nieuwe features in productie plaatsen brengt altijd een risico met zich mee. Het zou kunnen dat bepaalde nieuwe features bugs veroorzaken in de gekende oude features, of dat het (slecht getest) systeem helemaal niet werkt zoals men verwachtte. Om dat zo veel mogelijk te vermijden wordt er een release plan opgesteld waarin men aan ‘smart routing’ doet.
Stel, onze bibliotheek-website is toe aan vernieuwing. We wensen een nieuw scherm te ontwerpen om efficiënter te zoeken. We zijn echter niet zeker wat de gebruikers gaan vinden van deze nieuwe manier van werken, en beslissen daarom om slechts een aantal gebruikers bloot te stellen aan deze radicale verandering. Dat kan op twee manieren:
Blue/green releasing: Een ‘harde switch’ in het systeem bepaalt welke personen (bijvoorbeeld op regio of IP) naar versie van het zoekscherm worden begeleid.
Canary releasing: Een load balancer verdeelt het netwerkverkeer over verschillende servers, waarvan op één server de nieuwe versie is geïnstalleerd. In het begin gaat 90% van de bezoekers nog steeds naar de oude versie. Dit kan gradueel worden verhoogd, totdat de oude server wordt uitgeschakeld.
De juiste logging en monitoring tools zorgen ervoor dat we een idee krijgen over het gebruik van het nieuwe scherm (groen, versie B). Gaat alles zoals verwacht, dan wordt de switch weggehaald in geval (1), of wordt de loadbalancer ge-herconfigureerd zodat het hele verkeer naar de nieuwe site gaat in geval (2). Ook deze aanpassingen zijn volledig geautomatiseerd. Na verloop van tijd valt de oude versie (blauw, versie A) volledig weg, en kunnen we ons concentreren op de volgende uitbreidingen.
Het groene vlak, de ‘Ambassador/API gateway’, kan aanzien worden als:
Een fysiek aparte machine, zoals een loadbalancer.
Een publieke API, die de juiste redirects verzorgt.
Een switch in de code, die binnen dezelfde toepassing naar scherm 1 of 2 verwijst.
Versie A en B hoeven dus niet noodzakelijk aparte versies van applicaties te zijn: dit kan binnen dezelfde applicatie, softwarematig dus, worden ingebouwd.
Oefeningen (enkel ter oefening, de verplichte opdracht rond CI vind je bij de andere opdrachten)
Volgende videos kunnen je helpen bij het oplossen van de oefeningen en de uiteindelijke opdracht:
Video over Github actions met Gradle: Hier kan je dan specifiek terugvinden hoe je de concepten van in de vorige video kan toepassen op je Gradle projecten.
Oefening 1
Ontwerp een ‘calculator’ applicatie die 2 getallen kan optellen, aftrekken, het product en het quotient (zonder rest) kan berekenen. (gebruik Gradle)
Schrijf een aantal testen voor deze applicatie.
Maak een github repository aan en gebruik Github Actions om je applicatie automatisch te laten testen bij een push naar de main branch.
Oefening 2
Gebruik een andere workflow.yml om je repo uit opgave 1 te beveiligen tegen pull-requests. Zorg ervoor dat eerst je testen moeten slagen en je applicatie gebuild kan worden voordat je een pull request kan toelaten. (Test dit ook uit met een medestudent).
Kijk in Github bij de settings van je repo -> branches -> require status checks
Let op: je repo moet hiervoor public zijn. Je kan zoeken op status checks via de job names in je .yml action files
Opgave 3
Voeg nu aan je applicatie uit de vorige oefening de mogelijkheid toe om in te loggen.
Simuleer nu Continuous Development door geen begroeting in te voeren voor alle gebruikers, maar alle gebruikers wiens gebruikersnaam start met de letter ‘A’ moet een begroeting krijgen zoals bv. “Welkom terug ”.
Denkvragen
Waarom is het belangrijk om gebuilde artifacts van de CI server bij te houden?
Wat zijn de voordelen van het werken met een CI en CD systeem, ten opzichte van alles met de hand (of met eigen gemaakte scripts) in te stellen?
Version control en continuous delivery zijn klassiek gezien vijanden van database migratie (of omgekeerd). Toch is het mogelijk om een database systeem ook automatisch te up- of downgraden, met bijvoorbeeld https://flywaydb.org. Hoe gaat zoiets in zijn werk?
Zou het ook mogelijk zijn om een geautomatiseerde scenariotest uit te voeren in CircleCI? Zo ja, welke wijzigingen zou je moeten doorvoeren aan de config.yml?
Software Management Skills
De chaos van het Werk
De technische kant van het ontwikkelproces is slechts één kant van de medaille. De keerzijde bestaat uit het werk beheren en beheersen, zonder ten prooi te vallen aan de grillen van de klant of de chaos van de organisatie ervan.
Stel, een gemeente vraagt om een nieuwe website te ontwikkelen voor de lokale bibliotheek. Er wordt een vergadering ingepland met stafhouders om samen met jou te beslissen wat de vereisten zijn. Ze dachten aan een mooie visuele website (1) waar men ook on-line kan verlengen (2) en het profiel raadplegen (3). De website moet uiteraard de gebruiker laten weten of een boek is uitgeleend of niet (4), en nieuwe aanwisten verdienen een aparte pagina (5). Men wil kunnen inloggen met de eID (6), én met een speciale bibkaart (7). Een bezoek aan de bib zelf levert je nog meer eisen op: het personeel wilt immers de nadruk leggen op andere zaken dan de stafhouders.
Hoe ga je te werk om dit te beheren en tot een succesvol einde te brengen? Er is een raamwerk nodig om:
Werk overzichtelijk in kaart te brengen
Werk in te schatten en op te delen in beheersbare deeltaken
Werk eenvoudig te kunnen verdelen
Werk zichtbaar te maken: wie met wat bezig is, wanneer het klaar is, …
De klant in elke stap van het proces zo nauw mogelijk te betrekken
A. Werk managen: Scrum
De alsmaar populair wordende term ‘scrum’ komt vanuit de Amerikaanse sport rugby, waar men letterlijk de koppen bij elkaar steekt om nog een laatste peptalk uit te delen voordat de chaos van de wedstrijd zelf losbarst (Bron):
Het principe van deze coördinatie is gemuteerd naar de softwareontwikkeling, waar het Scrum framework een oplossing kan bieden voor ons beheer probleem, waarvan alle 5 bovenstaande punten van het probleem op een structurele manier worden aangepakt.
Een Werk ‘raamwerk’
Een agile software development methodologie is een methodologie om snel te kunnen ingrijpen op veranderingen. Klanten zijn van nature erg wispelturig en weten vaak zelf niet goed wat ze willen. Daarom is een ontwikkelmethode die sneller van richting kan veranderen tegenwoordig veel waardevoller dan een log systeem waarbij veel analysewerk op voorhand wordt verricht, om daarna alles te ontwikkelen. Een voorbeeld van zo’n klassiek log systeem is het waterval model. Een voorbeeld van zo’n modern agile systeem is scrum.
De volgende Figuur representeert het Scrum principe in de technische wereld:
Het Scrum principe verdeelt de ontwikkeltijd in een aantal iteraties, waarbij een iteratie een vooropgestelde tijd is, meestal 14 of 30 dagen, die een vaste kadans bepaalt waarin teams software ontwikkelen. Elke iteratie gebeurt er hetzelfde: bepalen wat te doen binnen die iteratie, de ontwikkeling ervan, en het vrijgeven van een nieuwe versie van het al dan niet volledig afgewerkt product.
De introductie van itererende blokken waar taken van de backlog worden genomen en verwerkt, biedt de mogelijkheid tot veranderen. Tussen elke iteratie in kan er worden bijgestuurd door functionaliteit op de (product) backlog te verwijderen, toe te voegen, of te wijzigen.
1. De Backlog
De backlog is een grote lijst van zaken die moeten worden ontwikkeld voordat de klanten tevreden zijn (een ‘story’’). Men begint met één grote product backlog waar op een hoog niveau alle eisen in zijn beschreven. Voor elke sprint van x dagen (30 in de Figuur), beslist het team welke items van deze backlog naar de sprint backlog worden verplaatst: dit zijn de zaken die het team denkt te kunnen verwerken in één sprint.
Een product backlog bevat stories die nog niet goed geanalyseerd en beschreven zijn, waarvan moeilijk te zeggen valt hoeveel werk dit effectief kost. Wanneer dit in een iteratie terecht komt, wordt dit nauwer bekeken door het team. De betere beschrijving leidt tot een accurate inschatting, en mogelijks zelfs meerdere backlog items.
Het volgende filmpje verduidelijkt de rol van de backlog in het team:
2. Taken
Een sprint backlog item wordt typisch door ontwikkelaars nog verder opgesplitst in kleinere taken om het werk beter te kunnen verdelen. Bijvoorbeeld, de mogelijkheid tot inloggen met eID kan bestaan uit (1) authenticatiestappen en het inlezen van een kaart, en (2) het UI gedeelte waar de gebruiker mee interageert. Misschien beschikt al één teamlid over authenticatie kennis, maar nog niemand weet hoe de UI aan te pakken. In dat geval is taak (1) sneller gedaan dan taak (2).
Als alle taken zijn opgesplitst, worden er inschattingen gemaakt van elke taak, ten opzichte van een referentie taak. Inschattingen zijn relatieve getallen in Fibonacci nummers: 1, 2, 3, 5, 8, … Hoe moeilijker of groter de taak, hoe vaker teams verkeerde inschattingen maken, en hoe meer impact dit heeft op de planning, vandaar de snel groeiende nummers. De referentie taak heeft een vast nummer in de rij, zoals bijvoorbeeld 2. Merk op dat dit nummer dus niets te maken heeft met een concreet aantal (uren, dagen) werk.
Stel dat een simpel loginscherm reeds werd ontwikkeld. Men schat dan de moeilijkhei van het authenticeren van eID in ten opzichte van het werk aan het loginscherm: zou dat veel minder werk kosten, of meer? Minder werk: 1. Meer werk: veel moeilijker of een beetje? Veel: 5 of meer. Een beetje: 3.
3. Een iteratie
Elke iteratie bestaande uit bijvoorbeeld 30 dagen kan een team een bepaald aantal ingeschatte punten verwerken, zoals 30. Men kiest een aantal taken waarvan de som van de inschatting niet dit maximum overschrijdt, en men begint aan de iteratie.
Elke dag is er ’s morgens een scrum stand-up: een korte, rechtstaande vergadering, waarin iedereen vertelt:
Wat hij of zij gisteren gedaan heeft
Wat hij of zij vandaag gaat doen
Met welke problemen hij of zij kampt
Op die manier is onmiddellijk iedereen op de hoogte. Dit noemt men ook wel een scrum meeting, geïnspireerd op de Rugby scrum. Als men merkt dat collega’s problemen hebben kan er dan beslist worden om taken weg te laten, toe te voegen, enzovoort.
Werk visualiseren
Een van de belangrijkste redenen om voor een agile methodologie te kiezen als Scrum, is de mogelijkheid tot het visualiseren van werk. Een team van 6 mensen kan daardoor ten allen tijden in één oogopslag zien aan welke taken wordt gewerkt, welke taken/stories in de iteratie zijn opgenomen, en waar het schoentje knelt (bron):
Elke story wordt een ‘swimlane’ toegewezen: een horizontale band, die wordt opgedeeld in een aantal kolommen. Wanneer alle taken van één story van links naar rechts zijn verhuisd, weet het team dat die bepaalde functionaliteit (de story) klaar is voor de eindgebruikers. De taken kunnen worden gecategoriseerd met behulp van kleurcodes (technische opzet, database werk, UI werk, scherm x, y, …) De kolommen zelf variëren van team tot team. Een voorbeeld:
(Task) Todo
Doing (in progress in bovenstaande Figuur)
To Review/To Test/Done
Een taak die van Doing naar Done wordt verschoven is daarom niet volledig afgewerkt. Het kan zijn dat de ontwikkeling af is, maar dit nog moet worden nagekeken door een technische collega (to review), of worden getest door de customer proxy (to test), of worden uitgerold naar een interne test- of acceptatieomgeving (to deploy).
In het volgende filmpje komen verschillende implementaties van persoonlijke scrumborden aan bod, om je een idee te geven van de aanpasbaarheid van zulke borden:
Hier wordt het woord kanban gebruikt om aan te geven dat werk wordt gevisualiseerd - maar niet noodzakelijk een deel is van agile softwareontwikkeling of van scrum. Zoals je kan zien is het dus ook een effectieve manier om voor jezelf TODO/DOING/DONE items (school taken, hobby’s, …) op te hangen en dus visueel te maken.
B. Teams managen: Rolverdelingen
Werk verdelen en managen is niet het enige sterkte punt van Scrum. Een efficiënt team opbouwen dat in staat is om verschillende rollen op te nemen is nog een van die punten. Om bovenstaande stories en taken als onderdeel daarvan zo goed mogelijk te kunnen afwerken, dient het werk verdeeld te worden. Hieronder volgt een kort overzicht van de vaakst voorkomende rollen.
De Product Owner
Een Scrum team is sterk klant-georiënteerd, waarbij stories hoofdzakelijk het gevolv zijn van de vraag van de klant. Ook welke stories in welke iteratie worden opgenomen is het gevolg van de wil van de klant. In de praktijk heeft de klant, een ander bedrijf dus, nauwelijks tijd om het ontwikkelproces op de voet op te volgen.
Daarom dat de product owner (PO) die belangrijke taak van de klant overneemt. Een Product Owner is een domein expert van het ontwikkelbedrijf die het overzicht bewaart: hij of zij weet welke stories nog moeten volgen, kan wijzigingen laten doorvoeren, en kent het product vanbinnen en vanbuiten. De PO overlegt vaak met de klant zelf en vertegenwoordigt de belangen van de klant bij het ontwikkelbedrijf.
De Customer Proxy
Stories zijn niet meer dan kleine briefjes waar in een paar zinnen staat beschreven welke grote blokken functionaliteit de klant verwacht. Voordat dit kan worden opgesplitst in deeltaken dient er een grondige analyse uitgevoerd te worden. Dit gebeurt door de customer proxy, vaak ook gewoon analist genoemd.
De customer proxy is, zoals het woord zegt, een vervanger voor de klant, die expert is in bepaalde deeldomeinen. De Product Owner bewaart het overzicht op een hoog niveau, van het héle product, en de Customer Proxy is expert in bepaalde deeldomeinen. Ontwikkelaars en proxies discussiëren en beslissen vaak samen de werking van bepaalde delen van het product, waarbij de proxy de belangen van de klant hierin verdedigt. Er zijn typisch meerdere proxies aanwezig in één team, terwijl er maar één product owner is.
De Ontwikkelaar
Stories worden opgesplitst in taken door de proxy en ontwikkelaar, die de functionele en technische gebundelde kennis gebruiken om problemen op te delen in kleinere, en makkelijker verwerkbare, deelproblemen. De ontwikkelaar is verantwoordelijk voor de implementatie van taken, en kan daardoor taken van todo naar doing en done verhuizen op het scrumbord.
De Team leider
Ontwikkelen en analyseren loopt nooit van een leien dakje. Een leider zorgt er voor dat het team zo weinig mogelijk last heeft van eender welke vorm van afleiding. Dat betekent zowel te veel druk van de klant als mogelijke administratieve taken die het bedrijf eist van elke werknemer. Een goede team leider is een onzichtbare die er voor zorgt dat iedereen zijn werk kan doen.
Een tweede taak van de team leider is het opvolgen van vooruitgang van de sprint. Het zou kunnen dat ingeschatte stories meer werk kosten dan initiëel gepland, of dat er een gaatje is om extra werk op te nemen. Dit wordt gevisualiseerd door middel van een ‘burndown chart’, een grafiek die het aantal nog te behandelen taken afbeeldt op de resterende tijd in dagen of uren (bron):
Pieken boven de groene ideaallijn betekent onverwacht extra werk die niet werd ingepland, waarbij de team leider mogelijk moet ingrijpen. Dalingen onder de groene lijn betekent vlot werk met mogelijkheid tot iets extra buiten de sprint. De team leider overlegt vaak met de Product Owner om de verwachtingen zo goed mogelijk bij de ideaallijn gealigneerd te krijgen.
Trends in burndown charts evalueren is een belangrijke vaardigheid voor elk lid van het team. Iedereen kan in één oogopslag onmiddellijk zien of het team meer werk heeft gedaan dan initieel ingepland, nog op schema ligt, of erg achter hinkt. Pieken en dalingen in de grafiek zijn duidelijke tekenen van onder- of overschattingen van de story’s. In bovenstaande grafiek krijgt het team bijvoorbeeld na dag 4 (X-as) een zware dobber te verwerken dat meer tijd kost dan eerst gedacht, die pas na dag 9 wordt opgelost. Tussen dag 11 en 15 verloopt alles op cruise snelheid - het gaat zelfs lichtjes beter dan verwacht. De grafiek ‘remaining effort’ is de belangrijkste (bron).
Het effect is erg uitgesproken op de tweede grafiek. Op dag 3 valt het team volledig stil (de oorzaak is natuurlijk niet af te lezen, dit kan zowel liggen aan technische problemen als aan bijvoorbeeld ziekte van een aantal programmeurs), wat de scherpe piek verklaart. De rest van de iteratie zwoegt het team om het verloren werk in te halen, wat pas na dag 10 uiteindelijk bijna lukt.
Deze informatie is erg belangrijk omdat het kan worden gebruikt om toekomstige sprints in te plannen. Grafieken worden ge-extrapoleerd om een betere inschatting te kunnen maken van het toekomstige werk. Een consistent goed presterend team - de remaining effort lijn ligt onder de remaining time - kan in de toekomst bijvoorbeeld meer werk aan binnen dezelfde iteratie. Het is dan aan de team leider om dit naargelang in te plannen.
Lees meer over de burndown chart via de extra bronnen.
Opdrachten
Dit deel bevat geen opdrachten maar kennis ervan zal afgetoetst worden tijdens het schriftelijk examen. Bijvoorbeeld wat betekent SCRUM en wat is Agile Development.
Denkvragen
Wat is het voordeel van taken of stories relatief ten opzichte van een referentiestory in te schatten, in plaats van een hoeveelheid in tijd zoals dagen of uren te gebruiken?
Wat is het verschil in taak tussen de Product Owner en de Customer Proxy?
Hoe lang moet een ideale iteratie volgens jou zijn, in dagen? Beargumenteer.
Waarvoor kan een burndown chart gebruikt worden? Bedenk minstens drie verschillende mogelijkheden en beargumenteer.
De inhoud van deel 2 wordt enkel gevolgd door de studenten SES.
7. Advanced Java
Hier start het tweede deel van de cursus, waarin we enkele geavanceerdere Java-concepten bekijken.
Deze concepten laten toe om op een moderne, efficiënte manier te programmeren, en vormen de basis om complexere problemen efficiënt op te lossen, bijvoorbeeld door te werken met recursie en backtracking.
We bekijken hier concepten uit Java, maar deze hebben vaak een equivalent in andere talen.
Aan het begin van elk hoofdstuk lijsten we daarom ook telkens kort op welke concepten uit andere programmeertalen hier het dichtst bij aanleunen.
Subsecties van 7. Advanced Java
7.1 Java basics
Als je Java-kennis wat roestig is (of wanneer je meer ervaring hebt in een andere programmeertaal), kan je je Java-kennis even opfrissen aan de hand van deze pagina.
IntelliJ
We maken voor de lessen in dit deel geen gebruik van VSCode, maar schakelen over naar Jetbrains IntelliJ IDEA, een van de vaakst gebruikte professionele Java IDE’s.
De gratis Community Edition volstaat voor dit vak, maar je kan als student ook een gratis licentie voor de Ultimate Edition aanvragen.
Download en installeer IntelliJ op je machine.
In IntelliJ organiseer je je code in projecten.
Elk IntelliJ scherm heeft op elk moment één geopend (actief) project.
Binnen een project heb je één of meer modules.
Een module is een onderdeel van een software-project.
Elke module kan in een verschillende programmeertaal geschreven zijn, en/of met zijn eigen (specifieke) instellingen gecompileerd worden.
Elke module is dus onafhankelijk.
In deel 2 van dit vak zullen we voor elk onderwerp (~elke les) een afzonderlijk project maken, en voor elke oefening een aparte module binnen dat project maken.
Dat zorgt ervoor dat je elke oefening onafhankelijk kan oplossen.
In combinatie met git zullen we één repository per project (en dus per onderwerp) gebruiken.
Je opdracht voor dit deel maak je ook in een apart project (en aparte git repository); zie de instructies bij de opdrachten.
Oefening 1: Hello world
Maak in IntelliJ een leeg project (Empty project) aan (dus geen Java-project!) met volgende instellingen:
Type (links in het scherm): Empty Project
Name: naar keuze (bijvoorbeeld sessie01-basics)
Location: ergens op je Linux/WSL2 installatie (bijvoorbeeld een map \\wsl.localhost\Ubuntu\home\youruser\ses-intellij)
Create git repository: aan
Klik op Create.
IntelliJ opent nu je project. Je kan de projectstructuur tonen en verbergen door links op het map-icontje te drukken.
Maak in de root van het project eerst een nieuw leeg bestand .noai. Dit zet de AI-ondersteuning in dit project uit.
Voeg nu een nieuwe Java-module toe aan het project:
Type (links in het scherm): Java
Name: naar keuze (bijvoorbeeld oef01-helloworld)
Location: zou standaard goed moeten staan (locatie van het project)
Build system: IntelliJ (later zullen we overschakelen naar Gradle)
JDK: een recente versie (25 of hoger)
Add sample code: uit
Klik op Create.
Geen Java 25?
Als je WSL2-installatie geen Java 25 SDK bevat, kan je deze via een terminal installeren met
sudo apt update
sudo apt install openjdk-25-jdk
Je ziet de module nu verschijnen als subfolder van je project.
Maak in de src-folder van deze module een nieuwe klasse HelloWorld, en kopieer volgend programma.
Met deze oefening fris je je geheugen over het gebruik van if en for nog eens op.
Maak een nieuwe Java-module oef02-basis.
Maak in die module een klasse Opteller die een getal n vraagt aan de gebruiker,
vervolgens de som berekent van alle oneven getallen van 1 tot en met n, en tenslotte het resultaat afdrukt.
Bijvoorbeeld:
Geef een getal: 25De som van de oneven getallen van 1 tot en met 25 is 169
Hint: gebruik IO.readln() en IO.println() om te lezen van en schrijven naar de console. Deze methodes zijn nieuw sinds Java 25.
Je kan een String omzetten naar een getal via Integer.parseInt.
Oplossing
classOpteller{publicstaticvoidmain(String[]args){intn=Integer.parseInt(IO.readln("Geef een getal: "));longsom=0;for(inti=1;i<=n;i++){if(i%2==1){som+=i;}}IO.println("De som van de oneven getallen van 1 tot en met "+n+" is "+som);}}
Oefening 3: Klasse en ArrayList
Deze oefening dient om je kennis van klassen en het gebruik van een ArrayList nog eens op te frissen.
Maak een nieuwe Java-module oef03-arraylist.
Maak in die module een nieuwe klasse Persoon met 2 attributen (velden):
een naam (String)
een leeftijd (int)
Maak ook een klasse Programma met een main-methode die aan de gebruiker steeds achtereenvolgens een naam en leeftijd vraagt, telkens een object van klasse Persoon aanmaakt, en deze Persoon-objecten bijhoudt in een ArrayList.
De invoer stopt wanneer de ingegeven naam leeg is.
Vervolgens moeten de gegevens van alle ingegeven personen uitgeprint worden (in de volgorde dat ze ingegeven werden).
Bijvoorbeeld:
Geef de naam van de volgende persoon: Jan
Geef de leeftijd van Jan: 25Geef de naam van de volgende persoon: Marie
Geef de leeftijd van Marie: 28Geef de naam van de volgende persoon:
De ingegeven personen zijn:
- Jan (25 jaar)- Marie (28 jaar)
// Programma.javaimportjava.util.ArrayList;publicclassProgramma{publicstaticvoidmain(){ArrayList<Persoon>personen=newArrayList<>();Stringnaam=IO.readln("Geef de naam van de volgende persoon: ");while(!naam.isBlank()){intleeftijd=Integer.parseInt(IO.readln("Geef de leeftijd van "+naam+": "));Persoonp=newPersoon(naam,leeftijd);personen.add(p);IO.println();naam=IO.readln("Geef de naam van de volgende persoon: ");}IO.println("De ingegeven personen zijn:");for(varp:personen){IO.println("- "+p);}}}
7.2 Java Collecties
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java collections zijn
de Standard Template Library (STL) in C++
enkele ingebouwde types, alsook de collections module in Python
de collecties in System.Collections.Generic in C#
Het komt vaak voor dat we meerdere objecten willen kunnen bijhouden.
Totnogtoe heb je hiervoor in de cursus Software-ontwerp in Java enkel gewerkt met een Java array [] (vaste grootte), en met ArrayList<T> (kan groter of kleiner worden).
In dit hoofdstuk kijken we in meer detail naar ArrayList, en behandelen we ook verschillende andere collectie-types in Java.
De meeste van die types vind je ook (soms onder een andere naam) terug in andere programmeertalen.
Je kan je afvragen waarom we andere collectie-types nodig hebben; uiteindelijk kan je (met genoeg werk) alles toch implementeren met een ArrayList? Dat klopt, maar de collectie-types verschillen in welke operaties snel zijn, en welke meer tijd vragen. Om dat preciezer uit te drukken, kan je gebruik maken van de notie van tijdscomplexiteit. We gaan daar in deze cursus niet verder op in; dat komt uitgebreid aan bod in de cursus Algoritmen en datastructuren.
implementaties van die interfaces (bv. ArrayList, LinkedList, Vector, Stack, ArrayDeque, PriorityQueue, HashSet, LinkedHashSet, TreeSet, en TreeMap)
algoritmes voor veel voorkomende operaties (bv. shuffle, sort, swap, reverse, …)
Je vindt een overzicht van de hele API op deze pagina.
Weetje: andere collectie-types
Behalve de Java Collections API zijn er ook externe bibliotheken met collectie-implementaties die je (bijvoorbeeld via Gradle) kan gebruiken in je projecten.
De twee meest gekende voorbeelden zijn
Collecties maken veelvuldig gebruik van zogenaamde generische (type-)parameters.
Dat zijn parameters die bij de naam van een klasse horen.
Ze staan steeds tussen < en >, bijvoorbeeld de <String> die je vroeger al tegenkwam bij ArrayList<String>.
We zullen generische parameters later in veel meer detail behandelen.
Voorlopig volstaat het om Collectie<E> te lezen als “Collectie van E’s”.
Om (straks bij de oefeningen) een zelfgedefinieerde klasse een generische parameter te geven, voeg je <E> toe achter de klasse-naam (je mag gerust ook andere namen gebruiken dan E, bijvoorbeeld T, Element, …).
Bijvoorbeeld:
classMijnCollectie<E>{voidvoegToe(Eelement){...}}
Binnen in de klasse kan je dan E gebruiken als type voor methode-parameters, lokale variabelen, en velden.
In het voorbeeld hiervoven heeft de parameter element van methode voegToe het type E.
Wat E precies is moet later bepaald worden, bij het gebruik van de klasse (= het aanmaken van een object).
Op dat moment moet je een concrete waarde opgeven voor E.
Bijvoorbeeld, als je een object van MijnCollectie wil maken waaraan je enkel Persoon-objecten kan toevoegen, dan kan dat als volgt:
Je kan het type MijnCollectie<Persoon> dus zien als de klasse MijnCollectie<E> waarin alle voorkomens van E vervangen werden door Persoon.
Iterable en Iterator
De interfaces Iterable<E> en Iterator<E> maken eigenlijk geen deel uit van de Java Collections API, maar zijn er wel sterk aan verwant.
Een Iterable<E> is een object dat meerdere objecten van type E één voor één kan teruggeven.
Er moet slechts één methode geïmplementeerd worden, namelijk iterator(), die een Iterator<E>-object teruggeeft (zie hieronder).
Elke klasse die Iterable implementeert, kan automatisch gebruikt worden in een zogenaamd ’enhanced for-statement’:
Iterable<E>iterable=...for(Eelement:iterable){...// code die element gebruikt}
Een Iterator<E> is een object dat gebruikt kan worden om (éénmalig) door alle elementen van een collectie te lopen.
Een Iterator<E> heeft twee methodes:
boolean hasNext(): geeft aan of er nog objecten zijn om terug te geven
E next(): geeft het volgende object (van type E) terug (als er nog objecten zijn).
Elke keer je next() oproept krijg je dus een ander object, tot hasNext() false teruggeeft. Vanaf dan krijg je een exception (NoSuchElementException).
Een Iterator moet dus een interne toestand bijhouden om te bepalen welke objecten al teruggegeven zijn en welke nog niet.
Eens alle elementen teruggegeven zijn, en hasNext() dus false teruggeeft, is de iterator ‘opgebruikt’.
Als je daarna nog eens over de elementen wil itereren, moet je een nieuwe iterator aanmaken.
Bij een enhanced for-statement wordt achter de schermen een iterator gebruikt.
Het enhanced for-statement van hierboven is equivalent aan volgende code:
Iterable<E>iterable=...Iterator<E>iterator=iterable.iterator();while(iterator.hasNext()){Eelement=iterator.next();...// code die element gebruikt}
Alle collectie-types die een verzameling elementen voorstellen (dus alles behalve Map), implementeren de Iterable interface.
Dat betekent dus dat je elk van die collecties in een enhanced for-lus kan gebruiken.
Je kan daarenboven ook zelf een nieuwe klasse maken die deze interface implementeert, en die vervolgens gebruikt kan worden in een enhanced for-loop.
Dat doen we later in de oefeningen.
Zoals je hierboven zag, kan een Iterable dus enkel elementen opsommen.
De basisinterface Collection erft hiervan over maar is uitgebreider: het stelt een eindige groep objecten voor.
Er zit nog steeds bitter weinig structuur in een Collection:
de volgorde van de elementen in een Collection ligt niet vast
er kunnen wel of geen dubbels in een Collection zitten
De belangrijkste operaties die je op een Collection-object kan uitvoeren zijn (volledige documentatie)
iterator(), geërfd van Iterable
size(): de grootte opvragen
isEmpty(): nagaan of de collectie leeg is
contains en containsAll: nakijken of een of meerdere elementen in de collectie zitten
add en addAll: een of meerdere elementen toevoegen
remove en removeAll: een of meerdere elementen verwijderen
clear: de collectie volledig leegmaken
toArray: alle elementen uit de collectie in een array plaatsen
Alle operaties die een collectie aanpassen (bv. add, addAll, remove, clear, …) zijn optioneel.
Dat betekent dat sommige implementaties een UnsupportedOperationException kunnen gooien als je die methode oproept.
Niet elke collectie hoeft dus alle operaties te ondersteunen.
List
classDiagram
Iterable <|-- Collection
Collection <|-- List
class Iterable["Iterable#lt;E>"] { <<interface>> }
class Collection["Collection#lt;E>"] { <<interface>> }
class List["List#lt;E>"] {
<<interface>>
get(int index)
add(int index, E element)
set(int index, E element)
remove(int index)
indexOf(E element)
lastIndexOf(E element)
reversed()
subList(int from, int to)
}
style List fill:#cdf,stroke:#99f
Een lijst is een collectie waar alle elementen een vaste plaats hebben.
De elementen in een lijst zijn dus geordend: je kan spreken over het eerste element, het tweede element, en het laatste element.
Merk op dat een lijst niet noodzakelijk gesorteerd is: het eerste element hoeft niet het kleinste (of grootste) element te zijn.
Een lijst wordt voorgesteld door de List interface, die Collection uitbreidt met operaties die kunnen werken met de plaats (index) van een object.
De ArrayList die je al kent, is een klasse die de List-interface implementeert.
get(int index): het element op een specifieke plaats opvragen
add(int index, E element): een element invoegen op een specifieke plaats (en de latere elementen opschuiven)
set(int index, E element): het element op een specifieke plaats wijzigen
remove(int index): het element op de gegeven index verwijderen (en de latere elementen opschuiven)
indexOf(E element) en lastIndexOf(E): de eerste en laatste index zoeken waarop het gegeven element voorkomt
reversed(): geeft een lijst terug in de omgekeerde volgorde
subList(int from, int to): geeft een lijst terug die een deel (slice) van de oorspronkelijke lijst voorstelt
Merk op dat de laatste twee methodes (reversed en subList) een zogenaamde view teruggeven op de oorspronkelijke lijst.
Het is dus geen nieuwe lijst, maar gewoon een andere manier om naar de oorspronkelijke lijst te kijken.
Bijvoorbeeld, in onderstaande code:
in de lijst rev het laatste element veranderen in X ook de oorspronkelijke lijst aanpast
de sublist cde leegmaken deze elementen ook verwijdert uit de oorspronkelijke lijst, alsook uit de omgekeerde view op de lijst (rev)
De reden is dat zowel rev als cde enkel verwijzen naar de onderliggende lijst alphabet, en zelf geen elementen bevatten:
block-beta
block:brev
space:1
rev
end
space
block:alphabet
columns 6
A B C D E F
end
space
block:bcde
cde
space:1
end
rev --> alphabet
cde --> alphabet
classDef node fill:#faa,stroke:#f00
classDef ptr fill:#ddd,stroke:black
classDef empty fill:none,stroke:none
classDef val fill:#ffc,stroke:#f90
class brev,bcde empty
class alphabet node
class rev,cde ptr
class A,B,C,D,E,F val
Indien je wat Python kent: subList is dus een manier om functionaliteit gelijkaardig aan slices te verkrijgen in Java. Maar, in tegenstelling tot slices in Python, maakt subList geen kopie, en is dus efficiënter!
ArrayList
ArrayList is de eerste concrete implementatie van de List-interface die we bekijken.
In een ArrayList wordt intern een array gebruikt om de elementen bij te houden.
Aangezien arrays in Java een vaste grootte hebben, kan je niet zomaar elementen toevoegen eens die onderliggende array vol is.
Daarom wordt er een onderscheid gemaakt tussen de de grootte van de lijst (het aantal elementen dat er effectief inzit), en de capaciteit van de lijst (de lengte van de onderliggende array).
Zolang de grootte kleiner is dan de capaciteit, gebeurt er niets speciaals. Op het moment dat de volledige capaciteit benut is, en er nog een element toegevoegd wordt, wordt een nieuwe (grotere) array gemaakt (bijvoorbeeld tweemaal zo lang) en worden alle huidige elementen daarin gekopieerd.
Bijvoorbeeld, voor een lijst met capaciteit 3 en twee elementen:
block-beta
columns 1
block:before
columns 12
e0["A"] e1["B"] e2[" "] space:9
end
space
block:after1
columns 12
ee0["A"] ee1["B"] ee2["C"] space:9
end
space
block:after2
columns 12
eee0["A"] eee1["B"] eee2["C"] eee3["D"] eee4[" "] eee5[" "] space:6
end
space
block:after3
columns 12
eeee0["A"] eeee1["B"] eeee2["C"] eeee3["D"] eeee4["E"] eeee5["F"] eeee6["G"] eeee7[" "] eeee8[" "] eeee9[" "] eeee10[" "] eeee11[" "]
end
before --"C toevoegen (behoud capaciteit)"--> after1
after1 --"D toevoegen (verdubbel capaciteit)"--> after2
after2 --"E, F, G toevoegen (verdubbel capaciteit)"--> after3
classDef ok fill:#6c6,stroke:#393,color:#fff
class e0,e1 ok
class ee0,ee1,ee2 ok
class eee0,eee1,eee2,eee3 ok
class eeee0,eeee1,eeee2,eeee3,eeee4,eeee5,eeee6 ok
Verdieping
Stel dat we ervoor zouden kiezen om, elke keer wanneer we een element toevoegen, de array één extra plaats te geven.
We moeten dan telkens alle vorige elementen kopiëren, en dat wordt al snel erg inefficiënt.
Bijvoorbeeld, stel dat we met een lege array beginnen:
om het eerste element toe te voegen, moeten we niets kopiëren
om het tweede element toe te voegen, moeten we één element kopiëren (het eerste element uit de vorige array van lengte 1)
om het derde element toe te voegen, moeten we twee elementen kopieëren (het eerste en tweede element uit de vorige array van lengte 2)
om het vierde element toe te voegen 3 kopieën, enzovoort.
Eén voor één \(n\) elementen toevoegen aan een initieel lege lijst zou dus in totaal \(0+1+…+(n-1) = (n^2-n)/2\) kopieën vereisen.
Dat is erg veel werk als \(n\) groot wordt.
Om die reden wordt de lengte van de array niet telkens met 1 verhoogd, maar meteen vermenigvuldigd met een constante (meestal 2, zodat de lengte van de array verdubbelt).
Onthoud
Een ArrayList is de juiste keuze wanneer je een lijst nodig hebt (geordende elementen) en verwacht dat je vaak elementen op een specifieke positie wil opvragen of vervangen, en/of de verwachte aanpassingen voornamelijk het achteraan toevoegen en verwijderen zijn.
LinkedList
Een gelinkte lijst (LinkedList) is een andere implementatie van de List interface.
Hier wordt geen array gebruikt, maar wordt de lijst opgebouwd uit knopen (nodes).
Elke knoop bevat
een waarde (value)
een verwijzing (next) naar de volgende knoop
(in een dubbel gelinkte lijst) een verwijzing (prev) naar de vorige knoop.
De LinkedList zelf bevat enkel een verwijzing naar de eerste knoop (first), en voor een dubbel gelinkte lijst ook nog een verwijzing naar de laatste knoop van de lijst (last).
Vaak wordt ook het aantal elementen (size) bijgehouden.
Hieronder zie je een grafische voorstelling van een dubbel gelinkte lijst met 3 knopen:
block-beta
block:bf
columns 1
space
first
space
end
space
block:n0
columns 1
e0["A"]
p0["next"]
pp0["prev"]
end
space
block:n1
columns 1
e1["B"]
p1["next"]
pp1["prev"]
end
space
block:n2
columns 1
e2["C"]
p2["next"]
pp2["prev"]
end
space
block:bl
columns 1
space
last
space
end
first --> n0
last --> n2
p0 --> n1
p1 --> n2
pp1 --> n0
pp2 --> n1
classDef node fill:#faa,stroke:#f00
classDef ptr fill:#ddd,stroke:black
classDef empty fill:none,stroke:none
classDef val fill:#ffc,stroke:#f90
class bf,bl empty
class n0,n1,n2 node
class pp0,p0,pp1,p1,pp2,p2,first,last ptr
class e0,e1,e2 val
Een LinkedList is efficiënter voor sommige operaties dan een ArrayList, maar trager voor andere.
Meer specifiek: we moeten nooit elementen kopiëren of verplaatsen als we een gelinkte lijst aanpassen, enkel referenties verleggen.
Dat is erg efficiënt.
Maar: we moeten wel eerst op de juiste plaats (knoop) geraken in de lijst, en daarvoor moeten we eerst wel een aantal referenties volgen (beginnend bij first of last), wat voor een lange lijst inefficiënt is.
Onthoud
Een LinkedList is de juiste keuze wanneer je een lijst nodig hebt (geordende elementen) en verwacht dat je veel aanpassingen aan je lijst zal doen, en die aanpassingen vooral voor- of achteraan zullen plaatsvinden.
Lijsten aanmaken
Je kan natuurlijk steeds een lijst aanmaken door een nieuwe, lege lijst te maken en daaraan je elementen toe te voegen:
Hierbij moet je wel opletten dat de lijst die je zo maakt immutable (onveranderbaar) is. Je kan aan de lijst die je zo gemaakt hebt dus later geen wijzigingen meer aanbrengen via add, remove, etc.:
De List-interface zelf bevat al enkele nuttige operaties op lijsten.
In de Collections-klasse (niet hetzelfde als de Collection-interface!) vind je nog een heleboel extra operaties die je kan uitvoeren op lijsten (of soms op collecties), bijvoorbeeld:
disjoint om na te gaan of twee collecties geen overlappende elementen hebben
sort om een lijst te sorteren
shuffle om een lijst willekeurig te permuteren
swap om twee elementen van plaats te verwisselen
frequency om te tellen hoe vaak een element voorkomt in een lijst
min en max om het grootste element in een collectie te zoeken
indexOfSubList om te zoeken of en waar een lijst voorkomt in een langere lijst
nCopies om een lijst te maken die bestaat uit een aantal keer hetzelfde element
fill om alle elementen in een lijst te vervangen door eenzelfde element
rotate om de elementen in een lijst cyclisch te roteren
Unmodifiable list
Soms wil je als resultaat van een methode een gewone (wijzigbare) lijst teruggeven maar er zeker van zijn dat de ontvanger die lijst niet kan aanpassen.
Bijvoorbeeld:
We willen niet dat een gebruiker van de klasse die lijst zomaar kan aanpassen — dat moet via de borrow-methode gaan.
We kunnen natuurlijk een nieuwe lijst teruggeven met een kopie van de elementen:
Er wordt dan geen nieuwe lijst gemaakt, maar wel een ‘view’ op de originele lijst (net zoals we eerder gezien hebben bij reversed en subList).
Het verschil is dat deze view nu geen wijzigingen toelaat; alle operaties die de lijst wijzigen, gooien een UnsupportedOperationException.
Doordenker
Is er, vanuit het standpunt van de code die getBorrowedBooks() oproept, een verschil tussen een kopie en een unmodifiableList()?
Denk bijvoorbeeld aan de situatie waar de lijst borrowedBooks later aangepast wordt (via borrow)?
Antwoord
Ja, er is wel degelijk een verschil.
Bij een kopie zal een nieuw toegevoegd boek niet verschijnen in die kopie.
De lijst gemaakt via unmodifiableList is echter een view: latere aanpassingen zullen ook onmiddellijk zichtbaar zijn.
Set
classDiagram
Iterable <|-- Collection
Collection <|-- List
Collection <|-- Queue
Collection <|-- Set
class Iterable["Iterable#lt;E>"] { <<interface>> }
class Collection["Collection#lt;E>"] { <<interface>> }
class List["List#lt;E>"] { <<interface>> }
class Queue["Queue#lt;E>"] { <<interface>> }
class Set["Set#lt;E>"] {
<<interface>>
}
style Set fill:#cdf,stroke:#99f
Alle collecties die we totnogtoe gezien hebben, kunnen dubbels bevatten.
Bij een Set is dat niet het geval. Het is een abstractie voor een (eindige) wiskundige verzameling: elk element komt hoogstens één keer voor.
In een wiskundige verzameling is ook de volgorde van de elementen niet van belang.
De Set interface legt geen volgorde van elementen vast, maar er bestaan sub-interfaces van Set (bijvoorbeeld SequencedSet en SortedSet) die wél toelaten dat de elementen een bepaalde volgorde hebben.
De Set interface voegt in feite geen nieuwe operaties toe aan de Collection-interface. Je kan elementen toevoegen, verwijderen, en nagaan of een element in de verzameling zit.
Het is leerrijk om even stil te staan bij hoe een set efficiënt geïmplementeerd kan worden.
Immers, verzekeren dat er geen duplicaten inzitten vereist dat we gaan zoeken tussen de huidige elementen, en dat kan makkelijk traag worden als er veel elementen zijn.
We bekijken één implementatie van een manier om dat efficiënt te doen, namelijk een HashSet.
HashSet
Een HashSet kan gebruikt worden om willekeurige objecten in een set bij te houden.
De objecten worden bijgehouden in een hashtable (in essentie een gewone array).
Om te voorkomen dat we een reeds bestaand element een tweede keer toevoegen, moeten we echter snel kunnen nagaan of het toe te voegen element al in de set voorkomt.
Een HashSet kan efficiënt nagaan of een element bestaat, alsook efficiënt een element toevoegen en verwijderen.
De sleutel om dat te doen is de hashCode() methode die ieder object in Java heeft.
Die methode moet, voor elk object, een hashCode (een int) teruggeven, zodanig dat als twee objecten gelijk zijn volgens hun equals-methode, ook hun hashcodes gelijk zijn.
Gewoonlijk zal je, als je equals zelf implementeert, ook hashCode moeten implementeren en omgekeerd.
De hashCode moet niet uniek zijn: meerdere objecten mogen dezelfde hashCode hebben, ook al zijn ze niet gelijk (al kan dat tot een tragere werking van een HashSet leiden; zie verder). Hoe uniformer de hashCode verdeeld is over alle objecten, hoe beter.
Opmerking
Java records, die we later zullen behandelen, voorzien standaard een zinvolle equals- en hashCode-methode die afhangt van de attributen van het record.
Bij records hoef je dus normaliter niet zelf een hashCode-methode te voorzien.
De hashCode wordt gebruikt om een index te bepalen in de onderliggende hashtable (array).
De plaats in die hashtable is een bucket.
Het element wordt opgeslagen in de bucket op die index.
Als we later willen nagaan of een element al voorkomt in de hashtable, berekenen we opnieuw de index aan de hand van de hashCode en kijken we of het element zich effectief in de overeenkomstige bucket bevindt.
Idealiter geeft elk object dus een unieke hashcode, en zorgen die voor perfecte spreiding van alle objecten in de hashtable.
Er zijn echter twee problemen in de praktijk:
twee verschillende objecten kunnen dezelfde hashCode hebben. Dat is een collision. Hiermee moeten we kunnen omgaan.
als er teveel elementen toegevoegd worden, moet de onderliggende hashtable dynamisch kunnen uitbreiden. Dat maakt dat elementen plots op een andere plaats (index) terecht kunnen komen als voorheen. Uitbreiden vraagt vaak rehashing, oftwel het opnieuw berekenen van de index (nu in een grotere hashtable) aan de hand van de hashcodes. De load factor van de hash table geeft aan hoe vol de hashtable mag zijn voor ze uitgebreid wordt. Bijvoorbeeld, een load factor van 0.75 betekent dat het aantal elementen in de hashtable tot 75% van het aantal buckets mag gaan.
Beide problemen zijn al goed onderzocht in de computerwetenschappen, en zullen in het vak Algoritmen en datastructuren uitgebreider aan bod komen.
SortedSet en TreeSet
Naast Set bestaat ook de interface SortedSet.
In een SortedSet worden de elementen steeds in gesorteerde volgorde opgeslagen en teruggegeven.
In tegenstelling tot een Set, kan een SortedSet geen willekeurige objecten bevatten.
De objecten moeten namelijk gesorteerd kunnen worden.
Met andere woorden, we moeten kunnen bepalen welk van twee objecten het grootste is (net zoals > bij getallen).
Dat kan op twee manieren:
de klasse van het op te slagen element kan zelf de Comparable-interface implementeren, die aangeeft welk van twee elementen het grootst is;
of je kan een Comparator-object meegeven bij het maken van een SortedSet, waarop beroep gedaan wordt om de volgorde van twee elementen te bepalen.
De TreeSet klasse is een efficiënte implementatie van SortedSet die gebruik maakt van een gebalanceerde boomstructuur (een red-black tree — de werking daarvan is hier niet van belang).
Voorbeeld
Een voorbeeld van het gebruik van een HashSet:
Set<String>mySet=newHashSet<>();mySet.add("John");mySet.add("Mary");System.out.println(mySet);// => [John, Mary]mySet.add("John");// John zit al in de setSystem.out.println(mySet);//=>[Mary,John]
Merk op dat er geen garanties zijn over de volgorde van de elementen in de set.
Als we dat wel willen, gebruiken we een SortedSet (met TreeSet als implementatie):
SortedSet<String>mySet=newTreeSet<>();mySet.add("John");mySet.add("Mary");for(Stringel:mySet){System.out.println(el);}// gegarandeerd in alfabetische volgorde:// John//Mary
De String-klasse implementeert Comparable om String-objecten alfabetisch te sorteren.
Onthoud
Gebruik een Set als je een collectie zonder dubbels wil voorstellen.
De elementen in een Set hebben geen vaste positie.
Als je gebruik maakt van een SortedSet kan je de elementen wel sorteren (bv. van klein naar groot).
Map (Dictionary)
De collecties hierboven stellen allemaal een groep elementen voor, en erven over van de Collection-interface.
Een Map is iets anders.
Hier worden sleutels bijgehouden, en bij elke sleutel hoort een waarde (een object).
Denk aan een telefoonboek, waar bij elke naam (de sleutel) een telefoonnummer (de waarde) hoort, of een woordenboek waar bij elk woord (de sleutel) een definitie hoort (de waarde).
Een andere naam voor een map is dan ook een dictionary.
Sleutels mogen slechts één keer voorkomen; eenzelfde waarde mag wel onder meerdere sleutels opgeslagen worden.
De interface Map<K, V> heeft niet één, maar twee generische parameters: een (K) voor het type van de sleutels, een een (V) voor het type van de waarden.
Elementen toevoegen aan een Map<K, V> gaat via de put(K key, V value)-methode.
De waarde opvragen kan via de methode V get(K key).
Verder zijn er methodes om na te gaan of een map een bepaalde sleutel of waarde bevat.
Een Map is sterk geoptimaliseerd voor deze operaties.
Er zijn verder ook drie manieren om een Map<K, V> als een Collection te beschouwen:
de keySet: de verzameling van alle sleutels in de Map (een Set<K>)
de values: de collectie van alle waarden in de Map (een Collection<V>, want dubbels zijn mogelijk)
de entrySet: een verzameling (Set<Entry<K, V>>) van alle sleutel-waarde paren (de entries).
HashMap
Net zoals bij Set kunnen we de Map-interface implementeren met een hashtable.
Dat gebeurt in de HashMap klasse.
Entries in een hashmap worden in een niet-gespecifieerde volgorde bijgehouden.
De werking van een hashmap is zeer gelijkaardig aan wat we besproken hebben bij HashSet hierboven.
Meer zelfs, de implementatie van HashSet in Java maakt gebruik van een HashMap.
Het belangrijkste verschil met de HashSet is dat we in een HashMap, naast de waarde, ook de sleutel moeten bewaren.
SortedMap en TreeMap
Een SortedMap is een map waarbij de sleutels (dus niet de waarden) gesorteerd worden bijgehouden (zoals bij een SortedSet). Een concrete implementatie van de SortedMap-interface is een TreeMap.
Voorbeeld
Een voorbeeld van het gebruik van Map als een telefoonbook:
classPersonimplementsComparable<Person>{...}classPhoneNumber{...}Personmary=newPerson("Mary");Personjohn=newPerson("John");Map<Person,PhoneNumber>phoneBook=newHashMap<>();phoneBook.put(john,newPhoneNumber("0470123456"));phoneBook.put(mary,newPhoneNumber("0480999999"));PersonsomePerson=...PhoneNumbernumberOrInfo;if(phoneBook.containsKey(somePerson)){// geeft `null` terug indien persoon niet gevondennumberOrInfo=phoneBook.get(somePerson);}else{numberOrInfo=newPhoneNumber("1207")}
Een Map bevat ook een getOrDefault-methode, waarmee we bovenstaande if-test kunnen vermijden door meteen aan te geven welke waarde teruggegeven moet worden als de sleutel niet in de map zit:
Aangezien we personen alfabetisch kunnen sorteren (Person hierboven implementeert namelijk Comparable), kunnen we ook een SortedMap gebruiken.
Als implementatie gebruiken we dan een TreeMap in plaats van HashMap:
Gebruik een Map om efficiënt een waarde-object op te slaan bij een gekend sleutel-object.
Het verwachte gebruik is dat je aan de hand van de sleutel de waarde opvraagt — niet omgekeerd.
De elementen in een Map hebben geen vaste positie.
Als je gebruik maakt van een SortedMap kan je de elementen wel sorteren (bv. van klein naar groot).
Oefeningen
Setup
Voor deze oefeningen is er al wat code beschikbaar op GitHub om van te vertrekken.
Je kan deze code in IntelliJ makkelijk inladen als project.
Doe daarvoor hetvolgende:
Kies in IntelliJ voor New > Project from Version Control
Zorg dat Git geselecteerd is, en geef als URL volgende URL in:
Na het laden zie je rechtsonder een pop-up Gradle build scripts found. Klik op Load.
Het project wordt nu ingeladen. Wacht tot de voortgangsbalk rechtsonder verdwenen is.
Gradle en unit tests
In dit project wordt reeds Gradle gebruikt als build system.
Dat is nog niet aan bod gekomen in deel 1.
Je hoeft je hier echter niet veel van aan te trekken; je kan de code gewoon uitvoeren met de play-knop zoals voorheen.
Merk wel op dat de broncode en testcode in verschillende folders staan:
alle broncode (de code van je applicatie) staat in src/main/java
alle testcode staat in src/test/java.
Ook testen (met JUnit/AssertJ) is nog niet aan bod gekomen in deel 1. Weet dat je de tests ook gewoon kan uitvoeren via de play-knop.
Oefening 1: Parking
Maak een klasse Parking die gebruikt wordt voor betalend parkeren.
Kies een of meerdere datastructuren om volgende methodes te implementeren:
void enterParking(String licensePlate): een auto (met gegeven nummerplaat) rijdt de parking binnen
double amountToPay(String licensePlate): bereken het te betalen bedrag voor de gegeven auto (nummerplaat). De parking kost 2 euro per begonnen uur.
void pay(String licensePlate): markeer dat de auto met de gegeven nummerplaat betaald heeft
boolean tryLeaveParking(String licensePlate): geef terug of de gegeven auto de parking mag verlaten (betaald heeft), en verwijder de auto uit het systeem indien betaald werd.
history(): geeft de nummerplaten van de auto’s terug die de parking zijn binnengereden, in volgorde van minst naar meest recent (kies zelf een geschikt terugkeertype).
Om te werken met huidige tijd en intervallen tussen twee tijdstippen, kan je gebruik maken van java.time.Instant. Een Instant verwijst naar een bepaald moment, en kan je verkrijgen via de instant()-methode van een Clock-object.
Omdat je Parking-object dus over een klok moet beschikken, voorzie je een constructor Parking(Clock clock) met een Clock-object als parameter.
Test uit hoe belangrijk het is dat de hashcodes van verschillende objecten in een HashSet goed verdeeld zijn aan de hand van de code hieronder.
Deze code meet hoelang het duurt om een HashSet te vullen met 50000 objecten; de eerste keer met goed verspreide hashcodes, en de tweede keer een keer met steeds dezelfde hashcode. Voer uit; merk je een verschil?
importjava.util.HashSet;importjava.util.concurrent.TimeUnit;importjava.util.function.Function;publicclassTiming{recordDefaultHashcode(inti){}recordCustomHashcode(inti){@OverridepublicinthashCode(){return4;// altijd 4!}}publicstaticvoidmain(String[]args){IO.print("With default hashcode: ");test(DefaultHashcode::new);System.gc();IO.print("With identical hashcode: ");test(CustomHashcode::new);}privatestatic<T>voidtest(Function<Integer,T>ctor){varset=newHashSet<T>();varstart=System.nanoTime();// vul de set op met 50000 nieuwe objectenfor(inti=0;i<50_000;i++){set.add(ctor.apply(i));}varend=System.nanoTime();IO.println("%d elements added in %.3f seconds".formatted(set.size(),TimeUnit.NANOSECONDS.toMillis(end-start)/1000.0));}}
Oefening 3: Veranderende hashcode
Is het nodig dat de hashCode van een object hetzelfde blijft doorheen de levensduur van het object, of mag deze veranderen?
Verklaar je antwoord.
Antwoord
Nee, deze mag niet veranderen. Mocht die wel veranderen, kan het zijn dat je een object niet meer terugvindt in een set, omdat er (door de veranderde hashcode) in een andere bucket gezocht wordt dan waar het object zich bevindt.
We willen een klasse IntRange maken waarmee we een gewone for-lus kunnen vervangen door een enhanced for-lus.
Je moet deze klasse als volgt kunnen gebruiken:
Schrijf eerst een klasse IntRangeIterator die Iterator<Integer> implementeert, en alle getallen teruggeeft tussen twee grensgetallen lowest en highest (beiden inclusief) die je meegeeft in de constructor. Je houdt hiervoor enkel de onder- en bovengrens bij, alsook het volgende terug te geven getal.
Schrijf nu ook een klasse IntRange die Iterable<Integer> implementeert, en die een IntRangeIterator-object aanmaakt en teruggeeft.
Notitie
Java laat niet toe om primitieve types als generische parameters te gebruiken.
Voor elk primitief type bestaat er een wrapper-klasse, bijvoorbeeld Integer voor int.
Daarom gebruiken we hierboven bijvoorbeeld Iterator<Integer> in plaats van Iterator<int>.
Achter de schermen worden int-waarden automatisch omgezet in Integer-objecten en omgekeerd.
Dat heet auto-boxing en -unboxing.
Je kan beide types in je code grotendeels door elkaar gebruiken zonder problemen.
Oefening 5: MultiMap
Schrijf een klasse MultiMap<K, V> die een Map voorstelt, maar waar bij elke key een verzameling (Set) van waarden hoort in plaats van slechts één waarde.
Bijvoorbeeld: een MultiMap<Manager, Employee> kan bijhouden voor welke werknemers (meervoud!) een manager verantwoordelijk is.
Maak gebruik een Map in je implementatie.
Hieronder vind je skeletcode die aangeeft welke methodes je moet voorzien, alsook enkele tests.
Leg uit hoe je een HashSet zou kunnen implementeren gebruik makend van een HashMap.
(Dit is ook wat Java (en Python) doen in de praktijk.)
Antwoord
Je gebruikt de elementen die je in de set wil opslaan als sleutel (key), en als waarde (value) neem je een willekeurig object.
Als het element in de HashMap een geassocieerde waarde heeft, zit het in de set; anders niet.
MyArrayList
Schrijf zelf een simpele klasse MyArrayList<E> die werkt zoals de ArrayList uit Java.
Voorzie in je lijst een initiële capaciteit van 4, maar zonder elementen.
Implementeer volgende operaties:
int size() die de grootte (het huidig aantal elementen in de lijst) teruggeeft
int capacity() die de huidige capaciteit (het aantal plaatsen in de array) van de lijst teruggeeft
E get(int index) om het element op positie index op te vragen (of een IndexOutOfBoundsException indien de index ongeldig is)
void add(E element) om een element achteraan toe te voegen (en de onderliggende array dubbel zo groot te maken indien nodig)
void remove(int index) om het element op plaats index te verwijderen (of een IndexOutOfBoundsException indien de index ongeldig is). De capaciteit moet niet terug dalen als er veel elementen verwijderd werden (dat gebeurt in Java ook niet).
E last() om het laatste element terug te krijgen (of een NoSuchElementException indien de lijst leeg is)
Hier vind je een test die een deel van dit gedrag controleert:
Testcode
@Testpublicvoidtest_my_arraylist(){MyArrayList<String>lst=newMyArrayList<>();// initial capacity and sizeassertThat(lst.capacity()).isEqualTo(4);assertThat(lst.size()).isEqualTo(0);// adding elementsfor(inti=0;i<4;i++){lst.add("item"+i);}assertThat(lst.size()).isEqualTo(4);assertThat(lst.capacity()).isEqualTo(4);assertThat(lst.last()).isEqualTo("item3");// adding more elementsfor(inti=4;i<10;i++){lst.add("item"+i);}assertThat(lst.size()).isEqualTo(10);assertThat(lst.capacity()).isEqualTo(16);assertThat(lst.last()).isEqualTo("item9");// remove an elementlst.remove(3);assertThat(lst.size()).isEqualTo(9);assertThat(lst.capacity()).isEqualTo(16);assertThat(lst.get(3)).isEqualTo("item4");assertThatThrownBy(()->lst.get(10)).isInstanceOf(IndexOutOfBoundsException.class);}
MyLinkedList
Schrijf zelf een klasse MyLinkedList<E> om een dubbel gelinkte lijst voor te stellen. Voorzie volgende operaties:
int size() om het aantal elementen terug te geven
void add(E element) om het gegeven element achteraan toe te voegen
E get(int index) om het element op positie index op te vragen
void remove(int index) om het element op positie index te verwijderen
Hieronder vind je enkele tests voor je klasse. Je zal misschien merken dat je implementatie helemaal juist krijgen niet zo eenvoudig is als het op het eerste zicht lijkt, zeker bij de remove-methode.
Gebruik de visuele voorstelling van eerder, en ga na wat je moet doen om elk van de getekende knopen te verwijderen.
De concepten in andere programmeertalen die het dichtst aanleunen bij Java records, pattern matching en sealed interfaces zijn
structs in C en C++ (pattern matching in C++ is nog niet beschikbaar, maar er wordt gewerkt aan dit toe te voegen aan de taal)
@dataclass en structured pattern matching in Python
(sealed) record types en pattern matching in C#
Wat zijn records
In een object-georiënteerd software-ontwerp brengen we data en gedrag samen binnen één klasse.
We gebruiken dan gewoonlijk encapsulatie: we maken de velden van een klasse privaat, zodat ze worden afgeschermd van andere klassen. Op die manier kunnen we de interne representatie (de velden en hun types) makkelijk aanpassen: zolang de publieke methodes (het gedrag) hetzelfde blijven, heeft zo’n aanpassing aan de interne voorstellingswijze geen effect op de rest van het systeem.
Maar soms is encapsulatie niet echt nodig: sommige klassen zijn niet meer dan een bundeling van verschillende waarden, zonder bijhorend complex gedrag.
Welgekende voorbeelden zijn een coordinaat (bestaande uit een x- en y-attribuut), een geldbedrag (een bedrag en een munteenheid), een adres (straat, huisnummer, postcode, gemeente), etc.
Objecten van deze klassen hoeven ook niet aanpasbaar te zijn; je kan makkelijk een nieuw object maken met andere waarden.
Met andere woorden, de identiteit van het object is van ondergeschikt belang.
We noemen dit data-oriented programming: een ontwerpstrategie waar data een first class citizen is, en niet gekoppeld hoeft te worden aan gedrag.
Voor dergelijke klassen heeft doorgedreven encapsulatie weinig zin.
Een record in Java is een eenvoudige klasse die gebruikt kan worden voor data-oriented programming.
Een record-object dient voornamelijk als data-drager, waarbij verschillende objecten met dezelfde attribuut-waarden gewoonlijk volledig inwisselbaar (equivalent) zijn.
De attributen van een record-object mogen daarom niet veranderen doorheen de tijd (het object is dus immutable).
Als voorbeeld definiëren we een coördinaat-klasse als een record, met 2 attributen: een x- en y-coördinaat.
publicrecordCoordinate(doublex,doubley){}
Merk het verschil op met de definitie van een gewone klasse: de attributen van de record staan hier vlak na de klassenaam, en er is geen constructor nodig.
Objecten van een record maak je gewoon aan met new, zoals elk ander object:
wanneer je een type wil definiëren dat overeenkomt met een ander, reeds bestaand datatype, maar met beperkingen.
recordPositiveNumber(intnumber){publicPositiveNumber{if(number<=0)thrownewIllegalArgumentException("Number must be larger than 0");}}
wanneer je een (immutable) datatype wil maken dat zonder probleem door meerdere threads gebruikt kan worden. We gaan in dit vak niet dieper in op het onderwerp Multithreading en concurrency, maar onthoud dat het gebruik van immutable objecten zeer sterk aangeraden wordt in deze context!
Merk op dat bij records in de eerste plaats gaat over het creëren van een nieuw datatype, door (primitievere) data of andere records te bundelen, of beperkingen op te leggen aan mogelijke waarden.
Je maakt dus als het ware een nieuw ‘primitief’ datatype, zoals int, double, of String.
Dit in tegenstelling tot gewone klassen, waar encapsulatie en mogelijkheden om de toestand van een object aan te passen (mutatie-methodes) ook essentieel zijn.
Onthoud
Gebruik een record wanneer je puur data modelleert, zonder bijhorend gedrag dat de toestand van het object kan veranderen.
Gebruik geen record als je een entiteit modelleert waarvan de toestand kan evolueren doorheen de tijd (met andere woorden, wanneer de identiteit van het object belangrijk is).
Achter de schermen
Een record is eigenlijk een gewone klasse, waarbij de Java-compiler zelf enkele zaken voorziet:
een constructor, die de velden initialiseert;
methodes om de attributen op te vragen;
een toString-methode om een leesbare versie van het record uit te printen; en
een equals- en hashCode-methode, die ervoor zorgen dat objecten met dezelfde parameters als gelijk worden beschouwd.
De klasse is ook final, zodat er geen subklassen van gemaakt kunnen worden.
De coördinaat-record van hierboven is equivalent aan volgende klasse-definitie:
Merk wel op dat, omdat de klasse immutable is, je in een methode geen nieuwe waarde kan toekennen aan de velden. Code als
this.x=5;
in een methode van een record is dus ongeldig, en leidt tot een foutmelding van de compiler.
Constructor van een record
Als je geen enkele constructor definieert, krijgt een record een standaard constructor met de opgegeven attributen als parameters (in dezelfde volgorde).
Maar je kan ook zelf een of meerdere constructoren definiëren voor een record, net zoals bij klassen (je krijgt dan geen default-constructor meer).
Je moet in die constructoren zorgen dat alle attributen van het record geïnitialiseerd worden.
publicrecordCoordinate(doublex,doubley){publicCoordinate(doublex,doubley){this.x=x;this.y=y;}publicCoordinate(doublex){// constructor for points on the x-axisthis(x,0);}}
Er is ook een verkorte notatie, waarbij je de parameters niet meer moet herhalen (die staan immers al achter de naam van het record).
Je hoeft met deze notatie ook de parameters niet toe te kennen aan de velden; dat gebeurt automatisch.
Het belangrijkste nut hiervan is om de geldigheid van de waarden te controleren bij het aanmaken van een object:
publicrecordCoordinate(doublex,doubley){publicCoordinate{if(x<0)thrownewIllegalArgumentException("x must be non-negative");if(y<0)thrownewIllegalArgumentException("y must be non-negative");}}
Records en overerving
Zoals eerder al vermeld werd, komt een record overeen met een final klasse.
Je kan er dus niet van overerven.
Een record zelf kan ook geen subklasse zijn van een andere klasse of record, maar kan wel interfaces implementeren.
Immutable
Een record is immutable (onveranderbaar): de attributen krijgen een waarde wanneer het object geconstrueerd wordt, en kunnen daarna nooit meer wijzigen.
Als je een object wil met andere waarden, moet je dus een nieuw object maken.
Bijvoorbeeld, als we een translate methode willen maken voor Coordinate, dan kunnen we de x- en y-coordinaten niet aanpassen.
We moeten een nieuw Coordinate-object maken, en dat teruggeven:
publicrecordCoordinate(doublex,doubley){publicCoordinatetranslate(doubledeltaX,doubledeltaY){// NIET:// this.x += deltaX; <-- kan niet; de x-waarde mag niet meer gewijzigd worden// WEL: een nieuw object makenreturnnewCoordinate(this.x+deltaX,this.y+deltaY);}}
Let op! Als een van de velden van het record een object is dat zelf wél gewijzigd kan worden (bijvoorbeeld een array of ArrayList), dan kan je de data die geassocieerd wordt met het record dus wel nog wijzigen.
Vermijd deze situatie!
Bijvoorbeeld:
Hier zijn twee record-objecten eerst gelijk, maar later niet meer.
Dat schendt het principe dat, voor data-objecten, de identiteit van het object niet zou mogen uitmaken.
De objecten zijn immers niet meer dan de aggregatie van de data die ze bevatten.
Overal waar playlist1 gebruikt wordt, zou ook playlist2 gebruikt moeten kunnen worden en vice versa.
Twee record-objecten die gelijk zijn, moeten altijd gelijk blijven, onafhankelijk van wat er later nog gebeurt.
Gebruik dus bij voorkeur immutable data types in een record.
Pattern matching
Je kan records ook gebruiken in switch statements.
Dit heet pattern matching, en is vooral nuttig wanneer je meerdere record-types hebt die eenzelfde interface implementeren.
Bijvoorbeeld:
Merk op dat je zowel kan matchen op het object als geheel (Square s in het voorbeeld hierboven), individuele argumenten (Circle(double radius) in het voorbeeld), en zelfs geneste patronen (Rectangle(Coordinate(double topLeftX, double topLeftY), Coordinate bottomRight)).
De switch-expressie hierboven is verschillend van het (oudere) switch-statement in Java:
er wordt -> gebruikt in plaats van :
er is geen break nodig op het einde van elke case
de switch-expressie geeft een waarde terug die kan toegekend worden aan een variabele, of gebruikt kan worden in een return-statement (zoals in het voorbeeld hierboven).
Tenslotte is er in een switch-expressie de mogelijkheid om een conditie toe te voegen door middel van een when-clausule:
publicdoublearea(Shapeshape){returnswitch(shape){caseSquares->s.side()*s.side();caseCircle(doubleradius)->Math.PI*radius*radius;caseRectangle(Coordinate(doubletopLeftX,doubletopLeftY),CoordinatebottomRight)whentopLeftX<=bottomRight.x()&&topLeftY<=bottomRight.y()->// <= when-clausule(bottomRight.x()-topLeftX)*(bottomRight.y()-topLeftY);default->thrownewIllegalArgumentException("Unknown or invalid shape");};}
Op die manier kan je extra voorwaarden toevoegen om een case te laten matchen, bovenop het type van het element.
Sealed interfaces
Wanneer je alle klassen kent die een bepaalde interface zullen implementeren (of van een abstracte klasse zullen overerven), kan je van deze interface (of klasse) een sealed interface (of klasse) maken.
Met een permits clausule kan je aangeven welke klassen de interface mogen implementeren:
Indien je geen permits-clausule opgeeft, zijn enkel de klassen die in hetzelfde bestand staan toegestaan.
Omdat elk Java-bestand slechts 1 publieke top-level klasse (of interface/record) mag hebben, zal je vaak ook zien dat de records in de interface-definitie geplaatst worden:
Omdat de compiler kan nagaan wat alle mogelijkheden zijn, kan je bij pattern matching op een sealed klasse in een switch statement ook de default case weglaten:
Omgekeerd zal de compiler je ook waarschuwen wanneer er een geval ontbreekt.
publicdoublearea(Shapeshape){returnswitch(shape){caseSquares->s.side()*s.side();caseCircle(doubleradius)->Math.PI*radius*radius;// <= compiler error: ontbrekende case voor 'Rectangle'};}
Geef enkele voorbeelden van types die volgens jou best als record gecodeerd worden, en ook enkele types die best als klasse gecodeerd worden.
Kan je, voor een van je voorbeelden, een situatie bedenken waarin je van record naar klasse zou gaan, en omgekeerd?
Antwoord
Records zijn vooral geschikt voor het bijhouden van stateless informatie (objecten zonder gedrag).
Bijvoorbeeld: Money, ISBN, BookInfo, ProductDetails, …
Klassen zijn geschikt als de identiteit van het object van belang is en constant blijft, maar de state (data) doorheen de tijd kan wijzigen.
Bijvoorbeeld: BankAccount, ShoppingCart, GameCharacter, OrderProcessor, …
Overgaan van de ene naar de andere vorm kan wanneer er gedrag toegevoegd of verwijderd wordt.
Bijvoorbeeld, BookInfo zou een klasse kunnen worden indien we er (in de context van een bibliotheek) ook informatie over ontleningen in willen bijhouden. Omgekeerd kan BankAccount van klasse naar object gaan indien het enkel een voorstelling wordt van rekeninginformatie (rekeningnummer en naam van de houder bijvoorbeeld), en de balans en transacties naar een ander object (bv. TransactionHistory) verplaatst worden.
Sealed interface
Kan je een voorbeeld bedenken van een nuttig gebruik van een sealed interface?
Antwoord
Sealed interfaces zijn vooral nuttig om een uitgebreidere vorm van enum’s te maken, waar elke optie ook extra informatie met zich kan meedragen.
Bijvoorbeeld:
sealed interface PaymentMethod om een manier van betalen voor te stellen, met subtypes (records) CreditCard(cardName, cardNumber, expirationDate), PayPal(email), BankTransfer(iban), …
sealed interface Command wat een commando voorstelt dat uitgevoerd kan worden, met subtypes (records) CreateUser(name, email), DeleteUser(uuid), UpdateUser(uuid, newEmail), …
Email
Definieer een Email-record dat een geldig e-mailadres voorstelt.
Het mail-adres wordt voorgesteld door een String.
Controleer de geldigheid van de String bij het aanmaken van een Email-object:
de String mag niet null zijn (anders NullPointerException)
de String moet exact één @-teken bevatten (anders IllegalArgumentException)
de String moet eindigen op “.com” of “.be” (anders IllegalArgumentException)
Schrijf een record die een rechthoek voorstelt.
Een rechthoek wordt gedefinieerd door 2 punten (linksboven en rechtsonder).
Gebruik een Coordinaat-record om deze hoekpunten voor te stellen.
Zorg ervoor dat enkel geldige rechthoeken aangemaakt kunnen worden (dus: het hoekpunt linksboven ligt zowel links als boven het hoekpunt rechtsonder).
Voeg extra methodes toe:
om de twee andere hoekpunten (linksonder en rechtsboven) op te vragen
om na te gaan of een gegeven punt zich binnen de rechthoek bevindt
om na te gaan of een rechthoek overlapt met een andere rechthoek. (Hint: bij twee overlappende rechthoeken ligt minstens één hoekpunt van de ene rechthoek binnen de andere)
Expressie-hierarchie
Maak een set van records om een wiskundige uitdrukking voor te stellen.
Alle records moeten een sealed interface Expression implementeren.
De mogelijke expressies zijn:
een Literal: een constante getal-waarde (een double)
een Variable: een naam (een String), bijvoorbeeld “x”
een Sum: bevat twee expressies, een linker en een rechter
een Product: gelijkaardig aan Som, maar stelt een product voor
een Power: een expressie tot een constante macht
De veelterm \( 3x^2+5 \) kan dus voorgesteld worden als:
Gebruik pattern matching (en TDD) voor elk van volgende opdrachten:
de methode evaluate moet de gegeven expressie evalueren voor de gegeven waarden van de variabelen. Bijvoorbeeld, \( 3x^2+5 \) evalueren met \( x=7 \) geeft \(152\). De parameter variableValues bevat een mapping van variabelen naar hun toegekende waarde.
Schrijf de methode prettyPrint die de gegeven expressie omzet in een String, bijvoorbeeld prettyPrint(poly) geeft (3.0) * ((x)^2.0) + 5.0.
Maak je op dit moment nog geen zorgen over onnodige haakjes.
Hint: voor het pretty-printen van een som, pretty-print je eerst de linker- en rechterterm afzonderlijk.
Zorg er nu voor dat er geen onnodige haakjes verschijnen in het resultaat van prettyPrint, door rekening te houden met de volgorde van de bewerkingen. (Hint: geef elke expressie een numerieke prioriteit)
(uitdagend) De methode simplify moet de gegeven expressie te vereenvoudigen door enkele vereenvoudigingsregels toe te passen. Bijvoorbeeld, het vervangen van \(3 + 7\) door \(10\), vervangen van \(x+0\), \(x*1\), en \(x^1\) door \(x\); vervangen van \(x * 0\) door \(0\), …
(uitdagend) de methode differentiate moet de afgeleide berekenen van de gegeven expressie in de gegeven variabele (bv. \( \frac{d}{dx} 3x^2+5x = 6x+5 \)).
Geef het resultaat zo eenvoudig mogelijk terug (Hint: gebruik simplify).
Denkvraag
Wat is het voor- en nadeel van het gebruik van pattern matching tegenover het gebruik van overerving en dynamische binding?
Met andere woorden, wat is het verschil met bijvoorbeeld de methodes simplify(), evaluate(), … in de interface Expression zelf te definiëren, en ze te implementeren in elke subklasse?
Extra oefeningen
Money
Maak een Money-record dat een geldbedrag (bijvoorbeeld 20) en een munteenheid (bijvoorbeeld “EUR”) bevat.
Voeg ook methodes toe om twee geldbedragen op te tellen. Dit mag enkel wanneer de munteenheid van beiden gelijk is; zoniet moet er een exception gegooid worden.
Interval
Maak een Interval-record dat een periode tussen twee tijdstippen voorstelt, bijvoorbeeld voor een vergadering. Elk tijdstip wordt voorgesteld door een niet-negatieve long-waarde.
Het eind-tijdstip mag niet voor het start-tijdstip liggen.
Voeg een methode toe om na te kijken of een interval overlapt met een ander interval.
Intervallen worden beschouwd als half-open: twee aansluitende intervallen overlappen niet, bijvoorbeeld [15, 16) en [16, 17).
Programmeertaal
Breid de expressies uit de oefening hierboven uit tot je eigen mini-programmeertaal met interpreter.
Voorzie daarvoor een sealed interface Statement met volgende klassen en betekenis:
Assign(name, expr): evalueer expr en sla het resultaat op in de variabele name
Print(expr): evalueer expr en print de waarde uit
If(cond, thenBranch, elseBranch): evalueer expressie cond; indien dit 0 is, voer statement thenBranch uit, anders statement elseBranch
While(cond, body): voer statement body uit zolang expressie cond naar 0 evalueert
Sequence(stmts): voer een lijst van statements stmts (een ‘blok’) na elkaar uit
Voeg dan een klasse Interpreter toe met een methode execute(Statement st) die het meegegeven statement (programma) uitvoert.
In je Interpreter maak je best gebruik van een klasse die de huidige toestand van het programma bijhoudt, met onderstaande interface:
/*
x := 5
while x != 0:
print x
x := x - 1
*/varxvar=newVariable("x");varprogram=newSequence(List.of(newAssign(xvar,newLiteral(5)),newWhile(xvar,newSequence(List.of(newPrint(xvar),newAssign(xvar,newSum(xvar,newLiteral(-1))))))));newInterpreter().execute(program);// 5.0// 4.0// 3.0// 2.0//1.0
7.4 Generics
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java generics zijn
templates in C++
generic types in Python (in de vorm van type hints)
generics in C#
In dit hoofdstuk behandelen we generics. Die worden veelvuldig gebruikt in datastructuren, en een goed begrip ervan is dan ook essentieel.
Generics zijn een manier om klassen en methodes te voorzien van type-parameters.
Bijvoorbeeld, neem de volgende klasse ArrayList1:
Stel dat we deze klasse makkelijk willen kunnen herbruiken, telkens met een ander type van elementen in de lijst.
We kunnen nu nog niet zeggen wat het type wordt van die elementen.
Gaan er Student-objecten in de lijst terechtkomen? Of Animal-objecten?
Dat weten we nog niet.
We daarom voor Object (het meest algemene type in Java) als type van elements, element, en het resultaat van get.
Maar dat betekent ook dat je nu objecten van verschillende, niet-gerelateerde types kan opnemen in één en dezelfde lijst, hoewel dat niet de bedoeling is!
Stel bijvoorbeeld dat je een lijst van studenten wil bijhouden, dan houdt de compiler je niet tegen om ook andere types van objecten toe te voegen:
ArrayListstudents=newArrayList();Studentstudent=newStudent();students.add(student);Animalanimal=newAnimal();students.add(animal);// <-- compiler vindt dit OK 🙁
Om dat tegen te gaan, zou je afzonderlijke klassen ArrayListOfStudents, ArrayListOfAnimals, … kunnen maken, waar het bedoelde type van elementen wel duidelijk is, en ook wordt afgedwongen door de compiler.
Bijvoorbeeld:
De prijs die we hiervoor betalen is echter dat we nu veel quasi-identieke implementaties moeten maken, die enkel verschillen in het type van hun elementen.
Dat leidt tot veel onnodige en ongewenste code-duplicatie.
Met generics kan je een type gebruiken als parameter voor een klasse (of methode, zie later) om code-duplicatie zoals hierboven te vermijden.
Dat ziet er dan als volgt uit (we gaan zodadelijk verder in op de details):
classArrayList<T>{privateT[]elements;// ...}
Generics geven je dus een combinatie van de beste eigenschappen van de twee opties die we overwogen hebben:
er moet slechts één implementatie gemaakt worden (zoals bij ArrayList hierboven), en
deze implementatie kan gebruikt worden om lijsten te maken waarbij het gegarandeerd is dat alle elementen een specifiek type hebben (zoals bij ArrayListOfStudents).
In de volgende secties bekijken we generics in meer detail.
Deze klasse is geïnspireerd op de ArrayList-klasse die standaard in Java zit. ↩︎
Subsecties van 7.4 Generics
7.4.1 Definiëren en gebruiken
Om generics te gebruiken moet je altijd een generische parameter (meestal aangegeven met een enkele letter) toevoegen, zoals de generische parameter T bij ArrayList<T>.
In het algemeen zijn er slechts twee plaatsen in je code waar je een nieuwe generische parameter mag introduceren:
Bij de definitie van een klasse (of interface, record, …)
Bij de definitie van een methode (of constructor)
We kijken eerst naar generische klassen.
Een generische klasse definiëren
Om een generische klasse te definiëren, zet je de type-parameter tussen < en > achter de naam van de klasse die je definieert.
Vervolgens kan je die parameter (bijna1) overal in die klasse gebruiken als type:
classMyGenericClass<E>{// je kan hier (bijna) overal E gebruiken als type}
Bijvoorbeeld, volgende klasse is een nieuwe versie van de ArrayList-klasse van eerder, maar nu met type-parameter E (waar E staat voor ‘het type van de elementen’).
Deze E wordt vervolgens gebruikt als type voor de elements-array, de parameter van de add-method, en het resultaat-type van de get-method:
Je zal heel vaak zien dat generische type-parameters slechts bestaan uit 1 letter (populaire letters zijn bijvoorbeeld E, R, T, U, V). Dat is geen vereiste: onderstaande code mag ook, en is volledig equivalent aan die van hierboven.
De reden waarom vaak met individuele letters gewerkt wordt, is om duidelijk te maken dat het over een type-parameter gaat, en niet over een bestaande klasse.
Naast klassen kan je ook records en interfaces voorzien van een generische parameter.
Weetje
Je kan een generische klasse ook zien als een functie (soms een type constructor genoemd).
Die functie geeft geen object terug op basis van een of meerdere parameters zoals je dat gewoon bent van functies, bijvoorbeeld getPet : (Person p) → Animal, maar geeft een nieuw type (een nieuwe klasse) terug, gebaseerd op de type-parameters.
Bijvoorbeeld, de generische klasse ArrayList<T> kan je beschouwen als een functie ArrayList : (Type T) → Type, die het type ArrayListOfStudents of ArrayListOfAnimals teruggeeft wanneer je ze oproept met respectievelijk T=Student of T=Animal.
In plaats van ArrayListOfStudents schrijven we dat type als ArrayList<Student>.
Een generische klasse gebruiken
Bij het gebruik van een generische klasse (bijvoorbeeld ArrayList<E> van hierboven) moet je een concreet type opgeven voor de type-parameter (E).
Bijvoorbeeld, op plaatsen waar je een lijst met enkel studenten verwacht, gebruik je ArrayList<Student> als type.
Je kan dan de klasse gebruiken op dezelfde manier als de ArrayListOfStudents klasse van hierboven:
ArrayList<Student>students=newArrayList<Student>();StudentsomeStudent=newStudent();students.add(someStudent);// <-- OK 👍// students.add(animal); // <-- niet toegelaten (compiler error) 👍StudentfirstStudent=students.get(0);//<--OK👍
Merk op hoe de compiler afdwingt en garandeert dat er enkel Student-objecten in deze lijst terecht kunnen komen.
Om wat typwerk te besparen, laat Java in veel gevallen ook toe om het type weg te laten bij het instantiëren, met behulp van <>.
Dat type kan immers automatisch afgeleid worden van het type van de variabele:
Een type-parameter <E> zoals we die tot nu toe gezien hebben kan om het even welk type voorstellen.
Soms willen we dat niet, en willen we beperkingen opleggen.
Stel bijvoorbeeld dat we volgende klasse-hierarchie hebben:
De Food-klasse is enkel bedoeld om met Animal (en de subklassen van Animal) gebruikt te worden, bijvoorbeeld Food<Cat> en Food<Dog>.
Maar niets houdt ons op dit moment tegen om ook een Food<Student of een Food<String> te maken.
Daarenboven zal de compiler (terecht) ook een compilatiefout geven in de methode giveTo van Food: er wordt een Animal-specifieke methode opgeroepen (namelijk showLike) op de parameter animal, maar die heeft type A en dat kan eender wat zijn, bijvoorbeeld ook String.
En String biedt natuurlijk geen methode showLike() aan.
We kunnen daarom aangeven dat type A een subtype moet zijn van Animal door bij de definitie van de generische parameter <A extends Animal> te schrijven.
Je zal dan niet langer Food<String> mogen schrijven, aangezien String geen subklasse is van Animal.
We begrenzen dus de mogelijke types die gebruikt kunnen worden voor de type-parameter A tot alle types die overerven van Animal (inclusief Animal zelf).
classFood<AextendsAnimal>{publicvoidgiveTo(Aanimal){/* ... */animal.showLike();// <= OK! 👍}}Food<Cat>catFood=newFood<>();// nog steeds OKFood<String>stringFood=newFood<>();//<--compilererror👍
Notitie
Wanneer je deze materie later opnieuw doorneemt, heb je naast extends ook al gehoord van super en wildcards (?) — dit wordt later besproken.
Het is belangrijk om op te merken dat je super en ?nooit kan gebruiken bij de definitie van een nieuwe generische parameter (de Java compiler laat dit niet toe).
Dat kan enkel op de plaatsen waar je een generische klasse of methode gebruikt.
Onthoud dus: op de plaatsen waar je een nieuwe parameter (een nieuwe ’letter’) introduceert, kan je enkel aangeven dat die een subtype van iets moet zijn met behulp van extends.
Een generische methode definiëren en gebruiken
In de voorbeelden hierboven hebben we steeds een hele klasse generisch gemaakt.
Naast een generische klasse is er ook een tweede manier om een generische parameter te definiëren, namelijk eentje die enkel in één methode gebruikt kan worden.
Dat doe je door de parameter te declareren vóór het terugkeertype van die methode, opnieuw tussen < en >.
Dat kan ook in een klasse die zelf geen type-parameters heeft.
Je kan die parameter dan gebruiken in de methode zelf, en ook in de types van de parameters en het terugkeertype (dus overal na de definitie ervan).
Bijvoorbeeld, onderstaande methodes doSomething en doSomethingElse hebben beiden een generische parameter T.
Die parameter hoort enkel bij elke individuele methode; beide generische types staan dus volledig los van elkaar.
Ook NormalClass is geen generische klasse; enkel de twee methodes zijn generisch.
classNormalClass{public<T>intdoSomething(ArrayList<T>elements){// je kan overal in deze methode type T gebruiken}publicstatic<T>ArrayList<T>doSomethingElse(ArrayList<T>elements,Telement){// deze T is onafhankelijk van die in doSomething}}
Het is trouwens ook mogelijk om generische klassen en generische methodes te combineren:
classFoo<T>{public<U>ArrayList<U>doSomething(ArrayList<T>ts,ArrayList<U>us){// code met T en U}}
Deze methode-definitie maakt zowel gebruik van de generische parameter T (beschikbaar in de hele klasse Foo) als de parameter U (enkel beschikbaar in de methode doSomething).
Type inference
Bij het gebruik van een generische methode zal de Java-compiler zelf proberen om de juiste types te vinden; dit heet type inference. Je kan de methode meestal gewoon oproepen zoals elke andere methode, en hoeft dus (in tegenstelling tot bij klassen) niet zelf aan te geven hoe de generische parameters geïnstantieerd worden.
In de uitzonderlijke gevallen waar type inference faalt, of wanneer je het type van de generische parameter expliciet wil maken, kan je die zelf opgeven als volgt:
Merk op hoe we, tussen het . en de naam van de methode, de generische parameter <Dog> toevoegen.
Voorbeeld
Als voorbeeld definiëren we (in een niet-generische klasse AnimalHelper) een generische (statische) methode findHappyAnimals.
Deze heeft 1 generische parameter T, en we leggen meteen ook op dat dat een subtype van Animal moet zijn (<T extends Animal>).
Merk op dat we het type T zowel gebruiken bij de animals-parameter als bij het terugkeertype van de methode.
Zo kunnen we garanderen dat de teruggegeven lijst precies hetzelfde type elementen heeft als de lijst animals, zonder dat we al moeten vastleggen welk type dier (bv. Cat of Dog) dat precies is.
Dus: als we een ArrayList<Cat> meegeven aan de methode, krijgen we ook een ArrayList<Cat> terug.
Op dezelfde manier kan je ook het type van meerdere parameters (en eventueel het terugkeertype) aan elkaar vastkoppelen.
In het voorbeeld hieronder zie je een methode die paren kan maken tussen dieren; de methode kan gebruikt worden voor elk type dier, maar kan enkel paren maken van dezelfde diersoort.
Je ziet meteen ook een voorbeeld van een generisch record-type AnimalPair.
classAnimalHelper{// voorbeeld van een generisch recordpublicrecordAnimalPair<TextendsAnimal>(Tmale,Tfemale){}publicstatic<TextendsAnimal>ArrayList<AnimalPair<T>>makePairs(ArrayList<T>males,ArrayList<T>females){/* ... */}}ArrayList<Cat>maleCats=...ArrayList<Cat>femaleCats=...ArrayList<Dog>femaleDogs=...ArrayList<AnimalPair<Cat>>pairedCats=makePairs(maleCats,femaleCats);// OKArrayList<AnimalPair<Animal>>pairedMix=makePairs(maleCats,femaleDogs);//nietOK(compilererror)👍
Merk hierboven op hoe, door de parameter T op verschillende plaatsen te gebruiken in de methode, deze methode enkel gebruikt kan worden om twee lijsten met dezelfde diersoorten te koppelen, en er meteen ook gegarandeerd wordt dat de AnimalPair-objecten die teruggegeven worden ook hetzelfde type dier bevatten.
Als het type T niet van belang is omdat het nergens terugkomt (niet in het terugkeertype van de methode, niet bij een andere parameter, en ook niet in de body van de methode), dan heb je strikt gezien geen generische methode nodig.
Zoals we later bij het gebruik van wildcards zullen zien, kan je dan ook gewoon het wildcard-type <? extends X> gebruiken, of <?> indien het type niet begrensd moet worden.
In plaats van
publicstatic<TextendsAnimal>voidfeedAll(ArrayList<T>animals){// code die T nergens vermeldt}
kan je dus ook de generische parameter T weglaten, en hetvolgende schrijven:
Dit is nu geen generische methode meer (er wordt geen nieuwe generische parameter geïntroduceerd); de parameter animals maakt wel gebruik van een generisch type.
Je leest deze methode-signatuur als ‘de methode feedAll neemt als parameter een lijst met elementen van een willekeurig (niet nader bepaald) subtype van Animal’.
Onthoud
Er zijn slechts 2 plaatsen waar je een nieuwe generische parameter (een ’letter’ zoals T of U) mag introduceren:
vlak na de naam van een klasse (of record, interface, …) die je definieert (class Foo<T> { ... }); of
vlak vóór het terugkeertype van een methode (public <T> void doSomething(...) { }).
Op alle andere plaatsen waar je naar een generische parameter verwijst (door de letter te gebruiken), moet je ervoor zorgen dat deze eerst gedefinieerd werd op één van deze twee plaatsen.
Meerdere type-parameters
De ArrayList<E>-klasse hierboven had één generische parameter (E).
Een generische klasse of methode kan ook meerdere type-parameters hebben, bijvoorbeeld een tuple van 3 elementen van mogelijk verschillend type (we maken hier een record in plaats van een klasse):
Bij het gebruik van deze klasse (bijvoorbeeld bij het aanmaken van een nieuw object) moet je dan voor elke parameter (T1, T2, en T3) een concreet type opgeven:
Ook hier kan je met de verkorte notatie <> werken om jezelf niet te moeten herhalen.
Notitie
Het lijkt erg handig om zo’n Tuple-type overal in je code te gebruiken waar je drie objecten samen wil bundelen, maar dat wordt afgeraden.
Niet omdat het drie generische parameters heeft (dat is perfect legitiem), maar wel omdat het niets zegt over de betekenis van de velden (wat zit er in ‘first’, ‘second’, ’third’?).
Gebruik in plaats van een algemene Tuple-klasse veel liever een record waar je de individuele componenten een zinvolle naam geeft.
Bijvoorbeeld: record Enrollment(String student, int year, String courseId) {} of record Point3D(double x, double y, double x) {}.
De generische parameter kan niet gebruikt worden in de statische velden, methodes, inner classes, … van de klasse. ↩︎
7.4.2 Generics en subtyping
Stel we hebben klassen Animal, Mammal, Cat, Dog, en Bird met volgende overervingsrelatie:
Een van de basisregels van object-georiënteerd programmeren is dat overal waar een object van type X verwacht wordt, ook een object van een subtype van X toegelaten wordt.
De Java compiler respecteert deze regel uiteraard.
Volgende toekenningen zijn bijvoorbeeld toegelaten:
maar mammal = new Bird(); is bijvoorbeeld niet toegelaten, want Bird is geen subtype van Mammal.
In onderstaande code is de eerste oproep toegelaten (cat heeft type Cat, en dat is een subtype van Mammal), maar de tweede niet (cat is geen Dog) en de derde ook niet (Cat is geen subtype van Bird):
staticvoidpet(Mammalmammal){/* ... */}staticvoidbark(Dogdog){/* ... */}staticvoidlayEgg(Birdbird){/* ... */}Catcat=newCat();pet(cat);// <- toegelaten (voldoet aan principe)bark(cat);// <- niet toegelaten (compiler error) 👍layEgg(cat);//<-niettoegelaten(compilererror)👍
Subtyping en generische lijsten
Een lijst in Java is een geordende groep van elementen van hetzelfde type.
List<E> is de interface1 die aan de basis ligt van alle lijsten.
ArrayList<E> is een klasse die een lijst implementeert met behulp van een array.
ArrayList<E> is een subtype van List<E>; dus overal waar een List-object verwacht wordt, mag ook een ArrayList gebruikt worden.
In het hoofdstuk rond Collections zagen we ook dat er een interface Collection<E> bestaat, wat een willekeurige groep van elementen voorstelt: niet enkel een lijst, maar bijvoorbeeld ook verzamelingen (Set) of wachtrijen (Queue).
List<E> is een subtype van Collection<E>. Bijgevolg (via transitiviteit) is ArrayList<E> dus ook subtype van Collection<E>.
Het lijkt intuïtief misschien logisch dat ArrayList<Cat> ook een subtype moet zijn van ArrayList<Animal>.
Een lijst van katten lijkt tenslotte toch een speciaal geval te zijn van een lijst van dieren?
Maar dat is niet het geval.
Waarom niet?
Stel dat ArrayList<Cat> toch een subtype zou zijn van ArrayList<Animal>. Dan zou volgende code ook geldig zijn:
ArrayList<Cat>cats=newArrayList<Cat>();ArrayList<Animal>animals=cats;// <- dit zou geldig zijn (maar is het niet!)Dogdog=newDog();animals.add(dog);//<-OOPS:erzitnueenhondindelijstvankatten🙁
Je zou dus honden kunnen toevoegen aan je lijst van katten zonder dat de compiler je waarschuwt, en dat is niet gewenst.
Om die reden beschouwt Java ArrayList<Cat> dus niet als subtype van ArrayList<Animal>, ondanks dat Cat wél een subtype van Animal is.
Onthoud
Zelfs als klasse Sub een subtype is van klasse Super, dan is ArrayList<Sub> toch geen subtype van ArrayList<Super>.
Later zullen we zien hoe we hier met wildcards in sommige gevallen wel flexibeler mee kunnen omgaan.
Overerven van een generisch type
Hierboven gebruikten we vooral ArrayList als voorbeeld van een generische klasse.
We hebben echter ook gezien dat je zelf generische klassen kan definiëren, en daarvan kan je uiteraard ook overerven.
Bij de definitie van een subklasse moet je voor de generische parameter van de superklasse een waarde (type) meegeven. Je kan ervoor kiezen om je subklasse zelf generisch te maken (door opnieuw een generische parameter te introduceren), of om een vooraf bepaald type mee te geven.
Bijvoorbeeld:
De superklasse Super heeft een generische parameter T.
De subklasse SubForAnimal definieert zelf een generische parameter A (hier met begrenzing), en gebruikt parameter A als type voor T uit de superklasse.
De klasse SubForCat tenslotte definieert zelf geen nieuwe generische parameter, maar geeft het type Cat op als type voor parameter A uit diens superklasse.
Een interface kan je zien als een abstracte klasse waarvan alle methodes abstract zijn. Het defineert alle methodes die geïmplementeerd moeten worden, maar bevat zelf geen implementatie. ↩︎
7.4.3 Wildcards
We zagen eerder dat de types List<Dog> en List<Animal> niets met elkaar te maken hebben, ondanks het feit dat Dog een subtype is van Animal.
Dat geldt in het algemeen voor generische types.
Als beide generische parameters hetzelfde type hebben, bestaat er wel een overervingsrelatie. Bijvoorbeeld, in volgende situatie:
is AnimalShelter<Dog> wel degelijk een subtype van Shelter<Dog>, om dezelfde reden dat ArrayList<Dog> een subtype is van List<Dog>.
Volgende toekenning en methode-oproep zijn dus toegelaten:
Dat komt omdat AnimalShelter een subtype is van Shelter, en de generische parameter bij beiden hetzelfde is (Dog).
Als de generische parameters verschillend zijn, is er echter geen overervingsrelatie.
Bijvoorveeld, tussen AnimalShelter<Cat> en Shelter<Animal> is er geen overervingsrelatie.
Ook is Shelter<Cat> geen subtype van Shelter<Animal>.
Het volgende is bijgevolg niet toegelaten:
Shelter<Animal>s=newAnimalShelter<Cat>();// NIET toegelatenpublicvoidprotectAnimal(Shelter<Animal>s){...}AnimalShelter<Cat>animalShelter=newAnimalShelter<Cat>();// wel OK!protectAnimal(animalShelter);//NIETtoegelaten
Onthoud
In het algemeen: als class Sub<T> extends Super<T>, dan is Sub<SomeClass> is een subklasse van Super<SomeClass>, maar niet van Super<OtherClass>, zélfs niet als SomeClass een subtype is van OtherClass.
In sommige situaties willen we wel zo’n overervingsrelatie kunnen maken.
We bekijken daarvoor twee soorten relaties, namelijk covariantie en contravariantie.
Notitie
Opgelet: Zowel covariantie als contravariantie gaan enkel over het gebruik van generische klassen.
Meer bepaald beïnvloeden ze wanneer twee generische klassen door de compiler als subtype van elkaar beschouwd worden, wat van belang is voor toekenningen en parameters bij methode-oproepen.
Dat staat los van de definitie van een generische klasse — die definities (en bijhorende begrenzing) blijven onveranderd!
Covariantie (extends)
Wat als we een methode copyFromTo willen schrijven die de dieren uit een gegeven (bron-)lijst toevoegt aan een andere (doel-)lijst van dieren? Bijvoorbeeld:
publicstaticvoidcopyFromTo(ArrayList<Animal>source,ArrayList<Animal>target){for(Animala:source){target.add(a);}}ArrayList<Animal>animals=newArrayList<>();ArrayList<Cat>cats=/* ... */ArrayList<Dog>dogs=/* ... *//* ... */copyFromTo(dogs,animals);// niet toegelaten 🙁copyFromTo(cats,animals);//niettoegelaten🙁
Volgens de regels die we hierboven gezien hebben, kunnen we deze methode niet gebruiken om de dieren uit een lijst van honden (ArrayList<Dog>) of katten (ArrayList<Cat>) te kopiëren naar een lijst van dieren (ArrayList<Animal>).
Maar dat lijkt wel een zinvolle operatie.
Een oplossing kan zijn om verschillende versies van de methode te schrijven:
Merk op dat de oproep target.add(cat), alsook die met dog en bird, toegelaten is, omdat Cat, Dog en Bird subtypes zijn van Animal.
Maar dan lopen we opnieuw tegen het probleem van gedupliceerde code aan.
Een eerste oplossing daarvoor is een generische methode, met een generische parameter die begrensd is (T extends Animal):
Dat werkt, maar de generische parameter T wordt slechts eenmaal gebruikt, namelijk bij de parameter ArrayList<T> source.
In zo’n situatie kunnen we ook gebruik maken van het wildcard-type <? extends X>.
We kunnen bovenstaande methode dus ook zonder generische parameter <T> schrijven als volgt:
Het type ArrayList<? extends Animal> staat dus voor “elke ArrayList waar het element-type een (niet nader bepaald) subtype is van Animal”.
Je kan dit ook bekijken alsof het type ArrayList<? extends Animal> staat voor de hele verzameling van types ArrayList<Animal>, ArrayList<Mammal>, ArrayList<Cat>, ArrayList<Dog>, alsook elke andere lijst van dieren.
Dit heet covariantie: omdat Cat een subtype is van Animal, is ArrayList<Cat> een subtype van ArrayList<? extends Animal>.
De ‘co’ in covariantie wijst erop dat de overervingsrelatie tussen Cat en Animal in dezelfde richting loopt als die tussen ArrayList<Cat> en ArrayList<? extends Animal> (in tegenstelling tot contravariantie, wat zodadelijk aan bod komt).
Dat zie je op de afbeelding hieronder:
Tenslotte kan je in Java ook <?> schrijven (bijvoorbeeld ArrayList<?>); dat is een verkorte notatie voor ArrayList<? extends Object>. Je interpreteert ArrayList<?> dus als een lijst van een willekeurig maar niet gekend type. Merk op dat ArrayList<?> dus niet hetzelfde is als ArrayList<Object>. Een ArrayList<Cat> is een subtype van ArrayList<?>, maar niet van ArrayList<Object>.
Hou er ook rekening mee dat elk voorkomen van ? voor een ander type staat (of kan staan). Hetvolgende kan dus niet:
omdat de eerste ArrayList<? extends Mammal> (source) bijvoorbeeld een ArrayList<Cat> kan zijn, en de tweede (target) een ArrayList<Dog>. Als je de types van beide parameters wil linken aan elkaar, moet je een generische methode gebruiken (zoals we eerder gezien hebben):
De lijst-variabele is gedeclareerd als een ArrayList met elementen van een ongekend type. Op basis van het type van de variabele kan de compiler niet afleiden dat er Strings toegevoegd mogen worden aan de lijst (het zou evengoed een ArrayList van Animals kunnen zijn).
Het feit dat lijst onmiddellijk geinititialiseerd werd met een ArrayList<String> doet hier niet terzake; enkel het type bij de declaratie van lijst is van belang.
Onthoud
Het type ArrayList<? extends Mammal> staat voor de verzameling van types ArrayList<Mammal>, ArrayList<Cat>, ArrayList<Dog>, en elk ander type dat overerft van Mammal.
Contravariantie (super)
Wat als we een methode willen die de objecten uit een gegeven bronlijst van katten kopieert naar een doellijst van willekeurige dieren? Bijvoorbeeld:
publicstaticvoidcopyFromCatsTo(ArrayList<Cat>source,ArrayList<Animal>target){for(Catcat:source){target.add(cat);}}ArrayList<Cat>cats=/* ... */ArrayList<Cat>otherCats=newArrayList<>();ArrayList<Mammal>mammals=newArrayList<>();ArrayList<Animal>animals=newArrayList<>();copyFromTo(cats,otherCats);// niet toegelaten 🙁copyFromTo(cats,mammals);// niet toegelaten 🙁copyFromTo(cats,animals);//OK👍
De eerste twee copyFromTo-regels zijn niet toegelaten, maar zouden opnieuw erg nuttig kunnen zijn.
Co-variantie met extends helpt ook niet (target zou dan immers ook een ArrayList<Dog> kunnen zijn):
publicstaticvoidcopyFromCatsTo(ArrayList<Cat>source,ArrayList<?extendsAnimal>target){for(Catcat:source){target.add(cat);}// ook niet toegelaten 🙁}
En aparte methodes schrijven leidt opnieuw tot code-duplicatie:
Zou het nuttig zijn om een methode copyFromCatsToBirds(ArrayList<Cat> source, ArrayList<Bird> target) te voorzien? Waarom (niet)?
De oplossing in dit geval is gebruik maken van het wildcard-type <? super T>.
Het type ArrayList<? super Cat> staat dus voor “elke ArrayList waar het element-type een supertype is van Cat” (inclusief het type Cat zelf).
Of nog: ArrayList<? super Cat> staat voor de verzameling van types ArrayList<Cat>, ArrayList<Mammal>, ArrayList<Animal>, en ArrayList<Object>, alsook elke andere ArrayList met een supertype van Cat als element-type.
copyFromCatsTo_wildcard(cats,otherCats);// OK 👍copyFromCatsTo_wildcard(cats,mammals);// OK 👍copyFromCatsTo_wildcard(cats,animals);//OK👍
Dit heet contravariantie: hoewel Cat een subtype is van Animal, is ArrayList<? super Cat> een supertype vanArrayList<Animal>.
De ‘contra’ in contravariantie wijst erop dat de overervingsrelatie tussen Cat en Animal in de omgekeerde richting loopt als die tussen ArrayList<? super Cat> en ArrayList<Animal>.
Bekijk volgende figuur aandachtig:
Als we ook ArrayList<Mammal>, ArrayList<? super Mammal>, en ArrayList<? super Animal> toevoegen aan het plaatje, ziet dat er als volgt uit:
graph BT
ALCat["ArrayList#lt;Cat>"]
ALsuperCat["ArrayList#lt;? super Cat>"]
ALsuperMammal["ArrayList#lt;? super Mammal>"]
ALsuperAnimal["ArrayList#lt;? super Animal>"]
ALMammal["ArrayList#lt;Mammal>"]
ALAnimal["ArrayList#lt;Animal>"]
ALCat --> ALsuperCat
ALAnimal --> ALsuperAnimal
ALMammal --> ALsuperMammal
ALsuperAnimal --> ALsuperMammal
ALsuperMammal --> ALsuperCat
Cat --> Mammal
Mammal --> Animal
classDef cat fill:#f99,stroke:#333,stroke-width:4px;
classDef mammal fill:#9f9,stroke:#333,stroke-width:4px;
classDef animal fill:#99f,stroke:#333,stroke-width:4px;
class ALCat,ALsuperCat,Cat cat;
class ALMammal,Mammal,ALsuperMammal mammal;
class ALAnimal,Animal,ALsuperAnimal animal;
Aan de hand van de kleuren kan je snel zien dat de overervingsrelatie links en rechts inderdaad omgekeerd verlopen.
Onthoud
Het type ArrayList<? super Mammal> staat voor de verzameling van types ArrayList<Mammal>, ArrayList<Animal>, ArrayList<Object>, en elk ander type dat een superklasse (of interface) is van Mammal.
Covariantie of contravariantie: PECS
Als we covariantie en contravariantie combineren, krijgen we volgend beeld (we focussen op de extends- en super-relatie vanaf Mammal):
Hier zien we dat ArrayList<? extends Mammal> (covariant) als subtypes ArrayList<Mammal> en ArrayList<Cat> heeft.
Het contravariante ArrayList<? super Mammal> heeft óók ArrayList<Mammal> als subtype, maar ook ArrayList<Animal>.
Hoe weet je nu wanneer je wat gebruikt als type voor een parameter? Wanneer kies je <? extends T>, en wanneer <? super T>?
Een goede vuistregel is het acroniem PECS, wat staat voor Producer Extends, Consumer Super.
Dus:
Wanneer het object gebruikt wordt als een producent van T’s (met andere woorden, het object is een levancier van T-objecten voor jouw code, die ze vervolgens gebruikt), gebruik je <? extends T> (covariantie). Dat is logisch: als jouw code met aangeleverde T’s omkan, dan kan jouw code ook om met de aanlevering van een subklasse van T (basisprincipe objectgeoriënteerd programmeren).
Wanneer het object gebruikt wordt als een consument van T’s (met andere woorden, het neemt T-objecten aan van jouw code), gebruik je <? super T> (contravariantie). Ook dat is logisch: een object dat beweert om te kunnen met elke superklasse van T moet zeker overweg kunnen met een T die jouw code aanlevert.
Wanneer het object zowel als consument als als producent gebruikt wordt, gebruik je gewoon <T> (dus geen co- of contra-variantie, maar invariantie). Er is dan weinig tot geen flexibiliteit meer in het type.
Onthoud
Is de parameter uitsluitend een producent van T’s? Gebruik dan <? extends T>.
Is de parameter uitsluitend een consument van T’s? Gebruik dan <? super T>.
Is de parameter zowel een producent als consument? Gebruik dan gewoon <T>.
Een voorbeeld om PECS toe te passen: we willen een methode copyFromTo die zo flexibel mogelijk is, om elementen uit een lijst van zoogdieren te kopiëren naar een andere lijst.
Met deze methode kunnen we nu alle zinvolle operaties uitvoeren, terwijl de zinloze operaties tegengehouden worden door de compiler:
ArrayList<Cat>cats=/* ... */ArrayList<Dog>dogs=/* ... */ArrayList<Bird>birds=/* ... */ArrayList<Mammal>mammals=/* ... */ArrayList<Animal>animals=/* ... */copyMammalsFromTo(cats,animals);// OK 👍copyMammalsFromTo(cats,mammals);// OK 👍copyMammalsFromTo(cats,cats);// OK 👍copyMammalsFromTo(mammals,animals);// OK 👍copyMammalsFromTo(cats,dogs);// compiler error (Dog is geen supertype van Mammal) 👍copyMammalsFromTo(birds,animals);//compilererror(BirdisgeensubtypevanMammal)👍
Merk op dat het type Mammal in onze laatste versie van copyMammalsFromTo hierboven eigenlijk onnodig is. We kunnen de methode nog verder veralgemenen door er een generische methode van te maken, die werkt voor alle lijsten (niet enkel lijsten van zoogdieren):
Met deze versie kunnen we nu bijvoorbeeld ook Birds kopiëren naar een lijst van dieren:
copyFromTo(birds,animals);//OK👍
Opmerking
Wanneer een parameter zowel een producent als een consument is, gebruik je geen wildcards.
De generische parameter heet dan invariant.
Bijvoorbeeld:
publicstatic<T>voidreverse(List<T>list){intleft=0;intright=list.size()-1;while(left<right){// Producent (get)Ttemp=list.get(left);// Consumer (set)list.set(left,list.get(right));list.set(right,temp);left++;right--;}}
Arrays en type erasure
In tegenstelling tot ArrayLists (en andere generische types), beschouwt Java arrays wél altijd als covariant.
Dat betekent dat Cat[] een subtype is van Animal[].
Volgende code compileert dus (maar gooit een uitzondering bij het uitvoeren):
De reden hiervoor is, in het kort, dat informatie over generics gewist wordt bij het compileren van de code.
Dit heet type erasure.
In de gecompileerde code is een ArrayList<Animal> en ArrayList<Cat> dus exact hetzelfde.
Er kan dus, tijdens de uitvoering, niet gecontroleerd worden of je steeds het juiste type gebruikt.
Daarom moet de compiler dat doen, en die neemt het zekere voor het onzekere: alles wat mogelijk fout zou kunnen aflopen, wordt geweigerd.
Bij arrays wordt er wel type-informatie bijgehouden na het compileren, en kan dus tijdens de uitvoering nog gecontroleerd worden of je geen elementen met een ongeldig type toevoegt. De compiler hoeft het niet af te dwingen — maar het wordt wel nog steeds gecontroleerd tijdens de uitvoering, en kan leiden tot een exception.
Aandachtspunten
Enkel bij generische types!
Tenslotte nog een opmerking (op basis van vaak gemaakte fouten op examens).
Co- en contra-variantie (extends, super, en wildcards dus) zijn enkel van toepassing op generische types.
Alles wat we hierboven gezien hebben is dus enkel nuttig op plaatsen waar je een generisch type (List<T>, Food<T>, …) gebruikt voor een parameter, terugkeertype, variabele, ….
Dergelijke types kan je met behulp van co-/contra-variantie en wildcards verrijken tot bijvoorbeeld List<? extends T>, Food<? super T>, …
Maar je kan deze constructies niet gebruiken op plaatsen waar een gewoon type verwacht wordt, bijvoorbeeld bij een parameter of terugkeertype.
Onderstaande regels code zijn dus allemaal ongeldig:
Deze methode kan óók al opgeroepen worden met een Cat-object, Dog-object, of elk ander type Mammal als argument.
Je hebt hier geen co- of contra-variantie van generische types nodig; je maakt gewoon gebruik van overerving uit objectgeoriënteerd programmeren.
Onthoud
Wildcards (?), co-variantie (? extends) en contra-variantie (? super) zijn enkel van toepassing bij generische types! Je kan ze dus niet gebruiken als een op zichzelf staand type. Je kan ze ook niet gebruiken bij de definitie van een nieuwe generische parameter (voor een klasse of methode), maar enkel bij het gebruik ervan.
Bounds vs. co-/contravariantie en wildcards
Tot slot is het nuttig om nog eens te benadrukken dat er een verschil is tussen het begrenzen van een generische parameter (met extends) enerzijds, en het gebruik van co-variantie, contra-variantie en wildcards (? extends T, ? super T) anderzijds. Het feit dat extends in beide gevallen gebruikt wordt, kan misschien tot wat verwarring leiden.
Een begrenzing (via <T extends SomeClass>) beperkt welke types geldige waarden zijn voor de type-parameter T. Dus: elke keer wanneer je een concreet type wil meegeven in de plaats van T moet dat type voldoen aan bepaalde eisen.
Je kan zo’n begrenzing enkel aangeven op de plaats waar je een nieuwe generische parameter (T) introduceert (dus bij een nieuwe klasse-definitie of methode-definitie).
Bijvoorbeeld: class Food<T extends Animal> laat later enkel toe om Food<X> te schrijven als type wanneer X ook een subtype is van Animal.
Door co- en contra-variantie (met <? extends X> en <? super X>) te gebruiken verbreed je de toegelaten types.
Een methode-parameter met als type Food<? extends Animal> laat een Food<Animal> toe als argument, maar ook een Food<Cat> of Food<Dog>.
Omgekeerd zal een parameter met als type Food<? super Cat> een Food<Cat> toelaten, maar ook een Food<Animal>.
Er wordt in beide gevallen dus meer toegelaten, wat meer flexibiliteit biedt.
Je kan co- en contravariantie toepassen op elke plaats waar je een generisch type gebruikt (en waar dat gepast is volgens de PECS regels).
Het kan dus perfect zijn dat je de ene keer in je code eens Food<Cat> gebruikt, ergens anders Food<? extends Cat>, en nog ergens anders Food<? super Cat>.
Bij begrenzing is dat niet zo; dat legt de grenzen eenmalig vast, en die moeten overal gerespecteerd worden waar het generisch type gebruikt wordt.
Onthoud
Een begrenzing (T extends X) is een eenmalige beperking op het type dat gebruikt kan worden als waarden voor een nieuw geïntroduceerde generische parameter. Dit kan enkel voorkomen in de definitie van een nieuwe generische parameter (bij een generische klasse of methode).
Co-en contravariantie (? extends X, ? super X) met wildcard ?versoepelen de types die aanvaard worden door de compiler. Ze komen enkel voor op plaatsen waar een generisch type gebruikt wordt.
Arrays met generisch type
Als je een array wil maken van een generisch type, laat de Java-compiler dat niet toe:
classMyClass<T>{privateT[]array;publicMyClass(){array=newT[10];// <-- niet toegelaten ☹️}}
De reden is opnieuw type erasure.
Aangezien arrays covariant zijn, moet tijdens de uitvoering gecontroleerd kunnen worden of objecten die in de array terechtkomen een geschikt type hebben.
Aangezien generische parameters verwijderd worden door de compiler, kan dat niet.
Een oplossing voor bovenstaand probleem is om een cast toe te voegen. Met een @SuppressWarning annotatie kan je de waarschuwing die door de compiler gegeven wordt negeren.
Lijn 3 OK: yourPlace heeft type Vehicle, en Bike erft over van Vehicle(de naam van de variabele is wel slecht gekozen)
Lijn 4 OK: ArrayList<Vehicle> (hier ArrayList<>) is een subtype van Collection<Vehicle>
Lijn 5 OK: vehicles kan om het even welk Vehicle bevatten, dus ook een Motorized (type van myCar)
Lijn 6 OK: ArrayList<Car> is een subtype van List<Car>
Lijn 7 niet OK: List<Car> is geen subtype van List<Vehicles>
Lijn 8 OK: ArrayList<Car> is een subtype van List<? extends Motorized>
Lijn 9 niet OK: motorized is een lijst van een onbekend type gemotoriseerde voertuigen; we kunnen daar geen auto aan toevoegen.
Covariantie en contravariantie 1
Maak een schema met de overervingsrelaties tussen
List<Animal>
List<? super Animal>
List<? extends Animal>
List<Cat>
List<? extends Cat>
List<? super Cat>
Antwoord
graph BT
LA["List#lt;Animal>"]
LSA["List#lt;? super Animal>"]
LEA["List#lt;? extends Animal>"]
LC["List#lt;Cat>"]
LSC["List#lt;? super Cat>"]
LEC["List#lt;? extends Cat>"]
LA --> LSA
LA --> LSC
LA --> LEA
LC --> LSC
LC --> LEC
LC --> LEA
LSA --> LSC
LEC --> LEA
In onderstaande figuur worden de verschillende types weergegeven door verzamelingen: een deelverzameling betekent dat het binnenste type overerft van het buitenste.
Covariantie en contravariantie 2
Maak een schema met de overervingsrelaties tussen
List<Cat>
ArrayList<Cat>
List<? super Cat>
ArrayList<? super Cat>
List<? extends Cat>
ArrayList<? extends Cat>
Antwoord
graph BT
LC["List#lt;Cat>"]
LSC["List#lt;? super Cat>"]
LEC["List#lt;? extends Cat>"]
AC["ArrayList#lt;Cat>"]
ASC["ArrayList#lt;? super Cat>"]
AEC["ArrayList#lt;? extends Cat>"]
AC --> LC
AC --> ASC
AC --> LSC
AC --> AEC
AC --> LEC
LC --> LSC
LC --> LEC
AEC --> LEC
ASC --> LSC
In onderstaande figuur worden de verschillende types weergegeven door verzamelingen: een deelverzameling betekent dat het binnenste type overerft van het buitenste.
Repository
Schrijf een generische klasse Repository die een repository van objecten voorstelt. De objecten hebben ook een ID. Zowel het type van objecten als het type van de ID moeten generische parameters zijn.
Definieer en implementeer volgende methodes (maak gebruik van een ArrayList):
add(id, obj): toevoegen van een object
findById(id): opvragen van een object aan de hand van de id
findAll(): opvragen van alle objecten in de repository
update(id, obj): vervangen van een object met gegeven id door het meegegeven object
remove(id): verwijderen van een object aan de hand van een id
Shop
Maak een klasse Shop die een winkel voorstelt die items (subklasse van StockItem) aankoopt.
Af en toe wordt er een inventaris opgemaakt van alle items die op stock zijn.
Een Shop-object wordt geparametriseerd met het type items dat aangekocht kan worden.
We beschouwen hier Fruit en Electronics; daarmee kunnen we dus een fruitwinkel (Shop<Fruit>) en elektronica-winkel (Shop<Electronics>) maken.
De Shop-klasse heeft drie methodes:
buy, die een lijst van items toevoegt aan de stock;
addStockToInventory, die de lijst van items uit de stock toevoegt aan de meegegeven inventaris-lijst (de items blijven bewaard in de stock);
stockSize() die het huidig aantal items in de stock toevoegt.
Daarnaast maak je een statische methode merge waarmee je twee Shop-objecten kan samenvoegen tot een nieuw Shop-object.
De twee Shops die samengevoegd worden hoeven niet hetzelfde type items te hebben. Je kan bijvoorbeeld een fruitwinkel en electronicawinkel samenvoegen tot een supermarkt waar elk soort StockItem verkocht kan worden.
Na een merge is de stock verdwenen uit de oorspronkelijke shops en terechtgekomen in de nieuwe (samengevoegde) winkel.
In de startcode vind je reeds een implementatie van een abstracte klasse StockItem, Fruit, en subklassen Apple en Orange.
Daarnaast is er ook een abstracte klasse Electronics, met als subklasse Smartphone.
Zorg dat onderstaande code (ongewijzigd) compileert en dat de test slaagt:
Vul de types en generische parameters aan op de 7 genummerde plaatsen zodat onderstaande code en main-methode compileert (behalve de laatste regel van de main-methode) en voldaan is aan volgende voorwaarden:
Elk actie-type kan enkel uitgevoerd worden door een bepaald karakter-type. Bijvoorbeeld: een FightAction kan enkel uitgevoerd worden door een karakter dat CanFight implementeert.
doAction mag enkel opgeroepen worden met een actie die uitgevoerd kan worden door alle karakters in de meegegeven lijst.
Als er op een bepaalde plaats geen type of generische parameter nodig is, vul je $\emptyset$ in.
Verklaar je keuze voor de combinatie van (5), (6), en (7).
interfaceCharacter{}interfaceCanFightextendsCharacter{}recordWarrior()implementsCanFight{}recordKnight()implementsCanFight{}recordWizard()implementsCharacter{}// kan niet vechteninterfaceAction<___/* 1 */___>{voidexecute(___/* 2 */____character);}classFightActionimplementsAction<___/* 3 */_____>{@Overridepublicvoidexecute(___/* 4 */______character){System.out.println(character+" fights!");}}classGameEngine{public<___/* 5 */______>voiddoAction(List<___/* 6 */____>characters,Action<___/* 7 */____>action){for(varcharacter:characters){action.execute(character);}}}publicstaticvoidmain(String[]args){varengine=newGameEngine();Action<CanFight>fight=newFightAction();List<Warrior>warriors=List.of(newWarrior(),newWarrior());engine.doAction(warriors,fight);List<Wizard>wizards=List.of(newWizard());engine.doAction(wizards,fight);// deze regel mag NIET compileren}
Antwoord
1: C extends Character : acties kunnen enkel uitgevoerd worden door subtypes van Character
2: C: C is het type van Character dat de actie zal uitvoeren
3: CanFight: FightAction is enkel mogelijk voor characters die CanFight implementeren
4: CanFight: aangezien de generische paremeter C van superinterface Action geinitialiseerd werd met CanFight, moet hier ook CanFight gebruikt worden.
5: T extends Character: we noemen T het type van de objecten in de meegeven lijst; we hebben hier een begrenzing nodig (want we willen enkel subtypes van Character toelaten)
6: T: lijst van T’s, zoals verondersteld in 5
7: ? super T: de meegegeven actie moet een actie zijn die door alle T’s uitgevoerd kan worden (dus door T of een van de supertypes van T).
Redenering met behulp van PECS: de meegegeven actie gebruikt/consumeert het character, dus super.
Alternatieve keuze voor 5/6/7:
5: T extends Character: we noemen T het type dat bij de actie hoort; we hebben hier een begrenzing nodig (want we willen enkel subtypes van Character toelaten)
6: ? extends T: lijst van T’s of subtypes ervan.
Redenering met behulp van PECS: de lijst levert/produceert de characters, dus extends.
7: T: het type van de actie, zoals verondersteld in 5
Extra oefeningen
SuccessOrFail
Schrijf een generische klasse (of record) SuccessOrFail die een object voorstelt dat precies één element bevat.
Dat element heeft 1 van 2 mogelijke types (die types zijn generische parameters).
Het eerste type stelt het type van een succesvol resultaat voor; het tweede type is dat van een fout.
Je kan objecten enkel aanmaken via de statische methodes success en fail.
Een voorbeeld van tests voor die klasse vind je hieronder:
@Testpublicvoidsuccess(){SuccessOrFail<String,Exception>result=SuccessOrFail.success("This is the result");assertThat(result.isSuccess()).isTrue();assertThat(result.successValue()).isEqualTo("This is the result");}@Testpublicvoidfailure(){SuccessOrFail<String,Exception>result=SuccessOrFail.fail(newIllegalStateException());assertThat(result.isSuccess()).isFalse();assertThat(result.failValue()).isInstanceOf(IllegalStateException.class);}
Functie compositie
Java bevat een ingebouwde interface java.util.function.Function<T, R>, wat een functie voorstelt met één parameter van type T, en een resultaat van type R. Deze interface voorziet 1 methode R apply(T value) om de functie uit te voeren.
Schrijf nu een generische methode compose die twee functie-objecten als parameters heeft, en als resultaat een nieuwe functie teruggeeft die de compositie voorstelt: eerst wordt de eerste functie uitgevoerd, en dan wordt de tweede functie uitgevoerd op het resultaat van de eerste.
Dus: voor functies
Function<A,B>f1=...Function<B,C>f2=...
moet compose(f1, f2) een Function<A, C> teruggeven, die als resultaat f2.apply(f1.apply(a)) teruggeeft.
Pas de PECS-regel toe om ook functies te kunnen samenstellen die niet exact overeenkomen qua type.
Bijvoorbeeld, volgende code moet compileren en de test moet slagen:
Schrijf een generische klasse (of record) Maybe die een object voorstelt dat nul of één waarde van een bepaald type kan bevatten.
Dat type wordt bepaald door een generische parameter. Je kan Maybe-objecten enkel aanmaken via de statische methodes some en none.
Hieronder vind je twee tests:
Maak de print-methode hieronder ook generisch, zodat deze niet enkel werkt voor een Maybe<String> maar ook voor andere types dan String.
classMaybePrint{publicstaticvoidprint(Maybe<String>maybe){if(maybe.hasValue()){System.out.println("Contains a value: "+maybe.getValue());}else{System.out.println("No value :(");}}publicstaticvoidmain(String[]args){Maybe<String>maybeAString=Maybe.some("yes");Maybe<String>maybeAnotherString=Maybe.none();print(maybeAString);print(maybeAnotherString);}}
Voeg aan Maybe een generische methode map toe die een java.util.function.Function<T, R>-object als parameter heeft, en die een nieuw Maybe-object teruggeeft, met daarin het resultaat van de functie toegepast op het element als er een element is, of een leeg Maybe-object in het andere geval.
Zie de tests hieronder voor een voorbeeld van hoe deze map-functie gebruikt wordt:
(optioneel) Herschrijf Maybe als een sealed interface met twee record-subklassen None en Some.
Geef een voorbeeld van hoe je deze klasse gebruikt met pattern matching.
Kan je ervoor zorgen dat je getValue() nooit kan oproepen als er geen waarde is (compiler error)?
Info
Java bevat een ingebouwd type gelijkaardig aan de Maybe-klasse uit deze oefening, namelijk Optional<T>.
Animal food
Dit is een uitdagende oefening, voor als je je kennis over generics echt wil testen.
Voeg generics (met grenzen/bounds) toe aan de code hieronder, zodat de code (behalve de laatste regel) compileert,
en de compiler enkel toelaat om kattenvoer te geven aan katten, en hondenvoer aan honden:
publicclassAnimalFood{staticclassAnimal{publicvoideat(Foodfood){System.out.println(this.getClass().getSimpleName()+" says 'Yummie!'");}}staticclassMammalextendsAnimal{publicvoiddrink(Milkmilk){this.eat(milk);}}staticclassCatextendsMammal{}staticclassKittenextendsCat{}staticclassDogextendsMammal{}staticclassFood{}staticclassMilkextendsFood{}staticclassMain{publicstaticvoidmain(String[]args){FoodcatFood=newFood();MilkcatMilk=newMilk();FooddogFood=newFood();MilkdogMilk=newMilk();Catcat=newCat();Dogdog=newDog();Kittenkitten=newKitten();cat.eat(catFood);// OK 👍cat.drink(catMilk);// OK 👍dog.eat(dogFood);// OK 👍dog.drink(dogMilk);// OK 👍kitten.eat(catFood);// OK 👍kitten.drink(catMilk);// OK 👍cat.eat(dogFood);// <- moet een compiler error geven! ❌kitten.eat(dogFood);// <- moet een compiler error geven! ❌kitten.drink(dogMilk);// <- moet een compiler error geven! ❌}}}
(Hint: Begin met het type Food te parametriseren met een generische parameter die het Animal-type voorstelt dat dit voedsel eet.)
Self-type
Dit is een uitdagende oefening, voor als je je kennis over generics echt wil testen.
Heb je je al eens afgevraagd hoe assertThat(obj) uit AssertJ werkt?
Afhankelijk van het type van obj dat je meegeeft, worden er andere assertions beschikbaar die door de compiler aanvaard worden:
// een List<String>List<String>someListOfStrings=List.of("hello","there","how","are","you");assertThat(someListOfStrings).isNotNull().hasSize(5).containsItem("hello");// een StringStringsomeString="hello";assertThat(someString).isNotNull().isEqualToIgnoringCase("hello");// een IntegerintsomeInteger=4;assertThat(someInteger).isNotNull().isGreaterThan(4);assertThat(someInteger).isNotNull().isEqualToIgnoringCase("hello");//<=compileertniet❌
Sommige assertions (zoals isNotNull) zijn echter generiek, en wil je slechts op 1 plaats implementeren.
Probeer zelf een assertThat-methode te schrijven die werkt zoals bovenstaande, maar waar isNotNull slechts op 1 plaats geïmplementeerd is.
De assertThat-methode moet een Assertion-object teruggeven, waarop de verschillende methodes gedefinieerd zijn afhankelijk van het type dat meegegeven wordt aan assertThat.
Hint 1: maak verschillende klassen, bijvoorbeeld ListAssertion, StringAssertion, IntegerAssertion die de type-specifieke methodes bevatten. Begin met isNotNull toe te voegen aan elk van die klassen (dus door de implementatie te kopiëren).
Hint 2: in een zogenaamde ‘fluent interface’ geeft elke operatie zoals isNotNull en hasSize het this-object op het einde terug (return this), zodat je oproepen na elkaar kan doen. Bijvoorbeeld .isNotNull().hasSize(5).
Hint 3: maak nu een abstracte klasse GenericAssertion die isNotNull bevat, en waarvan de andere assertions overerven. Verwijder de andere implementaties van isNotNull.
Hint 4: In isNotNull is geen informatie beschikbaar over het type dat gebruikt moet worden als terugkeertype van isNotNull. assertThat(someString).isNotNull() moet bijvoorbeeld opnieuw een StringAssertion teruggeven. Dat kan je oplossen met generics, en een abstracte methode die het juiste object teruggeeft.
Hint 5: Je zal een zogenaamd ‘self-type’ moeten gebruiken. Dat is een generische parameter die wijst naar de (sub)klasse zelf.
Hint 6: op deze pagina wordt uitgelegd hoe AssertJ dit doet. Probeer eerst zelf, zonder dit te lezen!
7.5 Lambdas
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java lambda’s zijn
in Python: lambda’s (met het keyword lambda) en callables
in C++: lambda expressies, function pointers
in C#: lambda expressies
Daarenboven zijn lambda’s en methode-referenties alomtegenwoordig in zogenaamde pure functionele programmeertalen (bv. Haskell).
Wat en waarom?
Met lambda-functies kun je in Java kort en bondig een functie schrijven zonder de functie een naam te geven.
Dat is handig als je de functie maar op één plaats zal gebruiken.
Bijvoorbeeld, stel dat we een record Person hebben:
en we willen die sorteren volgens "Voornaam Achternaam", maar ons Person-record heeft geen methode fullName().
In plaats van die functie te schrijven, enkel voor het sorteren, kunnen we een lambda-functie gebruiken.
Een lambda-functie die de voor- en achternaam van een persoon aan elkaar plakt met een spatie ziet er als volgt uit:
(Personp)->p.firstName()+" "+p.lastName()
De -> wijst op een lambda-functie. Links ervan staan de parameters, rechts de body van de methode.
Je kan met zo’n lambda-functie dan een Comparator maken die gebruikt wordt om een lijst van personen sorteert volgens hun voor- en achternaam:
Exact 1 parameter (haakjes mogen weg als je geen expliciet type schrijft):
x->x*x
Meerdere parameters:
(a,b)->a+b
Body met meerdere statements:
(a,b)->{intsom=a+b;returnsom*2;}
Notitie
Gebruik je een blok-body met { ... }, dan moet je return expliciet schrijven (behalve bij void-lambdas).
Bij een expression-body (x -> x + 1) gebeurt de return impliciet.
Methode-referenties
Methode-referenties zijn een manier om direct te verwijzen naar een reeds bestaande methode, in plaats van er een lambda voor te schrijven.
Waar je een lambda van de vorm (Person p) -> p.age() zou gebruiken, kun je ook gewoon Person::age schrijven.
De :: wijst op een methode-referentie. Links ervan staat de naam van de klasse, rechts de naam van de (bestaande) methode.
Merk op dat er geen haakjes () staan (dus nietPerson::age()). Het is enkel een verwijzing naar de methode; de methode zelf wordt niet meteen opgeroepen.
Een methode-referentie is vooral handig als de lambda precies één methode-aanroep doet.
Achter de schermen gebeurt hetzelfde, maar de code is wat compacter.
Om bijvoorbeeld de lijst people te sorteren volgens hun leeftijd, kan je een methode-referentie gebruiken als volgt:
people.sort(Comparator.comparing(Person::age));
Java kent vier standaardvormen van methode-referenties:
Merk op dat alle variabelen hierboven (toInt, print, lower, emptyList) verwijzen naar een methode (of functie), en niet naar een waarde (int, String, …) zoals je gewoon bent.
Deze variabelen hebben type Function<String, Integer>, Consumer<Object>, etc.
We gaan zodadelijk dieper in op deze types.
Het is erg belangrijk om te begrijpen dat in het voorbeeld hierboven geen van de methodes (parseInt, println, toLowerCase, of de constructor van ArrayList) opgeroepen of uitgevoerd wordt.
We maken enkel de verwijzing naar deze methode, en kennen die toe aan een variabele.
We kunnen deze variabelen nadien wel gebruiken om de methodes effectief uit te voeren, bijvoorbeeld:
ArrayList<String>newList=emptyList.get();// roept constructor van ArrayList opStringelement=lower.apply("HeLLo");// zet "HeLLo" om in "hello"newList.add(element);print.accept(newList.get(0));// print "hello" uitintx=toInt.apply("123");// zet "123" om naar 123print.accept(x);//print123uit
Types van lambda’s en methode-referenties
Omdat Java een sterk getypeerde taal is, moeten lambda-functies en methode-referenties ook een type hebben.
Dat gebeurt door een interface te definiëren.
Functional interface
Elke interface met daarin precies één methode kan automatisch gebruikt worden als type voor lambda-functies en methode-referenties, tenminste als de types van parameters en het resultaat overeen komen.
Als het expliciet de bedoeling is om de interface op deze manier te gebruiken, kan je die interface ook met @FunctionalInterface annoteren; de compiler komt dan klagen als je later een extra methode zou proberen toe te voegen aan die interface.
Bijvoorbeeld:
@FunctionalInterfaceinterfacePersonPredicate{booleantest(Personperson);// slechts één methode (van Person naar boolean)}
In de code hierboven zie je de PersonPredicate-interface, geannoteerd met @FunctionalInterface.
Deze definieert één methode die true of false teruggeeft voor een persoon.
De methode selectPeople hieronder gebruikt de PersonPredicate interface om alle personen te selecteren die voldoen aan de meegegeven voorwaarde.
We overlopen nu vier manieren om de selectPeople methode te gebruiken.
Een eerste manier is een klasse maken (bv. IsAdult) die de interface implementeert, en die nagaat of de persoon meerderjarig is.
Dat werkt, maar is nogal omslachtig, zeker als we dit slechts op 1 plaats nodig hebben:
Een tweede optie is om een anonieme klasse te gebruiken. In het voorbeeld gaat de anonieme klasse na of de achternaam van de persoon begint met “Do”.
Ook dat blijft omslachtig, het bespaart ons enkel de moeite om een naam voor een klasse te verzinnen:
Met lambda-functies kan je dergelijke code veel eenvoudiger schrijven.
In codefragment 3 en 4 hieronder zie je hoe je een lambda-functie kan gebruiken die hetzelfde doet als de vorige voorbeelden, maar dan zonder een klasse te schrijven.
Merk op dat het toegelaten is om de lambda-functies te gebruiken waar een PersonPredicate verwacht wordt.
De twee lambda-functies hieronder zijn inderdaad functies die een Person-object als argument hebben, en een boolean teruggeven, en komen dus qua type overeen met de test-methode in PersonPredicate.
Dat is vooral nuttig als deze methode al bestaat en je er gebruik van wil maken.
Voorgedefinieerde types voor functies
In plaats van zelf een interface zoals PersonPredicate te schrijven, kan je vaak ook beroep doen op een voorgedefinieerde functie-interface.
Je vindt de lijst daarvan in de documentatie.
We lijsten hier de belangrijkste reeds bestaande functionele interfaces op die gebruikt worden:
Function<T, R>: stelt een functie met 1 parameter voor die een T omzet in een R:
Supplier<T>: stelt een operatie zonder parameters voor die een T teruggeeft:
@FunctionalInterfaceinterfaceSupplier<T>{Tget();}
Een invocatie van de supplier mag telkens hetzelfde object teruggeven, maar ook elke keer een ander object en alles daartussenin. Een supplier kan dus beschouwd worden als generator. Bijvoorbeeld:
Op zich maakt het niet uit welke interface er gebruikt wordt, zolang de types van de enige methode erin maar overeenkomen met die van de lambda-expressie.
Bijvoorbeeld, de lambda
(Personp)->p.age()>=18
kan dus overal gebruikt worden waar onze zelfgedefinieerde PersonPredicate-interface verwacht wordt, maar ook overal waar een Predicate<Person> of een Function<Person, Boolean> verwacht wordt.
De compiler gaat enkel na of de types van parameters en resultaat overeenkomen met die van de enige methode in de interface; de naam van de interface en de naam van de methode in deze interface doen niet terzake.
Capturing en ’effectively final’
Een lambda mag variabelen uit de omliggende scope gebruiken.
Dat heet capturing.
Zo’n variabele (minAge hierboven) moet wel effectively final zijn: je mag ze na initialisatie niet meer aanpassen.
Met andere woorden: je zou de variabele final moeten kunnen maken zonder dat dat problemen geeft.
De Java compiler zal zelf uitzoeken of de variabelen die gebruikt worden in een lambda inderdaad effectively final zijn, en een fout geven als dat niet zo is.
Dit voorkomt verwarrende situaties rond toestand en lifetime van variabelen.
Bijvoorbeeld:
Als de code hierboven wel zou compileren, is het niet duidelijk welke leeftijd gebruikt zou moeten worden: 18 of 21?
De makkelijkste manier om hier geen last van te hebben is door geen variabelen te gebruiken die buiten de lambda gedefinieerd worden, en dat is dan ook ten zeerste aanbevolen.
Deze oefening is ook een extra oefening op generics.
Schrijf een generische methode compose die twee functies als parameters heeft, en als resultaat een nieuwe functie teruggeeft die de compositie voorstelt: eerst wordt de eerste functie uitgevoerd, en dan wordt de tweede functie uitgevoerd op het resultaat van de eerste.
Dus: voor functies
Function<A,B>f1=...Function<B,C>f2=...
moet compose(f1, f2) een Function<A, C> teruggeven, die als resultaat f2.apply(f1.apply(a)) teruggeeft.
Pas de PECS-regel toe om ook functies te kunnen samenstellen die niet exact overeenkomen qua type.
Bijvoorbeeld, volgende code moet compileren en de test moet slagen:
Java heeft geen interface voor een functie met 3 parameters.
Definieer zelf een (generische) functionele interface TriFunction die een functie voorstelt met 3 parameters (van een verschillend type).
Definieer een functie zip3 die 3 lijsten als parameters heeft, samen met een TriFunction.
De 3 lijsten moeten even lang zijn.
Deze functie geeft een lijst terug waarvan het i-de element gevormd wordt door de meegegeven tri-functie toe te passen op het i-de element van elk van de drie parameter-lijst.
Een voorbeeld van het gebruik van zip3 om een lijst van personen te maken op basis van een lijst van voornamen, achternamen, en leeftijden:
Schrijf een generische klasse Dispatcher<E> waar klassen zich kunnen inschrijven om op de hoogte gebracht te worden van een event.
Het event heeft generisch type E.
Voorzie twee methodes:
Een methode subscribe waar je een methode kan registreren die opgeroepen moet worden telkens een event E gepubliceerd wordt.
Een methode publish(E event) die alle geregistreerde methodes oproept met het meegegeven event.
Een voorbeeld van het gebruik van de Dispatcher-klasse (met String als event-type):
De concepten in andere programmeertalen die het dichtst aanleunen bij Java streams zijn
ranges in C++
iterators, generators en comprehensions in Python
LINQ in C#
Wat en waarom?
Streams vormen een krachtig concept om efficiënt data te verwerken.
Ze vormen een abstractie voor sequentiële en parallelle operaties op datasets, zoals filteren, transformeren, en aggregeren, zonder de onderliggende datastructuur te wijzigen.
Bovendien maakt het gebruik van streams het mogelijk om declaratief te programmeren: je beschrijft op hoog niveau wát je met de dataset wilt doen, in plaats van stap voor stap te beschrijven hoe dat moet gebeuren.
Een snel voorbeeldje om dat wat concreter te maken is onderstaande code, die streams gebruikt om de gemiddelde leeftijd te berekenen van de eerste 20 meerderjarige Person-objecten in de lijst people (we gaan later dieper in op de details):
Een stream zelf is geen datastructuur of collectie; een stream is een pijplijn — een ketting van operaties die uitgevoerd moeten worden op de data.
Die operaties kunnen de data filteren, transformeren, groeperen, reduceren, …
Een stream stelt dus één grote bewerking voor op de data, samengesteld uit meerdere operaties.
Elke stream bestaat uit 3 delen:
één bron voor de data (een stroom van data, vandaar de naam). Die bron kan een datastructuur zijn (bv. een array, ArrayList, HashSet, …), maar ook andere bronnen zijn mogelijk (bijvoorbeeld een oneindige sequentie van getallen, zoals de natuurlijke getallen). In het voorbeeld hierboven is de lijst people de bron.
intermediaire operaties (mogelijk meerdere na elkaar) die de data verwerken (transformeren). Elke operatie neemt het resultaat van de vorige operatie (of de bron) en doet daar iets mee; het resultaat daarvan dient als invoer voor de volgende operatie. Zo krijg je een pijplijn waar de data doorheen stroomt terwijl ze bewerkt wordt. In het voorbeeld hierboven zijn mapToInt, filter en limit intermediaire operaties.
één terminale operatie: deze beëindigt de ketting en geeft het uiteindelijke resultaat terug. In het voorbeeld hierboven is average de terminale operatie.
Notitie
average() geeft een OptionalDouble terug, geen gewone double.
Dat komt omdat de stream leeg kan zijn (er zijn bijvoorbeeld geen meerderjarigen), en de gemiddelde waarde van een lege stream niet berekend kan worden.
We gebruiken daarom bij het uitprinten orElse(...) om 0 terug te geven als er geen ander resultaat is.
Je kan een stream-pijplijn slechts éénmaal doorlopen. Als je na het uitvoeren van de operaties nog een sequentie van operaties wil uitvoeren op dezelfde bron-elementen, moet je een nieuwe stream maken.
Streams zijn ook lazy: er worden slechts zoveel elementen verwerkt als nodig om het resultaat te berekenen.
Dat maakt dat de bron oneindig veel elementen mag aanleveren; zolang de rest van de pijplijn er slechts een eindig aantal nodig heeft, vormt dat geen probleem.
Enkel elementen die nuttig zijn om het resultaat te bekomen worden gebruikt.
We zullen hier later nog op terugkomen.
Een zeer concrete situatie waarin streams nuttig zijn, is wanneer je van plan bent om code te schrijven met volgende vorm:
Dit patroon komt zeer vaak voor in code.
Neem, als eenvoudig voorbeeld om te starten, de situatie uit het voorbeeld hierboven: de gemiddelde leeftijd berekenen van de eerste 20 meerderjarige personen in een lijst.
Zonder streams zou je dat waarschijnlijk ongeveer als volgt schrijven (merk op hoe dit het patroon van hierboven volgt):
De versie met streams ziet er helemaal anders uit — je schrijft zelf geen lussen, maar focust je op het beschrijven van de uit te voeren operaties.
Hier ter vergelijking nogmaals de code met streams:
Een stream van T-objecten wordt aangeduid met de interface Stream<T>.
Voor streams van primitieve types zijn er ook specifieke interfaces, bijvoorbeeld IntStream, DoubleStream, …
Om een stream aan te maken, start je steeds met een bron voor de data die verwerkt zal worden.
Dat kan op verschillende manieren.
Je kan eenvoudig een stream maken van alle elementen in een collectie: elke collectie heeft een .stream() operatie die een stream teruggeeft van alle elementen. Dit is de meest courante manier om te werken met streams. Merk op dat een stream zelf geen datastructuur is, en dus ook geen elementen bevat. Een stream lijkt dus meer op een iterator (die de elementen uit de bron een voor een teruggeeft, maar deze niet zelf bevat) dan op een collectie.
people.stream()
Stream.of(T t1, T t2, ...) maakt een stream met als data exact de opgegeven objecten. Gelijkaardig kan je bijvoorbeeld ook IntStream.of(int i1, int i2, ...) gebruiken voor een stream van getallen.
Stream.of(person1,person2,person3)
Specifiek voor IntStream is er ook IntStream.range en IntStream.rangeClosed om een IntStream te maken van alle getallen in een bepaald bereik.
Stream.concat(s1, s2) maakt een nieuwe stream door twee streams samen te voegen: eerst komen alle elementen van de eerste stream, daarna die van de tweede stream.
Opnieuw is er ook een gelijkaardige operatie op IntStream.
Stream.generate(supplier) maakt een stream waarbij de elementen aangeleverd worden door de meegegeven Supplier. Die dient dus als generator voor nieuwe elementen.
Stream.iterate(seed, unaryOp) maakt een stream waarvan de elementen gegenereerd worden door unaryOp herhaald toe te passen, beginnend bij seed. De elementen van de stream zijn dus seed, unaryOp(seed), unaryOp(unaryOp(seed)), .... Dit is bijvoorbeeld een (oneindige) stream van alle strikt positieve getallen1:
Stream.iterate(1,(n)->n+1)//=>1,2,3,4,...
Je kan ook een stream maken via een StreamBuilder, die je maakt via Stream.builder(). Dat laat toe om elementen één voor één toe te voegen (via add(...)), en daar uiteindelijk een stream van te maken via de build()-methode. Deze manier geeft je veel controle en is daardoor zeer flexibel, maar zal slechts zeer uitzonderlijk nodig zijn.
Tussentijdse (intermediate) operaties worden uitgevoerd op een stream, en geven een nieuwe stream terug.
De elementen in de nieuwe stream zijn gebaseerd op die van de originele stream, na het toepassen van de operatie.
Je kan de operaties dus na elkaar toepassen om een pijplijn te definiëren (dat is precies de bedoeling van een stream).
Het voorbeeld van daarstraks toont 3 tussentijdse operaties die na elkaar toegepast worden: mapToInt, filter, en limit (average is een terminale operatie; zie later).
We bespreken hieronder de meest voorkomende tussentijdse operaties.
De lijst van alle tussentijdse operaties is vooraf vastgelegd door de Stream-interface.
Met behulp van Gatherers kan je sinds Java 24 zelf tussentijdse operaties definiëren; we gaan hier niet dieper op in (zie links onderaan deze pagina voor meer info).
filter
De filter-operatie filtert sommige data-elementen uit de stream: enkel de elementen die voldoen aan het meegegeven predicaat worden verder doorgegeven.
Bijvoorbeeld, onderstaande filter-operatie verwijdert alle klinkers uit een stream van letters:
block-beta
columns 1
block:in
A B C D E F
end
arrow<["filter"]>(down)
block:out
space BB["B"] CC["C"] DD["D"] space FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
map, mapToInt, mapToLong, mapToDouble, mapToObj
De map-operatie transformeert elk elementen in een stream naar een ander element door een functie toe te passen op elk element.
Bijvoorbeeld, onderstaande map-operatie zet alle strings om naar lowercase:
block-beta
columns 1
block:in
ALICE Bob ChaRLIe
end
arrow<["map"]>(down)
block:out
alice bob charlie
end
classDef str stroke:black,fill:orange
class in,out str
In tegenstelling tot de filter-operatie kan de map-operatie het type van de elementen in de stream veranderen. Bijvoorbeeld, onderstaande code vertrekt van een stream van Strings, en eindigt met een stream van Integer-objecten:
block-beta
columns 1
block:in
ALICE Bob ChaRLIe
end
arrow<["map"]>(down)
block:out
alice bob charlie
end
arrow2<["map"]>(down)
block:out2
5 3 7
end
classDef str stroke:black,fill:orange
class in,out,out2 str
Er zijn ook specifieke map-operaties voor wanneer het resultaat een int, long, of double is.
Bijvoorbeeld, mapToInt geeft een IntStream terug.
Bij een IntStream, LongStream en DoubleStream geeft de map-operatie altijd opnieuw een stream van hetzelfde type (IntStream, LongStream, of DoubleStream).
Wanneer je de getallen in zo’n stream wil omzetten naar een object, kan dat met mapToObj:
Werk bij voorkeur met IntStream/LongStream/DoubleStream wanneer je numerieke data verwerkt.
Zo vermijd je onnodige boxing en unboxing van Integer, Long, of Double.
limit en takeWhile
De limit-operatie beperkt de resultaat-stream tot de eerste \( n \) elementen van de bron-stream:
block-beta
columns 1
block:in
A B C D E F
end
arrow<["limit"]>(down)
block:out
AA["A"] BB["B"] CC["C"] space:3
end
classDef str stroke:black,fill:orange
class in,out str
Merk op dat de plaats van limit (zoals die van de meeste tussentijdse operaties trouwens) belangrijk is:
De eerste variant resulteert in de eerste 3 medeklinkers uit de oorspronkelijke stream (je filtert eerst alle klinkers eruit, en neemt dan de eerste 3 overblijvende elementen).
In de tweede variant begin je met de eerste 3 letters, en filtert daaruit dan de klinkers weg.
Soms ken je het aantal elementen niet, maar wil je elementen blijven doorgeven zolang aan een bepaalde voorwaarde voldaan is.
Dat kan met takeWhile.
Merk op dat takeWhile niet hetzelfde is als filter: eenmaal de voorwaarde niet meer voldaan is, worden de volgende elementen niet meer bekeken, ook al zouden die opnieuw voldoen aan de voorwaarde.
block-beta
columns 1
block:in
A B C D E F
end
arrow<["skip"]>(down)
block:out
space:3 DD["D"] EE["E"] FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
De dropWhile-operatie is het omgekeerde van takeWhile: ze negeert elementen zolang aan een gegeven voorwaarde voldaan is.
block-beta
columns 1
block:in
Alpha Bravo Charlie Delta
end
arrow<["dropWhile"]>(down)
block:out
space:2 CC["Charlie"] DD["Delta"]
end
classDef str stroke:black,fill:orange
class in,out str
distinct
De distinct-operatie filtert alle dubbele waarden uit de stream. Deze operatie is stateful: de waarden die reeds gezien zijn moeten bijgehouden worden om mee te vergelijken.
block-beta
columns 1
block:in
A B A2["A"] C A3["A"] D
end
arrow<["distinct"]>(down)
block:out
AA["A"] BB["B"] space CC["C"] space DD["D"]
end
classDef str stroke:black,fill:orange
class in,out str
sorted
De sorted-operatie sorteert de waarden in de stream. Deze operatie is stateful (de reeds geziene waarden moeten bijgehouden worden om ze gesorteerd terug te geven), en de operatie vereist ook dat de stream eindig is. Het sorteren kan immers pas uitgevoerd worden wanneer alle elementen gekend zijn.
block-beta
columns 1
block:in
C D A F E B
end
arrow<["sorted"]>(down)
block:out
AA["A"] BB["B"] CC["C"] DD["D"] EE["E"] FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
peek
De peek-operatie doet eigenlijk niets: ze geeft alle elementen gewoon door, maar laat toe om een functie uit te voeren voor elk element.
Deze operatie kan bijvoorbeeld handig zijn om te debuggen: je kan ze middenin een pijplijn toevoegen om te kijken welke elementen daar voorbijkomen.
Stream.of("A","B","C","D","E","F").limit(3).peek(IO::println)// => A, B, C.filter(l->!"AEIOUY".contains(l))
block-beta
columns 1
block:in
A B C D E F
end
arrow<["limit"]>(down)
block:out
AA["A"] BB["B"] CC["C"] space:3
end
arrow2<["peek"]>(down)
block:out2
AAA["A"] BBB["B"] CCC["C"] space:3
end
arrow3<["filter"]>(down)
block:out3
space BBBB["B"] CCCC["C"] space:3
end
classDef str stroke:black,fill:orange
class in,out,out2,out3 str
flatMap
De flatMap operatie is gelijkaardig aan de map-operatie, maar wordt gebruikt wanneer het resultaat van de map-functie op één element opnieuw een stream geeft.
Opnieuw bestaan er specifieke versies flatMapToInt, flatMapToLong, en flatMapToDouble voor wanneer het resultaat een IntStream, LongStream of DoubleStream moet worden.
We gebruiken de String::chars methode als voorbeeld; die geeft voor een String een IntStream terug met de char-values van elk karakter (denk: de ASCII of Unicode-waarde van elke letter).
Als we gewoon map zouden toepassen, krijgen we een stream van streams (hier: een stream van 3 streams, elk met 2 elementen):
block-beta
columns 1
block:in
Aa Bb Cc
end
arrow<["map"]>(down)
block:out
columns 3
block:blockA
columns 2
A a
end
block:blockB
columns 2
B b
end
block:blockC
columns 2
C c
end
end
classDef str stroke:black,fill:orange
classDef str2 stroke:red,fill:yellow
class in,out str
class blockA,blockB,blockC str2
Vaak is dat niet wat we willen: stel dat we één lange stream van char-waarden (ints) willen maken, met daarin de karakters van alle woorden uit de oorspronkelijke stream na elkaar.
In dat geval gebruiken we flatMap (of, in dit geval, flatMapToInt omdat chars een IntStream teruggeeft):
block-beta
columns 1
block:in
Aa Bb Cc
end
arrow<["flatMap"]>(down)
block:out
columns 6
A a
B b
C c
end
classDef str stroke:black,fill:orange
class in,out str
flatMap maakt dus in zekere zin een combinatie van een gewone map-operatie (die telkens een stream teruggeeft voor elk element), gevolgd door een concatenatie van al die resulterende streams.
De naam komt van het feit dat de resulterende structuur een ‘flattened’ versie is, waarbij één niveau van nesting weggehaald werd: waar map een stream van streams oplevert (bv. Stream<IntStream>), krijgen we bij flatMap (of hier flatMapToInt) één gewone stream terug (hier een IntStream).
mapMulti
De mapMulti operatie kan je gebruiken wanneer elk object in de bronstream kan leiden tot meerdere objecten in de doelstream, net zoals bij flatMap.
In tegenstelling tot flatMap, waar de mapping-operatie een stream moet teruggeven, werkt mapMulti anders.
Je moet hier namelijk geen stream teruggeven.
Aan mapMulti geef je een BiConsumer mee; dat is een functie met 2 argumenten (we noemen die hier value en output):
Het eerste argument (value) is het element uit de bronstream waarvoor de overeenkomstige elementen in de doelstream bepaald moeten worden
Het tweede argument (output) is een Consumer-functie: elk element wat je daaraan doorgeeft (via de accept-methode), komt terecht in de doelstream.
De functie die meegegeven wordt aan mapMulti moet dus alle objecten bepalen die voor het gegeven bronobject (value) in de doelstream terecht moeten komen, en die één voor één doorgeven aan output.
Een voorbeeld maakt dit hopelijk wat duidelijker.
Stel dat we de lijst \( [1, 2, 3] \) willen omzetten in \( [1, 2, 2, 3, 3, 3] \): elk getal in de bronstream wordt even vaak als zijn waarde herhaald in de doelstream.
We zouden dat met flatMap kunnen doen, door telkens een stream te maken van het juiste aantal elementen.
Dat doen we hieronder door een oneindige stream te maken (via generate) van telkens hetzelfde element (value), en dan elk van die streams te beperken tot de eerste value elementen:
Dankzij de laziness van streams (zie later) moeten we niet bang zijn dat de oneindige stream zal leiden tot een oneindige uitvoeringstijd; het aantal elementen dat we gebruiken wordt beperkt door de limit-operatie, en er zullen er nooit meer dan dat gegenereerd worden.
De versie met mapMulti ziet er wat anders (en misschien vertrouwder) uit — hier kunnen we gewone imperatieve code (lussen) schrijven:
block-beta
columns 1
block:in
AA["1"] BB["2"] CC["3"]
end
arrow<["mapMulti"]>(down)
block:out
A1["1"]
B1["2"]
B2["2"]
C1["3"]
C2["3"]
C3["3"]
end
classDef str stroke:black,fill:orange
classDef aa stroke:black,fill:#afa
classDef cc stroke:black,fill:#aaf
class AA,A1 aa
class CC,C1,C2,C3 cc
class in,out str
Terminale (terminal) operaties
Een terminale operatie staat op het einde van de pijplijn, na alle tussentijdse operaties.
Na een terminale operatie kunnen dus geen extra operaties meer uitgevoerd worden met de elementen uit de stream.
De voorbeelden hierboven hadden geen terminale operaties.
Een stream zonder terminale operatie doet niets: er wordt geen enkel element verwerkt, en er wordt geen enkele tussentijdse operatie uitgevoerd.
Het is de terminale operatie die alle verwerking in gang zet.
De reden daarvoor is de laziness van streams.
Laziness (luiheid)
We zeiden eerder al dat streams lazy zijn.
Dat houdt in dat de gedefinieerde operaties niet uitgevoerd worden, tenzij het echt niet anders kan.
Bekijk bijvoorbeeld onderstaande code:
varlist=List.of(1,2,3,4,5,6,7,8,9,10);Stream<Integer>incrementAll=list.stream().peek(n->IO.println("Processing "+n)).map(n->n+1).limit(1);// [1] hier werd nog niets uitgeprintincrementAll.forEach(n->{IO.println("Got "+n);});//[2]print"Processing 1"envervolgens"Got 2"
We maken een lijst van 10 getallen, voeren map uit op een stream van die getallen, en beperken het resultaat tot het eerste element.
Aangekomen op punt [1] werd er, misschien verrassend, helemaal niets uitgeprint.
Dat betekent dat de lambda-functie die \( n \) met 1 verhoogt ook niet uitgevoerd werd: er gebeurde helemaal niets met de getallen uit de lijst.
We definiëren met streams enkel de pijplijn: wat moet er later eventueel gebeuren met de getallen?
Pas wanneer we op punt [2] komen, en de terminale operatie forEach (zie later) uitgevoerd werd, werd er voor de eerste keer “Processing 1” uitgeprint.
Maar dan enkel voor het eerste element: door de limit-operatie is er geen nood aan het verwerken van het tweede, derde, … element, dus dat gebeurt ook nooit.
De code hierboven verwerkt dus enkel het eerste element uit de lijst; met alle andere elementen wordt nooit iets gedaan.
Het is dus belangrijk om in het achterhoofd te houden dat stream-operaties enkel uitgevoerd worden wanneer dat noodzakelijk is, en pas op het allerlaatste moment (als gevolg van een terminale operatie).
Dat is efficiënt, maar kan soms leiden tot verrassende situaties (zoals hierboven).
We bekijken nu enkele vaak voorkomende terminale operaties.
toList, toArray
De terminale operatie toList maakt een nieuwe lijst met daarin de elementen op het einde van de pijplijn, in de volgorde dat ze daar toekomen.
Bijvoorbeeld:
Door de beperkingen van generics in Java (i.e., je mag niet new T[n] schrijven voor een generisch type T) kan er enkel een Object[] array gemaakt worden, geen String[].
Indien je dat wel wil, moet je een functie meegeven om een lege array van het juiste type en de juiste lengte aan te maken, bijvoorbeeld:
Zoals de naam aangeeft, telt de count()-operatie het aantal elementen op het einde van de stream.
Dat aantal wordt als een long teruggegeven, niet als int.
Bijvoorbeeld:
De operaties findFirst en findAny geven respectievelijk het eerste en een niet nader bepaald element terug uit de stream.
Merk op dat findAny niet ‘random’ is; er zijn gewoon geen garanties over welk element precies teruggegeven wordt.
findAny is vooral nuttig bij parallelle streams (zie later).
Het resultaat van beide methodes is een Optional; die is leeg wanneer de stream leeg is, er dus geen element is om terug te geven.
Deze methodes geven true of false terug, afhankelijk van of respectievelijk ten minste één, elk, of geen enkel element in de stream voldoet aan de meegegeven voorwaarde.
De min en max operaties vereisen een Comparator-object om elementen te vergelijken met elkaar.
Ze geven een Optional terug met het kleinste respectievelijk grootste element, of de lege optional indien de stream geen elementen bevat.
Bijvoorbeeld, onderstaande code geeft het element terug waarin de letter ‘a’ het vaakst voorkomt.
We maken dus een Comparator gebaseerd op het aantal a’s in het woord.
Om dat aantal te tellen, maken we opnieuw gebruik van een stream-pipeline, namelijk chars().filter().count():
Voor een IntStream, LongStream en DoubleStream hoef je geen Comparator mee te geven; daar worden uiteraard gewoon de getallen zelf vergeleken.
sum, average, summaryStatistics
De sum, average en summaryStatistics operaties zijn enkel beschikbaar op IntStream, LongStream en DoubleStream.
De eerste twee geven, weinig verrassend, de som en het gemiddelde van de waarden terug.
average geeft een OptionalDouble terug, omdat een lege stream geen gemiddelde heeft.
De summaryStatistics operatie geeft een object terug met daarin
het aantal waarden (count)
de kleinste waarde (min)
de gemiddelde waarde (average)
de grootste waarde (max)
de totale waarde (sum)
Indien je meer dan één van die resultaten zoekt, is het dus efficiënter om deze methode te gebruiken dan de afzonderlijke operaties (die elk een nieuwe stream moeten doorlopen).
De reduce-operatie is een zeer veelzijdige operatie.
Ze combineert alle elementen in de stream tot één nieuwe waarde (dit is dus bijna de definitie van een terminale operatie).
We beschouwen hier de versie van reduce met twee argumenten, die een resultaat teruggeeft van hetzelfde type als de elementen in de stream:
een startwaardeidentity van type T
een accumulator-functie accumulator (een BinaryOperator) die een vorige T combineert met de huidige T uit de stream, en de nieuwe T teruggeeft
Met andere woorden, de reduce-operatie op een stream heeft het volgende effect:
Een andere manier om hiernaar te kijken is dat de accumulator een bewerking is die ingevoegd wordt tussen alle elementen van de stream;
de linker-parameter van de accumulator is de waarde tot dan toe, en de rechterparameter de volgende waarde om mee in rekening te brengen.
Bijvoorbeeld, we kunnen de som van alle elementen ook berekenen via reduce in plaats van via sum:
Weetje: in sommige andere programmeertalen wordt reduce ook fold genoemd (en de Java-versie van reduce is meer specifiek foldLeft).
collect
De laatste terminale operatie die we bekijken is collect.
Deze is gelijkaardig aan reduce, maar laat toe om de set van terminale operaties uit te breiden via Collector-objecten.
Een Collector-object bevat 4 elementen:
een supplier-functie (type Supplier) die wordt gebruikt om een startwaarde (state) te verkrijgen, vergelijkbaar met de identity bij reduce
een accumulator-functie (type BiConsumer) die een nieuw data-element toevoegt aan het voorlopige resultaat (de state); vergelijkbaar met de accumulator van reduce
een combiner-functie (type BinaryOperator) die twee voorlopige resultaten kan combineren (vooral nuttig bij parallelle uitvoering; zie later)
een finisher-functie (type Function) die, op het einde, het voorlopige resultaat omzet naar het finale resultaat.
De supplier, accumulator, combiner en finisher werken conceptueel op de volgende manier:
Merk op dat, in tegenstelling tot de accumulator bij reduce, er bij die van een collector niets wordt teruggegeven; de verwachting is dat het tijdelijke resultaat zelf geüpdated wordt (en dus stateful is).
Info
De combiner is enkel nuttig indien er meerdere deelresultaten zijn.
Dat is enkel het geval als de invoer-stream in meerdere delen opgedeeld kan worden.
Gewoonlijk gebeurt dat enkel bij parallelle streams (zie later).
Een gewone (sequentiële) stream heeft geen combiner nodig.
We geven één voorbeeld van een Collector-implementatie, namelijk een collector die (voor een stream van Strings) de Strings aan elkaar plakt tot één lange String, gescheiden door komma’s.
De state van de collector is een object van de klasse JoiningState.
Die state houdt de tot dan toe aan elkaar geplakte string bij (current), alsook of het eerste element nog toegevoegd moet worden (first).
Java bevat reeds enkele handige voorgedefinieerde collectors.
Deze vind je in de Collectors-klasse. We bekijken er enkele.
Collectors.joining
Deze collector doet wat we hierboven zelf implementeerden: Strings aan elkaar plakken, gescheiden door een separator-string.
We hadden onszelf dus wat werk kunnen besparen, en gewoon het volgende schrijven:
Deze collectors doen wat de naam zegt: ze maken een List, Set, of Collection met daarin de elementen van de stream.
De toList terminale operatie die we eerder zagen lijkt op Collectors.toList(), maar er is een belangrijk verschil:
stream.toList() geeft gegarandeerd een unmodifiable lijst terug
collect(Collectors.toList()) geeft een lijst terug waarvan het concrete type niet gegarandeerd is; het kan dus aanpasbaar zijn of niet.
Bij toCollection ligt niet vast welk type collectie gemaakt moet worden; je moet zelf een functie meegeven (de collectionFacory) om een lege collectie van het gewenste type te maken:
Je kan ook een collector meegeven (de downstream collector) die bepaalt hoe de values geaggegregeerd worden in elke groep (als je die niet meegeeft wordt er een lijst gemaakt, zoals in het voorbeeld hierboven).
Deze downstream collector is een collector die de T’s in elke groep kan omzetten naar een resultaattype (V), om zo een Map<K, V> terug te geven.
Het resultaat hoeft dus niet hetzelfde type te hebben als de elementen in de oorspronkelijke stream.
Met andere woorden, groupingBy zet een stream van T’s om in meerdere streams, namelijk één stream per groep, en de downstream collector bepaalt hoe die streams verwerkt worden tot een eindresultaat.
Dat eindresultaat komt als value terecht in de resulterende map, met als key de waarde die bepaald werd door de eerste functie (de classifier).
We geven hier enkele voorbeelden van zo’n nuttige downstream collectors en hun gebruik in groupingBy.
Collectors.counting()
Deze collector telt simpelweg het aantal elementen.
Bijvoorbeeld:
Collectors.counting() is dan ook vooral handig in combinatie met groupingBy.
Bijvoorbeeld, als je het aantal woorden per lengte wil tellen in de stream, kan je dat doen via groupingBy met counting als downstream collector:
Deze functie groepeert dus eerst alle woorden volgens hun aantal letters (met het eerste argument String::length), en telt vervolgens per groep het aantal woorden (met het tweede argument Collectors.counting()).
Je krijgt dus een Map<Integer, Long> terug, waarbij de key de woordlengte is, en de value het aantal woorden met die lengte.
Een visualisatie van het proces (voor een ander voorbeeld) vind je in volgende afbeelding:
Hier wordt een stream van gekleurde Box-objecten gegroepeerd volgens hun kleur, en vervolgens per kleur het aantal Boxen geteld.
Collectors.summingInt, summingLong, summingDouble
Deze collector zet eerst elk element om naar een int volgens de meegegeven functie (dus equivalent aan een mapToInt) en telt deze vervolgens op.
Er zijn ook gelijkaardige collectors voor long en double.
Bijvoorbeeld, om het totaal aantal karakters te tellen van de woorden in een stream kunnen we summingInt als volgt gebruiken:
Het gebruik van summingInt als downstream collector bij groupingBy is ook mogelijk, en nuttiger.
We kunnen dit bijvoorbeeld gebruiken om het totaal aantal karakters te tellen van de woorden per beginletter:
Dus: de woorden die met een ‘a’ beginnen hebben samen 5 letters, en de woorden die met een ‘b’ beginnen hebben samen 12 letters.
Collectors.mapping
Deze collector past een functie toe op elk element, en verwerkt vervolgens de resultaten met een downstream collector.
Bijvoorbeeld, als we de woorden in hoofdletters willen hebben in plaats van kleine letters, kunnen dat doen via mapping:
Er zijn dus twee woorden die met ‘a’ beginnen, met respectievelijk 5 en 8 letters, één woord dat met ‘b’ begint en 5 letters heeft, en twee woorden die met ‘c’ beginnen, elk met 7 letters.
Collectors.flatMapping
Deze collector is gelijkaardig aan Collectors.mapping(), maar de functie die je meegeeft moet een stream teruggeven, en de resultaten van al die streams worden samengevoegd tot één stream.
Dat komt overeen met de flatMap-operatie, maar dan in de context van collectors.
Je geeft aan flatMapping dus een functie mee die één element uit de oorspronkelijke stream omzet naar een nieuwe stream, en ook een downstream collector die de elementen van die resulterende streams verwerkt.
Bijvoorbeeld, stel dat we een Stream<String> als bron hebben, en we willen een List<Character> terugkrijgen met alle karakters uit alle woorden, dan kunnen we dat als volgt doen:
mapToObj() is nodig omdat chars() een IntStream teruggeeft.
Die moet omgezet worden naar een Stream<Character>, omdat flatMapping een Stream<? extends Object> verwacht, en geen IntStream
Zonder mapToObj() zou de code niet compileren.
In combinatie met groupingBy kan dit bijvoorbeeld gebruikt worden om alle letters per woordlengte in een Set te groeperen:
Deze collector groepeert de elementen ook in een Map, maar nu met als key true of false, afhankelijk van of het object voldoet aan de meegegeven voorwaarde of niet:
Ook hier bestaan, net zoals bij groupingBy, varianten waarbij je een downstream collector kan meegeven om de values te aggregeren.
Bijvoorbeeld, als we het aantal korte en lange woorden willen tellen, kunnen we dat doen via partitioningBy met counting als downstream collector:
Met Collectors.toMap maak je een Map door twee argumenten mee te geven: een key-functie en value-functie.
De key-functie bepaalt de key voor elk element in de stream, en de value-functie bepaalt de waarde die aan die key gekoppeld wordt.
Let op: als twee elementen dezelfde key produceren, krijg je standaard een IllegalStateException.
Als duplicate keys mogelijk zijn, geef dan expliciet een merge-functie mee (als derde argument) die aangeeft hoe twee waarden gecombineerd moeten worden tot 1 waarde in de Map:
De forEach(fn) terminale operatie voert de meegegeven functie fn uit voor elk element dat het einde van de pijplijn bereikt.
Een heel eenvoudig gebruik hiervan is het uitprinten van alle elementen via IO.println:
De forEach-operatie is dus zowat het streams-equivalent van de enhanced for-loop (for (var x : collection)) bij collecties.
Opgelet
Vermijd het gebruik van forEach om een variabele/lijst/… buiten de forEach-lambda aan te passen, zoals het toevoegen aan de result-lijst in onderstaand voorbeeld.
Meestal is dit een antipattern, en is er een betere manier om hetzelfde resultaat te bekomen.
Vaak kunnen operaties in een stream efficiënt in parallel gebeuren.
Denk bijvoorbeeld aan map of filter: deze gebeuren element per element, en zijn dus onafhankelijk van wat er met de andere elementen gebeurt.
Je kan in Java daarom ook een parallelle stream aanmaken.
Deze zal, bij uitvoering, meerdere threads gebruiken om de stream te verwerken.
Het is eenvoudig om een stream parallel te maken: dat kan via de parallel() intermediate operatie, of de parallelStream()-operatie op collecties.
Er is ook een sequential() operatie die de stream sequentieel maakt.
Merk op dat de mode waarin de stream zich bevindt op het moment van de terminale operatie bepaalt hoe de hele stream uitgevoerd wordt; je kan dus geen deel van de operaties parallel en een ander deel sequentieel uitvoeren.
Parallelle streams zijn niet automatisch sneller: de overhead van het opsplitsen, schedulen en samenvoegen van deelresultaten kan groter zijn dan de winst.
Voor kleine datasets of goedkope bewerkingen is een sequentiële stream vaak efficiënter.
Meet dus altijd eerst voor je parallelle streams als optimalisatie inzet.
Nog meer streams? (optioneel)
Gatherers
Via de Collector-API kan je, zoals we gezien hebben, zelf al nieuwe collectors toevoegen.
Voor de tussentijdse operaties ben je via de streams API echter beperkt tot de voorgedefinieerde tussentijdse operaties; maar je kan er veel meer bedenken.
Onderstaande presentatie bespreekt Gatherers, de oplossing die sinds Java 24 aangeboden wordt om zelf nieuwe tussentijdse operaties te definiëren.
Gebruik dit enkel als je met Java 24 of nieuwer werkt; in Java 21 is Gatherer nog niet beschikbaar.
Spliterators
Streams (en parallelle streams in het bijzonder) maken gebruik van Spliterators.
Dat is een variant op een iterator, die (naast de elementen overlopen, zoals bij een gewone iterator) ook de elementen van een bron (bv. een collectie) in 2 delen kan splitsen.
Bij parallelle streams zal dan elk van die delen afzonderlijk (in een aparte thread) verwerkt worden.
Meer info over Spliterators vind je in onderstaande presentatie.
Omdat int maar een eindig aantal waarden kan hebben (de hoogste waarde is \( 2^{31}-1 \)), zal deze stream ooit negatieve getallen beginnen produceren: …, 2147483646, 2147483647, -2147483648, -2147483647, …. De stream is wel nog steeds oneindig. ↩︎
Subsecties van 7.6 Streams
Oefeningen
Alle oefeningen moeten opgelost worden zonder if-statements, zonder for- of while-lussen, en zonder extra variabelen.
Elke methode bevat slechts één return-statement met daarachter een streams-pipeline.
Gebruik waar mogelijk methode-referenties.
We werken met een dataset van personen, onderverdeeld in volwassenen en kinderen:
4. ★ Geef enkele statistieken (minimum, maximum, gemiddelde) van de leeftijd van alle volwassenen in de dataset die ten minste 30 jaar oud zijn.
Modeloplossing
7. ★★★ Geef een String met de 5 oudste volwassenen terug, in het formaat "voornaam achternaam leeftijd", gesorteerd volgens voornaam, 1 persoon per lijn.
Modeloplossing
18. ★★ Maak een Map<String, Long> die voor elke postcode het aantal volwassenen met die postcode bevat.
Hint: gebruik Collectors.counting() in combinatie met groupingBy
19. ★★★ Geef een alfabetisch gesorteerde lijst van alle achternamen van volwassenen die minstens 2 keer voorkomen in de lijst van volwassenen.
Modeloplossing
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
20. ★★ Zoek de jongste volwassene zonder kinderen.
Modeloplossing
22. ★★ Maak een Map<String, Long> met de frequentie van kind-voornamen (case-insensitive), bijvoorbeeld "alice" en "Alice" samen tellen.
Modeloplossing
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
24. ★★★★ Zoek alle volwassenen met een twee- of meerling (twee of meer van hun kinderen hebben dezelfde leeftijd).
Modeloplossing
Merk op dat .collect(...).values().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
25. ★★★★★ Maak een lijst van AvgAgeZip-objecten voor alle postcodes waar een volwassene met minstens één kind woont, gesorteerd volgens postcode.
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
26. ★★★ Schrijf, gebruik makend van streams, een generische methode mapAllValues(map, function) die op basis van de gegeven Map een nieuwe Map maakt waarbij alle values vervangen zijn door de gegeven functie erop toe te passen. Denk na over geschikte grenzen voor je generische parameters (PECS).
Modeloplossing
Wiskundig gezien zijn recursieve functies functies die zichzelf één of meerdere keren oproepen.
Een gekend voorbeeld is faculteit: \( n! = n \times (n-1)! \) met \( 0! = 1 \).
Bijvoorbeeld:
Een ander gekend voorbeeld zijn de Fibonacci-getallen \( 0, 1, 1, 2, 3, 5, 8, 13, 21, \ldots \), gegeven door volgende recursieve vergelijking:
\( F(n) = F(n-1) + F(n-2) \) met \( F(1) = 1 \) en \( F(0) = 0 \).
In Java kunnen we ook recursieve methodes definiëren.
Hier is bijvoorbeeld een recursieve methode om de faculteit van een getal te berekenen:
publicstaticintfac(intn){if(n<0)thrownewIllegalArgumentException("n must be non-negative");if(n==0)return1;returnn*fac(n-1);}
Merk op hoe dicht de implementatie aanleunt bij de wiskundige definitie.
Dat geldt ook voor de methode om het n-de Fibonacci-getal te berekenen:
publicstaticintfib(intn){if(n<0)thrownewIllegalArgumentException("n must be non-negative");if(n==0)return0;if(n==1)return1;returnfib(n-1)+fib(n-2);}
Merk op hoe de functie zichzelf tweemaal oproept.
De recursie eindigt wanneer een basisgeval bereikt wordt.
Dat is een situatie (meestal een zeer eenvoudige) waar het antwoord onmiddellijk gekend is, en geen recursieve oproep meer nodig is.
In bovenstaande code voor fib zijn de basisgevallen de oproepen waarin n kleiner is dan 2.
We zouden ook een versie kunnen maken met meer basisgevallen; op zich maakt dat (buiten een klein beetje efficiëntie-winst) weinig verschil.
publicstaticintfib_alt(intn){if(n<0)thrownewIllegalArgumentException("n must be non-negative");if(n==0)return0;if(n==1)return1;if(n==2)return1;if(n==3)return2;if(n==4)return3;if(n==5)return5;returnfib_alt(n-1)+fib_alt(n-2);}
Het belangrijkste bij een recursieve functie is dat de ketting van recursieve oproepen ooit eindigt.
Volgende recursieve definitie van Fibonacci zou dus niet goed zijn:
Wanneer we een recursieve functie uitvoeren, doet Java achter de schermen heel wat boekhouding voor ons.
Bekijk onderstaande illustratie die aangeeft wat er allemaal gebeurt om fib(5)=5 te berekenen:
De uitvoering van recursieve methodes maakt (net zoals de uitvoering van gewone methodes) gebruik van een stack.
We herschrijven fib lichtjes om de uitleg te vergemakkelijken:
publicstaticintfib(intn){if(n<0)thrownewIllegalArgumentException("n must be non-negative");if(n==0)return0;if(n==1)return1;intfib_n1=fib(n-1);intfib_n2=fib(n-2);intresult=fib_n1+fib_n2;returnresult;}
Elke methode-oproep voegt een stackframe toe; in dat stackframe worden de waarden van alle parameters (bv. n voor fib hierboven) en lokale variabelen (fib_n1, fib_n2, en result) bewaard.
Het bovenste stackframe is het actieve stackframe.
Wanneer de methode-oproep voltooid is (bijvoorbeeld na het uitvoeren van een return-statement) verdwijnt dat stackframe, en wordt het vorige stackframe terug geactiveerd.
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
classDef active stroke:#363,fill:#afa
class f5 active
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
classDef active stroke:#363,fill:#afa
class f4 active
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
f3["`**fib**
n=3
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
f4 --> f3
classDef active stroke:#363,fill:#afa
class f3 active
...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
f3["`**fib**
n=3
fib_n1=1
fib_n2=1
**result=2**`"]
main --> f5
f5 --> f4
f4 --> f3
classDef active stroke:#363,fill:#afa
class f3 active
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
**fib_n2=???**
result=???`"]
f3["`**fib**
n=3
fib_n1=1
fib_n2=1
result=2`"]
main --> f5
f5 --> f4
f4 ~~~ f3
classDef active stroke:#363,fill:#afa;
classDef removed stroke:#aaa,fill:#ddd,color:#aaa;
class f4 active
class f3 removed
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
**fib_n2=???**
result=???`"]
f2["`**fib**
n=2
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
f4 --> f2
classDef active stroke:#363,fill:#afa
class f2 active
...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
fib_n2=1
**result=3**`"]
main --> f5
f5 --> f4
classDef active stroke:#363,fill:#afa
class f4 active
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f4["`**fib**
n=4
fib_n1=2
fib_n2=1
result=3`"]
f5["`**fib**
n=5
fib_n1=3
**fib_n2=???**
result=???`"]
main --> f5
f5 ~~~ f4
classDef active stroke:#363,fill:#afa
classDef removed stroke:#aaa,fill:#ddd,color:#aaa;
class f5 active
class f4 removed
...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
fib_n1=3
fib_n2=2
**result=5**`"]
main --> f5
classDef active stroke:#363,fill:#afa
class f5 active
Stack overflow
Zoals je hierboven kan zien, groeit de stack bij elke recursieve oproep.
Elke stack-frame neemt een bepaalde hoeveelheid geheugen in.
De totale grootte van de stack is echter beperkt.
Wanneer de stack te groot wordt, krijg je een stack overflow.
In Java uit zich dat door het gooien van een StackOverflowException.
Je kan de grootte die gereserveerd wordt voor de stack vergroten door bij de uitvoering een argument (-Xss) mee te geven aan de Java virtual machine (JVM).
Bijvoorbeeld, om een stack van 4 megabyte te voorzien (de standaardgrootte is gewoonlijk 1 MB):
java -Xss4m Program
In IntelliJ kan je die optie toevoegen in de ‘Run configuration’.
Gewoonlijk zal dat niet nodig zijn; enkel wanneer je gebruik maakt van recursie voor grotere problemen.
Een meer waarschijnlijke oorzaak van een StackOverflowException is een recursieve operatie die niet eindigt in een basisgeval.
Eindigheid en invoergrootte
Indien een recursieve methode niet zorgvuldig gedefinieerd wordt, bestaat de kans dat de recursie nooit stopt, en de methode dus nooit eindigt (tenzij met een StackOverflowException).
Bijvoorbeeld, onderstaande recursieve methode bad
eindigt enkel voor positieve even getallen (overtuig jezelf hiervan).
Om er zeker van te zijn dat een recursieve methode ooit zal eindigen, moeten we kunnen aantonen dat elke recursieve oproep ooit een basisgeval zal bereiken.
Dat is niet altijd eenvoudig of mogelijk.
Neem bijvoorbeeld volgende welgekende functie van Collatz, gedefinieerd voor \( n \geq 1 \):
publicstaticbooleancollatz(intn){if(n==1){returntrue;}elseif(n%2==0){// n is evenreturncollatz(n/2);}else{// n is oneven > 1returncollatz(3*n+1);}}
Wanneer we die uitvoeren voor n=5 krijgen we als waarden voor n achtereenvolgens 5, 16, 8, 4, 2, 1 en eindigt de recursie dus na 6 oproepen.
Voor n=12 krijgen we 12, 6, 3, 10, 5, 16, 8, 4, 2, 1, en voor n=19 krijgen we 19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1.
De reeks waarden in deze voorbeelden lijkt dus steeds te eindigen op n=1, maar is dit zo voor elke beginwaarde van n?
Er zijn geen gekende tegenvoorbeelden, maar er is ook geen bewijs dat dit het geval is voor elke beginwaarde van n.
Bewijzen dat een recursieve functie eindigt is echter wel vanzelfsprekend als elke recursieve oproep de grootte van de invoer strikt kleiner maakt, en de basisgevallen overeenkomen met de kleinst mogelijke invoergrootte(s).
Aangezien een invoergrootte steeds (per definitie) een niet-negatief getal moet zijn, moet een voortdurende verkleining ervan ooit stoppen.
Typische invoergroottes bij recursieve problemen zijn
de waarde van een parameter, indien dit een natuurlijk getal is (bijvoorbeeld n in fib hierboven)
het aantal elementen in een datastructuur (lijst, set, …) die gebruikt wordt.
Maakt de collatz-methode de invoer steeds strikt kleiner?
Recursief denken
Recursie biedt vaak een erg krachtige manier om complexe algoritmische problemen op te lossen.
Je moet hiervoor wel op de juiste manier redeneren over recursie.
Een grote valkuil is nadenken over de volledige uitvoeringsboom, zoals we hierboven getoond hebben voor de Fibonacci-functie.
De complexiteit hiervan is gigantisch, en staat een elegante oplossing en helder redeneren in de weg.
Een betere manier om na te denken over recursie gaat als volgt.
Je wil een probleem van een bepaalde grootte \( n \) oplossen.
Stel nu dat je mag veronderstellen dat je (magischerwijze) datzelfde probleem al kan oplossen, maar dan alleen voor alle (strikt kleinere) groottes \( n’ < n \).
Hoe kan dit je helpen om het volledige probleem op te lossen?
Met andere woorden, welke manieren zie je om een oplossing van een deel van het probleem te transformeren in een oplossing voor het hele probleem?
Of nog anders gezegd: recursie gaat om vertrouwen: vertrouw erop dat het kleinere probleem juist opgelost wordt, en besteed enkel aandacht aan hoe je de oplossing voor een kleiner probleem kan gebruiken om de oplossing voor het grotere probleem te vinden.
Eens je deze denkwijze onder de knie hebt, wordt recursie bijna een magisch stuk gereedschap.
We bekijken twee voorbeelden van deze denkwijze.
Voorbeeld 1: grootste element
Veronderstel dat je het grootste element uit een lijst van getallen wil bepalen (vergeet even dat we dat ook makkelijk kunnen met behulp van een lus).
We noemen de lengte van die lijst \( n \).
Stel nu dat we reeds beschikken over een magische oplossing (een functie) om het grootste element te vinden in alle lijsten met een lengte tot en met \( n-1 \).
Hoe kunnen we deze oplossing gebruiken om het probleem op te lossen voor een lijst van lengte \( n \)?
Denk hier even zelf over na!
Er zijn verschillende mogelijkheden.
We weten bijvoorbeeld dat het grootste element ofwel het eerste element is, ofwel voorkomt in de rest van de lijst (alle elementen behalve het eerste).
We kunnen onze magische functie dus gebruiken om het grootste element uit de rest van de lijst te zoeken, en dat vervolgens te vergelijken met het eerste.
Dat leidt tot volgende recursieve implementatie:
De basisgevallen hier zijn een lege lijst (er is dan geen grootste element) en een lijst met slechts één element (dat ene element moet het grootste element zijn).
Merk op hoe we een subList gebruiken om makkelijk een kleinere lijst (zonder het element op index 0) te creëren voor de recursieve oproep.
Zoals je je misschien herinnert, is het resultaat van subList een view op de originele lijst — er worden geen elementen gekopieerd.
Dat is dus zeer efficiënt.
Er waren ook andere oplossingsstrategieën mogelijk met een gelijkaardige denkwijze.
Bijvoorbeeld, we hadden het laatste element kunnen afzonderen in plaats van het eerste.
Of we hadden het maximum van de eerste helft van de elementen kunnen vergelijken met het maximum van de tweede helft:
Recursief denken lijkt voor dit voorbeeld misschien wat overbodig.
Het maximum zoeken kan je inderdaad ook heel eenvoudig iteratief (met een for-lus).
Daarom volgt een tweede voorbeeld, waar een iteratieve oplossing niet voor de hand ligt.
Voorbeeld 2: Toren van Hanoi
Je kent misschien de puzzel van de toren van Hanoi.
We hebben drie stapels (A, B, en C), en op elke stapel mogen schijven liggen, van groot (onderaan) naar klein (bovenaan).
De puzzel bestaat eruit om alle schijven van één stapel naar een andere te verplaatsen.
Daarbij zijn er twee regels:
Je mag slechts 1 schijf per keer verplaatsen.
Een schijf mag nooit op een kleinere schijf terecht komen.
Hoe moeilijk/lang verwacht je dat een algoritme wordt om deze puzzel op te lossen?
Dit probleem wordt heel eenvoudig als we recursief denken.
We moeten \( n \) schijven verplaatsen van een bronstapel (bijvoorbeeld A) naar een doelstapel (bijvoorbeeld C), en we hebben een extra stapel (B) die we als hulpstapel kunnen gebruiken.
We vertrouwen er bovendien op dat we een magische oplossing (recursie!) hebben om \( n-1 \) (of minder) schijven te verplaatsen van een willekeurige stapel naar een andere willekeurige stapel, volgens de regels van de puzzel.
Hoe kunnen we die magische oplossing gebruiken om het hele probleem op te lossen?
Denk hier zelf even over na!
We kunnen eerst de bovenste \( n-1 \) schijven verplaatsen van stapel A naar stapel B (de hulpstapel).
De laatste overblijvende schijf op stapel A (de grootste schijf) verplaatsen we nu naar doelstapel C.
Tenslotte verplaatsen we de \( n-1\) schijven van hulpstapel B ook naar doelstapel C (opnieuw via onze magische oplossing).
Het basisgeval is heel eenvoudig: indien we 0 schijven moeten verplaatsen, doen we niets.
Dat geeft volgende oplossing in code, met n het aantal schijven en from, to, en helper de namen van de stapels, (bijvoorbeeld “A”, “B”, en “C”, of “links”, “midden”, en “rechts”):
publicstaticvoidhanoi(intn,Stringfrom,Stringto,Stringhelper){if(n<=0)return;hanoi(n-1,from,helper,to);// verplaats n-1 schijven van `from` naar `helper`, met `to` als hulpstapelSystem.out.println("Verplaats de bovenste schijf van stapel "+from+" naar stapel "+to);hanoi(n-1,helper,to,from);// verplaats n-1 schijven van `helper` naar `to`, met `from` als hulpstapel}
Erg kort en elegant, niet?
Als we deze oplossing uitvoeren voor n=4 en from="A", to="C", en helper="B", krijgen we volgende uitvoer:
Verplaats de bovenste schijf van stapel A naar stapel B
Verplaats de bovenste schijf van stapel A naar stapel C
Verplaats de bovenste schijf van stapel B naar stapel C
Verplaats de bovenste schijf van stapel A naar stapel B
Verplaats de bovenste schijf van stapel C naar stapel A
Verplaats de bovenste schijf van stapel C naar stapel B
Verplaats de bovenste schijf van stapel A naar stapel B
Verplaats de bovenste schijf van stapel A naar stapel C
Verplaats de bovenste schijf van stapel B naar stapel C
Verplaats de bovenste schijf van stapel B naar stapel A
Verplaats de bovenste schijf van stapel C naar stapel A
Verplaats de bovenste schijf van stapel B naar stapel C
Verplaats de bovenste schijf van stapel A naar stapel B
Verplaats de bovenste schijf van stapel A naar stapel C
Verplaats de bovenste schijf van stapel B naar stapel C
Ga na dat dit een correcte oplossing is voor het probleem, bijvoorbeeld via deze simulator.
Ter illustratie: de volledige uitvoeringsboom die bij bovenstaande uitvoer hoort ziet er als volgt uit; je leest de oplossing van boven naar onder af in de groene nodes.
Het spreekt hopelijk voor zich dat denken over recursie in termen van zo’n bijhorende uitvoeringsboom niet de makkelijkste of duidelijkste manier is.
graph LR
H4ACB["1: hanoi(4,A,C,B)"]
H4ACBH3ABC["2: hanoi(3,A,B,C)"]
H4ACBH3ABCH2ACB["3: hanoi(2,A,C,B)"]
H4ACBH3ABCH2ACBH1ABC["4: hanoi(1,A,B,C)"]
H4ACBH3ABCH2ACBH1ABCH0ACB["5: hanoi(0,A,C,B)"]
H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCH0ACB
H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCm["6: Move A to B"]:::move
H4ACBH3ABCH2ACBH1ABCH0CBA["7: hanoi(0,C,B,A)"]
H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCH0CBA
H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBH1ABC
H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBm["8: Move A to C"]:::move
H4ACBH3ABCH2ACBH1BCA["9: hanoi(1,B,C,A)"]
H4ACBH3ABCH2ACBH1BCAH0BAC["10: hanoi(0,B,A,C)"]
H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAH0BAC
H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAm["11: Move B to C"]:::move
H4ACBH3ABCH2ACBH1BCAH0ACB["12: hanoi(0,A,C,B)"]
H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAH0ACB
H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBH1BCA
H4ACBH3ABC --> H4ACBH3ABCH2ACB
H4ACBH3ABC --> H4ACBH3ABCm["13: Move A to B"]:::move
H4ACBH3ABCH2CBA["14: hanoi(2,C,B,A)"]
H4ACBH3ABCH2CBAH1CAB["15: hanoi(1,C,A,B)"]
H4ACBH3ABCH2CBAH1CABH0CBA["16: hanoi(0,C,B,A)"]
H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABH0CBA
H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABm["17: Move C to A"]:::move
H4ACBH3ABCH2CBAH1CABH0BAC["18: hanoi(0,B,A,C)"]
H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABH0BAC
H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAH1CAB
H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAm["19: Move C to B"]:::move
H4ACBH3ABCH2CBAH1ABC["20: hanoi(1,A,B,C)"]
H4ACBH3ABCH2CBAH1ABCH0ACB["21: hanoi(0,A,C,B)"]
H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCH0ACB
H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCm["22: Move A to B"]:::move
H4ACBH3ABCH2CBAH1ABCH0CBA["23: hanoi(0,C,B,A)"]
H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCH0CBA
H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAH1ABC
H4ACBH3ABC --> H4ACBH3ABCH2CBA
H4ACB --> H4ACBH3ABC
H4ACB --> H4ACBm["24: Move A to C"]:::move
H4ACBH3BCA["25: hanoi(3,B,C,A)"]
H4ACBH3BCAH2BAC["26: hanoi(2,B,A,C)"]
H4ACBH3BCAH2BACH1BCA["27: hanoi(1,B,C,A)"]
H4ACBH3BCAH2BACH1BCAH0BAC["28: hanoi(0,B,A,C)"]
H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAH0BAC
H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAm["29: Move B to C"]:::move
H4ACBH3BCAH2BACH1BCAH0ACB["30: hanoi(0,A,C,B)"]
H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAH0ACB
H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACH1BCA
H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACm["31: Move B to A"]:::move
H4ACBH3BCAH2BACH1CAB["32: hanoi(1,C,A,B)"]
H4ACBH3BCAH2BACH1CABH0CBA["33: hanoi(0,C,B,A)"]
H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABH0CBA
H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABm["34: Move C to A"]:::move
H4ACBH3BCAH2BACH1CABH0BAC["35: hanoi(0,B,A,C)"]
H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABH0BAC
H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACH1CAB
H4ACBH3BCA --> H4ACBH3BCAH2BAC
H4ACBH3BCA --> H4ACBH3BCAm["36: Move B to C"]:::move
H4ACBH3BCAH2ACB["37: hanoi(2,A,C,B)"]
H4ACBH3BCAH2ACBH1ABC["38: hanoi(1,A,B,C)"]
H4ACBH3BCAH2ACBH1ABCH0ACB["39: hanoi(0,A,C,B)"]
H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCH0ACB
H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCm["40: Move A to B"]:::move
H4ACBH3BCAH2ACBH1ABCH0CBA["41: hanoi(0,C,B,A)"]
H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCH0CBA
H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBH1ABC
H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBm["42: Move A to C"]:::move
H4ACBH3BCAH2ACBH1BCA["43: hanoi(1,B,C,A)"]
H4ACBH3BCAH2ACBH1BCAH0BAC["44: hanoi(0,B,A,C)"]
H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAH0BAC
H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAm["45: Move B to C"]:::move
H4ACBH3BCAH2ACBH1BCAH0ACB["46: hanoi(0,A,C,B)"]
H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAH0ACB
H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBH1BCA
H4ACBH3BCA --> H4ACBH3BCAH2ACB
H4ACB --> H4ACBH3BCA
classDef move stroke:green,fill:#afa
Recursie vs. iteratie
In sommige gevallen kan je een for- of while-lus eenvoudig herschrijven tot een recursieve methode en omgekeerd.
Die omzetting volgt vaak eenzelfde patroon. Gegeven volgende while- of for-lus (in pseudocode):
Bijvoorbeeld, de iteratieve versie om faculteit te berekenen met een for-lus ziet er als volgt uit:
publicintfactorial(intn){if(n<0)thrownewIllegalArgumentException("n must be positive");intresult=1;for(intx=n;x>0;x--){result*=x;}returnresult;}
En de bijhorende recursieve versie (volgens bovenstaand schema):
publicintfactorial(intn){if(n<0)thrownewIllegalArgumentException("n must be positive");returnfactorial_worker(n,1);}privateintfactorial_worker(intx,intresult){if(x<=0)returnresult;result*=x;x--;returnfactorial_worker(x,result);}
De factorial_worker methode kunnen we ook nog wat korter schrijven:
publicintfactorial(intn){if(n<0)thrownewIllegalArgumentException("n must be positive");returnfactorial_worker(n,1);}privateintfactorial_worker(intn,intresult){if(n==0)returnresult;returnfactorial_worker(n-1,n*result);}
Deze recursieve oplossing bestaat uit 2 methodes; je herinnert je misschien nog dat de fac-methode aan het begin van deze pagina uit slechts 1 recursieve methode bestond:
publicstaticintfac(intn){if(n<0)thrownewIllegalArgumentException("n must be non-negative");if(n==0)return1;returnn*fac(n-1);}
Het verschil is dat we bij factorial gebruik maakten van het worker-wrapper patroon voor recursie.
Dat patroon zie je vaak opduiken.
De recursieve factorial_worker-methode (met 2 parameters) is de worker (daar gebeurt het eigenlijke werk), en de (niet-recursieve) factorial-methode met 1 parameter is de wrapper (die roept enkel de worker op met beginwaarden voor de extra parameters).
Hulpvariabelen (hier het voorlopige resultaat, namelijk result) worden doorgegeven als parameters van de worker-methode.
Die parameter wordt ook vaak de ‘accumulator’ genoemd, aangezien die het resultaat bijhoudt van al het werk dat tot dan toe gebeurd is.
De factorial_worker-methode is ook tail-recursive.
Dat betekent dat de recursieve oproep de laatste bewerking is die gebeurt voor de functie eindigt (ze staat direct achter de ‘return’).
In sommige programmeertalen (maar niet in Java) worden dergelijke tail-recursive oproepen geoptimaliseerd door de compiler: aangezien er geen werk meer uitgevoerd moet worden na de recursieve oproep, kan het stackframe meteen ook verwijderd worden. Je loopt dan geen risico op een stack overflow door teveel recursieve oproepen.
Tail-recursie (maar dan in C++) zal in meer detail behandeld worden in het vak Algoritmen en datastructuren.
Efficiëntie
Wie goed kijkt naar de uitvoeringsboom van fib(5) hierboven kan zien dat er delen van de boom zijn die terugkeren.
Bijvoorbeeld, fib(3) wordt tweemaal opnieuw berekend, fib(2) driemaal, en fib(1) komt vijfmaal voor.
Dat is natuurlijk niet erg efficiënt.
Technieken zoals ‘dynamisch programmeren’ (dynamic programming) en memoization kunnen hier soelaas bieden.
We gebruiken deze technieken niet verder binnen deze cursus, maar deze komen later wel aan bod binnen het opleidingsonderdeel Algoritmen en datastructuren.
Patronen om het probleem te verkleinen
Zoals eerder gezegd, gaan we bij recursie kijken of/hoe de oplossing voor hetzelfde maar kleiner probleem ons kan helpen om het volledige probleem op te lossen.
Er zijn enkele vaak voorkomende manieren om dat te doen, die we hier kort oplijsten.
Alle manieren komen in essentie natuurlijk op hetzelfde neer: een geschikt deelprobleem zoeken dat je helpt om het volledige probleem op te lossen.
Een numerieke parameter rechtstreeks verkleinen. Bijvoorbeeld, de oplossing voor parameter x berekenen aan de hand van de oplossing voor x-1, x-2, x/2, …
Het eerste/laatste element van de invoer weglaten. Bijvoorbeeld, de oplossing voor de hele invoerlijst lst berekenen aan de hand van de oplossing voor de invoerlijst maar dan zonder het eerste of laatste element (bv. lst.subList(1, lst.size()))). Hetzelfde idee kan je toepassen op Strings (met substring).
De invoer halveren. Bijvoorbeeld, de oplossing voor de hele lijst lst berekenen aan de hand van de oplossing voor de eerste en tweede helft van de invoerlijst (bv. lst.subList(0, lst.size()/2)). Ook dit idee kan toegepast worden op Strings (met substring).
Twee situaties beschouwen. Dit is een variant van het weglaten van het eerste/laatste element die vooral handig is bij problemen waar de oplossing gevormd wordt met een combinatie van sommige invoerelementen. Je beschouwt dan twee deelproblemen:
je zoekt eerst naar een oplossing waarbij je ervan uitgaat dat het eerste (of laatste, middelste, …) element deel uitmaakt van de oplossing.
Daarnaast zoek je ook naar een oplossing waarbij je ervan uitgaat dat dat element geen deel uitmaakt van de oplossing.
Voor elk van die twee situaties los je dan een kleiner (en waarschijnlijk aangepast) probleem op waarbij je verder geen rekening meer houdt met dat ene element. Achteraf combineer je de oplossingen voor beide deelproblemen op een gepaste manier. Zie de oefeningen voor concrete voorbeelden (in het bijzonder de oefening over gepast betalen).
Recursie: oefeningen
Je vind tests en skelet-code voor de oefeningen rond recursie op Github:
Schrijf een recursieve functie isPalindrome die nagaat of een String een palindroom is.
Een String is een palindroom als die hetzelfde is van links naar rechts als van rechts naar links, bijvoorbeeld
racecar
level
deified
lepel
droomoord
redder
meetsysteem
koortsmeetsysteemstrook
String omkeren
Schrijf een recursieve methode reverse om een String om te keren, bijvoorbeeld:
Hello -> olleH
racecar -> racecar
Element zoeken in lijst
Schrijf een recursieve functie <T> int search(List<T> list, T element) die nagaat of het gegeven element voorkomt in de gegeven lijst.
Als het element voorkomt, wordt de index teruggegeven, anders -1.
Maak eerst een versie die werkt voor een willekeurige (niet-gesorteerde) lijst.
Maar vervolgens een snellere versie die werkt voor een gesorteerde lijst, door het te doorzoeken stuk van de lijst telkens halveert en slechts in één van die helften verder gaat zoeken. (Dit is ‘binary search’)
Duplicaten verwijderen
Schrijf een recursieve methode removeDuplicateCharacters die opeenvolgende dezelfde karakters uit een String verwijdert.
Bijvoorbeeld:
aaaaa -> a
koortsmeetsysteemstrook -> kortsmetsystemstrok
AAAbbCdddAAA -> AbCdA
Trap beklimmen
Schrijf een functie om te berekenen hoeveel verschillende manieren er zijn om een trap met \( n \) treden op te gaan, als je bij elke stap kan kiezen om 1 of 2 treden tegelijk te nemen.
Bijvoorbeeld, een trap met \( n = 4 \) treden kan je op 5 verschillende manieren beklimmen:
1 trede, 1 trede, 1 trede, 1 trede
1 trede, 1 trede, 2 treden
1 trede, 2 treden, 1 trede
2 treden, 1 trede, 1 trede
2 treden, 2 treden
Alle permutaties van een lijst berekenen
Schrijf een functie allPermutations die een Set teruggeeft met alle permutaties van een gegeven lijst.
Bijvoorbeeld:
Schrijf een recursieve methode boolean kanGepastBetalen(int bedrag, List<Integer> munten) die nagaat of je het gegeven bedrag (uitgedrukt in eurocent) gepast kan betalen met (een deel van) de gegeven munten (en briefjes). Elke munt in de lijst mag slechts één keer gebruikt worden.
Bijvoorbeeld:
kanGepastBetalen(260, List.of(100, 100, 50, 20, 5 )) geeft false terug: er is geen combinatie van munten die samen 260 geeft.
Gepast betalen (bis)
Gegeven een lijst van muntwaarden (bv. 5, 10, 20, 50, 100, 200), schrijf een recursieve methode int countChange(int amount, List<Integer> coinValues) die bepaal op hoeveel manieren je een specifiek bedrag kan betalen.
Je mag nu veronderstellen dat je een voldoende aantal (of oneindig veel) munten van elke opgegeven waarde hebt.
Met andere woorden, je mag een munt(waarde) meerdere keren gebruiken.
Bijvoorbeeld, met bovenstaande muntwaarden
countChange(35, List.of(5, 10, 20, 50, 100, 200)) == 6:
je kan een bedrag van 35 betalen op 6 manieren:
7×5
1×10 en 5×5
1×10 en 1×20 en 1×5
2×10 en 3×5
3×10 en 1×5
1×20 en 3×5
countChange(260, List.of(5, 10, 20, 50, 100, 200)) == 646: je kan een bedrag van 260 betalen op 646 manieren
countChange(1000, List.of(5, 10, 20, 50, 100, 200)) == 98411: je kan een bedrag van 1000 betalen op 98411 manieren
Alle prefixen van een String
Schrijf een recursieve functie allPrefixes die een Set teruggeeft met alle prefixen van een gegeven String.
Bijvoorbeeld:
Schrijf een recursieve functie allInterleavings(String s1, String s2) die een Set teruggeeft met alle interleavings van de twee strings s1 en s2.
Een interleaving is een nieuwe string met daarin alle karakters van de eerste en de tweede string, in dezelfde volgorde waarin ze in elk van de originele strings voorkomen, maar mogelijk afwisselend.
Bijvoorbeeld:
Schrijf een recursieve methode int sumOfDigits(long number) die de som van de cijfers van een (niet-negatief) getal berekent, en dat herhaalt tot die som kleiner is dan 10.
Bijvoorbeeld: 62984 geeft 6+2+9+8+4 = 29; dat wordt vervolgens 2+9 = 11; en dat wordt uiteindelijk 1+1 = 2.
Het resultaat is dus 2.
Vliegtuigreis
Gegeven een record Item:
recordItem(Stringname,intweight,intvalue){}
wat een item voorstelt dat je mee wil nemen op reis. Het item heeft een naam, een gewicht (> 0), en een waarde (hoe graag je het mee wil, > 0).
Schrijf een methode List<Item> pack(List<Item> choices, int maxWeight) die een keuze maakt uit de gegeven lijst van items, zodanig dat de items met een zo groot mogelijke totaalwaarde kan meenemen zonder dat het totale gewicht hoger wordt dan het maximumgewicht (opgelegd door de vliegtuigmaatschappij).
Bijvoorbeeld, met vier items (A, 50kg, 10), (B, 20kg, 5), (C, 10kg, 2), en (D, 5kg, 1):
met een totaal toegelaten gewicht van 100kg kan je alle items meenemen, voor een totale waarde van 18;
met een totaal toegelaten gewicht van 60kg kan je best items A en C meenemen, voor een totale waarde van 12;
met een totaal toegelaten gewicht van 20kg kan je best item B meenemen, voor een totale waarde van 5;
Powerset
Schrijf een recursieve functie Set<Set<T>> powerset(Set<T> s) die de powerset berekent van de gegeven set s.
De powerset is de set van alle deelverzamelingen van s.
Bijvoorbeeld:
Schrijf met behulp van recursie een methode boolean balancedParentheses(String s) die nagaat of alle haakjes in de gegeven string gebalanceerd zijn.
Bijvoorbeeld:
() geeft true terug
()) geeft false terug
()() geeft true terug
)( geeft false terug
(( geeft false terug
abc(def(xy))z geeft true terug
a(bc(def(xy))z geeft false terug
Hint
Je eerste intuïtie, namelijk ‘is deze string gebalanceerd’ als deelprobleem voor kleinere strings gebruiken, zal je niet verder helpen.
Probeer een andere (gerelateerde) vraag te vinden die wél nuttig kan zijn om het probleem recursief op te lossen.
Gebruik ook het worker-wrapper-patroon.
Longest common subsequence
Schrijf een recursieve methode String longestCommonSubsequence(String s1, String s2) die de langste reeks karakters teruggeeft die in beide strings in dezelfde volgorde terugkomen (niet noodzakelijk aaneensluitend). Als er meerdere oplossingen zijn, maakt het niet uit welke je teruggeeft.
Bijvoorbeeld:
longestCommonSubsequence("gitaarsnaar", "imaginair") == "ginar" of "ianar":
longestCommonSubsequence("sterrenstelselsamenstellingsanalyseinstrument", "restaurantkeukenapparatuurontwerpmethodiek") == "restantenaantrmet" (met dank aan ChatGPT voor de suggestie):
sterrenstelselsamenstellingsanalyseinstrument
en
restaurantkeukenapparatuurontwerpmethodiek
Het laatste voorbeeld zal waarschijnlijk veel te lang duren. Je kan nadenken of je je algoritme wat ‘slimmer’ kan maken.
Stack omkeren
Schrijf een recursieve methode <T> void reverse(Deque<T> stack) die de volgorde van de items in een stack (Deque) omdraait, zonder gebruik te maken van een extra datastructuur (dus zonder een andere array, lijst, set, …).
Maak enkel gebruik van de isEmpty()-, pollFirst() en addFirst()-methodes van de Deque-interface.
varstack=newLinkedList<>(List.of("A","B","C","D","E","F"));System.out.println(stack);// [A, B, C, D, E, F]reverse(stack);System.out.println(stack);//[F,E,D,C,B,A]
Hint
Zou een (recursieve) hulpoperatie om een element onderaan de stack in te voegen nuttig kunnen zijn?
Denkvraag: ondanks dat je geen extra datastructuur mag gebruiken in je oplossing, wordt er toch een vorm van extra opslag gebruikt om de stack te kunnen omkeren. Waar bevindt die opslag zich?
Toren van Hanoi (uitbreiding)
Los de toren van Hanoi op voor \( n\) schijven op 4 stapels (dus 2 hulpstapels).
Je kan je oplossing manueel uittesten via deze simulator.
(In de simulator moet je klikken, niet slepen)
Sorteren van een lijst
Schrijf een recursieve methode om een lijst van getallen te sorteren. De sortering moet in-place gebeuren (je past de lijst zelf aan door elementen van volgorde te wisselen, en geeft dus geen nieuwe lijst terug).
reduce
Schrijf een recursieve reduce-operatie die werkt op een lijst, naar analogie met de reduce-operatie op streams.
In deze oefening maken we gebruik van een boomstructuur. Deze structuur zal in het vak rond algoritmen en datastructuren een belangrijke rol spelen en daar dan ook uitgebreid aan bod komen. We gebruiken deze hier enkel als voorbeeld.
Gegeven onderstaande record om een boomstructuur op te bouwen:
Schrijf een recursieve methode int treeSize(TreeNode<?> tree) om het totale aantal knopen in de boom te berekenen. Voor de boom hierboven is de grootte 6.
Schrijf een recursieve methode int treeHeight(TreeNode<?> tree) om de hoogte van de boom te berekenen. De hoogte is het maximum aantal stappen van de wortel (“A” hierboven) tot een kind (“C”, “D”, of “F”). In het voorbeeld is de hoogte dus 2.
Schrijf een recursieve methode <T> void visitDepthFirstPreOrder(TreeNode<T> tree, Consumer<T> consumer) die de elementen van de boom overloopt in depth-first, pre-order volgorde. Dat houdt in: eerst de huidige knoop, dan de knopen van de linkertak (opnieuw in depth-first pre-order volgorde) en daarna die van de rechtertak. Voor de boom hierboven worden dus achtereenvolgens knopen “A”, “B”, “C”, “D”, “E”, en “F” bezocht en doorgegeven aan de consumer. Een voorbeeld van het gebruik van de methode om de knopen uit te printen:
Schrijf een recursieve methode <T> void visitDepthFirstInOrder(TreeNode<T> tree, Consumer<T> consumer) die de elementen van de boom overloopt in depth-first, in-order volgorde. Dat houdt in: eerst de linkertak (in depth-first in-order volgorde), dan de knoop zelf, dan de rechtertak. Voor de boom hierboven worden dus achtereenvolgens knopen “C”, “B”, “D”, “A”, “F”, en “E” bezocht en doorgegeven aan de consumer.
Schrijf een recursieve methode <T> TreeNode<T> mirrorTree(TreeNode<T> tree) om een willekeurige boom te spiegelen: het resultaat moet een nieuwe boom zijn, waar de linker-takken de rechtertakken geworden zijn en omgekeerd.
De gespiegelde versie van de boom hierboven is dus:
(extra) Schrijf een methode String prettyPrint(TreeNode<?> tree) die een ASCII-voorstelling van de boom maakt.
De voorbeeldboom wordt bijvoorbeeld:
Backtracking is een techniek om oplossingen te vinden voor zoekproblemen.
Een eenvoudig voorbeeld waar je backtracking kan toepassen is de weg zoeken in een doolhof: op elke splitsing waar je kan kiezen welke richting je uitgaat, maak je een keuze.
Als die keuze niet leidde tot een oplossing, keer je terug naar die splitsing en probeer je een van de andere richtingen.
Meer algemeen werkt een backtracking-algoritme als volgt:
je vertrekt van een gedeeltelijke oplossing (in het begin is die leeg). In het voorbeeld van de doolhof: het pad dat je al afgelegd hebt om tot bij een splitsing te komen.
je breidt die gedeeltelijke oplossing stapsgewijs uit naar een volledige(re) oplossing, waar je bij elke uitbreiding een keuze maakt.
Wanneer die keuze later niet blijkt te leiden tot een geschikte oplossing, keer je terug naar dat keuzepunt (backtracking) en maak je een andere keuze.
In het voorbeeld van de doolhof: als je vastzit, keer keer je terug naar de vorige splitsing, en je kiest een andere gang.
Als je alle gangen geprobeerd hebt zonder resultaat, keer je terug naar de splitsing daarvoor, etc.
Een backtracking-algoritme maakt meestal gebruik van recursie.
De stack die impliciet gebruikt wordt bij recursie is immers heel handig om bij te houden welke keuzes al gemaakt werden, en in welke volgorde.
Voorbeeld: token segmentatie
Het token segmentatie probleem bestaat erin na te gaan of je een gegeven string kan bekomen als sequentie van een of meerdere tokens uit een gegeven lijst van tokens.
Bijvoorbeeld: voor de string "catsanddogs" en de tokenlijst [s, an, ca, cat, dog, and, sand, dogs] zijn volgende segmentaties mogelijk:
cat sand dogs
cat sand dog s
cat s and dog s
cat s and dogs
Met dezelfde woordenlijst kan de string acatandadog niet gesegmenteerd worden.
We bespreken hieronder hoe we dit probleem kunnen oplossen met backtracking.
We beschouwen drie varianten:
uitzoeken of er minstens één segmentatie bestaat (en die teruggeven)
alle mogelijke segmentaties teruggeven
de segmentatie die het minst aantal tokens gebruikt teruggeven.
Eén (willekeurige) oplossing zoeken
De essentie van een backtracking-algoritme is het zoeken van één oplossing.
Dit ligt ook aan de basis van de andere twee varianten (zoeken van alle oplossingen en zoeken van een optimale oplossing).
Het achterliggend idee is zeer eenvoudig: probeer telkens iets, en als dat niet tot een oplossing leidt, keer terug en probeer iets anders, tot je een oplossing gevonden hebt of alles geprobeerd hebt (dan is er geen oplossing).
We bekijken nu hoe we dit idee concreet kunnen beschrijven met een algoritme.
Voorbeeld: token segmentatie
Stel: we willen voor het segmentatie-probleem een (willekeurige) oplossing teruggeven (als die bestaat).
De oplossing zoeken met een backtracking-algoritme zal, zoals gezegd, gebaseerd zijn op recursie.
Dus: om token segmentatie voor een string van lengte \( n \) te doen, veronderstellen we dat we dit al kunnen oplossen voor alle strings van lengte \( n' < n \).
Het basisgeval is een lege string segmenteren; we moeten dan geen tokens gebruiken.
We moeten nu enkel nog nadenken over hoe een oplossing voor een kortere string ons precies kan helpen om het hele probleem op te lossen.
Denk hier zelf even over na
Hier is een idee: wat als we, voor elke mogelijke token, nagaan of die overeenkomt met het begin van de string, en als dat zo is, die token wegknippen uit het begin van de string?
Zo wordt de string korter, en kunnen we recursie gebruiken om het probleem verder op te lossen voor die kortere string.
De oplossing voor het hele probleem bestaat dan uit de weggeknipte token, gevolgd door de tokens die nodig zijn om de kortere string op te bouwen (die bekomen we via de recursie).
We maken dus telkens één keuze, namelijk welk token (uit de lijst van mogelijke tokens) we proberen te matchen met het begin van de string.
Hieronder zie je een zoekboom die een mogelijke uitvoering van dat idee weergeeft voor de string catsanddogs en de tokenlijst [s, an, ca, cat, dog, and, sand, dogs].
Om die te begrijpen, beginnen we bovenaan.
In de rechthoeken staat telkens de lijst van tokens die we tot dan toe gekozen hebben, en de resterende string.
In het begin hebben we nog geen tokens gekozen ([]), en is de resterende string nog gelijk aan de volledige string catsanddogs.
De pijltjes geven aan welke token we kiezen (we tonen enkel de tokens die overeenkomen met het begin van de string; de anderen leiden sowieso tot niets).
We volgen steeds eerst de linkerpijl naar beneden.
De gestippelde lijnen geven aan waar we backtracken.
Een situatie die niet tot een oplossing kan leiden (geen enkele token komt overeen met het begin van de string) wordt rood gekleurd; we gaan dan terug een knoop naar boven en nemen de volgende tak.
De gevonden oplossing wordt in het groen aangeduid. Eens deze gevonden is, zoeken we niet meer verder.
De informatie in de rechthoeken stelt de gedeeltelijke/partiële oplossing voor die we bijhouden.
Die bevat hier dus twee zaken:
de reeds gebruikte token-sequentie (initieel een lege lijst)
het deel van de string dat nog overblijft (initieel de hele string)
Nadat we een token gekozen hebben, moeten we deze gedeeltelijke oplossing uitbreiden (aanpassen) op basis van die keuze.
Om dat te doen, moeten we
nakijken of het gekozen token voorkomt aan het begin van de resterende string
dat token toevoegen aan de lijst van gebruikte tokens
de resterende string inkorten, door het token vooraan te verwijderen
Eens we dat gedaan hebben, kiezen we opnieuw een token en doen we hetzelfde.
Die herhaling gebeurt door middel van recursie.
We hebben een oplossing gevonden wanneer het overblijvende deel van de string leeg is.
Als later zou blijken dat een gemaakte keuze fout was (dus dat we met die keuze niet tot een oplossing komen), moeten we deze keuze ongedaan maken (backtracken, overeenkomstig de gestippelde pijlen).
Om dat te doen, verwijderen we het laatste token terug uit de token-sequentie, en moeten we zorgen dat we terug de niet-ingekorte string gebruiken.
We proberen dan opnieuw met een ander token.
Hoe ziet dat eruit in code? Zo:
privatestaticList<String>findAny(StringremainingString,List<String>allTokens,List<String>tokensUsedSoFar){// basisgevalif(remainingString.isEmpty())returntokensUsedSoFar;for(Stringtok:allTokens){// probeer token tokif(remainingString.startsWith(tok)){// uitbreiden gedeeltelijke oplossingtokensUsedSoFar.add(tok);varshorterString=remainingString.substring(tok.length());// recursief verder zoekenvarsolution=findAny(shorterString,allTokens,tokensUsedSoFar);if(solution!=null){// oplossing gevonden; stop met zoeken en geef oplossing terugreturnsolution;}else{// laatste keuze ongedaan makentokensUsedSoFar.removeLast();}}}// geen enkel token leidde tot een oplossing;// geef null terug om aan te duiden dat er geen oplossing isreturnnull;}
De gedeeltelijke oplossing wordt voorgesteld met de twee parameters remainingString en tokensUsedSoFar.
Het basisgeval komt overeen met een lege string; we hebben dan een oplossing gevonden.
Die oplossing zit in de parameter tokensUsedSoFar.
Als de string niet leeg is, proberen we alle tokens beurt om de beurt uit.
Als een token niet overeenkomt met het begin van de string, kunnen we die token meteen overslaan.
Als die wel overeenkomt met het begin, voegen we de token toe aan de lijst met gebruikte keuzes en korten we de string in door de token vooraan te verwijderen.
We zoeken vervolgens recursief verder naar een oplossing.
Als we een oplossing vinden, hebben we meteen ook een oplossing voor het hele probleem.
Zo niet, dan verwijderen we onze token terug uit de lijst van gebruikte tokens, vooraleer we opnieuw proberen met de volgende token.
(De string hoeven we niet terug langer te maken; we kunnen gewoon remainingString blijven gebruiken)
Als we alle tokens geprobeerd hebben zonder een oplossing te vinden (return solution werd nooit uitgevoerd), dan is er geen oplossing en geven we null terug.
Om deze methode wat eenvoudiger bruikbaar te maken, kunnen we het worker-wrapper patroon toepassen.
We voegen dan een tweede findAny-methode toe, die geen lijst van gebruikte tokens bevat, en de methode hierboven oproept met een lege lijst.
publicstaticList<String>findAny(Stringstring,List<String>tokens){returnfindAny(string,tokens,newArrayList<>());}publicstaticvoidmain(String[]args){// voorbeeld van gebruikSystem.out.println(findAny("catsanddogs",List.of("s","an","ca","cat","dog","and","sand","dogs")));}
Skelet-programma (algemeen)
Backtracking-algoritmes volgen vaak een gelijkaardige structuur.
Naast een voorbeeld geven we daarom telkens ook een skelet-programma: een algemene structuur die je vaak kan herbruiken.
Backtracking-algoritmes draaien allemaal rond het gebruik van een partiële oplossing: dat is de sequentie van keuzes die je reeds gemaakt hebt, en de toestand waarin je je daardoor bevindt.
Voor elk probleem zal je een geschikte representatie (datastructuur) moeten kiezen voor je partiële oplossing.
Om de skelet-programma’s algemeen te houden, gebruiken we hiervoor volgende interfaces (het zal later duidelijk worden waarvoor de verschillende methodes precies dienen):
interfacePartialSolution{booleanisComplete();// volledige oplossing?booleanshouldAbort();// leidt sowieso niet tot oplossing?Collection<Extension>extensions();// mogelijke keuzes/extensiesSolutiontoSolution();// zet om naar finale oplossingbooleancanImproveUpon(Solutionsolution);// vergelijken van oplossingen}publicinterfaceExtension{voidapply(PartialSolutionsolution);// pas keuze toe op partiële oplossingvoidundo(PartialSolutionsolution);// maak keuze ongedaan}interfaceSolution{booleanisBetterThan(Solutionother);// vergelijken van oplossingen}
In de algoritmes die je zelf schrijft zal je natuurlijk niet exact deze interfaces gebruiken, maar kan je zelf kiezen hoe je de oplossingen best voorstelt.
Maar zelfs zonder deze interfaces te gebruiken is het vaak wel nuttig om eens na te denken over hoe je de operaties uit de interfaces kan uitvoeren met jouw voorstelling.
Skelet-programma: een willekeurige oplossing zoeken
Onderstaande code geeft het skelet om eender welke oplossing voor het probleem te vinden.
We maken gebruik van het worker-wrapper patroon.
Het eigenlijke werk gebeurt in de recursieve findAnySolution-methode.
Die zoekt een oplossing voor het hele probleem, vertrekkend van een gegeven partiële oplossing.
We gaan eerst na of de huidige partiële oplossing toevallig al een oplossing is voor het hele probleem (hier via de isComplete()-methode). Dit is het basisgeval voor de recursie. Als dat zo is, moeten we niet verder zoeken, en geven we de oplossing terug. Soms moeten we nog enkele bewerkingen doen om de partiële oplossing om te zetten in het verwachte formaat van de oplossing. Dat wordt hier aangeduid met de toSolution()-methode.
Soms kan je op voorhand al snel zien dat een partiële oplossing nooit tot een oplossing kan leiden (shouldAbort()). Dan geven we meteen op, en geven we null terug (geen oplossing).
In alle andere gevallen overlopen we elke mogelijke uitbreiding (keuze) van de partiële oplossing (gegenereerd met extensions()).
We veranderen de partiële oplossing door elk van de uitbreidingen (één voor één) toe te passen (apply()).
Dan zoeken we recursief naar een volledige oplossing, vertrekkend van die uitgebreide partiële oplossing.
Zodra we zo een (volledige) oplossing bekomen, geven we die terug.
Als een uitbreiding niet tot een oplossing leidt, maken we ze ongedaan (undo()) en proberen we de volgende uitbreiding.
Als we alle mogelijke uitbreidingen overlopen hebben, en geen oplossing gevonden hebben, geven we op.
We geven null terug.
Vergelijk deze skelet-code met de code voor het token segmentatie voorbeeld.
Herken je de verschillende onderdelen?
privatestaticList<String>findAny(StringremainingString,List<String>allTokens,List<String>tokensUsedSoFar){// if (current.isComplete()) return current.toSolution();if(remainingString.isEmpty())returntokensUsedSoFar;// if (current.shouldAbort()) return null;// for (var extension : current.extensions()) {for(Stringtok:allTokens){if(remainingString.startsWith(tok)){// extension.apply(current);tokensUsedSoFar.add(tok);varshorterString=remainingString.substring(tok.length());// var solution = findAnySolution(current);varsolution=findAny(shorterString,allTokens,tokensUsedSoFar);if(solution!=null){returnsolution;}else{// extension.undo(current);tokensUsedSoFar.removeLast();}}}returnnull;}
(Onze code voor token segmentatie bevat geen code die overeenkomt met shouldAbort.)
Alle oplossingen zoeken
Een variant van het zoeken van één oplossing is het zoeken van alle oplossingen.
Om dat te doen, doen we in essentie hetzelfde als bij het zoeken van één oplossing.
Nadat we een oplossing gevonden hebben, stoppen we echter niet: we houden de gevonden oplossing bij en gaan (met backtracking) verder op zoek naar eventuele andere oplossingen.
Voorbeeld: token segmentatie
Stel: we willen niet één, maar alle mogelijke segmentaties zoeken.
We kunnen vertrekken van de versie om één oplossing te zoeken, maar moeten dan enkele wijzigingen doorvoeren.
Een eerste duidelijke wijziging is het terugkeertype. In plaats van één lijst van tokens, moeten we nu meerdere lijsten van tokens kunnen teruggeven.
We kiezen daarom voor List<List<String>> als terugkeertype.
Een tweede wijziging komt voort vanuit het volgende inzicht.
Waar we bij het zoeken van 1 oplossing meteen konden stoppen eens we een oplossing gevonden hadden, zullen we bij het zoeken naar alle oplossingen verder moeten backtracken nadat we een oplossing tegengekomen zijn.
Dat betekent dat, op het moment dat we een oplossing vinden, we die ergens willen ‘wegschrijven’.
We voegen daarom een extra parameter toe, een lijst solutionsSoFar, die alle oplossingen voorstelt die we eerder al gevonden hebben.
Telkens we een nieuwe oplossing tegenkomen, voegen we die toe aan solutionsSoFar.
Nadat we (via backtracking) alle keuzes doorlopen hebben, bevat solutionsSoFar dan ook alle gevonden oplossingen.
Een derde wijziging is dat we geen null meer teruggeven als we geen oplossing vinden; als er geen oplossingen zijn voor het probleem, vertaalt zich dat in een lege lijst van oplossingen.
Belangrijk om op te merken is dat we de lijst tokensUsedSoFarkopiëren wanneer we die toevoegen aan de lijst solutionsSoFar.
Dat is noodzakelijk: de tokensUsedSoFar-lijst is immers deel van de partiële oplossing, en die lijst zal later nog aangepast (bijvoorbeeld met .removeLast()) wanneer we verder naar oplossingen zoeken.
In het vorige voorbeeld was dit niet essentieel; zodra we een oplossing vonden, gaven we de gevonden lijst meteen terug en stopten we met zoeken.
In de uitvoeringsboom voor het zoeken van alle oplossingen zien we dat alle mogelijkheden overlopen en teruggegeven worden.
Alle groene knopen zijn oplossingen, en zullen (van links naar rechts) aan de lijst solutionsSoFar toegevoegd worden.
Dit duurt uiteraard een stuk langer dan enkel de eerste oplossing teruggeven.
We doorlopen immers steeds alle mogelijkheden.
Skelet-programma: alle oplossingen zoeken
We geven opnieuw een skelet-programma, dit keer om alle oplossingen voor het probleem te vinden.
Het eigenlijke werk gebeurt in de recursieve findAllSolutions-methode.
Die doet grotendeels hetzelfde als de findAnySolution-methode uit het skelet-programma voor één oplossing.
Het verschil is dat er nu een extra parameter is, namelijk een collectie van alle tot dan toe gevonden (volledige) oplossingen, solutionsSoFar.
Elke keer een nieuwe oplossing gevonden wordt, voegen we die toe aan solutionsSoFar.
De extra parameter wordt geïnitialiseerd in solve met een lege lijst.
Vergelijk deze skelet-code opnieuw met de code voor het token segmentatie voorbeeld.
Herken je de verschillende onderdelen?
privatestaticList<List<String>>findAll(StringremainingString,List<String>allTokens,List<String>tokensUsedSoFar,List<List<String>>foundSoFar){// if (current.isComplete()) {if(remainingString.isEmpty()){// solutionsSoFar.add(current.toSolution());foundSoFar.add(List.copyOf(tokensUsedSoFar));// return solutionsSoFar;returnfoundSoFar;};// if (current.shouldAbort()) return solutionsSoFar;// for (var extension : current.extensions()) {for(Stringtok:allTokens){if(remainingString.startsWith(tok)){// extension.apply(current);tokensUsedSoFar.add(tok);varshorterString=remainingString.substring(tok.length());// findAllSolutions(current, solutionsSoFar);findAll(shorterString,allTokens,tokensUsedSoFar,foundSoFar);// extension.undo(current);tokensUsedSoFar.removeLast();}}// return solutionsSoFar;returnfoundSoFar;}
Een optimale oplossing zoeken
De laatste variant die we beschouwen is het zoeken van een optimale oplossing voor een probleem.
Je zou dat kunnen doen door eerst alle oplossingen te zoeken, en dan in die lijst van oplossingen de meest optimale oplossing te zoeken.
Het bijhouden van alle oplossingen kan in sommige gevallen echter leiden tot een te hoog geheugengebruik.
In plaats van alle oplossingen bij te houden, is het daarom beter om enkel de (tot dantoe) beste oplossing te bewaren.
Het zoeken van een optimale oplossing duurt dus meestal even lang als het zoeken van alle oplossingen, maar niet altijd.
Soms is het zinloos om nog naar oplossingen te blijven zoeken als die sowieso nooit beter kunnen zijn dan een reeds eerder gevonden oplossing.
Je kan dus meteen stoppen met zoeken wanneer je weet dat de huidige partiële oplossing nooit meer tot een betere finale oplossing kan leiden dan de tot dan toe beste oplossing.
Dat kan een hoop werk besparen, en de tijd gevoelig inkorten.
Voorbeeld: token segmentatie
De optimale oplossing wordt gedefinieerd als de oplossing die de string splitst in het minst aantal tokens.
De wijzigingen ten opzichte van het algoritme om alle oplossingen te zoeken zijn devolgende:
Ten eerste hoeven we geen lijst van oplossingen meer bij te houden, maar enkel de tot dan toe beste oplossing.
Dat doen we in een variabele bestSoFar. Die variabele is null wanneer er nog geen oplossing gevonden werd (bijvoorbeeld bij de start van de zoektocht).
Ten tweede moeten we, wanneer we een oplossing gevonden hebben, nagaan of die beter is dan de vorige beste oplossing (als die er is).
Aangezien we zoeken naar de splitsing met het minst aantal tokens, vergelijken we op basis van de lengte van de oplossing.
We geven de kortste van de twee terug.
Tenslotte kijken we of we de zoektocht voortijdig kunnen staken.
Wanneer de huidige splitsing al meer tokens bevat dan de beste splitsing die we op dat moment kennen, heeft het geen zin om nog verder te zoeken.
Er kunnen immers enkel nog extra tokens bijkomen, waardoor de oplossing enkel langer kan worden, nooit korter.
Merk op dat we na de recursieve oproep de variabele bestSoFar aanpassen met het resultaat van die oproep, voor het geval de recursieve oproep een betere oplossing opgeleverd heeft.
De uitvoeringsboom ziet er als volgt uit.
De gele knopen zijn oplossingen die op een bepaald moment de beste oplossing waren, maar later vervangen zijn door een nog betere oplossing.
Ook het zoeken naar een optimale oplossing via backtracking heeft vaak dezelfde vorm.
We bespreken daarom een derde skelet-programma.
Het eigenlijke werk gebeurt opnieuw in de recursieve findOptimalSolution-methode.
Die doet grotendeels hetzelfde als bij het programma om één of alle oplossingen te zoeken.
Het speciale hier is een extra parameter, namelijk de beste tot dan toe gevonden (volledige) oplossing bestSoFar.
Elke keer een nieuwe oplossing gevonden wordt, vergelijken we die met de beste tot dan toe (via isBetterThan), en geven de betere van de twee terug.
De extra parameter wordt geïnitialiseerd in solve met null: er is nog geen oplossing om mee te vergelijken.
Merk op dat we dus niet eerst alle oplossingen zoeken en bijhouden om daarna de beste te selecteren; we houden enkel de beste oplossing tot dan toe bij en vergelijken daarmee.
Daarenboven voegen we nog een optimalisatie toe: als we op een bepaald moment merken dat de huidige partiële oplossing nooit meer kan uitgroeien tot een oplossing die beter is dan de beste reeds gekende oplossing, dan stoppen we met zoeken op basis van die partiële oplossing.
Bijvoorbeeld, wanneer we een kortste pad zoeken in een doolhof en het huidige pad (waarmee we nog niet uit het doolhof zijn) is al langer dan het tot dan toe beste pad (dat wel reeds heel het doolhof oploste), dan hoeven we niet meer verder te zoeken: extra stappen toevoegen zal immers nooit kunnen leiden tot een korter pad.
We modelleren dit met de canImproveUpon-methode.
Vergelijk deze skelet-code opnieuw met de code voor het token segmentatie voorbeeld.
Herken je de verschillende onderdelen?
privatestaticList<String>findShortest(StringremainingString,List<String>allTokens,List<String>tokensUsedSoFar,List<String>bestSoFar){// if (current.isComplete()) {if(remainingString.isEmpty()){// var solution = current.toSolution();varsolution=List.copyOf(tokensUsedSoFar);// if (bestSoFar == null || solution.isBetterThan(bestSoFar)) {if(bestSoFar==null||solution.size()<bestSoFar.size()){returnsolution;}else{returnbestSoFar;}};// if (current.shouldAbort() ||// (bestSoFar != null && !current.canImproveUpon(bestSoFar))) {if(bestSoFar!=null&&bestSoFar.size()<=tokensUsedSoFar.size()){returnbestSoFar;}// for (var extension : current.extensions()) {for(Stringtok:allTokens){if(remainingString.startsWith(tok)){// extension.apply(current);tokensUsedSoFar.add(tok);varshorterString=remainingString.substring(tok.length());// bestSoFar = findOptimalSolution(current, bestSoFar);bestSoFar=findShortest(shorterString,allTokens,tokensUsedSoFar,bestSoFar);// extension.undo(current);tokensUsedSoFar.removeLast();}}returnbestSoFar;}
Efficiëntie van backtracking
Backtracking is vaak niet heel efficiënt, zeker niet als je alle oplossingen of een optimale oplossing zoekt.
Bijvoorbeeld, als er \( k \) keuzepunten zijn, en je bij elke keuzepunt precies \( m\) mogelijkheden hebt, dan zijn er in totaal \( m^k \) mogelijke paden die je moet proberen.
Door snel te herkennen wanneer een partiële oplossing niet zal leiden tot een geschikte oplossing, en de zoekoperatie dan onmiddellijk af te breken, kan je het algoritme soms wel een pak efficiënter maken.
Kopiëren vs. aanpassen en herstellen
In de skelet-code hierboven maakten we steeds gebruik van apply() en undo(): we passen de partiële oplossing aan (door ze uit te breiden), en maken die aanpassing later weer ongedaan.
Dat gaat makkelijk als de aanpassing eenvoudig ongedaan te maken is, bijvoorbeeld een element toevoegen aan een lijst en dat nadien weer verwijderen.
Als het ongedaan maken niet zo eenvoudig is (bijvoorbeeld omdat er na de aanpassing heel wat herberekend wordt), is het vaak eenvoudiger om de volledige toestand eerst te kopiëren en verder te werken met deze kopie.
Dat heeft als nadeel een hoger geheugengebruik, maar vereenvoudigt het uitbreiden en herstellen van de partiële oplossing wel aanzienlijk.
Je hoeft immers niets ongedaan te maken; aangezien alle aanpassingen op een kopie gebeurd zijn, kan je gewoon teruggrijpen naar de originele toestand.
Die is ongewijzigd, aangezien alle aanpassingen op een kopie gebeurden.
Hieronder zie je een voorbeeld hiervan (een variant om één oplossing te zoeken voor het token segmentatie probleem).
De commentaarregels geven aan wat er van belang is.
privatestaticList<String>findAny(StringremainingString,List<String>allTokens,List<String>tokensUsedSoFar){if(remainingString.isEmpty())returntokensUsedSoFar;for(Stringtok:allTokens){if(remainingString.startsWith(tok)){// uitbreiding gedeeltelijke oplossing OP EEN KOPIEvarcopyOfUsedTokens=newArrayList<>(tokensUsedSoFar);copyOfUsedTokens.add(tok);varshorterString=remainingString.substring(tok.length());// recursief verder zoeken OP BASIS VAN DE KOPIEvarsolution=findAny(shorterString,allTokens,copyOfUsedTokens);if(solution!=null){returnsolution;}else{// we hoeven hier NIETS ongedaan te maken,// de volgende iteratie gebruikt opnieuw de originele usedTokens-lijst}}}returnnull;}
In het voorbeeld van token-segmentatie mocht een token meermaals gebruikt worden.
Schrijf nu een algoritme dat uitzoekt of een string gesegmenteerd kan worden op een manier waarbij elke token hoogstens één keer gebruikt wordt.
Doe dat voor de drie varianten:
één oplossing
alle oplossingen
optimale oplossing, waarbij de optimale oplossing deze keer de segmentatie is met het grootste aantal tokens.
Als er geen oplossing is, geef dan null terug (voor variant 1 en 3) of een lege Set (voor variant 2).
8-queens / n-queens
Dit is de klassieker onder de backtracking-algoritmes.
Schrijf een backtracking-algoritme om te zoeken hoe je, op een schaakbord van 8x8 vakjes, 8 koninginnen kan plaatsen zodat ze elkaar niet kunnen slaan.
Voor wie niet thuis is in schaken: een koningin (queen, ‘Q’) kan elke andere koningin slaan die zich in dezelfde rij, kolom, of diagonaal bevindt:
Uitbreiding 1: Doe dit voor een schaakbord van willekeurige grootte n, in plaats van 8.
Uitbreiding 2: Zoek alle oplossingen in plaats van 1 oplossing (voor een bord van willekeurige grootte n, maar probeer met 5x5).
Knight’s tour
Nog een klassieker met een schaakbord.
Schrijf een backtracking-algoritme om met een paard, beginnend op positie (0, 0), precies één keer op elk vakje van het bord te komen.
Een paard (knight, ‘N’) beweegt 2 vakjes in een richting, en 1 vakje in de orthogonale richting:
Hint als je oplossing te lang duurt: Begin met een kleiner bord (5x5), en overloop de mogelijke volgende posities van het paard steeds volgens de wijzers van de klok.
Uitbreiding: Zoek alle oplossingen in plaats van 1 oplossing, voor een klein bord (5x5). Begin nog steeds op (0, 0). Zoek ook online op hoeveel oplossingen er bestaan voor een 8x8 bord.
SEND+MORE=MONEY
Schrijf een backtracking-algoritme om een letterpuzzel op te lossen zodanig dat de som klopt.
Elke letter komt in de hele puzzel overeen met hetzelfde cijfer (0–9).
Twee verschillende letters staan altijd voor verschillende cijfers.
De getallen beginnen niet met 0 (geen leading zeros).
Bijvoorbeeld:
S E N D
+ M O R E
-----------
M O N E Y
of
ONE + TWO = SIX
SUN + FUN = SWIM
CRACK + HACK = ERROR
MATH + MYTH = HARD
BASE + BALL = GAMES
Hint: onderstaande hulpfuncties kunnen misschien handig zijn. Ook Integer.parseInt(String s) om een String om te zetten naar een int kan nuttig zijn.
Uitbreiding: Laat toe om meer dan twee termen op te tellen, bijvoorbeeld ONE + TWO + SIX = NINE.
Uitbreiding: Zoek alle oplossingen.
Uurrooster planner
Schrijf een programma om een conflict-vrije uurrooster te maken voor een lijst van vakken.
Bij elk vak hoort een verzameling van personen (bv. leerkracht en studenten).
We vereenvoudigen het uurrooster tot een verzameling van vaste slots waarop vakken ingepland kunnen worden.
Elk slot stellen we voor door een positief getal, beginnend bij 1.
Zo kan slot 1 bijvoorbeeld staan voor maandagmorgen om 8u30, slot 2 voor maandagmorgen om 10u30, etc.
Enkele beperkingen waaraan het rooster moet voldoen:
(compleet) Elk vak moet ingepland worden op precies 1 slot.
(beperkt) Er moet rekening gehouden worden met een maximaal aantal slots (bv. 10).
(optimaal) Het uiteindelijke uurrooster moet gebruik maken van zo weinig mogelijk slots, met de voorkeur om lagere slotnummers eerst te gebruiken.
(conflict-vrij) Een persoon mag nooit voor 2 of meer verschillende vakken in hetzelfde slot ingeroosterd worden.
(capaciteitsconform) Er mogen nooit meer dan 3 vakken op hetzelfde slot ingepland worden, zodat er steeds voldoende lokalen zijn.
Woorden samentrekken
Maak een methode die de kortste samentrekking zoekt van een gegeven verzameling van woorden.
We spreken van een samentrekking wanneer het einde van een woord overeenkomt met het begin van het woord dat daarop volgt (minstens 1 overlappende letter).
Bijvoorbeeld: banaananas is een samentrekking van ananas en banaan, waar we beginnen met het woord banaan, en de letters an overlappen.
Voor de woorden "besturend", "declaratiesysteem", "deelgemeente", "gemeentebesturen", "merendeel", "programmeren", "sturende", "urendeclaraties" bekom je als kortste samentrekking "programmerendeelgemeentebesturendeclaratiesysteem".
Voor [samentrekking, trekkingsdata, datavoorziening, voorzieningsfonds, fondsmanager, managersfuncties, functiesysteem, systeemdata] wordt dat samentrekkingsdatavoorzieningsfondsmanagersfunctiesysteemdata.
Soms bestaat er geen samentrekking.
Uitbreiding: Zoek ook de langste samentrekking. Voor het eerste voorbeeld hierboven is dat programmerendeelgemeentebesturendeclaratiesturendeclaratiesysteem. Voor het tweede functiesysteemdatavoorzieningsfondsmanagersfunctiesamentrekkingsdata.
Traveling sales person
Gegeven een lijst van plaatsen met bijhorende (x, y)-coördinaten en een startplaats, zoek de kortste tour (dus met de kleinste totale afgelegde afstand) die terug uitkomt op de startplaats en onderweg elke gegeven plaats exact één keer bezoekt.
Bijvoorbeeld, voor de volgende lijst van locaties (hieronder visueel weergegeven) heeft de kortste tour vertrekkend en eindigend bij A een lengte 3.7485395:
Uitbreiding: Alle volgordes van locaties proberen leidt tot enorm veel mogelijkheden (hoeveel?), en dus een zeer traag algoritme. Bedenk één of meer opties om de zoektocht wat te versnellen (al zal het algoritme traag blijven voor veel coördinaten; hoop niet op een oplossing die voldoende snel werkt voor meer dan een 20-tal locaties).
Doolhof
Schrijf een functie om het kortste pad door een doolhof te vinden van het begin- naar een eindpunt (er kunnen meerdere eindpunten zijn).
Een doolhof wordt voorgesteld als een string, met
@ voor het startpunt (steeds exact één per doolhof)
$ voor een eindpunt (minstens één per doolhof)
. voor een vrije cel (hier kan je doorgaan)
X voor een cel met een muur (hier kan je niet doorheen gaan)
Je krijgt een lijst van kleurpatronen voor een handdoek (gekleurde strepen van links naar rechts), bv. r, wr, b, g, bwu wat staat voor red, white-red, black, green, black-white-blue.
Je krijgt ook een lijst van voorgestelde designs (bv. brwrr).
De vraag is om na te gaan hoeveel van de voorgestelde designs je kan maken door handdoeken met de gegeven patronen naast elkaar te leggen.
Het design brwrr kan je bijvoorbeeld maken met de gegeven patronen (r, wr, b, g, bwu) door 4 handdoeken naast elkaar te leggen: b + r + wr + r = brwrr.
Merk op dat je meerdere handdoeken met hetzelfde patroon mag gebruiken (bv. r in dit voorbeeld).
Je mag echter geen handdoeken in stukken knippen (dus je kan bv. bwu niet gebruiken om bw te maken).
Schrijf een functie nbPossibleDesigns om te tellen hoeveel van de voorgestelde designs je kan maken met behulp van handdoeken met de gegeven patronen.
Bijvoorbeeld: voor onderstaande invoer (eerste lijn zijn de patronen, en na een lege lijn volgen de voorgestelde designs):
brwrr gemaakt kan worden met een br handdoek, dan een wr handdoek, en tenslotte een r handdoek.
bggr gemaakt kan worden met een b handdoek, twee g handdoeken, en tenslotte een r handdoek.
gbbr gemaakt kan worden met een gb handdoek en dan een br handdoek.
rrbgbr gemaakt kan worden met een r, rb, g, and br.
ubwu is onmogelijk.
bwurrg gemaakt kan worden met een bwu, r, r, and g.
brgr gemaakt kan worden met een br, g, and r.
bbrgwb is onmogelijk.
Hint: Je eerste backtracking-algoritme zal waarschijnlijk werken voor kleine problemen, maar heel traag zijn voor het grote probleem in de meegeleverde tests. Je kan het heel wat versnellen door gebruik te maken van een cache (die het resultaat van vorige sub-patronen bijhoudt).
Uitbreiding: maak nu ook een methode countDifferentRealizations die het aantal verschillende manieren zoekt om een design te maken. Bijvoorbeeld, gbbr kan gemaakt worden op 4 verschillende manieren met de patronen van hierboven, namelijk
g, b, b, r
g, b, br
gb, b, r
gb, br
De methode countDifferentRealizations moet dus het getal 4 teruggeven voor het design gbbr en de patronen van hierboven.
Ook hier zal caching nuttig zijn om het algoritme sneller te maken.
Snakefill
Oud-examenvraag
Dit is een oud-examenvraag.
In het spel SnakeFill beweeg je het hoofd van een slang over een bord in een bepaalde richting. Het bord bestaat uit vrije cellen en muren. De slang wordt steeds langer, en beweegt steeds verder in dezelfde richting tot die een obstakel (een muur, de rand van het bord, of een deel van zichzelf) tegenkomt. Pas dan kan je de richting veranderen. Het hoofd van de slang beweegt dus steeds van obstakel tot obstakel.
Het doel van het spel is om alle vakjes van het bord te vullen met de slang. Hieronder zie je een voorbeeld. Het hoofd van de slang begint (fig. A) linksboven op positie (0, 0), beweegt dan naar onder (B), dan naar rechts (C), etc. Helemaal rechts (fig. D) zie je een traject dat het hele bord vult. Dit komt overeen met de bewegingen [DOWN, RIGHT, UP, LEFT, UP, RIGHT, DOWN, RIGHT, UP, LEFT].
Ontwerp een backtracking-algoritme om, met zo weinig mogelijk bewegingen, het hele bord te vullen. Je geeft de oplossing terug als een lijst van bewegingen (Directions). Indien er geen oplossing is, geef je null terug. Je moet een solve-methode schrijven die opgeroepen wordt zoals getoond in de gegeven main-methode. In de solve-methode mag je gebruik maken van zelfgeschreven hulpmethodes.
Je krijgt alvast de interface van een Board-klasse om het bord van SnakeFill voor te stellen. Je mag ervan uitgaan dat er hiervan een implementatie beschikbaar is die correct werkt; je moet deze dus niet zelf schrijven. Er zijn ook hulpklassen gegeven om posities en richtingen voor te stellen. In principe volstaan de gegeven methodes in deze klassen om het probleem op te lossen. Je mag elk van deze klassen echter verder uitbreiden met extra methodes die je nuttig acht. Schrijf daarvoor de methode-hoofding en een beschrijving van wat de methode moet doen. Je hoeft de methode zelf niet te implementeren.
publicinterfaceBoard{/* Huidige positie van het hoofd van de slang */PositiongetCurrentHead();/* Maakt de gegeven positie deel uit van het bord? */booleanisValid(Positionpos);/* Is de gegeven positie vrij (geen muur, geen slang)” */booleanisFree(Positionpos);/* Zijn alle posities van het bord gevuld? */booleanisFull();/* Telt het aantal opeenvolgende vrije cellen in de gegeven
richting vanaf het hoofd van de slang.
In situatie (A) in het voorbeeld geeft deze methode
5 terug voor DOWN, 2 voor RIGHT, en 0 voor LEFT en UP. */intfreeCells(Directiondir);/* Maak de slang n vakken langer in de gegeven richting.
In het voorbeeld ga je van (A) naar (B) met n=5 en dir=DOWN */voidextendSnake(intn,Directiondir);/* Maak de slang n vakken korter in de gegeven richting.
In het voorbeeld ga je van (B) naar (A) met n=5 en dir=UP */voidretractSnake(intn,Directiondir);/* Maak een kopie van het bord */Boardcopy();}/* Positie op het bord */recordPosition(introw,intcol){/* Positie op n vakken vanaf de huidige positie in de
gegeven richting. */publicPositiongo(Directiondir,intn){returnswitch(dir){caseRIGHT->newPosition(row,col+n);caseLEFT->newPosition(row,col-n);caseUP->newPosition(row-n,col);caseDOWN->newPosition(row+n,col);};}}/* Een richting (UP, DOWN, LEFT, RIGHT). */enumDirection{UP,DOWN,LEFT,RIGHT;publicstaticfinalDirection[]ALL_DIRECTIONS={UP,DOWN,LEFT,RIGHT};…/* Geef de omgekeerde richting terug
(UP <-> DOWN, LEFT <-> RIGHT) */publicDirectionopposite(){…};}publicstaticvoidmain(String[]args){varboard=…/* Maak een bord (dit hoef je niet te schrijven) */varsolution=solve(board);if(solution!=null)System.out.println(solution);elseSystem.out.println("No solution");}publicstaticList<Direction>solve(Boardboard){// TODO}
9. Specificaties
Wanneer is software correct? Hoe weet je dat een implementatie doet wat het moet doen?
Zeker in een wereld waar meer en meer code door AI-tools gegenereerd wordt, is het belangrijk om een goed begrip te hebben van wat correct gedrag is, en hoe je dat kan specificeren en controleren, zonder blind te vertrouwen op de gegenereerde code.
Om dat te onderzoeken, bekijken we in dit hoofdstuk hoe je softwaregedrag precies kan beschrijven, los van de concrete code die dat gedrag realiseert.
We focussen op specificaties, contracten, invarianten, en op hoe je met tests en formele redeneringen (zoals Hoare-logica) kan nagaan of een implementatie correct is.
Het domein van specificatie en correctheid is enorm breed, met veel theorie en tools.
We beperken ons hier daarom tot een eerste kennismaking met de kernconcepten.
Specificaties
Een specificatie beschrijft het gewenste gedrag van software.
Ze zegt wat correct gedrag is, zonder vast te leggen hoe je dat gedrag intern programmeert.
Of nog: ze legt vast wat de (gewenste) relatie is tussen invoer en uitvoer (of begin- en eindtoestand), zonder te zeggen welke algoritmen, datastructuren of codeconstructies je moet gebruiken.
Dat klinkt eenvoudig, maar in de praktijk is dit een van de belangrijkste denkoefeningen in softwareontwikkeling.
Veel bugs ontstaan niet door een typfout in code, maar doordat de bedoeling onduidelijk of impliciet was.
Een goede specificatie maakt die bedoeling expliciet.
Zeker voor grote softwaresystemen, met meerdere modules en teams, is het essentieel dat iedereen dezelfde verwachtingen heeft over wat een software-component moet doen.
Ook voor onderhoud en toekomstige uitbreidingen is het belangrijk dat de oorspronkelijke bedoelingen duidelijk blijven, zelfs als de code verandert.
Tenslotte spelen specificaties ook een belangrijke rol bij het gebruik van GenAI om code te genereren: hoe duidelijker en preciezer de specificatie (prompt), hoe beter de gegenereerde code zal aansluiten bij de bedoeling.
Je kan een specificatie zien als een contract tussen verschillende rollen:
de gebruiker of opdrachtgever die gedrag verwacht,
de ontwikkelaar (of AI-model) die dat gedrag implementeert,
de tester die controleert of de implementatie voldoet aan de verwachtingen,
de toekomstige maintainer die code moet aanpassen of uitbreiden zonder het gewenste gedrag te breken.
Intuïtief voorbeeld
Stel dat je een parkeerapp bouwt.
Een mogelijke specificatie van de methode int berekenParkeerkost(int duurInMinuten) is:
het resultaat (de kost) is nooit negatief,
tot en met 30 minuten is de kost 0 euro,
boven 30 minuten betaal je een gekend bedrag (1 euro) per begonnen half uur.
vanaf 6 uur (360 minuten) is er een vast dagtarief van 12 euro.
Die specificatie zegt niets over hoe je dit implementeert.
Je kan intern werken met if-statements, lussen, een tabel, of een formule: allemaal prima, zolang het externe gedrag overeenkomt met de specificatie.
Deze specificatie kan je ook onmiddellijk omzetten in een aantal tests:
Merk op hoe je aan de hand van bovenstaande specificatie zinvolle tests kan ontwerpen zonder te hoeven weten hoe de implementatie eruit ziet (of zal zien, als je volgens TDD eerst de tests schrijft en pas daarna de implementatie).
Specificatie en implementatie
Een specificatie beschrijft dus gedrag zonder codekeuzes. De implementatie wordt gevormd door een keuze van algoritmen, datastructuren, en codeconstructies die dat gewenste gedrag moeten realiseren. Dus:
specificatie (of contract): wat moet waar zijn vanuit het standpunt van de gebruiker,
implementatie: hoe je dat gedrag technisch realiseert.
Voor eenzelfde specificatie zijn gewoonlijk meerdere implementaties mogelijk.
Bijvoorbeeld, gegeven de specificatie van een max-functie die het grootste van 2 getallen teruggeeft, zijn volgende implementaties allemaal correct:
Zolang al deze methodes aan hetzelfde contract voldoen, zijn ze extern equivalent.
Het splitsen van specificatie en implementatie heeft verschillende voordelen:
Refactoren wordt veiliger
Je mag intern herwerken zolang de specificatie (het contract) gelijk blijft.
Samenwerken wordt duidelijker
De grenzen waarbinnen code veranderd mag worden zonder impact te hebben op een ander team worden expliciet gemaakt.
Testen krijgt richting
Tests worden afgeleid uit contracten, en zijn niet sterk gekoppeld aan de implementatie.
Pre- en postcondities van methodes
Om het concept van specificaties concreter te maken, introduceren we de begrippen precondities en postcondities.
Een preconditie is een voorwaarde die waar moet zijn vóór de methode start.
Meer bepaald is het een voorwaarde op de invoer en/of de begintoestand.
De preconditie beschrijft dus de aannames die een methode maakt over zijn omgeving.
Een postconditie is een voorwaarde die waar moet zijn na de methode, tenminste als de preconditie geldig was.
Het is dus een voorwaarde op de uitvoer en/of de eindtoestand.
De postconditie beschrijft dus het gewenste resultaat van de methode (voor alle geldige invoer).
Belangrijk hierbij is de taakverdeling:
de aanroeper van de methode is verantwoordelijk om de preconditie te respecteren,
de methode zelf (of de programmeur ervan) is verantwoordelijk om de postconditie waar te maken.
Een methode is correct geïmplementeerd met betrekking tot een specificatie (pre- en postconditie) als, telkens de preconditie geldt vóór de methode-uitvoering, ook de postconditie geldt na de uitvoering (en de uitvoering blijft niet oneindig doorlopen en gooit geen exception).
Met andere woorden: in elke toestand die aan de preconditie voldoet, zal de uitvoering van de methode gegarandeerd leiden tot een toestand die aan de postconditie voldoet.
Dit is schematisch weergegeven in volgende afbeelding:
We schrijven dit ook als een zogenaamd Hoare-triple $ \{P\}\ C\ \{Q\} $ waarbij P de preconditie is, C het commando (de methode) en Q de postconditie.
Dat betekent exact wat we hierboven beschreven hebben: als P waar is vóór het uitvoeren van C, dan is Q waar na het uitvoeren ervan.
Merk hierbij op dat niet voldoen aan de preconditie niet noodzakelijk leidt tot een fout: het betekent alleen dat er geen garanties zijn over het gevolg. Het is best mogelijk dat de methode eindigt in een toestand die nog steeds voldoet aan de postconditie, maar dat is niet gegarandeerd.
Notatie
Om pre- en postcondities precies te specificeren voor Java-code, halen we in dit hoofdstuk inspiratie uit OpenJML, die JML (Java Modeling Language)-annotaties toevoegt in Java-comments.
De belangrijkste annotaties zijn:
requires ...; voor precondities,
ensures ...; voor postcondities,
\result voor de returnwaarde,
\old(expr) voor de waarde vóór uitvoering,
invariant ...; voor klasse-invarianten,
In code ziet dat er meestal zo uit:
//@ requires ...;//@ensures...;
Concreet voorbeeld:
//@ requires true;//@ ensures \result >= a && \result >= b;//@ ensures \result == a || \result == b;publicstaticintmax(inta,intb){return(a>=b)?a:b;}
Voorbeeld: deling
Hieronder zie je een voorbeeld van een preconditie (weergegeven met requires) en postconditie (weergegeven met ensures) voor een methode divide die een gehele deling uitvoert:
//@ requires a >= 0;//@ requires b > 0;//@ ensures a == b * \result + (a % b);publicstaticintdivide(inta,intb){returna/b;}
Dit betekent:
de correctheid van divide is enkel gegarandeerd als a niet negatief is én b strikt positief is (preconditie),
onder die voorwaarde garandeert de methode de standaard eigenschap van gehele deling in Java, namelijk dat a gelijk is aan b maal het resultaat van de methode plus het restgetal (postconditie).
We kunnen dit ook schrijven als een Hoare-triple:
\[\{a \geq 0 \wedge b > 0\}\ \texttt{divide(a, b)}\ \{a == b * \texttt{\result} + (a \% b)\}\]
Merk bij de postconditie op dat we niet rechtstreeks zeggen hoe\result berekend moet worden.
We leggen enkel een relatie op tussen a, b en \result.
Dat is het mooie van specificaties: ze leggen vast wat er moet gebeuren, zonder te zeggen hoe je dat moet doen.
Merk ook op dat deze implementatie van divide ook werkt als a en/of b negatief zijn.
Maar omdat de preconditie dat niet toestaat, is er geen garantie dat de postconditie nog steeds geldt in die gevallen.
Als programmeur van divide mag je de implementatie later dus wijzigen in een andere implementatie die misschien niet correct werkt voor negatieve getallen, zolang je maar de preconditie respecteert en de postconditie waarmaakt voor geldige invoer.
Een andere implementatie van divide die aan dezelfde specificatie voldoet, maar gebruik maakt van een lus in plaats van de delingsoperator, is bijvoorbeeld:
//@ requires a >= 0;//@ requires b > 0;//@ ensures a == b * \result + (a % b);publicstaticintdivide(inta,intb){intquotient=0;intremainder=a;while(remainder>=b){remainder=remainder-b;quotient=quotient+1;}returnquotient;}
Deze implementatie is misschien minder efficiënt, maar voldoet nog steeds aan dezelfde pre- en postcondities.
Ze werkt echter niet meer correct als a of b negatief zijn (maar dat is geen probleem, want de preconditie sluit die gevallen uit).
Sterke en zwakke pre- en postcondities
Pre- en postcondities kunnen sterker of zwakker zijn.
Een sterke preconditie stelt meer eisen aan de invoer, waardoor er minder situaties zijn waarin de methode correct kan worden opgeroepen.
Een zwakke preconditie stelt minder eisen, waardoor er meer situaties zijn waarin de methode correct kan worden opgeroepen. Dit is meestal de gewenste situatie, omdat het de methode flexibeler maakt.
In termen van verzamelingen van toestanden betekent dit dat een sterke preconditie een kleinere verzameling van geldige invoer toestaat, terwijl een zwakke preconditie een grotere verzameling toestaat.
De zwakst mogelijke preconditie is requires true;, omdat die geen enkele beperking oplegt aan de invoer.
De sterkst mogelijke preconditie is requires false;. Dit laat echter geen enkele invoer toe. Met andere woorden, een methode met requires false; geeft in geen enkele situatie enige garantie over het resultaat.
Voor postcondities:
Een sterke postconditie stelt meer eisen aan het resultaat, waardoor er minder mogelijke implementaties zijn die de postconditie waar maken. Vaak willen we dus een zo sterk mogelijke postconditie, omdat die meer garanties geeft over het gedrag van de methode.
Een zwakke postconditie stelt minder eisen aan het resultaat, waardoor er meer mogelijke implementaties zijn die de postconditie waar maken.
Een sterke postconditie betekent dus dat er minder mogelijke eindtoestanden zijn die aan de postconditie voldoen, terwijl een zwakke postconditie meer mogelijke eindtoestanden toestaat.
De zwakst mogelijke postconditie is ensures true;, omdat die geen enkele uitspraak doet over het resultaat. De sterkst mogelijke postconditie is ensures false;, omdat die geen enkele eindtoestand toestaat. Met andere woorden, een methode met ensures false; kan nooit correct worden geïmplementeerd1, omdat er geen enkele uitvoer of eindtoestand is die aan de postconditie voldoet.
Hieronder zie je, als voorbeeld, een methode max met een zwakke preconditie én een zwakke postconditie:
De postconditie is zwak omdat het toestaat dat \result een waarde is die groter is dan zowel a en b, zoals Integer.MAX_VALUE.
Met andere woorden, volgende implementatie voldoet aan de zwakke postconditie, maar is duidelijk fout als “maximum van twee getallen”:
Die is sterker omdat het nu vereist dat \result precies gelijk is aan a of b, en niet een willekeurige waarde die groter is dan een van beide.
Hetzelfde zie je bij berekenParkeerkost.
Als je als enige postconditie specificeert //@ ensures \result >= 0;, dan is volgende implementatie ook “correct”:
Maar dat schendt duidelijk de bedoeling.
Ook hier zou de specificatie extra regels moeten bevatten, bijvoorbeeld over de drempel van 30 minuten.
In JML zou dat er als volgt kunnen uitzien:
Merk op dat deze specificatie precies vastlegt hoe de parkeerkost berekend wordt.
Dat houdt in dat latere wijzigingen aan de parkeerregels (zoals een ander tarief of een andere drempel) ook een wijziging van de specificatie vereisen.
In sommige gevallen kan dat wenselijk zijn, maar in andere gevallen is deze postconditie te sterk en wil je een meer abstracte specificatie die de exacte berekening niet vastlegt.
Je zou bijvoorbeeld kunnen kiezen voor een specificatie die enkel zegt dat de kost nooit negatief is, en dat de kost niet kan dalen als de parkeerduur langer wordt, zonder de grenzen of het precieze bedrag vast te leggen:
//@ requires duurInMinuten >= 0;//@ ensures \result >= 0;////@ ensures (\forall int d;//@ d >= 0 && d <= duurInMinuten//@ ==> berekenParkeerkost(d) <= \result);publicstaticintberekenParkeerkost(intduurInMinuten){...}
We maken hier gebruik van \forall om te zeggen dat voor alle d tussen 0 en duurInMinuten, de parkeerkost voor d minuten nooit groter mag zijn dan de parkeerkost van duurInMinuten.
Deze specificatie is zwakker dan de vorige versie omdat het niet de exacte drempels of bedragen vastlegt.
Deze specificatie laat ook mogelijk ongewenste implementaties toestaat, zoals een implementatie die altijd 0 teruggeeft.
Ze legt wel nog steeds een belangrijke relatie vast tussen de duur en de kost.
De beste specificatie hangt dus af van de context (bv. hoe vaak de parkeerregels aangepast moeten kunnen worden).
Onthoud
We zijn vaak geïnteresseerd in
een voldoende zwakke preconditie (zodat de methode in zoveel mogelijk situaties kan worden opgeroepen), en
een voldoende sterke postconditie (zodat we heel precieze garanties krijgen over wat de methode precies doet).
Een bruikbare specificatie moet voldoende flexibel zijn, correcte implementaties toelaten, en ook ongewenste implementaties uitsluiten.
Specificaties en wijzigen van toestand
Tot nu toe beschreven we specificaties van individuele methodes, maar we kunnen ook specificaties maken over toestandsveranderingen binnen een object of tussen methodes.
Bijvoorbeeld, voor een BankAccount-klasse kunnen we specificeren dat het saldo nooit negatief mag zijn, en dat een withdraw-methode het saldo met een bepaald bedrag vermindert.
invariant geeft aan dat balanceInCents altijd groter of gelijk aan 0 moet zijn, ongeacht welke methode wordt aangeroepen. Het concept van invarianten komt dadelijk verder aan bod.
spec_public geeft aan dat een private veld toch gebruikt mag worden in specificaties, zodat we het kunnen gebruiken om pre- en postcondities mee te formuleren.
assignable balanceInCents; geeft aan dat deze methode alleen balanceInCents mag wijzigen, en geen andere toestand van het object (of andere objecten).
\old(balanceInCents) verwijst naar de waarde van balanceInCents vóór de methode-uitvoering.
Klasse-invarianten
Contracten per methode zijn sterk, maar bij toestandrijke objecten wil je ook eigenschappen die altijd behouden blijven.
Dat zijn (klasse-)invarianten.
Voor BankAccount gebruikten we:
//@publicinvariantbalanceInCents>=0;
Die invariant moet gelden
nadat de constructor uitgevoerd is; en
voor en na elke uitvoering van een publieke methode.
Dat zijn de zogenaamde zichtbare toestanden van het object. In deze toestanden moet de invariant altijd gelden.
Met andere woorden, je kan erop vertrouwen dat balanceInCents nooit negatief is, ongeacht welke methodes er worden aangeroepen, zolang je maar de precondities respecteert.
Je kan een invariant ook zien als een soort “globale pre- en postconditie” die voor en na elke publieke methode-uitvoering moet gelden.
In plaats van die bij elke methode apart te herhalen, definieer je die als een invariant die altijd behouden moet blijven.
Voorbeelden van nuttige klasse-invarianten
In een User-klasse kan een invariant zijn dat het e-mailadres altijd een geldig formaat heeft, of dat de leeftijd van de gebruiker altijd groter is dan 0.
In een Rectangle-klasse kan een invariant zijn dat de breedte en hoogte altijd positief zijn, en dat de coördinaten van de hoeken consistent zijn (bijvoorbeeld dat de rechterbovenhoek altijd rechts en boven de linksonderhoek ligt).
In een Date-klasse kan een invariant zijn dat de dag, maand en jaar altijd binnen geldige grenzen liggen (bijvoorbeeld dat de dag tussen 1 en 31 ligt, afhankelijk van de maand, en dat de maand tussen 1 en 12 ligt).
In een Employee-klasse kan een invariant zijn dat het salaris altijd groter is dan 0, en dat de werknemer een geldige ID heeft.
Hoare-logica
Hoare-logica is een logica die correctheid beschrijft met Hoare-triples die we eerder gezien hebben:
\[
\{P\}\ C\ \{Q\}
\]
De interpretatie daarvan was:
als preconditie P geldt vóór commando C, dan geldt postconditie Q erna.
OpenJML kan je zien als een praktische, code-nabije manier om dit soort specificatie toe te voegen aan Java-methodes:
P komt overeen met requires,
Q met ensures.
C is de code van de methode zelf.
In Hoare-logica bestaan er wiskundige regels over het toekennen van Hoare-triples gebruikt voor eenvoudige statements, zoals een toewijzing aan een variabele.
Er zijn verder ook regels om te redeneren over samengestelde commando’s, zoals sequenties van statements, conditionele statements, en lussen.
Hiermee kan je bewijzen dat een hele methode correct is, door de pre- en postcondities van individuele statements te combineren.
We gaan hier niet verder op in, maar het is goed om te weten dat er een formele theorie bestaat die precies beschrijft hoe je vanuit de pre- en postcondities van individuele statements de pre- en postconditie van een hele methode correct kan bewijzen.
JML en OpenJML zijn praktische tools die deze theorie toepassen in de context van Java-code.
Oefeningen
Specificatie of implementatie?
Geef voor elke uitspraak aan of die vooral bij de specificatie hoort, of bij de implementatie.
Motiveer telkens kort in één zin.
“De methode indexOf geeft -1 terug als het element niet voorkomt.”
“De methode indexOf gebruikt een for-lus en vergelijkt elk element.”
“Voor binarySearch moet de inputlijst oplopend gesorteerd zijn.”
“De methode gebruikt twee indexen lo en hi.”
“Na withdraw(amount) is het saldo exact oudSaldo - amount.”
“De implementatie gebruikt intern een LinkedList in plaats van een ArrayList.”
Antwoorden
Specificatie: dit beschrijft het gewenste gedrag van de methode zonder te zeggen hoe het geïmplementeerd is.
Implementatie: dit beschrijft hoe de methode intern werkt, wat een specifieke keuze van algoritme en datastructuur impliceert.
Specificatie: dit is een vereiste voor het correct functioneren van binarySearch, maar zegt niets over hoe die vereiste wordt geïmplementeerd.
Implementatie: dit is een specifieke keuze in de code die aangeeft hoe de methode werkt, en is niet noodzakelijk voor het gewenste gedrag.
Specificatie: dit beschrijft het gewenste resultaat van de withdraw-methode, en is een garantie die de methode moet waarmaken, ongeacht hoe het intern is geïmplementeerd.
Implementatie: dit is een specifieke keuze van datastructuur die de interne werking van de methode beïnvloedt, maar heeft geen invloed op het contract dat de methode moet naleven.
Specificatie van indexOf
Schrijf een specificatie (pre- en postcondities) voor een methode indexOf die een element x zoekt in een lijst van gehele getallen, en de index teruggeeft als x voorkomt, of -1 als x niet voorkomt.
Volgende elementen moeten aanwezig zijn in de specificatie:
de preconditie dat de lijst niet null is,
de postconditie dat als x niet voorkomt, het resultaat -1 is,
de postconditie dat als het resultaat niet -1 is, het een geldige index is binnen de lijst,
de postconditie dat als het resultaat niet -1 is, het element op die index gelijk is aan x.
indexOf bij gesorteerde lijsten
Stel dat we een efficiëntere versie van indexOf uit de vorige oefening willen schrijven, gebruik makend van binary search (de details zijn niet belangrijk).
Dat vereist dat de inputlijst gesorteerd is.
Wat is het effect op de specificatie van indexOf als we deze eis toevoegen?
Antwoord
We moeten een extra preconditie toevoegen die vereist dat de inputlijst gesorteerd is. Bijvoorbeeld:
Deze extra preconditie requires isSorted(list); geeft aan dat de methode alleen correct werkt als de lijst gesorteerd is, wat een belangrijke beperking is voor het gebruik van deze specifieke implementatie van indexOf.
Transfer
Stel dat we volgende transfer-methode hebben tussen twee bankrekeningen:
Stel dat we enkel geïnteresseerd zijn in het feit dat geld niet verdwijnt tijdens de transfer, maar we willen niet vastleggen hoe het precies verdeeld wordt tussen from en to.
Hoe zou je een postconditie kunnen formuleren die dit expliciet maakt?
Antwoord
Om expliciet te maken dat geld niet verdwijnt tijdens de transfer, kunnen we een ensures-clausule toevoegen die stelt dat de totale hoeveelheid geld in beide rekeningen samen gelijk blijft. Bijvoorbeeld:
Formuleer een klasse-invariant die deze fout voorkomt.
Pas het ontwerp van de klasse aan zodat de invariant altijd behouden blijft.
Voeg een removeLast-methode toe die de laatste temperatuur verwijdert. Geef de pre- en postcondities van deze methode, en zorg ervoor dat de invariant behouden blijft.
Is er een andere (ongewenste) implementatie van removeLast die ook voldoet aan jouw specificatie? Zo ja, hoe zou je die kunnen uitsluiten?
Antwoord
De fout in deze klasse is dat de average-methode een deling door nul kan veroorzaken als er geen temperaturen zijn toegevoegd aan de values-lijst. Dit gebeurt wanneer values.size() gelijk is aan 0.
Een nuttige klasse-invariant is dat de lijst values nooit leeg mag zijn. Dus we kunnen de invariant formuleren als: //@ invariant values.size() > 0;.
Om het ontwerp aan te passen zodat de invariant altijd behouden blijft, kunnen we ervoor zorgen dat er altijd minstens één temperatuur in de lijst staat bij het aanmaken van een TemperatureLog. Bijvoorbeeld:
In dit aangepaste ontwerp is er een constructor die een initiële temperatuur vereist, waardoor de invariant values.size() > 0 altijd behouden blijft. Hierdoor kunnen we veilig de average-methode aanroepen zonder het risico op een deling door nul.
De removeLast-methode kan als volgt worden toegevoegd:
//@ requires values.size() > 1;//@ ensures values.size() == \old(values.size()) - 1;publicvoidremoveLast(){if(values.size()<=1){thrownewIllegalStateException("Cannot remove last temperature, invariant would be violated.");}values.remove(values.size()-1);}
In deze removeLast-methode hebben we een preconditie toegevoegd die vereist dat er meer dan één temperatuur in de lijst moet zijn voordat we er één kunnen verwijderen. Dit zorgt ervoor dat de invariant values.size() > 0 behouden blijft, omdat we nooit de laatste temperatuur zullen verwijderen als er maar één is. De postconditie geeft aan dat de grootte van de lijst met precies één is verminderd na het uitvoeren van deze methode.
Een ongewenste implementatie van removeLast zou kunnen zijn dat we de hele lijst leegmaken en terug opvullen met nullen, in plaats van slechts één element te verwijderen, bijvoorbeeld:
publicvoidremoveLast(){intoldSize=values.size();values.clear();for(inti=0;i<oldSize-1;i++){values.add(0.0);// voeg nullen toe in plaats van de laatste temperatuur te verwijderen}}
Deze implementatie voldoet ook aan de preconditie en postconditie van hierboven, maar is duidelijk niet wat we bedoelen met “removeLast”. Om dit soort ongewenste implementaties uit te sluiten, kunnen we de postconditie versterken door expliciet te eisen dat alleen het laatste element wordt verwijderd, en dat alle andere elementen behouden blijven. Bijvoorbeeld:
//@ requires values.size() > 1;//@ ensures values.size() == \old(values.size()) - 1;//@ ensures (\forall int i; 0 <= i && i < values.size(); values.get(i) == \old(values.get(i)));publicvoidremoveLast(){if(values.size()<=1){thrownewIllegalStateException("Cannot remove last temperature, invariant would be violated.");}values.remove(values.size()-1);}
In deze versterkte postconditie geven we aan dat alle elementen behalve het laatste element gelijk moeten blijven aan hun oude waarde, waardoor we duidelijk maken dat alleen het laatste element verwijderd mag worden. Dit sluit de ongewenste implementatie uit.
Sterk of zwak
Gegeven volgende methodes met hun specificaties, zeg of de pre- en postcondities (te) sterk of zwak zijn, en motiveer kort waarom.
Verbeter waar mogelijk.
De preconditie requires true; is zwak, omdat het geen enkele beperking oplegt aan de invoer. Dit is wenselijk in dit geval, omdat er geen zinnige beperkingen zijn.
De postconditie ensures \result >= 0; is te zwak, omdat het toestaat dat \result een willekeurige niet-negatieve waarde kan zijn, zoals Integer.MAX_VALUE, zelfs als x negatief is. Een sterkere specificatie zou zijn:
//@ requires true;//@ensures\result==(x>=0?x:-x);
//@ requires x >= 0;//@ ensures \result == x * x;publicstaticintsquare(intx){returnx*x;}
Antwoord
De preconditie requires x >= 0; is te sterk, omdat het een duidelijk onnodige beperking oplegt aan de invoer. De methode square kan ook correct werken voor negatieve getallen. Een betere (zwakkere) preconditie zou zijn:
//@ requires true;//@ensures\result==x*x;
De postconditie ensures \result == x * x; is voldoende sterk, omdat ze precies specificeert wat de uitvoer moet zijn.
De preconditie requires true; is iets te zwak. We kunnen een preconditie toevoegen die vereist dat de lijst niet null is, bijvoorbeeld requires list != null;, omdat het sorteren van een null-lijst niet zinvol is en waarschijnlijk een exception zou veroorzaken.
De postconditie ensures isSorted(\result); is ook te zwak, omdat het enkel oplegt dat de uiteindelijke lijst gesorteerd is, maar niet noodzakelijkerwijs dezelfde elementen bevat als de oorspronkelijke lijst. Met andere woorden, een implementatie die de lijst leegmaakt of vervangt door een andere gesorteerde lijst zou nog steeds aan deze postconditie voldoen, maar dat is niet wat we willen.
Een betere (sterkere) postconditie zou zijn dat de gesorteerde lijst een permutatie is van de oorspronkelijke lijst.
Dat houdt in dat
de lijst is even lang is gebleven; en
alle elementen van de oorspronkelijke lijst nog steeds (even vaak) aanwezig zijn in de gesorteerde lijst.
Een mogelijke formulering van deze sterkere postconditie, met behulp van een te definiëren functie countOccurrences, is:
//@ requires list != null;//@ ensures isSorted(\result);//@ ensures \result.size() == \old(list.size());//@ ensures (\forall int i; 0 <= i && i < \result.size(); //@countOccurrences(\result,\result.get(i))==countOccurrences(\old(list),\result.get(i)));
Specificaties voor backtracking-oefeningen
Schrijf een specificatie (pre- en postcondities) voor de volgende methodes uit de oefeningen over backtracking.
Dat mag informeel (in woorden) in plaats van formeel met JML-annotaties, maar probeer wel zo precies mogelijk te zijn in je formulering.
Token-segmentatie (waar elke token slechts eenmalig gebruikt mag worden)
Antwoord
Pre-conditie:
De invoerlijst van tokens is niet null.
De te segmenteren string is niet null.
Post-conditie:
Als er geen segmentatie mogelijk is, dan is het resultaat null.
Als er een segmentatie mogelijk is, dan is het resultaat een lijst die voldoet aan volgende voorwaarden:
alle elementen uit de lijst zijn tokens uit de invoerlijst
het aantal keer dan een token voorkomt in het resultaat is niet groter dan het aantal keer dat het voorkomt in de invoerlijst
als we de tokens in het resultaat achter elkaar plakken, krijgen we precies de te segmenteren string terug.
Uurrooster-planner
Antwoord
Pre-conditie:
De lijst van vakken is niet null.
De planningparameters zijn niet null.
Het maximaal aantal slots is een positief getal.
Het maximaal aantal vakken per slot is een positief getal.
Elk vak heeft een niet-null verzameling van personen.
Post-conditie:
Als er geen rooster mogelijk is, dan is het resultaat null.
Als er een rooster mogelijk is, dan is het resultaat een Planning-object dat voldoet aan volgende voorwaarden:
elk vak uit de invoerlijst is precies één keer ingeroosterd in een slot
elk gebruikt slot is kleiner dan het maximaal aantal slots
er zijn nooit meer vakken in hetzelfde slot dan het maximaal aantal vakken per slot
er is geen persoon die in twee verschillende vakken is ingeroosterd in hetzelfde slot
er bestaat geen planning waarbij het hoogst gebruikte slotnummer lager is dan in het resultaat
Traveling Sales Person
Antwoord
Pre-conditie:
De startlocatie is niet null.
De lijst van andere locaties is niet null.
De startlocatie mag niet voorkomen in de lijst van andere locaties (omdat we elke locatie precies één keer moeten bezoeken, en we al beginnen bij de startlocatie).
Post-conditie:
Als er geen geldige route mogelijk is, dan is het resultaat null.
Als er een geldige route mogelijk is, dan is het resultaat een Route-object dat voldoet aan volgende voorwaarden:
de route begint en eindigt bij de startlocatie
elke locatie uit de lijst van andere locaties komt precies één keer voor in de route
de totale afstand van de route is kleiner dan of gelijk aan de afstand van elke andere mogelijke route die aan bovenstaande voorwaarden voldoet.
In de praktijk zou een methode met ensures false; kunnen worden geïmplementeerd als een methode die altijd een exception gooit of oneindig blijft lopen, omdat er dan strikt genomen geen eindtoestand is, maar dat is meestal niet de bedoeling. ↩︎
10. AI in software engineering
AI is een krachtig hulpmiddel dat softwareontwikkeling kan versnellen, maar het brengt ook nieuwe uitdagingen en overwegingen met zich mee.
In dit hoofdstuk bekijken we hoe je AI praktisch en verantwoord inzet tijdens software engineering.
Hoe werken LLMs?
Wanneer we in software engineering over AI spreken, bedoelen we meestal een Large Language Model (LLM). Intuïtief is een LLM een systeem (in de vorm van een diep neuraal netwerk) dat een tekst (en/of code) stukje per stukje aanvult. Het kijkt naar wat er al staat, en kiest daarna een volgende stukje tekst, waarbij het meer waarschijnlijke vervolg met meer kans gekozen worden.
Vervolgens kijkt het model naar de nieuwe tekst, en kiest opnieuw een volgend stukje, enzovoort.
Dat stuk per stuk aanvullen heet autoregressief genereren (auto = zelf, regressie = gebaseerd op vorige stukjes, dus gebaseerd op vorige stukjes die het eerder zelf gegenereerd heeft).
Een voorbeeld: als we een LLM vragen om volgende zin te vervolledigen:
Beter één
dan zal het model als volgend woord waarschijnlijk vogel kiezen.
Vervolgens vervolgens zal het model kijken naar de nieuwe tekst Beter één vogel en als volgende woord waarschijnlijk in kiezen, enzovoort, tot het een volledige zin heeft gegenereerd: Beter één vogel in de hand dan tien in de lucht.
Maar in plaats van vogel had het model ook voor goede kunnen kiezen, en dat verder vervolledigen tot Beter één goede vriend dan tien slechte vrienden.
Het model bouwt dus geen antwoord in één keer op, of bepaalt op voorhand niet welke richting het uitgaat.
Het kiest gewoon steeds het volgende stuk tekst, dan het volgende, en zo verder tot een volledige output ontstaat.
Een LLM zelf heeft, omwille van het autoregressieve karakter, dus ook geen manier om een vorig woord te herzien of te corrigeren, behalve door het volgende woord te kiezen dat een correctere zin oplevert1.
Een voorbeeld uit de software engineering context: stel dat de LLM gevraagd wordt om volgende tekst aan te vullen:
publicstaticintadd(inta,intb){return
Een waarschijnlijke aanvullig hiervoor is a + b;, en het model zal dat dan waarschijnlijk ook voorstellen. Dat lijkt op “begrijpen”, maar technisch is het vooral patroonherkenning op basis van heel veel eerdere voorbeelden, alsook de geleerde samenhang tussen het woord add en de +-operator.
Tokens
Een “stukje” tekst noemen we een token.
Hierboven gebruikten we volledige woorden als tokens, maar in werkelijkheid zijn tokens meestal kleinere woorddelen of zelfs individuele letters.
Je kan dat ruwweg zien als een klein fragment: een woorddeel, operator, haakje, enzovoort.
Op deze webpagina kan je zien hoe OpenAI/ChatGPT een tekst opsplitst in tokens.
Bijvoorbeeld, de zin Beter één vogel in de hand dan tien in de lucht. wordt bij OpenAI opgesplitst in 13 tokens:
Beter␣één␣vogel␣in␣de␣hand␣dan␣tien␣in␣de␣lucht.
Merk op dat de hoofdletter B een apart token is, en heel wat tokens bestaan uit een spatie gevolgd door een woord.
Niet elk model gebruikt dezelfde tokenisatie, maar het concept van tokens is universeel in LLMs.
Het aantal tokens dat een model kan verwerken in één keer (het “contextvenster”) is een belangrijke beperking, omdat het bepaalt hoeveel tekst het model kan zien en gebruiken bij het genereren van output.
Embeddings
Een LLM leert niet alleen patronen in tekst, maar ook een soort “betekenis” van woorden en zinnen, door ze te representeren als vectoren in een zeer hoog-dimensionale ruimte (duizenden dimensies). Deze vectoren worden “embeddings” genoemd. Ze stellen het model in staat om semantische relaties tussen woorden te begrijpen, zoals dat koning en koningin dichter bij elkaar liggen dan koning en auto. Embeddings zijn cruciaal voor het genereren van coherente en contextueel relevante output.
In de praktijk zal elke token omgezet worden in een overeenkomstige embedding-vector voordat het model er een volgend token op gaat voorspellen. Dat betekent dat het model niet rechtstreeks met tekst werkt, maar met deze vectorrepresentaties van tekst.
Net zoals bij tokens kunnen verschillende modellen ook verschillende embeddings gebruiken, maar het concept van het representeren van tekst als vectoren is een fundamenteel onderdeel van hoe LLMs werken.
Transformer architecture
Zowat elke LLM is tegenwoordig gebaseerd op de transformer-architectuur (geïntroduceerd in 2017 in de paper Attention is All You Need). Deze architectuur maakt gebruik van een mechanisme genaamd “self-attention”, waarmee het model kan bepalen hoe woorden (tokens) elkaar beïnvloeden en welke delen van de inputtekst het meest relevant zijn voor het genereren van het volgende token. Dit stelt het model in staat om lange-afstandsrelaties in tekst te begrijpen, wat cruciaal is voor het genereren van coherente en contextueel relevante output.
Deze self-attention is ook een van de voornaamste redenen waarom LLMs een contextvenster hebben met beperkte lengte.
Omdat elk woord elk ander woord kan beïnvloeden, moet het model alle woorden in het contextvenster met elkaar vergelijken.
Voor 1000 tokens betekent dat 1 miljoen vergelijkingen, voor 2000 tokens 4 miljoen, enzovoort.
Instruction tuning
Een LLM zelf is eigenlijk enkel een tekstvoorspeller die een bestaande tekst verder uitbreidt.
Als je aan een ‘pure’ LLM zou vragen om de tekst
Hoe bak ik een brood?
aan te vullen, dan zou het best kunnen dat je dit als aanvulling krijgt:
Deze vraag stellen mensen zich al sinds de oudheid, want brood is een van de oudste en meest fundamentele voedingsmiddelen. Het proces van brood bakken is een combinatie van wetenschap, kunst en geduld.
Als we een LLM als chatbot of assistent willen gebruiken, willen we echter een concreet antwoord krijgen op de vraag, zoals een recept of stapsgewijze instructies.
Om dat te doen, wordt de aan te vullen tekst opgedeeld in een afwisseling van “systeem”, “gebruiker” en “model” berichten, waarbij het systeem een instructie geeft aan het model over hoe het zich moet gedragen, de gebruiker een vraag stelt of een opdracht geeft, en het model een antwoord genereert.
Deze instructies kunnen heel krachtig zijn, omdat ze de context van het model sturen en de mogelijke vervolgen beperken.
Bijvoorbeeld, je vraagt aan het model om volgende tekst aan te vullen:
<Systeem> Je bent een behulpzame assistent.
<Gebruiker> Hoe bak ik een brood?
<Model>
In het begin van LLM-gebaseerde assistenten werd dit gedaan met een ’trucje’, door bijvoorbeeld volgende tekst te laten aanvullen:
Dit is een conversatie tussen een gebruiker en een behulpzame assistent. De assistent geeft duidelijke, stapsgewijze instructies om de vraag van de gebruiker te beantwoorden.
<Gebruiker> Hoe bak ik een brood?
<Assistent>
Tegenwoordig wordt een LLM specifiek getraind om instructies van gebruikers op te volgen. Dit proces heet instruction tuning en vormt een belangrijke stap in de ontwikkeling van chatbots en AI-assistenten. Daarbij wordt het model getraind op voorbeelden van instructies en bijbehorende gewenste antwoorden, zodat het leert hoe het adequaat moet reageren op verschillende soorten prompts.
Daarnaast wordt vaak gebruikgemaakt van RLHF (Reinforcement Learning from Human Feedback). Hierbij beoordelen mensen de kwaliteit van modelantwoorden, en die feedback wordt gebruikt om het model verder te optimaliseren zodat het nuttigere, relevantere en veiligere antwoorden genereert.
Van veel (open weight) modellen zijn er verschillende versies, waaronder een basismodel (een algemene tekstvoorspeller) en een instructie-getunede versie.
Hallucinaties
Een LLM genereert tekst op basis van statistische patronen die het tijdens training heeft geleerd, niet op basis van een expliciet begrip van waarheid of feitelijke correctheid.
Die voorspellingen steunen op veel meer dan enkel woordfrequenties: het model leert bv. ook complexe patronen in taal en de betekenis van woorden. Toch blijft het fundamenteel een systeem dat voorspelt welke tekst waarschijnlijk volgt op eerdere tekst.
Een standaard-LLM controleert daarbij niet expliciet of uitspraken waar zijn, zoekt niet automatisch informatie op in betrouwbare bronnen, en beschikt doorgaans niet over expliciete kennis van de oorsprong van zijn informatie2. Daarom kan een LLM geen garantie geven dat gegenereerde antwoorden correct zijn.
De formulering van je prompt heeft een grote invloed op het resultaat. Als jij vaag bent, zijn er veel mogelijke vervolgen die allemaal “kloppen” binnen de statistische patronen van het model.
Als jij daarentegen expliciet bent over randvoorwaarden en context, beperk je de mogelijke vervolgen en verhoog je de kans op een correct antwoord.
Daarom krijg je in praktijk betere output met concrete prompts dan met korte algemene vragen.
Een instructie geven aan het model zoals “hallucineer niet, verifieer je informatie” is weinig effectief (vergelijk het met zeggen tegen iemand die niet kan koken om enkel lekkere gerechten te maken).
Het model kan enkel de volgende token kiezen op basis van waarschijnlijkheid, en niet op basis van een begrip van waarheid of logica.
Het enige (waarschijnlijk beperkte) effect van deze instructie is dat de kans van een vervolg dat statistisch geassocieerd is met welgekende onwaarheden kleiner wordt.
Hierdoor zal de LLM dat vervolg minder snel kiezen. Maar dat is geen garantie dat het model niet alsnog een fout antwoord genereert.
Opnieuw in de keuken-analogie: het helpt de slechte kok misschien om zich te beperken tot traditionele en daarvoor veilige smaakcombinaties, maar verhindert niet dat er alsnog iets oneetbaar ontstaat.
Voor deze cursus volstaat dit mentaal model: een LLM is een zeer geavanceerde “volgende-stap-voorspeller” voor tekst en code.
Gebruik het als snelle assistent voor voorstellen, maar niet als automatische waarheidsmachine.
Reasoning
Van moderne LLM’s wordt vaak gezegd dat ze kunnen redeneren (reasoning models).
Dat is niet helemaal correct, omdat in de LLM zelf geen expliciete redeneercapaciteit ingebouwd zit: het blijft een voorspeller van volgende tokens.
Wat wordt er dan bedoeld met “reasoning” in de context van LLMs?
In essentie komt het erop neer dat de LLM niet meteen het antwoord begint te formuleren, maar eerst een soort “tussenstappen” genereert die lijken op een redenering of een gedachtegang.
Deze tussenstappen komen terecht in de context voor de voorspelling van volgende woorden, en tenslotte het antwoord.
Ze worden echter niet (standaard) getoond aan de eindgebruiker.
Een bekende techniek hiervoor is de zogenaamde chain of thought (CoT). Hierbij wordt het model expliciet gevraagd (of getraind) om eerst zijn redenering in stappen te formuleren, voordat het tot een antwoord komt. Met andere woorden, luidop nadenken. Bijvoorbeeld:
Gebruiker: Als ik groter ben dan mijn broer, en mijn broer groter is dan mijn zus, wie is er dan het kleinst?
Model: <Reasoning> De gebruiker vraagt wie het kleinst is in de gegeven situatie. Laten we de informatie stap voor stap analyseren:
1. Ik ben groter dan mijn broer. (Ik > Broer)
2. Mijn broer is groter dan mijn zus. (Broer > Zus)
3. Uit de eerste twee stappen kunnen we afleiden dat ik ook groter ben dan mijn zus, door de transitiviteit van >. (Ik > Zus)
4. Dus, de volgorde van grootte is: Ik > Broer > Zus.
</Reasoning>
Jouw zus is het kleinst.
Geavanceerdere technieken, zoals (Tree of Thoughts)[https://proceedings.neurips.cc/paper_files/paper/2023/file/271db9922b8d1f4dd7aaef84ed5ac703-Paper-Conference.pdf], gaan nog een stap verder en plaatsen een extra sturingslaag rond het model om het redeneerproces te plannen, evalueren en bij te sturen.
Daarbij kan hetzelfde model meerdere keren worden aangeroepen om verschillende mogelijke redeneringspaden of plannen te genereren. Vervolgens kunnen die plannen opnieuw door het model (of door bijkomende evaluatiemechanismen) beoordeeld worden, waarna het meest veelbelovende pad geselecteerd wordt om verder uit te werken.
Bij alle redeneer-technieken is het belangrijk om te beseffen dat het model nog steeds een volgende-token-voorspeller is, en dat de “redenering” die het genereert niet noodzakelijkerwijs logisch of correct is. Het model kan bijvoorbeeld een redenering genereren die er plausibel uitziet, maar toch fouten bevat of tot een onjuist antwoord leidt. Daarom is het cruciaal om de output van dergelijke redeneerprocessen kritisch te evalueren en waar nodig te corrigeren.
Tool calls
Een belangrijke uitbreiding op de standaardwerking van een LLM is dat het model niet alleen tekst kan genereren, maar ook externe tools kan aanroepen of informatie kan opvragen via zogenaamde tool calls (ook wel function calling genoemd).
Daarbij genereert het model niet enkel gewone tekst, maar ook een gestructureerde representatie van een gewenste actie, bijvoorbeeld het opvragen van informatie, het uitvoeren van een berekening, of het raadplegen van een externe API.
Hiermee geeft het model aan dat het de weather_api tool wil aanroepen met de parameter location=“Amsterdam”.
De omgeving rond het model (het systeem dat de LLM aanstuurt) herkent deze tool call, voert de bijbehorende actie uit, en geeft het resultaat vervolgens terug aan het model als bijkomende context. Het model kan die informatie daarna gebruiken om een beter geïnformeerd antwoord te genereren.
Belangrijk is dat de LLM zelf geen directe toegang heeft tot externe systemen. Het model genereert enkel tekst of gestructureerde output die een tool call voorstelt; het is de software rond het model die beslist of en hoe die tool call effectief uitgevoerd wordt.
De mogelijkheid om tool calls te maken is niet standaard in een LLM, maar vereist specifieke training: de LLM moet leren om de juiste syntax te gebruiken voor tool calls.
Daarnaast moet er een infrastructuur zijn die deze tool calls kan herkennen en uitvoeren, en de resultaten terug kan geven aan het model. Deze combinatie van LLM met tool calls maakt het mogelijk om veel krachtigere en contextueel relevante antwoorden te genereren, omdat het model nu toegang heeft tot actuele informatie en specifieke functionaliteiten die het zelf niet kan genereren.
Hoe weet een LLM welke tools er beschikbaar zijn en hoe die werken?
Een eenvoudige techniek is om de beschikbare tools expliciet mee te geven in de prompt of systeemcontext. Bijvoorbeeld:
<Systeem>
Je bent een behulpzame assistent. Je hebt toegang tot de volgende tools:
1. weather_api:
vraagt het weer op voor een gegeven locatie.
Gebruik:
<tool_call>
{
"tool": "weather_api",
"parameters": {
"location": "<locatie>"
}
}
</tool_call>
2. calculator:
voert eenvoudige wiskundige berekeningen uit.
Gebruik:
<tool_call>
{
"tool": "calculator",
"parameters": {
"expression": "<uitdrukking>"
}
}
</tool_call>
Op die manier krijgt het model informatie over welke tools bestaan, waarvoor ze dienen, en hoe ze correct aangeroepen moeten worden.
Model Context Protocol (MCP)
Model Context Protocol (MCP) definieert een gestandaardiseerde manier waarop externe programma’s tools, databronnen en functionaliteiten beschikbaar kunnen maken aan een LLM. In plaats van voor elke toepassing een aparte integratie te bouwen, kan een LLM-client via MCP dynamisch ontdekken welke tools beschikbaar zijn, welke parameters ze verwachten, en hoe ze aangeroepen moeten worden.
Daardoor kan hetzelfde model in verschillende omgevingen met verschillende tools werken zonder specifiek voor die tools getraind te moeten worden. De intelligentie rond toolgebruik zit grotendeels in het algemene vermogen van het model om instructies en gestructureerde context te interpreteren.
Een veelgebruikte toepassing van MCP is integratie met een command line interface (CLI). Daarbij kan een LLM bijvoorbeeld toegang krijgen tot shellcommando’s, programmeertools, versiebeheersystemen zoals Git, of build- en testomgevingen. De LLM genereert dan geen rechtstreekse systeemaanroepen, maar gestructureerde instructies die door een MCP-server of orchestration layer vertaald worden naar concrete CLI-commando’s.
Zo kan een model bijvoorbeeld bestanden opzoeken, tests uitvoeren, logs analyseren of code compileren. Het resultaat van die acties wordt vervolgens teruggegeven aan het model als bijkomende context, zodat het verder kan redeneren of antwoorden genereren.
Fundamenteel blijft de LLM echter een volgende-token-voorspeller: het model voert zelf geen commando’s uit, maar genereert enkel output die door externe software geïnterpreteerd en uitgevoerd kan worden.
Welke verschillende soorten tools zijn er?
Chat-UI
De eenvoudigste vorm van AI-ondersteunde softwareontwikkeling gebeurt via een klassieke chatinterface, zoals ChatGPT, Claude, of Google Gemini. Daarbij beschrijft de gebruiker een programmeerprobleem in natuurlijke taal, waarna het model code, uitleg of suggesties genereert.
De context die het model heeft is hier meestal beperkt tot de huidige conversatie, eventueel geüploade bestanden, en expliciet meegestuurde codefragmenten.
Daardoor werkt een chatinterface goed voor kleinere of afgebakende taken (zoals het genereren van kleine codefragmenten of uitleg vragen), maar minder goed voor complexe softwareprojecten met veel onderlinge afhankelijkheden.
Een belangrijk voordeel van een chat-UI is de lage instapdrempel: er is geen integratie met een ontwikkelomgeving nodig, en de interactie verloopt volledig via natuurlijke taal.
IDE-integratie
Een tweede categorie bestaat uit AI-tools die rechtstreeks geïntegreerd zijn in een IDE zoals Visual Studio Code, IntelliJ, of gespecialiseerde AI-first editors zoals Cursor.
In tegenstelling tot een losse chatinterface heeft het model hier toegang tot veel rijkere context over het softwareproject. Het systeem kan bijvoorbeeld informatie gebruiken over de projectstructuur, meerdere broncodebestanden, type-informatie, compileerfouten, testresultaten en versiebeheer. Daardoor kunnen IDE-geïntegreerde assistenten veel geavanceerdere ondersteuning bieden, zoals intelligente code completion, refactorings, projectbrede wijzigingen of contextgevoelige codegeneratie.
Veel moderne IDE-tools combineren klassieke autocomplete met chatfunctionaliteit en tool use. Het model kan bijvoorbeeld relevante bestanden zoeken, symbolen analyseren, terminalcommando’s uitvoeren of tests starten. Omdat het model toegang heeft tot de volledige ontwikkelcontext, zijn de gegenereerde suggesties doorgaans consistenter en beter afgestemd op de bestaande codebase dan bij een losse chatinterface.
Agentische UI/CLI
Een derde categorie bestaat uit zogenaamde agentische systemen (bv. Claude Code CLI of OpenAI Codex). Daarbij beperkt het model zich niet tot het beantwoorden van één prompt, maar probeert het zelfstandig een grotere programmeertaak uit te voeren via meerdere opeenvolgende stappen.
Deze systemen werken vaak via een terminalinterface (CLI) of een gespecialiseerde agentische UI. Het model krijgt dan toegang tot tools zoals shellcommando’s, programmeertools, versiebeheer, testframeworks, buildsystemen of deployment-tools. Een agentisch systeem kan bijvoorbeeld eerst een codebase analyseren, vervolgens relevante bestanden zoeken, code aanpassen, tests uitvoeren, foutmeldingen interpreteren en daarna bijkomende wijzigingen uitvoeren totdat een taak succesvol afgerond lijkt.
De “agentische” component zit grotendeels in de software rond het model. Een orchestration layer bepaalt welke tool calls uitgevoerd worden, geeft resultaten terug aan het model en organiseert iteratieve feedbacklussen waarin het model zijn eerdere resultaten kan evalueren en bijsturen.
Dergelijke systemen zijn bijzonder krachtig voor grotere softwaretaken, maar brengen ook extra complexiteit mee. Omdat het model autonoom meerdere acties na elkaar kan uitvoeren, wordt het moeilijker om elke stap volledig te controleren of voorspellen. Daarom blijven menselijke validatie en toezicht essentieel, zeker wanneer agentische systemen wijzigingen uitvoeren aan grotere codebases of productieomgevingen.
Skills en gespecialiseerde agents
Veel moderne AI-systemen ondersteunen zogenaamde skills: herbruikbare pakketten van instructies, context, tools en workflows die een model gespecialiseerd gedrag geven voor een bepaalde taak. In agentische systemen spelen skills vaak een belangrijke rol. Een agent kan afhankelijk van de taak verschillende gespecialiseerde skills activeren.
Net zoals bij tool calls krijgt het model een overzicht van welke skills beschikbaar zijn, en kan het die dynamisch inzetten op basis van de context en de vereisten van de taak.
Conceptueel lijken skills op een combinatie van configuratie, prompt engineering, toolintegratie, en domeinspecifieke automatisering. Ze maken het mogelijk om een algemeen LLM gedeeltelijk te specialiseren of te aligneren op een specifieke werkwijze zonder het model opnieuw te trainen.
In de praktijk worden skills vaak beschreven in een SKILL.md bestand, waarin de functionaliteit, parameters, en gebruiksinstructies van de skill worden vastgelegd. Het model kan dat bestand lezen en gebruiken als context om te bepalen wanneer en hoe de skill in te zetten.
Een zeer populaire skill is bijvoorbeeld de ‘grill-me’ skill.
Deze is slechts enkele regels lang, en laat het model de gebruiker ondervragen over een plan of ontwerp tot alle details uitgeklaard zijn.
---
name: grill-me
description: Interview the user relentlessly about a plan or design until reaching shared understanding, resolving each branch of the decision tree. Use when user wants to stress-test a plan, get grilled on their design, or mentions "grill me".
---
Interview me relentlessly about every aspect of this plan until we reach a shared understanding. Walk down each branch of the design tree, resolving dependencies between decisions one-by-one. For each question, provide your recommended answer.
Ask the questions one at a time.
If a question can be answered by exploring the codebase, explore the codebase instead.
Software schrijven met AI: aanpak
Vibe coding
De term vibe coding verwijst naar een informele manier van softwareontwikkeling waarbij de programmeur vooral op hoog niveau beschrijft wat een systeem moet doen, terwijl een LLM grote delen van de concrete implementatie genereert. De interactie verloopt meestal via natuurlijke taal: de gebruiker beschrijft gewenste functionaliteit, vraagt wijzigingen, geeft feedback op gegenereerde code en stuurt iteratief bij.
Bij vibe coding verschuift de focus van het handmatig schrijven van code naar het begeleiden, evalueren en corrigeren van gegenereerde code. De programmeur werkt meer als een reviewer of architect die de globale richting bepaalt, terwijl het model veel implementatiedetails invult.
Deze aanpak werkt bijzonder goed voor prototypes, kleine scripts of tools, experimentele projecten, of wanneer de programmeur snel een werkend voorbeeld wil hebben om verder mee te werken. Het is ook een krachtige manier om te leren: door te zien hoe een LLM code genereert op basis van een beschrijving, kan een programmeur nieuwe patronen, bibliotheken of technieken ontdekken.
Omdat moderne LLM’s grote hoeveelheden programmeerpatronen hebben geleerd, kunnen ze vaak verrassend snel werkende code genereren voor veelvoorkomende problemen.
Tegelijk brengt vibe coding ook risico’s mee. Het model kan immers code genereren die niet doet wat de programmeur bedoelt, of code die er op het eerste gezicht correct uitziet maar in werkelijkheid fouten bevat. Het is ook mogelijk dat de gegenereerde code moeilijk te begrijpen of te onderhouden is, vooral als het model complexe patronen gebruikt die niet goed aansluiten bij de rest van de codebase. Daarom is het belangrijk om gegenereerde code altijd kritisch te beoordelen, en niet zomaar aan te nemen dat het correct is.
Bij grotere softwareprojecten kan een puur iteratieve “prompt → code → prompt → code”-workflow daarom snel leiden tot inconsistente architecturen of moeilijk onderhoudbare codebases. Vibe coding werkt meestal het best wanneer de programmeur voldoende expertise heeft om gegenereerde code kritisch te beoordelen.
Spec-driven development met AI
Een meer gestructureerde aanpak bestaat uit spec-driven development met AI. Daarbij gebruikt men natuurlijke taal niet alleen om losse codefragmenten te genereren, maar om expliciete specificaties, ontwerpdocumenten en plannen op te stellen die als basis dienen voor verdere codegeneratie.
In plaats van rechtstreeks te vragen “Schrijf een webapplicatie” werkt men eerder stapsgewijs:
de vereisten beschrijven;
een architectuur definiëren;
interfaces en datamodellen vastleggen;
componenten opdelen;
en pas daarna implementaties laten genereren.
De specificatie wordt hierbij een centrale bron van waarheid waar zowel de programmeur als het model voortdurend naar kunnen teruggrijpen.
Deze aanpak sluit beter aan bij klassieke software-engineeringprincipes.
Omdat LLM’s sterk afhankelijk zijn van context, helpt een goede specificatie bovendien om consistentere output te genereren over langere interacties en grotere codebases heen.
Spec-driven development combineert dus de snelheid van AI-ondersteunde codegeneratie met meer expliciete controle over architectuur en ontwerpbeslissingen.
Programmeren in markdown
Een opvallende evolutie binnen spec-driven development is het idee van “programmeren in markdown”. Daarbij worden Markdown-documenten gebruikt als centrale interface tussen programmeur en AI-systeem.
In plaats van uitsluitend broncode te schrijven, genereert en onderhoudt de programmeur Markdown-documenten met vereisten, architectuurbeschrijvingen,
datamodellen, …
Een AI-systeem gebruikt deze documenten vervolgens als context voor codegeneratie, refactorings, testgeneratie of projectanalyse.
Markdown is hiervoor bijzonder geschikt omdat het eenvoudig leesbaar is voor mensen en gemakkelijk verwerkt kan worden door LLM’s, en structuur biedt zonder zware formele syntax.
In veel moderne AI-workflows verschuift een deel van het programmeerwerk daardoor van direct code schrijven naar het expliciet beschrijven van intentie, structuur en constraints.
De kwaliteit van de specificatie wordt dan steeds belangrijker, omdat die in sterke mate bepaalt welke code het model genereert.
AI, code quality, software engineering principles
Hoewel AI-ondersteunde softwareontwikkeling veel voordelen biedt, zoals snellere prototyping en toegang tot geavanceerde codegeneratie, brengt het ook uitdagingen mee op het gebied van codekwaliteit en software-engineeringprincipes.
Omdat LLM’s geen expliciet begrip hebben van software-architectuur, design patterns, of best practices, kunnen ze code genereren die functioneel is maar moeilijk te onderhouden, slecht gestructureerd of inconsistent met de rest van de codebase. Daarom is het belangrijk om bij AI-gegenereerde code dezelfde kwaliteitsnormen toe te passen als bij handgeschreven code, en om regelmatig refactorings en code reviews uit te voeren.
Daarnaast is het cruciaal om goede testpraktijken te volgen, omdat gegenereerde code mogelijk fouten bevat die niet meteen zichtbaar zijn. Unit tests, integratietests en code coverage analyses blijven essentieel om de betrouwbaarheid van AI-gegenereerde code te waarborgen. Tot slot is het belangrijk om bewust te zijn van de beperkingen van LLM’s en om menselijke expertise en kritische beoordeling te blijven inzetten, vooral bij grotere of complexere softwareprojecten.
Er zijn wel technieken om een LLM toch te laten “redeneren” of “reviseren”, maar dat is niet de standaardwerking van een LLM, en vereist specifieke voorzieningen. We bespreken dat in het deel rond reasoning. ↩︎
We zullen later (bij het deel rond Tools) zien dat er manieren zijn om een LLM toch informatie te laten teruggeven uit bronnen, maar dat is niet de standaardwerking van een LLM. ↩︎
Algemene info
Opdrachten
Algemene informatie
Hier vind je de opdrachten voor de permanente evaluatie van SES+EES.
De opdrachten voor deel 1 worden gemaakt door alle studenten (SES+EES).
De opdrachten voor deel 2 worden enkel gemaakt door de studenten SES.
GitHub repository linken
Om de permanente evaluatie opdrachten in te dienen voor het vak Software Engineering Skills maken we gebruik van GitHub. In de lessen zal je onder begeleiding een gratis account aanmaken op dit platform.
Je maakt de opdrachten in een repository die je aanmaakt via GitHub Classroom. Daarvoor moet je je GitHub gebruikersnaam linken aan je naam, zodat wij weten bij welke student de repository van ‘FluffyBunny’ hoort :). Zie de instructies bij de eerste opdracht voor meer details.
Naamgeving bij indienen (tags)
Om de verschillende (sub)opdrachten te identificeren wordt er gebruik gemaakt van “tags” bij het committen van je finale resultaat. (In de eerste lessen worden deze onderwerpen klassikaal uitgelegd zodat alle studenten de juiste werkwijze gebruiken).
De naamgeving: voor het committen van je resultaat van “Opdracht 1” gebruik je de tag v1, voor “Opdracht 2” gebruik je de tag v2, enzoverder.
Tags pushen naar github: git push --tagsTags op github verwijderen: git push --delete origin <tagname>. Dit moet je doen als je bijvoorbeeld lokaal een tag verplaatst hebt.
Lokaal een tag deleten: git tag --delete <tagname>
Pushen van branches en tags naar de remote repository
Standaard worden lokale branches en tags niet altijd gepushed naar een remote repository, gebruik daarom volgende flags bij het push-command: $ git push --all && git push --tags
Deadlines
Er is 1 deadline voor alle opdrachten van het eerste deel (SES+EES): vrijdag 27/03/2026 23u59.
De deadline voor alle opdrachten van het tweede deel (enkel SES) is vrijdag 15/05/2026 23u59.
Opdrachten deel 1 SES/EES
Hier vind je de opdrachten voor de permanente evaluatie van SES+EES. De opdrachten voor deel 1 worden gemaakt door alle studenten (SES+EES).
Github classroom link
Klik hier voor de invite van de assignment “SES en EES Opdrachten deel 1”.
Extra start files van andere start repositories downloaden in je eigen repo
Om jullie het leven makkelijk te maken, hebben we voor veel van de opdrachten al startcode geschreven in de vorm van een github repository. Die nieuwe repositories simpelweg clonen in een subdirectory van je eigen repository zorgt echter voor een aantal problemen. Die nieuwe directories met startcode worden dan namelijk als een submodule toegevoegd aan je main repo. Die repo wordt dus als een soort link beschouwd en aangezien die nieuwe repo niet van jullie zelf is ga je dan ook geen veranderingen aan die code kunnen pushen. In de plaats moeten we die start-code-repositories als een subtree toevoegen. Dat heeft als voordeel dat je zelf gewoon wijzigingen kan aanbrengen, committen en pushen naar je eigen hoofd repository. Bovendien blijft er ook een zachte link met de originele start-code-repository zodat als hier iets aan wijzigt je die online wijzigingen nog wel kan fetchen. (Bijvoorbeeld als we merken dat er nog een foutje in de startcode stond!).
Zo een subtree aanmaken doe je dan op de volgende manier:
Voeg de remote-start-code-repository toe aan je eigen repo met volgende commando:
met --prefix= geef je aan in welke subdirectory de inhoud van de externe repo moet komen.
je kan een specifieke branch meegeven (meestal main)
met --squash condenseer je de git history van de externe repo tot één enkele commit. (Je kan deze optie weglaten als je toch de hele git history wil bekijken)
Zodra de files in jouw repo staan, kan je ze bewerken zoals normaal. De changes worden dan onderdeel van de history van JOUW repository, onafhankelijk van de oorspronkelijke externe repository.
Moesten er later toch wijzigingen aangebracht worden in de remote-start-code-repository die je wil fetchen dan kan je volgend commando gebruiken:
Heb je toch al zo een repo gecloned en is dit nu een een submodule waarvan je de changes niet kan committen dan kan je best je wijzigingen even kopieren naar een andere locatie buiten je repo. De subdirectory verwijderen en nu als subtree toevoegen en dan je oplossingen terug erin zetten.
Opdrachten rond Versiebeheer
Opdracht 1:
Download volgende file Candy_Crush_spelregels.txt via rechtermuisklik, ‘opslaan als’ en sla de file op in volgende directory/folder opdracht1-3_Versiebeheer. Behoud de juiste naam!
Doe nu op de correcte manier een commit en tag de commit met v1.
Opdracht 2:
Los alle TODO’s in de file Candy_Crush_spelregels.txt op.
Verander <voornaam> en <naam> nog NIET, dit doe je in opdracht 3.
Los de TODO op rond hoofdletters en kleine letters.
Los de TODO op rond speciale snoepjes, verzin dus zelf vier namen en verwissel <naamSnoepje> steeds met jouw verzonnen naam.
Doe nu op de correcte manier een commit en tag de commit met v2.
Opdracht 3:
Maak een branch aan met als naam “opdracht_branch”.
Switch naar die branch.
In de file Candy_Crush_spelregels.txt verander je nu <voornaam> en <achternaam> naar jouw voor- en achternaam.
Commit je aanpassingen in deze opdracht_branch branch.
Switch terug naar de main branch en vul daar andere waarden in voor de auteur gegevens (Dit is bijvoorbeeld een bug in je software).
Commit nu je aanpassingen in deze main branch.
Merge de opdracht_branch nu met de main branch. Hiervoor zal je dus ook het mergeconflict moeten oplossen.
Doe nu op de correcte manier een commit en tag de commit met v3.
Laatste belangrijke stap!
Push nu je aanpassingen naar Github met behulp van git push --all && git push --tags
Dankzij --all wordt je branch mee gepushed en dankzij --tags worden je tags mee gepushed.
Opdrachten rond Build Systems
Opdracht 4
In de subfolder c/ binnenin de folder opdracht4_BuildSystems:
Je moet de makefile aanpassen zodat het C-programma kan gecompiled+gelinked worden met make compile,
dat de binaries en object files gedeletet worden met make clean
en dat je project gerund kan worden met make run (je moet hier ook flags kunnen meegeven).
De uiteindelijk binary moet in de root van je c-project (dus subfolder c in de folder opdracht4_BuildSystems) directory staan met als naam friendshiptester.bin. Er mag geen andere binary file in staan!
In de subfolder java/ binnenin de folder opdracht4_BuildSystems:
Schrijf een simpele makefile dat de volgende dingen kan doen:
compile: Compileert de bronbestanden naar de /build-directory
jar: packaged alle klassen naar een jar genaamd ‘app.jar’ in de ‘build’-directory met entrypoint de ‘App’-klasse.
run: Voert de jar file uit
clean: Verwijdert de ‘.class’-bestanden en het ‘.jar’-bestand uit de ‘build’-directory
In de subfolder python/ binnenin de folder opdracht4_BuildSystems:
Schrijf een simpele makefile dat de volgende dingen kan doen:
compile: Compileert de bronbestanden naar de single ‘friendshiptester.bin’ file in de “/dist”-directory
test: Voert de ‘app.py’ uit
run: Voert de ‘friendshiptester.bin’ uit
clean: Verwijdert het ‘.bin’-bestand
Doe nu op de correcte manier een commit en tag de commit met v4 en push naar Github.
Opdrachten rond Dependency Management
Opdracht 5
In de folder opdracht5-6_DependencyManagement maak je een javaproject met gradle aan in een subdirectory genaamd “checkneighbours” met package “be.ses”.
Je kan de package name meegeven met het ‘gradle init’ commando op de volgende manier: gradle init --package be.ses
In je checkneighbours gradle project, moet je nu een klasse ‘CheckNeighboursInGrid’ maken en onderstaande static method in implementeren, los ook de TODO op:
CheckNeighboursInGrid.java (klik om te verbergen/tonen)
/**
CheckNeighboursInGrid.java
* This method takes a 1D Iterable and an element in the array and gives back an iterable containing the indexes of all neighbours with the same value as the specified element
*@return - Returns a 1D Iterable of ints, the Integers represent the indexes of all neighbours with the same value as the specified element on index 'indexToCheck'.
*@param grid - This is a 1D Iterable containing all elements of the grid. The elements are integers.
*@param width - Specifies the width of the grid.
*@param height - Specifies the height of the grid (extra for checking if 1D grid is complete given the specified width)
*@param indexToCheck - Specifies the index of the element which neighbours that need to be checked
*/publicstaticIterable<Integer>getSameNeighboursIds(Iterable<Integer>grid,intwidth,intheight,intindexToCheck){// TODO write your code below so you return the correct resultIterable<Integer>result=null;returnresult;}
Genereer een checkneighbours.jar file van deze Javaklasse in de build/libs directory van je gradle project. Kopiëer de jar-file naar de folder “…/opdracht5-6_DependencyManagement/” (dus .../opdracht5-6_DependencyManagement/checkneighbours.jar).
Doe nu op de correcte manier een commit en tag de commit met v5 en push naar Github.
Opdracht 6
In het gradle project .../opdracht5-6_DependencyManagement/checkneighbours_examplemoet je alle TODO’s oplossen. (Je kan met de TODO tree extensie in VSCode gemakkelijk zien of je alle TODO’s gedaan hebt)
kopieer je checkneighbours.jar (die in de directory .../opdracht5-6_DependencyManagement/ zou moeten staan van opdracht 5) naar de app/lib directory van het gradle project ‘checkneighbours_example’.
Pas de build.gradle in dat project ook aan zodat de main-method in de App.java correct gebuild en gerund kan worden.
Doe nu op de correcte manier een commit en tag de commit met v6 en push naar Github.
Opdrachten rond Test Driven Development
Opdracht 7
Voeg minstens 6 unittesten toe aan je gradle project checkneighbours (in de directory .../opdracht5-6_DependencyManagement/checkneighbours/) waarbij de unittesten je oplossing voor de getSameNeighboursIds-methode testen van de CheckNeighboursInGrid-klasse. De testen moeten aan volgende vereisten voldoen:
Gebruik de correcte naamgeving voor de testen
Gebruik het correcte Arrange, Act, Assert principe
Maak minstens 1 test die een Exception test
Probeer de randgevallen te testen en elke test moet een ander scenario testen. (bv. 1 test waarbij je een element aan de linker rand test mag maar 1 keer voorkomen. Eentje in een hoek testen kan dan wel al een ander scenario zijn.)
Doe nu op de correcte manier een commit en tag de commit met v7 en push naar Github.
Opdracht 8
Het python project in de subdirectory .../opdracht7-8_TestDrivenDevelopment/tdd_python bevat:
een checkneighbours.py-bestand met een implementatie van de functie get_same_neighbours_ids()
een file checkneighbours_test.py met het geraamte van het unittest framework al ingevuld.
Schrijf nu dezelfde testen als in Opdracht 7 maar dan voor het python programma.
Doe nu op de correcte manier een commit en tag de commit met v8 en push naar Github.
Opdrachten rond Continuous Integration and Continuous Deployment
Opdracht 9
Gebruik Github Actions om een CI-pipeline aan te maken die steeds je testen van je ‘checkneighbours’ uit opdracht 7 uitvoert wanneer je naar de main branch pusht. Voorzie ook een badge in een README.md in de root folder van deze git directory zodat je in één opslag kan zien wanneer de tests falen.
Let op! Je wil nu dus de testen runnen van een specifiek gradle project dat in een subdirectory staat. Meer info hier
Doe nu op de correcte manier een commit en tag de commit met v9 en push naar Github.
Opdrachten deel 2
Deze opdrachten worden enkel door de studenten van SES gemaakt en ingediend via Github Classroom.
Gebruik van GenAI en samenwerking
Omdat dit deel van het vak gericht is op het zelf leren programmeren, en de opdrachten gequoteerd worden, is het niet toegestaan om GenAI tools (ChatGPT, Claude Code, Gemini, CoPilot, de assistent in IntelliJ, …) te gebruiken om de opdrachten op te lossen. Met andere woorden, we verwachten dus dat je alle ingediende code zelf geschreven hebt. Ook code delen met mede-studenten, of buitenstaanders om hulp vragen, is om dezelfde reden niet toegestaan.
Je zal je oplossing na de indiening mondeling nog moeten toelichten (moment nog vast te leggen). Bij deze toelichting wordt getoetst of je de code die je ingedien hebt ook zelf begrijpt.
Tenslotte is het absoluut geen probleem om GenAI tools te gebruiken bij het studeren en verwerken van de leerstof. Begrijp je een concept niet goed, en wil je meer uitleg of voorbeelden? Wil je hulp bij het oplossen van een oefening? Krijg je een compiler error niet opgelost? Gebruik deze tools dan gerust (hou er wel rekening mee dat er ook fouten in hun antwoord kunnen zitten)! Maar gebruik ze dus niet voor de opdracht.
Setup
Volg onderstaande stappen nauwgezet om je project juist te configureren.
Maak hier (via GitHub Classroom) je repository aan voor de assignment “SES opdrachten deel 2”. Deze repository is nog leeg.
Clone jouw (lege) repository naar een folder op je eigen machine (bv. project-candycrush).
Voeg vervolgens een tweede remote aan die repository op je machine toe, namelijk git@github.com:KULeuven-Diepenbeek/ses-startcode-deel2-2526.git onder de naam startcode. Dat kan je met volgend commando:
Je lokale repository heeft nu dus twee remote repositories (kijk dit na met git remote -v):
origin: je eigen GitHub repository (hierop heb je schrijfrechten)
startcode: de GitHub repository met de startcode die door ons aangeleverd wordt (deze kan je alleen lezen)
Haal de laatste versie van de startcode op en merge die in je repository via git pull startcode main. Doe dit minstens voor elke nieuwe opdracht, en eventueel ook tussendoor (als er wijzigingen/bugfixes aan onze startcode gebeurd zijn).
Open de folder als project in IntelliJ.
Als alles goed gegaan is, wordt je project herkend en geïmporteerd als een Gradle-Java-project. Het is normaal dat de code nog fouten geeft bij het compileren, aangezien die code verwachten die je nog moet schrijven als deel van de opdracht.
Startcode
De startcode bevat een JavaFX-applicatie voor het spel CandyCrush.
Het is een Gradle-project voor IntelliJ, en maakt gebruik van Java 25.
Je kan de folder openen als project in IntelliJ.
De applicatie is gestructureerd volgens het Model-View-Controller (MVC) patroon.
Er zijn ook reeds enkele testen voorgedefinieerd met AssertJ, maar de set van testen is niet volledig. De voorgedefinieerde testen dienen voornamelijk om na te gaan of je oplossing automatisch getest kan worden.
Belangrijk!
Omdat je inzendingen (deels) automatisch verbeterd zullen worden, is het noodzakelijk dat alle gegeven testen compileren zonder enige aanpassingen.
Je mag uiteraard wel extra testen toevoegen.
Ook is het geen groot probleem indien een bepaalde test niet slaagt — zolang hij maar uitgevoerd kan worden.
Opdracht 1: Records
Startcode
Zorg dat je eerst de setup-instructies voor deel 2 hierboven gevolgd hebt.
Merge de laatste versie van de startcode in je repository door git pull startcode 01-records uit te voeren in jouw lokale repository.
Maak, in package ses.candycrush.board een record BoardSize. Dit stelt de grootte voor van een CandyCrush speelveld. Het heeft als attributen het aantal rijen (rows) en aantal kolommen (columns) van het speelveld.
Het aantal rijen en kolommen moeten beiden groter zijn dan 0, zoniet gooi je een IllegalArgumentException.
Maak, in hetzelfde package, ook een tweede record genaamd Position met attributen row en column. Dit stelt een geldige positie van een cel op een CandyCrush-speelveld voor.
Rijen en kolommen worden genummerd vanaf 0.
Aan de constructor van een Position-object moeten (in deze volgorde) een rij- en kolomnummer alsook een BoardSize meegegeven worden.
Indien de positie ongeldig is voor de grootte van het speelveld, moet je een IllegalArgumentException gooien.
Voeg in Position volgende methodes toe:
een methode int toIndex() die de positie omzet in een index. Voor veld met 2 rijen en 4 kolommen lopen de indices als volgt:
0 1 2 3
4 5 6 7
een statische methode Position fromIndex(int index, BoardSize size) die de positie teruggeeft die overeenkomt met de gegeven index.
Deze methode moet een IllegalArgumentException gooien indien de index ongeldig is.
methodes boolean isFirstRow(), boolean isFirstColumm(), boolean isLastRow(), en boolean isLastColumn() die aangeven of de positie zich in de eerste/laatste rij/kolom van het bord bevindt.
een methode Collection<Position> neighbors() die alle posities van (geldige) directe buren (horizontaal en verticaal) in het speelveld teruggeeft. Kies een geschikt collectie-type voor de teruggegeven collectie.
een methode boolean isNeighborOf(Position other) die nagaat of de gegeven positie een directe buur is van de huidige positie. Gooit een IllegalArgumentException als de gegeven positie bij een andere bordgrootte hoort.
Voeg in BoardSize de volgende methodes toe:
een methode Collection<Position> positions() die een collectie (kies zelf het type) met daarin alle posities op het bord teruggeeft.
Voeg, in package ses.candycrush.model, een sealed interfaceCandy toe, met subklassen (telkens een record, die je in de Candy-interface plaatst) voor
NoCandy, wat staat voor het ontbreken van een snoepje.
NormalCandy, met een attribuut color (een int met mogelijke waarden 0, 1, 2, of 3); je gooit een IllegalArgumentException indien een ongeldige kleur opgegeven wordt.
Elk van de volgende speciale soorten snoepjes:
een RowSnapper
een MultiCandy
een RareCandy
een TurnMaster
Voeg, in het package ses.candycrush.model, een record Switch toe. Een Switch-object stelt een mogelijke wissel voor tussen twee Positions first en second.
Beide posities moeten buren zijn van elkaar; je constructor moet een IllegalArgumentException gooien indien dat niet het geval is.
Zorg ervoor dat het niet uitmaakt in welke volgorde de twee posities meegegeven worden aan de constructor; maar het veld first moet uiteindelijk de positie bevatten met de kleinste index (zoals gedefinieerd bij toIndex()).
Voeg aan dat Switch-record een operatie other(Position pos) toe die de andere positie teruggeeft dan de gegeven positie (dus als je first meegeeft, krijg je second terug, en omgekeerd).
Indien de gegeven positie geen deel uitmaakt van het Switch-object, gooi je een IllegalArgumentException.
Pas nu je code (CandyCrushGame, CandyCrushBoardUI, en Controller) aan zodat die op zoveel mogelijk plaatsen gebruik maakt van bovenstaande records in plaats van int en int[] (Switch moet je nog niet gebruiken). Dus:
op elke plaats waar voorheen een int voor width en/of height gebruikt of teruggegeven werd, moet nu BoardSize gebruikt worden
op elke plaats waar voorheen een rij- en/of kolomnummer gebruikt of teruggegeven werd, moet nu een Position object gebruikt worden
op elke plaats waar voorheen een int gebruikt of teruggegeven werd om een snoepje aan te duiden, moet nu een Candy object gebruikt worden.
In de klasse CandyCrushBoardUI (methode makeCandyShape) moet je pattern matching gebruiken om een JavaFX Node aan te maken voor de gegeven candy op de gegeven positie.
Hint: Laat de compiler je helpen met het vinden van de nog aan te passen code, door bv. eerst de type van een veld te veranderen en dan alle compilatie-problemen die daardoor ontstaan aan te pakken.
Implementeer in de model-klasse CandyCrushGame de methode Collection<Switch> getPotentialSwitchesOf(Position pos). Deze moet alle mogelijke wissels teruggeven (collectie-type naar keuze) van positie pos. Positie pos kan wisselen met een andere positie indien (1) ze buren zijn; (2) geen van beiden een NoCandy zijn; én (3) de snoepjes op beide posities verschillend zijn (qua soort en/of kleur). (Deze methode zullen we in een latere opdracht verfijnen, maar voorlopig volstaat dit).
Als je dit alles correct gedaan hebt, zou alle code moeten compileren en kan je de applicatie uitvoeren (./gradlew run). Ook de testen zouden moeten slagen.
Tag het resultaat als v1 en push dit naar jouw remote repository (origin) op GitHub: git push origin.
Vergeet niet om de tag zelf ook expliciet te pushen: git push origin v1. Dit gebeurt namelijk niet automatisch bij een git push.
Je kan ook alle tags in 1 keer pushen met git push --tags.
Controleer op je GitHub-repository of je de tags kan zien.
Opdracht 2: Generics
Startcode
Merge eerst de laatste versie van de startcode in je repository door git pull startcode 02-generics uit te voeren in de main-branch van jouw lokale repository.
CandyCrush bestaat uit een rechthoekig spelbord, met verschillende vakjes (cellen) waarin een candy geplaatst kan worden. Zo’n spelbord kan ook voor andere spellen dan Candycrush gebruikt worden; denk bijvoorbeeld aan schaken, dammen, zeeslag, go, … . In deze opdracht ga je daarom een algemene klasse Board ontwikkelen voor zo’n rechthoekig spelbord.
Maak, in package ses.candycrush.board, een generische Board-klasse, met een generische parameter die het type voorstelt van de mogelijke inhoud van een cel (bv. een Candy voor CandyCrush, een schaakstuk voor schaken, of een boot voor zeeslag).
De constructor van Board vereist enkel een BoardSize. Initieel zijn alle cellen leeg (null).
Voor het voorstellen van de inhoud van het bord moet deze klasse maximaal gebruik maken van de BoardSize en Position records uit de vorige opdracht. Je moet volgende operaties snel en efficiënt kunnen uitvoeren; kies daarvoor geschikte datastructuren:
Het opvragen van de inhoud van een cel op basis van positie (bv. welk snoepje staat er op positie (2, 3)?)
Het opvragen van alle cel-posities (als Set) waarop een element voorkomt. Bijvoorbeeld:
in de context van CandyCrush: alle posities waarop een RowSnapper snoepje voorkomt
in de context van zeeslag: alle posities die bezet zijn door een bepaald schip
Zorg voor encapsulatie: andere klassen mogen de inhoud van een bord enkel via de gepaste publieke methodes kunnen aanpassen (zie hieronder).
Voeg volgende publieke methodes toe en implementeer ze:
BoardSize getSize() die de grootte van het bord teruggeeft (als BoardSize-object)
boolean isValidPosition(position) die nagaat of de gegeven positie geldig is voor dit bord (dus of ze in het bord ligt).
getCellAt(position) om de cel op een gegeven positie van het bord op te vragen. Als de positie ongeldig is, gooi je een IllegalArgumentException.
getPositionsOfElement die alle posities teruggeeft waarop het gegeven element (cel) voorkomt, gebruik makend van de omgekeerde Map van hierboven.
De teruggegeven collectie mag niet aanpasbaar zijn (dus: de ontvanger mag ze niet kunnen aanpassen).
void replaceCellAt(position, newCell) om de cel op een gegeven positie te vervangen door een meegegeven object. Als de positie ongeldig is, gooi je een IllegalArgumentException.
void fill(cellCreatorFunction) om het hele bord te vullen met objecten die teruggegeven worden door de cellCreatorFunction. De cellCreatorFunction is een java.util.function.Function-object dat, gegeven een Position-object als argument, het cel-object teruggeeft wat op die positie geplaatst moet worden.
Je kan deze methode bijvoorbeeld gebruiken om op alle even rijen een rood snoepje te zetten, en op alle onven rijen een blauw snoepje. Als functie geef je dan een functie
De meegeleverde tests bevatten deze functie als voorbeeld.
een methode copyTo(otherBoard) die alle cellen van het huidige bord kopieert naar het meegegeven bord. Als het meegegeven bord niet dezelfde afmetingen heeft, gooi je een IllegalArgumentException.
Zorg dat deze laatste twee methodes zo algemeen mogelijk zijn qua (generische) types, en schrijf telkens een test waarin je hier gebruik van maakt.
Gebruik je Board-klasse en bijhorende methodes nu zoveel mogelijk in CandyCrushGame (in plaats van de array int[][] speelbord). De inhoud van de cellen moeten uiteraard Candy-objecten zijn (en niet langer ints).
Tag het resultaat als v2 en push dit naar je remote repository op GitHub.
Vergeet niet om de tag zelf ook expliciet te pushen: git push origin v2 of git push --tags
Opdracht 3: Streams
Startcode
Merge eerst de laatste versie van de startcode in je repository door git pull startcode 03-streams uit te voeren in de main-branch van jouw lokale repository.
Elke methode die hieronder vermeld wordt moet volledig geïmplementeerd worden met streams.
In het bijzonder mogen er geen if-statement, for- of while-lussen gebruikt worden.
Je mag ook de forEach()-methode niet gebruiken.
(Als een methode je echt niet lukt met streams, mag je wel if-statements of lussen gebruiken — dat zal je wel een deel van de punten op deze opdracht kosten.)
Maak in klasse Position vier methodes (uitsluitend met behulp van streams).
public Stream<Position> walkLeft()
public Stream<Position> walkRight()
public Stream<Position> walkUp()
public Stream<Position> walkDown()
Elk van die methodes geeft een stream terug met alle (geldige) posities die links, rechts, boven, of onder een positie liggen (rij 0 is de bovenste rij).
De streams starten met de positie zelf, dan de positie die vlak naast de this-positie ligt, dan die daarnaast, enzovoort.
Kijk naar de meegeleverde testen voor het verwachte gedrag.
Hint: de makkelijkste manier is om te vertrekken van een IntStream.
De startcode bevat een klasse ses.candycrush.model.Match. Een Match-object stelt een opeenvolging van posities voor (bijgehouden in een lijst).
Deze posities mogen niet null zijn, en moeten steeds naast elkaar liggen, ofwel allemaal horizontaal (geordend van links naar rechts), ofwel allemaal verticaal (geordend van boven naar onder).
Implementeer in deze klasse (uitsluitend met behulp van streams) de statische methodes
containsNull
areAdjacentFromLeftToRight
areAdjacentFromTopToBottom
die gebruikt worden om deze voorwaarden te controleren.
Hint: de makkelijkste manier voor de areAdjacent-methodes is om te vertrekken van een IntStream.
Voorzie in klasse CandyCrushGame een methode Set<Match> findAllMatches() die alle matches met een minimale lengte van 3 op het bord teruggeeft.
Bijvoorbeeld: voor het bord hieronder moet de methode een Set met daarin twee Match-objecten teruggeven, namelijk de rode match (de posities van de 3 rode snoepjes, van links naar rechts) en de groene match (de posities van 4 groene snoepjes, van boven naar onder).
Om deze findAllMatches-methode te implementeren, zijn volgende hulpfuncties handig. Zet deze (publiek) in je CandyCrushGame-klasse, en implementeer ze volledig via streams.
Het idee van deze hulpmethodes is om eerst de mogelijke startposities van een match te zoeken (het meest linkse of bovenste snoepje van de match), en van daaruit (naar rechts of naar onder) de langste reeks van dezelfde snoepjes te zoeken.
static <T> boolean firstTwoEqual(T value, Stream<T> stream). Deze methode geeft terug of de eerste twee elementen in de gegeven stream hetzelfde zijn als de gegeven waarde. Als de stream minder dan 2 elementen bevat, geef je false terug.
Stream<Position> horizontalStartingPositions(). Deze methode geeft een stream terug van alle posities op het bord waar een snoepje staat, en links van die positie een ander soort snoepje (of geen snoepje) staat. Deze posities zijn dus de mogelijke startposities van een horizontale match. (Die match loopt dus naar rechts). We kijken hier nog niet naar de lengte van de match. Hint: Maak gebruik van firstTwoEqual en de walkLeft-methode.
Maak ook de (gelijkaardige) methode Stream<Position> verticalStartingPositions() die de mogelijke startposities van een verticale match teruggeeft.
In de figuren hieronder wordt met een kruisje aangeduid welke posities een mogelijke startpositie zijn, en teruggegeven moeten worden.
List<Position> longestMatchToRight(Position pos) en List<Position> longestMatchDown(Position pos). Deze methodes geven de langste match terug als een lijst van posities. De teruggegeven posities vertrekken op de gegeven positie en lopen in de richting aangegeven door de methodenaam. Deze methode geeft ook matches van lengte 1 of 2 terug. (Hint: gebruik de walk-methodes van Position).
Voor het voorbeeld hierboven zijn dit de matches die teruggegeven worden door longestMatchDown voor elk van de verticale startposities:
Eens je beschikt over deze hulpmethodes, kan je findAllMatches implementeren (via streams). (Hint: Stream.concat)
Vervang de bestaande implementatie van de methode getPotentialSwitchesOf door een implementatie die volledig werkt via streams.
Deze mag enkel Switch-objecten teruggeven die voldoen aan volgende voorwaarden:
de posities zijn twee naburige posities;
er staat een snoepje (geen NoCandy) op beide posities;
beide snoepjes zijn verschillend;
na het uitvoeren van de wissel zou er minstens één match ontstaan (dus: findAllMatches geeft een niet-lege Set terug).
Let op: de uitvoering van getPotentialSwitchesOf moet het bord in de oorspronkelijke toestand achterlaten!
Volgende methodes zijn hierbij handig; ze zijn reeds toegevoegd aan de CandyCrushGame-klasse in de startcode:
Tag het resultaat als v3 en push dit naar je remote repository op Github.
Vergeet niet om de tag zelf ook expliciet te pushen: git push origin v3. Dit gebeurt namelijk niet automatisch bij een git push.
Je kan ook alle tags in 1 keer pushen met git push --tags.
Controleer op je GitHub-repository of je de tags kan zien.
Opdracht 4: Recursie
Startcode
Merge eerst de laatste versie van de startcode in je repository door git pull startcode 04-recursie uit te voeren in de main-branch van jouw lokale repository.
Elke methode die hieronder vermeld wordt moet recursief geïmplementeerd worden. Dat wil zeggen dat ze minstens 1 nuttige recursieve oproep moeten bevatten. Je mag daarnaast ook for- en while-lussen gebruiken, en ook extra parameters en/of hulpmethodes toevoegen indien nodig.
(Als een methode je echt niet lukt met recursie, mag je ze ook op een andere manier implementeren — dat zal je wel een deel van de punten op deze opdracht kosten.)
Maak (in klasse CandyCrushGame) een recursieve methode void clearMatch(List<Position> match) die alle snoepjes die deel uitmaken van de gegeven match (= de posities uit één van de matches gevonden door findAllMatches uit de vorige opdracht) van het speelbord verwijdert. De plaatsen waarop een verwijderd snoepje stond, blijven leeg (en krijgen dus een NoCandy in de plaats).
Maak (in klasse CandyCrushGame) een recursieve methode fallDownTo(Position pos) die alle snoepjes die boven positie pos staan zoveel mogelijk naar beneden laat vallen, tot ze op een ander snoepje of positie pos terecht komen. Bijvoorbeeld, in onderstaande situatie (met pos aangegeven door het pijltje) verandert de methode de situatie aan de linkerkant in die van de rechterkant.
*
o
*
*
-> o
o
*
wordt
o
o
*
*
-> *
o
*
en
o
*
o
*
-> *
o
*
wordt
o
o
*
*
-> *
o
*
Maak (in klasse CandyCrushGame) een recursieve methode boolean updateBoard() die alle matches zoekt, verwijdert, en de overblijvende snoepjes naar beneden laat vallen (gebruik hiervoor de methodes findAllMatches, clearMatch, en fallDownTo). Als er hierdoor nieuwe matches ontstaan, moeten die ook weer verwijderd worden en moeten de snoepjes weer naar beneden vallen etc., totdat er geen matches meer zijn. De methode moet true teruggeven indien er minstens één match verwijderd werd, en false indien dat niet zo is.
Merk op dat we (in tegenstelling tot de ‘gewone’ CandyCrush) het bord niet terug opvullen met nieuwe snoepjes: in onze variant is het de bedoeling om het bord zo leeg mogelijk te maken. Om alles zo eenvoudig mogelijk te houden, negeren we ook de effecten van de speciale snoepjes.
Vervang de code van de methode selectCandy in CandyCrushGame.java door hetvolgende:
Met deze wijzigingen, en correcte implementaties tot nu toe, krijg je een speelbare versie van CandyCrush.
Tag het resultaat als v4 en push dit naar je remote repository op Github.
Vergeet niet om de tag zelf ook expliciet te pushen: git push origin v4. Dit gebeurt namelijk niet automatisch bij een git push.
Je kan ook alle tags in 1 keer pushen met git push --tags.
Controleer op je GitHub-repository of je de tags kan zien.
Opdracht 5: Backtracking
Startcode
Merge eerst de laatste versie van de startcode in je repository door git pull startcode 05-backtracking uit te voeren in de main-branch van jouw lokale repository.
De spelregels van CandyCrush nog eens samengevat:
De speler mag enkel snoepjes van plaats wisselen die vlak naast elkaar liggen.
Twee snoepjes van plaats proberen te wisselen zonder dat dat onmiddellijk leidt tot een match is niet toegelaten; beide snoepjes blijven dan op hun oorspronkelijke plaats.
De speler mag geen snoepje wisselen met een lege plaats, enkel met een ander snoepje.
Wanneer er een match is (3 of meer dezelfde snoepjes naast elkaar, horizontaal of verticaal), verdwijnen die snoepjes en vallen de andere snoepjes naar beneden. Dit herhaalt zich tot er geen matches meer zijn.
We voegen nu ook een score toe:
De score verhoogt telkens er snoepjes verwijderd worden, en dat met het aantal snoepjes dat verwijderd wordt. Dus 3 snoepjes verwijderen verhoogt de score met 3.
Elk verwijderd snoepje telt slechts één keer voor de score, ook als het tegelijkertijd deel is van zowel een horizontale als een verticale match.
De enige operatie die de speler dus kan uitvoeren is twee naburige snoepjes van plaats wisselen, om zo nieuwe matches te creëren, die vervolgens verdwijnen. Daardoor verandert het bord en kan er opnieuw een wissel gedaan worden. Het doel van het spel is om het bord zo leeg mogelijk te krijgen. Omdat het bord verandert na elke wissel, is de volgorde van die wissels erg belangrijk.
Schrijf in klasse CandyCrushGame een methode public List<Switch> maximizeScore() met een backtracking-algoritme dat de beste sequentie van geldige wissels zoekt voor het huidige spel. De beste sequentie is deze die de hoogste score oplevert.
Als er meerdere sequenties zijn die tot dezelfde score leiden, geef je de kortste terug. Zijn er meerdere met dezelfde score en lengte, dan maakt het niet uit welke je daarvan teruggeeft.
Na afloop van deze methode moet de toestand van het bord onveranderd zijn: de methode berekent enkel de optimale lijst van switches, zonder het bord te wijzigen.
Hints:
Je mag, naast de maximizeScore-methode, uiteraard ook nog hulpmethodes toevoegen. Een nuttige hulpmethode is eentje om alle mogelijke switches op het bord te zoeken (gebruik makend van getPotentialSwitchesOf).
Maak zeker gebruik van de updateBoard()-methode de vorige opdracht. Je kan die uitbreiden om de score aan te passen.
Besteed niet te veel aandacht aan efficiëntie; kies liever voor duidelijkheid.
Je kan werken met een kopie van het bord om aanpassingen uit te voeren zonder de oorspronkelijke toestand te veranderen.
In de bijgeleverde tests worden de volgende drie spellen gebruikt:
Tag het resultaat als v5 en push dit naar je remote repository op Github.
Vergeet niet om de tag zelf ook expliciet te pushen: git push origin v5. Dit gebeurt namelijk niet automatisch bij een git push.
Je kan ook alle tags in 1 keer pushen met git push --tags.
Controleer op je GitHub-repository of je de tags kan zien.
Dit was de laatste opdracht voor het vak. Controleer zeker of alle tags (v1 tot en met v5) gepushed zijn naar GitHub.
Extra informatie
Extra informatie Examen deel 1 (zie menu)
Subsecties van Extra informatie
Examen: Kennen en kunnen deel 1 SES
Extra informatie Examen deel 1 SES
Hieronder kan je per onderdeel één of meer voorbeeldvragen terugvinden. De vragen van het examen zullen anders zijn maar gaan gelijkaardig zijn aan vraagstelling en moeilijkheidsgraad aan de voorbeelden hieronder.
De focus ligt in dit deel nooit op de exacte code of syntax, maar je kan wel code krijgen waar jij dan moet uitleggen wat die code ongeveer doet etc.
WSL en VSCode
Enkel kunnen, niets specifiek te kennen voor examen
Versiebeheer: Git en Github
Voorbeeld vragen:
Casus gegeven van een bug in een programma en er moet een nieuwe feature ontwikkeld worden, de ontwikkelaars werken met een productie branch en een development branch. Schets de git workflow die de bugfix en de nieuwe feature uiteindelijk integreert in de productie branch.
Build systems + Dependency Management
Voorbeeld vragen:
Geef drie voordelen van het gebruik van een dependency management tool zoals Gradle. Tip: elk voordeel is een nadeel van het manueel beheren van dependencies.
Gegeven is een stuk code uit een makefile. Leg uit wat deze code juist doet.
Test driven development
Voorbeeld vragen:
Gegeven bovenstaande java methode, schrijf unittests die alle scenario’s testen. (Java syntax is niet belangrijk, wel de structuur van de testen)
Geef vijf eigenschappen van een goede unit test en leg uit.
Lifecycle CI/CD + SCRUM
Voorbeeld vragen:
Leg het verschil uit tussen continuous integration en continuous deployment.
Extra Voorbeeldvragen
Voorbeeld vragen:
Leg de volgende begrippen uit:
end-to-end test
Maven Central Repository
SCRUM
Transitieve dependency
Bijlagen
Hier vind je wat extra informatie die handig kan zijn, maar geen deel is van de leerstof:
Lijst met veelgebruikte termen en afkortingen in deze online cursus
Versiebeheer = Version control = source control
VCS = Version Control Systems = versiebeheer systemen
OS = Operating system = Besturingssysteem (Bv. Windows, Mac OS, Linux)
File Explorer = Windows verkenner
Directory ≈ folder ≈ map
Bestand = file
GUI (Graphical User Interface)
CLI (Command Line Interface)
IDE = Integrated Development Environment (bv. IntelliJ, PyCharm, Netbeans …)
Bijlage B - Java in een notendop
Dit document biedt een overzicht van enkele Java-specifieke concepten en syntax voor studenten die wel vertrouwd zijn met een object-georiënteerde programmeertaal, maar niet met Java.
Algemeen
Java is een sterk getypeerde taal: alle variabelen hebben types, en de compiler dwingt af dat de types overeenkomen.
Het type wordt steeds vóór de variabele geschreven: int x.
Java is ook object-georiënteerd: elke variabele is ofwel een referentie naar een object, ofwel een primitieve waarde (int, boolean, …). De speciale waarde null wordt gebruikt voor referentie-variabelen die naar geen enkel object verwijzen.
Een methode oproepen op een object gebeurt via een punt: ontvanger.methode(parameter1, parameter2)
Primitieve datatypes
De primitieve datatypes in Java zijn
int (32-bit integer)
long (64-bit integer)
short (16-bit integer)
boolean
float (single-precision)
double (double-precision)
char (16-bit unicode character)
byte (signed! -128..127)
Daarnaast is ook String een ingebouwd datatype (maar strikt genomen geen primitief type).
Strings zijn immutable: eens aangemaakt, kan geen karakters wijzigen/toevoegen/….
Tenslotte bestaan er ook zogenaamde ‘boxed’ types: Integer, Long, Short, Boolean, Float, Double, Char, Byte. Dit zijn objecten die exact één primitieve waarde van het overeenkomstige type bevatten.
De Java compiler zorgt zelf voor boxing en unboxing:
inta=2;Integerx=a;Doubley=3.2;doublez=x*y;
Je kan ze dus bijna overal door elkaar gebruiken, maar het is aangeraden om, waar mogelijk de primitieve types te gebruiken.
Het voornaamste gebruik van de boxed types is als type voor ArrayLists (zie hieronder), bijvoorbeeld ArrayList<Integer> om een lijst van gehele getallen voor te stellen.
Main method
De uitvoering van een Java-programma start steeds in een methode public static void main(String[] args), die in een klasse moet staan.
Java heeft arrays; deze hebben een vaste lengte die bepaald wordt bij het aanmaken en daarna niet meer gewijzigd kan worden.
Het type van een array van type T is T[]; bij het aanmaken geef je de lengte op: new T[lengte].
De lengte kan je opvragen via het .length attribuut.
Individuele elementen vraag je op en verander je via [index]; het eerste element heeft index 0:
Een ArrayList is een collectie zoals een array, maar die groter en kleiner kan worden.
Je voegt elementen toe met add(element), en vraagt ze op via get(index).
Je moet ArrayList importeren uit het java.util package om het te kunnen gebruiken.
Een if-statement in java bevat steeds een conditie (haakjes verplicht!).
Er kunnen ook meerdere else if blokken aan toegevoegd worden,
en/of één else-blok.
behalve dat je, bij de for-loop, de variabelen die in de initializer gedeclareerd worden (number in het voorbeeld hierboven) niet meer kan gebruiken na de lus (die zijn out of scope).
Enhanced for-loop (foreach)
Een enhanced for-loop (‘foreach’) kan je gebruiken om over de elementen van een array of collectie (bijvoorbeeld een ArrayList) te itereren (meer in detail: alle klassen die de Iterable interface implementeren).
een of meerdere constructoren, die opgeroepen worden wanneer een object aangemaakt wordt. Indien je geen constructor schrijft, wordt een default constructor voorzien (zonder parameters).
velden/attributen: de eigenschappen van een object, telkens met een type
methodes: de acties die uitgevoerd kunnen worden door een object. Elke methode heeft
precies 1 terugkeertype, of void indien de methode geen resultaat teruggeeft. Je geeft een waarde terug via een return-statement.
0 of meer parameters
Een voorbeeld:
packageexample.person;publicclassPerson{// veldenprivateStringname;privatePersonmarriedTo=null;// default null// constructorpublicPerson(Stringname){this.name=name;}// getter en setter voor naampublicStringgetName(){returnname;// zelfde als 'return this.name;'}publicvoidsetName(StringnewName){this.name=newName;}publicbooleanisMarried(){returnmarriedTo!=null;}publicvoidmarryTo(Personother){if(isMarried()){thrownewIllegalStateException("Already married");}if(other.isMarried()){thrownewIllegalArgumentException("Other person is already married");}this.marriedTo=other;other.marriedTo=this;// OK ondanks `private` modifier (want zelfde klasse)}}
Elke publieke klasse moet in een bestand staan met dezelfde naam als de klasse, bijvoorbeeld Person.java.
Als de klasse in een package zit, moet het pad overeenkomen met dat package, bijvoorbeeld example/person/Person.java.
Objecten aanmaken
Een object van een klasse wordt aangemaakt via new. Daarbij wordt de constructor opgeroepen.
Java heeft automatische garbage collection: objecten die niet meer gebruikt worden, worden automatisch uit het geheugen verwijderd.
Modifiers
Java heeft 4 visibility modifiers voor klassen, velden, en methodes:
public: het element is overal toegankelijk
private: het element is enkel toegankelijk binnen het bestand zelf (de compilation unit)
protected: het element is toegankelijk voor 1) klassen binnen hetzelfde package, en 2) subklassen
(package): het element is toegankelijk voor klassen binnen hetzelfde package. Er is geen specifieke modifier hiervoor (dit is de standaard als je niets schrijft).
Daarnaast zijn er nog volgende modifiers:
static: het element is statisch, dit wil zeggen dat het geen deel uitmaakt van individuele objecten, maar van de klasse als geheel (het bestaat dus slechts 1 keer, en wordt gedeeld)
final:
voor een klasse: er kan niet van overgeërfd worden
voor een methode: de methode kan niet overridden worden in een subklasse
voor een veld/attribuut en variabele: de referentie (of waarde voor een primitief type) van het veld kan niet meer gewijzigd worden (opgelet: het object waarnaar verwezen wordt, kan zelf wel nog gewijzigd worden! Enkel de referentie is onwijzigbaar).
abstract: de klasse of de methode is abstract; zie verder.
Java heeft enkelvoudige overerving: elke klasse erft over van exact 1 superklasse (indien er geen opgegeven wordt, is dat Object). Overerving van een klasse wordt aangegeven door middel van extends na de klasse-naam:
Een klasse die zelf niet rechtstreeks geïnstantieerd kan worden, is abstract.
Een abstracte klasse kan abstracte methodes hebben, die door (niet-abstracte) subklassen geïmplementeerd moeten worden.
Enkel niet-abstracte subklassen kunnen aangemaakt worden via new.
Over het algemeen is het gebruik van instanceof een ‘code smell’, en kijk je beter of je gebruik kan maken van polymorfisme.
Polymorfisme en dynamic dispatch
In Java kan je methodes overloaden (zelfde naam maar verschillende parameter-types binnen eenzelfde klasse) en overriden (zelfde naam en parameters in super- en subklasse). Bij het overriden van een methode kan voor een object dezelfde methode dus bestaan in de klasse en in een of meerdere van de superklassen.
Daarom is er een mechanisme nodig om te bepalen welke methode uiteindelijk uitgevoerd zal worden. Dat wordt in Java bepaald door
het gedeclareerde (statisch) type van de argumenten (at compile time)
het effectieve (dynamische) type van het object (at runtime)
Het statisch type van food (at compile time) is Food.
Het dynamisch type van person (at runtime) is Student.
Dus wordt de methode eat(Food food) uit de klasse Student uitgevoerd.
Exceptions
Wanneer zich een onvoorziene situatie voordoet, kan je dat in Java aangeven door een exception-object te gooien via throw.
Bijvoorbeeld:
classBreuk{privatefinalintteller,noemer;publicBreuk(intteller,intnoemer){if(noemer==0)thrownewIllegalArgumentException("Noemer mag niet 0 zijn");this.teller=teller;this.noemer=noemer;}}
De uitvoering breekt dan onmiddellijk af, en er wordt gezocht naar code die de uitzondering kan opvangen.
Exceptions opvangen doe je via een try .. catch block:
try{// probeer code uit te voerenBreukbreuk=newBreuk(3,0);// gelukt, ga verder met breuk}catch(IllegalArgumentExceptione){// wordt (enkel) uitgevoerd wanneer de code in het try-block een IllegalArgumentException gooideSystem.out.println("Oeps");}
Er wordt eerst gekeken naar een try-catch blok in de methode die de methode opgeroepen heeft waarin een uitzondering gegooid werd. Is daar geen try-catch block aanwezig, wordt gekeken in de methode die die methode opgeroepen heeft, etc, tot in de main-methode.
Als er geen enkele try-catch block gevonden wordt die de uitzondering kan afhandelen, stopt het programma.
Hierboven gebruikten we unchecked exceptions; alle unchecked exceptions erven over van de klasse RuntimeException. Java heeft ook checked exceptions; deze erven over van de klasse Exception. Checked exceptions moeten vermeld worden in de methode-hoofding, en code die de methode oproept moet ze opvangen of ze opnieuw vermelden in de methode-hoofding.
classNoemerIsNulextendsException{}classBreuk{privatefinalintteller,noemer;publicBreuk(intteller,intnoemer)throwsNoemerIsNul{// <- exception moet vermeld worden in hoofdingif(noemer==0)thrownewNoemerIsNul();this.teller=teller;this.noemer=noemer;}}try{Breukbreuk=newBreuk(3,0);// compiler geeft een fout als NoemerIsNul niet opgevangen wordt}catch(NoemerIsNule){System.out.println("Oeps");}
Checked exceptions maken het vaak lastig om iets te programmeren, en de voorkeur wordt tegenwoordig vaak gegeven aan unchecked exceptions.
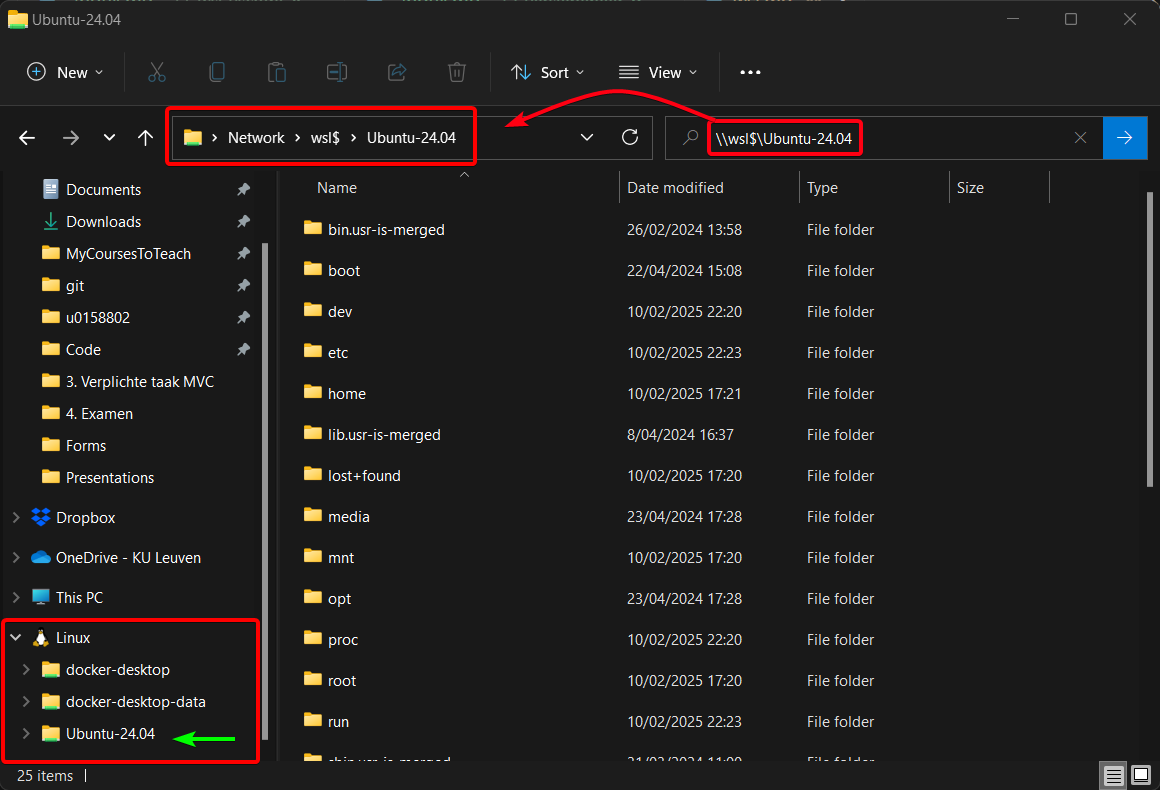



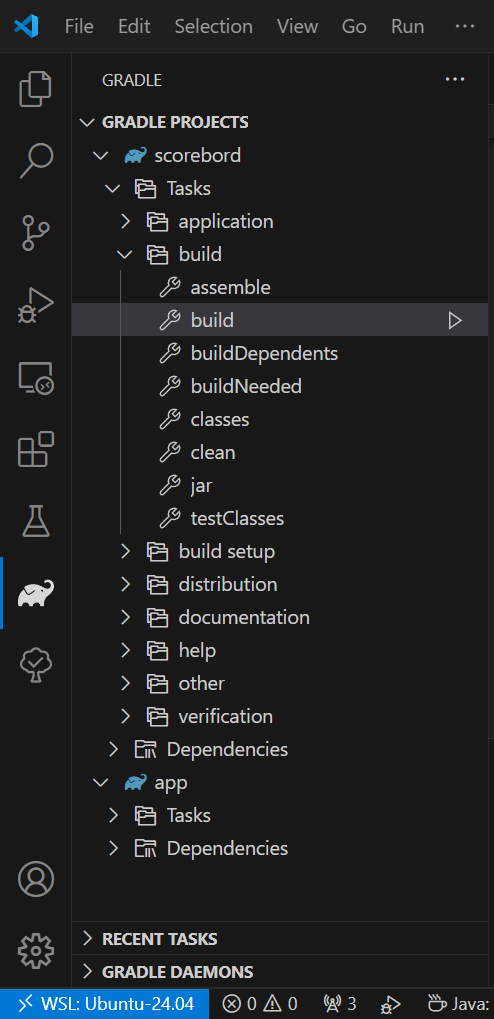
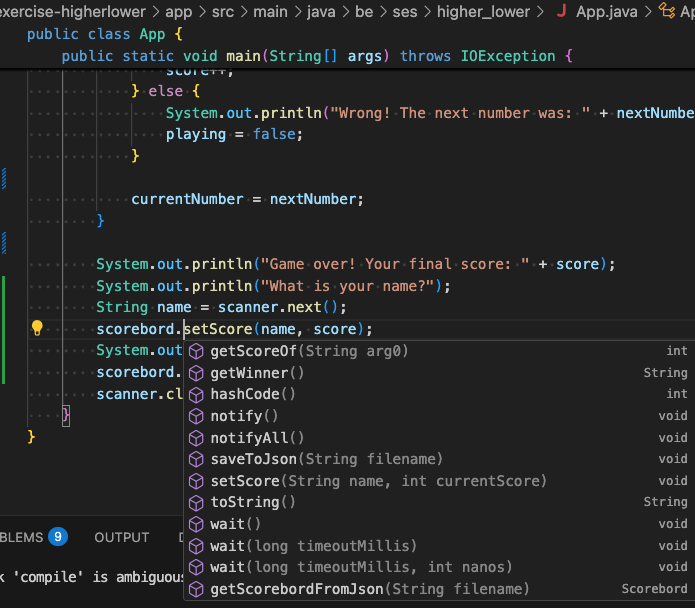

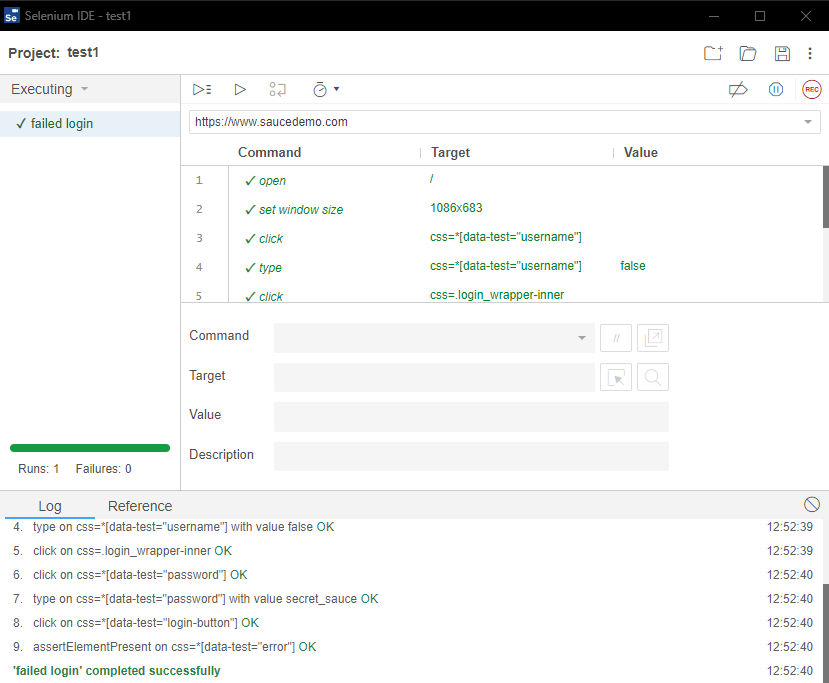



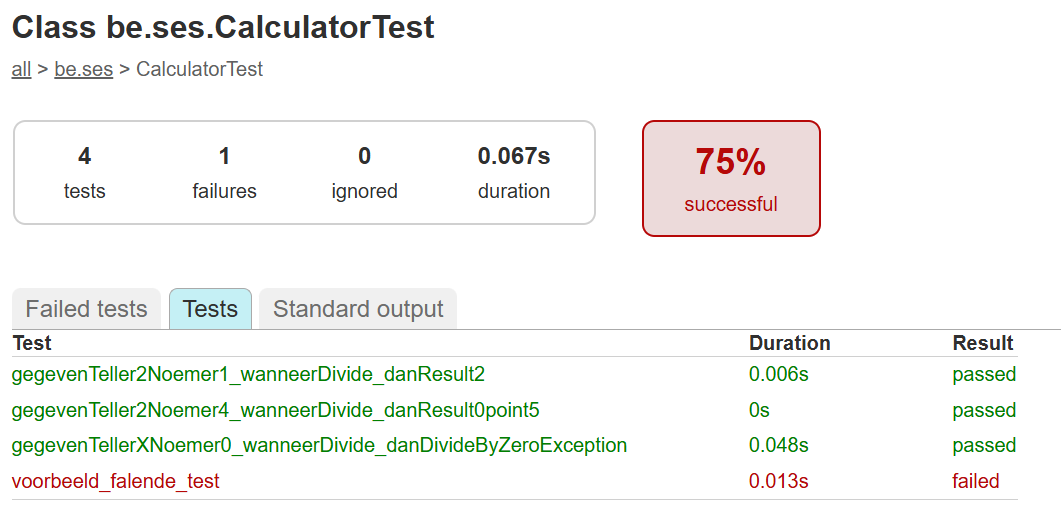
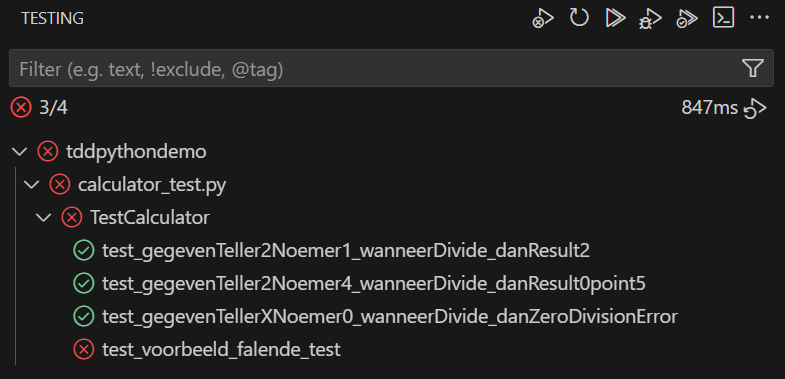

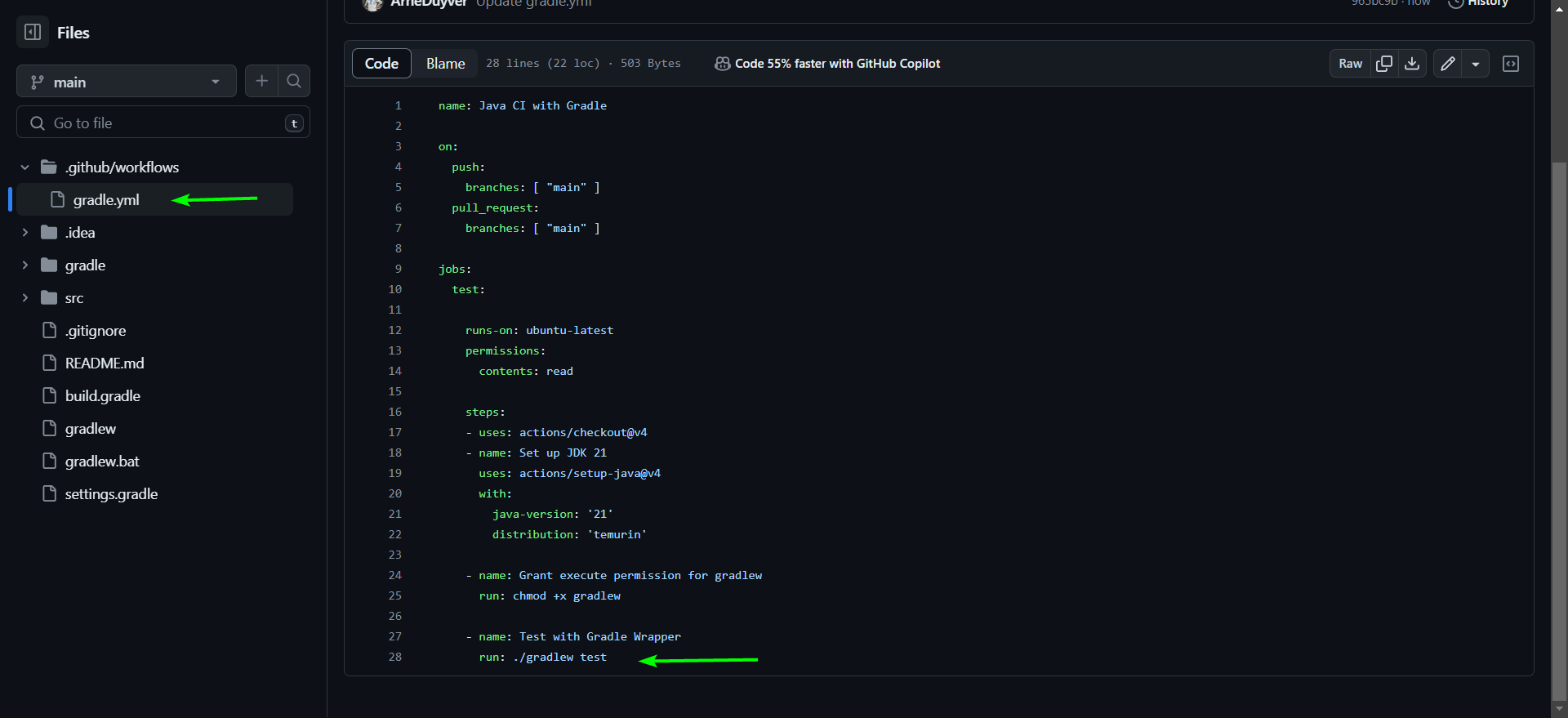
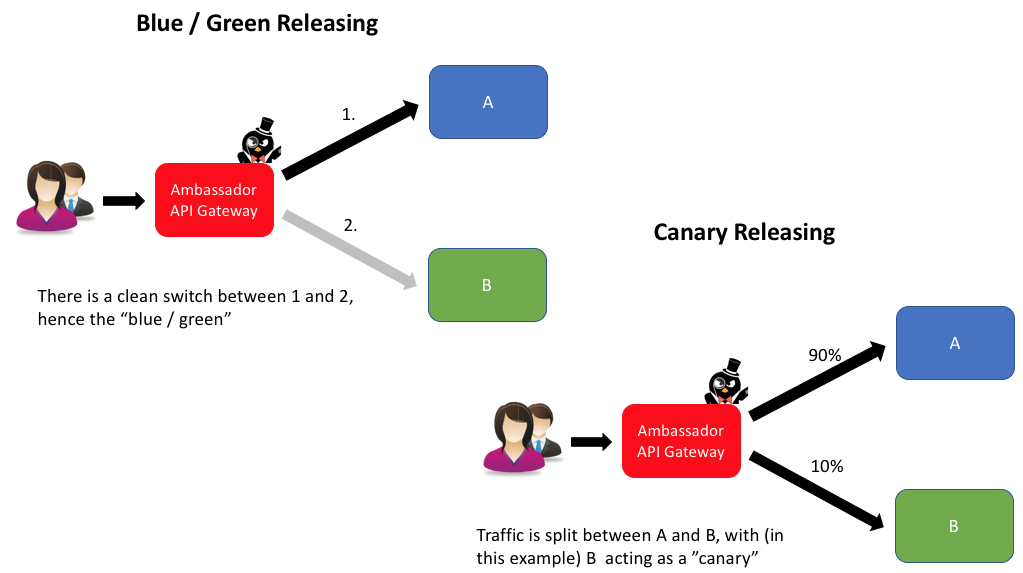

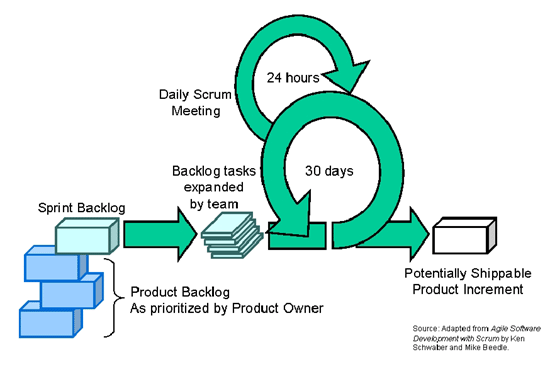




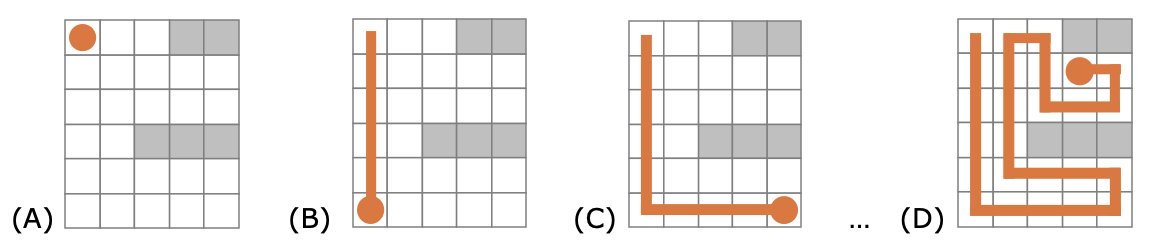
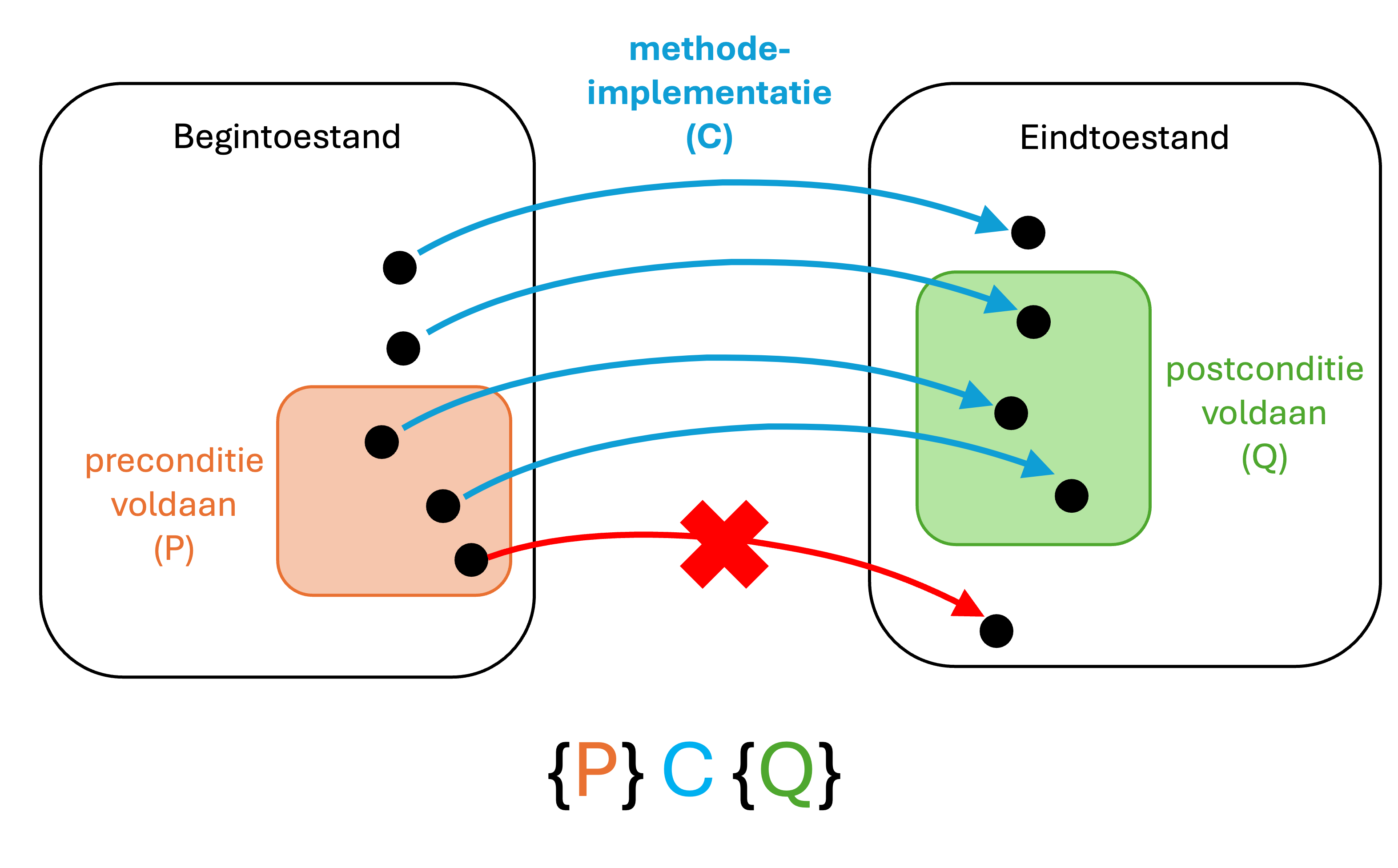








{kind=link}