Subsecties van 8. Recursie en backtracking
8.1 Recursie
Wat is recursie?
Wiskundig gezien zijn recursieve functies functies die zichzelf één of meerdere keren oproepen. Een gekend voorbeeld is faculteit: \( n! = n \times (n-1)! \) met \( 0! = 1 \). Bijvoorbeeld:
\(\begin{align} 5! & = 5 \times 4! \\\\ & = 5 \times (4 \times 3!) \\\\ & = 5 \times (4 \times (3 \times 2!)) \\\\ & = 5 \times (4 \times (3 \times (2 \times 1!))) \\\\ & = 5 \times (4 \times (3 \times (2 \times (1 \times 0!)))) \\\\ & = 5 \times (4 \times (3 \times (2 \times (1 \times 1)))) \\\\ & = 120 \end{align}\)
Een ander gekend voorbeeld zijn de Fibonacci-getallen \( 0, 1, 1, 2, 3, 5, 8, 13, 21, \ldots \), gegeven door volgende recursieve vergelijking: \( F(n) = F(n-1) + F(n-2) \) met \( F(1) = 1 \) en \( F(0) = 0 \).
In Java kunnen we ook recursieve methodes definiëren. Hier is bijvoorbeeld een recursieve methode om de faculteit van een getal te berekenen:
Merk op hoe dicht de implementatie aanleunt bij de wiskundige definitie. Dat geldt ook voor de methode om het n-de Fibonacci-getal te berekenen:
Merk op hoe de functie zichzelf tweemaal oproept.
De recursie eindigt wanneer een basisgeval bereikt wordt.
Dat is een situatie (meestal een zeer eenvoudige) waar het antwoord onmiddellijk gekend is, en geen recursieve oproep meer nodig is.
In bovenstaande code voor fib zijn de basisgevallen de oproepen waarin n kleiner is dan 2.
We zouden ook een versie kunnen maken met meer basisgevallen; op zich maakt dat (buiten een klein beetje efficiëntie-winst) weinig verschil.
Het belangrijkste bij een recursieve functie is dat de ketting van recursieve oproepen ooit eindigt. Volgende recursieve definitie van Fibonacci zou dus niet goed zijn:
Waarom niet?
Recursie achter de schermen
Wanneer we een recursieve functie uitvoeren, doet Java achter de schermen heel wat boekhouding voor ons.
Bekijk onderstaande illustratie die aangeeft wat er allemaal gebeurt om fib(5)=5 te berekenen:
graph TB
t[" "]
f5["return fib(4) + fib(3)"]
f4["return fib(3) + fib(2)"]
f3["return fib(2) + fib(1)"]
f2_1["return fib(1) + fib(0)"]
f2_2["return fib(1) + fib(0)"]
f1_1["return 1"]
f1_2["return 1"]
f1_3["return 1"]
f0_1["return 0"]
f0_2["return 0"]
f3_2["return fib(2) + fib(1)"]
f2_3["return fib(1) + fib(0)"]
f1_4["return 1"]
f1_5["return 1"]
f0_3["return 0"]
t --> |"fib(5)"| f5
f5 --> |"fib(4)"| f4
f4 -->|"fib(3)"| f3
f3 -->|"fib(2)"| f2_1
f2_1 -->|"fib(1)"| f1_1
f1_1 -->|1| f2_1
f2_1 -->|"fib(0)"| f0_1
f0_1 -->|0| f2_1
f2_1 -->|1| f3
f3 -->|"fib(1)"| f1_2
f1_2 -->|1| f3
f3 -->|2| f4
f4 -->|"fib(2)"| f2_2
f2_2 -->|"fib(1)"| f1_3
f1_3 -->|1| f2_2
f2_2 -->|"fib(0)"| f0_2
f0_2 -->|0| f2_2
f2_2 -->|1| f4
f5 --> |"fib(3)"| f3_2
f3_2 -->|"fib(2)"| f2_3
f2_3 -->|"fib(1)"| f1_4
f1_4 -->|1| f2_3
f2_3 -->|"fib(0)"| f0_3
f0_3 -->|0| f2_3
f2_3 -->|1| f3_2
f3_2 -->|"fib(1)"| f1_5
f1_5 -->|1| f3_2
f3_2 -->|2| f5
f4 -->|3| f5
f5 -->|5| t
classDef base fill:#fcc,stroke:#933
class f0_1,f0_2,f0_3 base
class f1_1,f1_2,f1_3,f1_4,f1_5 baseStack
De uitvoering van recursieve methodes maakt (net zoals de uitvoering van gewone methodes) gebruik van een stack.
We herschrijven fib lichtjes om de uitleg te vergemakkelijken:
Elke methode-oproep voegt een stackframe toe; in dat stackframe worden de waarden van alle parameters (bv. n voor fib hierboven) en lokale variabelen (fib_n1, fib_n2, en result) bewaard.
Het bovenste stackframe is het actieve stackframe.
Wanneer de methode-oproep voltooid is (bijvoorbeeld na het uitvoeren van een return-statement) verdwijnt dat stackframe, en wordt het vorige stackframe terug geactiveerd.
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
classDef active stroke:#363,fill:#afa
class f5 active%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
classDef active stroke:#363,fill:#afa
class f4 active%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
f3["`**fib**
n=3
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
f4 --> f3
classDef active stroke:#363,fill:#afa
class f3 active...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
**fib_n1=???**
fib_n2=???
result=???`"]
f3["`**fib**
n=3
fib_n1=1
fib_n2=1
**result=2**`"]
main --> f5
f5 --> f4
f4 --> f3
classDef active stroke:#363,fill:#afa
class f3 active%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
**fib_n2=???**
result=???`"]
f3["`**fib**
n=3
fib_n1=1
fib_n2=1
result=2`"]
main --> f5
f5 --> f4
f4 ~~~ f3
classDef active stroke:#363,fill:#afa;
classDef removed stroke:#aaa,fill:#ddd,color:#aaa;
class f4 active
class f3 removed%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
**fib_n2=???**
result=???`"]
f2["`**fib**
n=2
**fib_n1=???**
fib_n2=???
result=???`"]
main --> f5
f5 --> f4
f4 --> f2
classDef active stroke:#363,fill:#afa
class f2 active...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
**fib_n1=???**
fib_n2=???
result=???`"]
f4["`**fib**
n=4
fib_n1=2
fib_n2=1
**result=3**`"]
main --> f5
f5 --> f4
classDef active stroke:#363,fill:#afa
class f4 active%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f4["`**fib**
n=4
fib_n1=2
fib_n2=1
result=3`"]
f5["`**fib**
n=5
fib_n1=3
**fib_n2=???**
result=???`"]
main --> f5
f5 ~~~ f4
classDef active stroke:#363,fill:#afa
classDef removed stroke:#aaa,fill:#ddd,color:#aaa;
class f5 active
class f4 removed...
%%{init: {"flowchart": {"htmlLabels": false}} }%%
graph BT
main["`**main**`"]
f5["`**fib**
n=5
fib_n1=3
fib_n2=2
**result=5**`"]
main --> f5
classDef active stroke:#363,fill:#afa
class f5 activeStack overflow
Zoals je hierboven kan zien, groeit de stack bij elke recursieve oproep.
Elke stack-frame neemt een bepaalde hoeveelheid geheugen in.
De totale grootte van de stack is echter beperkt.
Wanneer de stack te groot wordt, krijg je een stack overflow.
In Java uit zich dat door het gooien van een StackOverflowException.
Je kan de grootte die gereserveerd wordt voor de stack vergroten door bij de uitvoering een argument (-Xss) mee te geven aan de Java virtual machine (JVM).
Bijvoorbeeld, om een stack van 4 megabyte te voorzien (de standaardgrootte is gewoonlijk 1 MB):
In IntelliJ kan je die optie toevoegen in de ‘Run configuration’.
Gewoonlijk zal dat niet nodig zijn; enkel wanneer je gebruik maakt van recursie voor grotere problemen.
Een meer waarschijnlijke oorzaak van een StackOverflowException is een recursieve operatie die niet eindigt in een basisgeval.
Eindigheid en invoergrootte
Indien een recursieve methode niet zorgvuldig gedefinieerd wordt, bestaat de kans dat de recursie nooit stopt, en de methode dus nooit eindigt (tenzij met een StackOverflowException).
Bijvoorbeeld, onderstaande recursieve methode bad
eindigt enkel voor positieve even getallen (overtuig jezelf hiervan).
Om er zeker van te zijn dat een recursieve methode ooit zal eindigen, moeten we kunnen aantonen dat elke recursieve oproep ooit een basisgeval zal bereiken. Dat is niet altijd eenvoudig of mogelijk. Neem bijvoorbeeld volgende welgekende functie van Collatz, gedefinieerd voor \( n \geq 1 \):
Wanneer we die uitvoeren voor n=5 krijgen we als waarden voor n achtereenvolgens 5, 16, 8, 4, 2, 1 en eindigt de recursie dus na 6 oproepen.
Voor n=12 krijgen we 12, 6, 3, 10, 5, 16, 8, 4, 2, 1, en voor n=19 krijgen we 19, 58, 29, 88, 44, 22, 11, 34, 17, 52, 26, 13, 40, 20, 10, 5, 16, 8, 4, 2, 1.
De reeks waarden in deze voorbeelden lijkt dus steeds te eindigen op n=1, maar is dit zo voor elke beginwaarde van n?
Er zijn geen gekende tegenvoorbeelden, maar er is ook geen bewijs dat dit het geval is voor elke beginwaarde van n.
Bewijzen dat een recursieve functie eindigt is echter wel vanzelfsprekend als elke recursieve oproep de grootte van de invoer strikt kleiner maakt, en de basisgevallen overeenkomen met de kleinst mogelijke invoergrootte(s). Aangezien een invoergrootte steeds (per definitie) een niet-negatief getal moet zijn, moet een voortdurende verkleining ervan ooit stoppen.
Typische invoergroottes bij recursieve problemen zijn
- de waarde van een parameter, indien dit een natuurlijk getal is (bijvoorbeeld
ninfibhierboven) - het aantal elementen in een datastructuur (lijst, set, …) die gebruikt wordt.
Maakt de collatz-methode de invoer steeds strikt kleiner?
Recursief denken
Recursie biedt vaak een erg krachtige manier om complexe algoritmische problemen op te lossen. Je moet hiervoor wel op de juiste manier redeneren over recursie. Een grote valkuil is nadenken over de volledige uitvoeringsboom, zoals we hierboven getoond hebben voor de Fibonacci-functie. De complexiteit hiervan is gigantisch, en staat een elegante oplossing en helder redeneren in de weg.
Een betere manier om na te denken over recursie gaat als volgt. Je wil een probleem van een bepaalde grootte \( n \) oplossen. Stel nu dat je mag veronderstellen dat je (magischerwijze) datzelfde probleem al kan oplossen, maar dan alleen voor alle (strikt kleinere) groottes \( n’ < n \). Hoe kan dit je helpen om het volledige probleem op te lossen? Met andere woorden, welke manieren zie je om een oplossing van een deel van het probleem te transformeren in een oplossing voor het hele probleem? Of nog anders gezegd: recursie gaat om vertrouwen: vertrouw erop dat het kleinere probleem juist opgelost wordt, en besteed enkel aandacht aan hoe je de oplossing voor een kleiner probleem kan gebruiken om de oplossing voor het grotere probleem te vinden. Eens je deze denkwijze onder de knie hebt, wordt recursie bijna een magisch stuk gereedschap.
We bekijken twee voorbeelden van deze denkwijze.
Voorbeeld 1: grootste element
Veronderstel dat je het grootste element uit een lijst van getallen wil bepalen (vergeet even dat we dat ook makkelijk kunnen met behulp van een lus). We noemen de lengte van die lijst \( n \). Stel nu dat we reeds beschikken over een magische oplossing (een functie) om het grootste element te vinden in alle lijsten met een lengte tot en met \( n-1 \). Hoe kunnen we deze oplossing gebruiken om het probleem op te lossen voor een lijst van lengte \( n \)?
Denk hier even zelf over na!
Er zijn verschillende mogelijkheden. We weten bijvoorbeeld dat het grootste element ofwel het eerste element is, ofwel voorkomt in de rest van de lijst (alle elementen behalve het eerste). We kunnen onze magische functie dus gebruiken om het grootste element uit de rest van de lijst te zoeken, en dat vervolgens te vergelijken met het eerste. Dat leidt tot volgende recursieve implementatie:
De basisgevallen hier zijn een lege lijst (er is dan geen grootste element) en een lijst met slechts één element (dat ene element moet het grootste element zijn).
Merk op hoe we een subList gebruiken om makkelijk een kleinere lijst (zonder het element op index 0) te creëren voor de recursieve oproep.
Zoals je je misschien herinnert, is het resultaat van subList een view op de originele lijst — er worden geen elementen gekopieerd.
Dat is dus zeer efficiënt.
Er waren ook andere oplossingsstrategieën mogelijk met een gelijkaardige denkwijze. Bijvoorbeeld, we hadden het laatste element kunnen afzonderen in plaats van het eerste. Of we hadden het maximum van de eerste helft van de elementen kunnen vergelijken met het maximum van de tweede helft:
Recursief denken lijkt voor dit voorbeeld misschien wat overbodig. Het maximum zoeken kan je inderdaad ook heel eenvoudig iteratief (met een for-lus). Daarom volgt een tweede voorbeeld, waar een iteratieve oplossing niet voor de hand ligt.
Voorbeeld 2: Toren van Hanoi
Je kent misschien de puzzel van de toren van Hanoi. We hebben drie stapels (A, B, en C), en op elke stapel mogen schijven liggen, van groot (onderaan) naar klein (bovenaan). De puzzel bestaat eruit om alle schijven van één stapel naar een andere te verplaatsen. Daarbij zijn er twee regels:
- Je mag slechts 1 schijf per keer verplaatsen.
- Een schijf mag nooit op een kleinere schijf terecht komen.

Hoe moeilijk/lang verwacht je dat een algoritme wordt om deze puzzel op te lossen?
Dit probleem wordt heel eenvoudig als we recursief denken. We moeten \( n \) schijven verplaatsen van een bronstapel (bijvoorbeeld A) naar een doelstapel (bijvoorbeeld C), en we hebben een extra stapel (B) die we als hulpstapel kunnen gebruiken. We vertrouwen er bovendien op dat we een magische oplossing (recursie!) hebben om \( n-1 \) (of minder) schijven te verplaatsen van een willekeurige stapel naar een andere willekeurige stapel, volgens de regels van de puzzel. Hoe kunnen we die magische oplossing gebruiken om het hele probleem op te lossen?
Denk hier zelf even over na!
We kunnen eerst de bovenste \( n-1 \) schijven verplaatsen van stapel A naar stapel B (de hulpstapel). De laatste overblijvende schijf op stapel A (de grootste schijf) verplaatsen we nu naar doelstapel C. Tenslotte verplaatsen we de \( n-1\) schijven van hulpstapel B ook naar doelstapel C (opnieuw via onze magische oplossing). Het basisgeval is heel eenvoudig: indien we 0 schijven moeten verplaatsen, doen we niets.
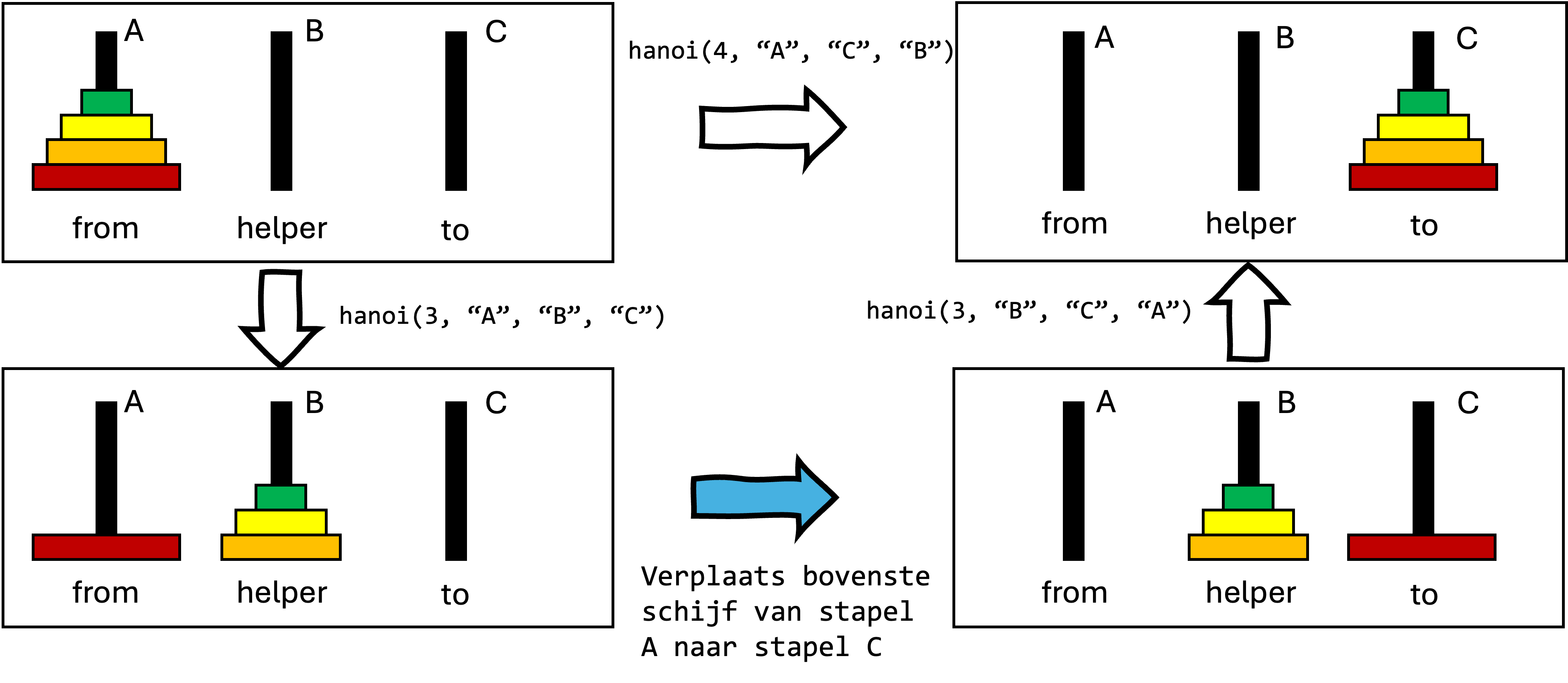
Dat geeft volgende oplossing in code, met n het aantal schijven en from, to, en helper de namen van de stapels, (bijvoorbeeld “A”, “B”, en “C”, of “links”, “midden”, en “rechts”):
Erg kort en elegant, niet?
Als we deze oplossing uitvoeren voor n=4 en from="A", to="C", en helper="B", krijgen we volgende uitvoer:
Ga na dat dit een correcte oplossing is voor het probleem, bijvoorbeeld via deze simulator.
Ter illustratie: de volledige uitvoeringsboom die bij bovenstaande uitvoer hoort ziet er als volgt uit; je leest de oplossing van boven naar onder af in de groene nodes. Het spreekt hopelijk voor zich dat denken over recursie in termen van zo’n bijhorende uitvoeringsboom niet de makkelijkste of duidelijkste manier is.
graph LR H4ACB["1: hanoi(4,A,C,B)"] H4ACBH3ABC["2: hanoi(3,A,B,C)"] H4ACBH3ABCH2ACB["3: hanoi(2,A,C,B)"] H4ACBH3ABCH2ACBH1ABC["4: hanoi(1,A,B,C)"] H4ACBH3ABCH2ACBH1ABCH0ACB["5: hanoi(0,A,C,B)"] H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCH0ACB H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCm["6: Move A to B"]:::move H4ACBH3ABCH2ACBH1ABCH0CBA["7: hanoi(0,C,B,A)"] H4ACBH3ABCH2ACBH1ABC --> H4ACBH3ABCH2ACBH1ABCH0CBA H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBH1ABC H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBm["8: Move A to C"]:::move H4ACBH3ABCH2ACBH1BCA["9: hanoi(1,B,C,A)"] H4ACBH3ABCH2ACBH1BCAH0BAC["10: hanoi(0,B,A,C)"] H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAH0BAC H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAm["11: Move B to C"]:::move H4ACBH3ABCH2ACBH1BCAH0ACB["12: hanoi(0,A,C,B)"] H4ACBH3ABCH2ACBH1BCA --> H4ACBH3ABCH2ACBH1BCAH0ACB H4ACBH3ABCH2ACB --> H4ACBH3ABCH2ACBH1BCA H4ACBH3ABC --> H4ACBH3ABCH2ACB H4ACBH3ABC --> H4ACBH3ABCm["13: Move A to B"]:::move H4ACBH3ABCH2CBA["14: hanoi(2,C,B,A)"] H4ACBH3ABCH2CBAH1CAB["15: hanoi(1,C,A,B)"] H4ACBH3ABCH2CBAH1CABH0CBA["16: hanoi(0,C,B,A)"] H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABH0CBA H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABm["17: Move C to A"]:::move H4ACBH3ABCH2CBAH1CABH0BAC["18: hanoi(0,B,A,C)"] H4ACBH3ABCH2CBAH1CAB --> H4ACBH3ABCH2CBAH1CABH0BAC H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAH1CAB H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAm["19: Move C to B"]:::move H4ACBH3ABCH2CBAH1ABC["20: hanoi(1,A,B,C)"] H4ACBH3ABCH2CBAH1ABCH0ACB["21: hanoi(0,A,C,B)"] H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCH0ACB H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCm["22: Move A to B"]:::move H4ACBH3ABCH2CBAH1ABCH0CBA["23: hanoi(0,C,B,A)"] H4ACBH3ABCH2CBAH1ABC --> H4ACBH3ABCH2CBAH1ABCH0CBA H4ACBH3ABCH2CBA --> H4ACBH3ABCH2CBAH1ABC H4ACBH3ABC --> H4ACBH3ABCH2CBA H4ACB --> H4ACBH3ABC H4ACB --> H4ACBm["24: Move A to C"]:::move H4ACBH3BCA["25: hanoi(3,B,C,A)"] H4ACBH3BCAH2BAC["26: hanoi(2,B,A,C)"] H4ACBH3BCAH2BACH1BCA["27: hanoi(1,B,C,A)"] H4ACBH3BCAH2BACH1BCAH0BAC["28: hanoi(0,B,A,C)"] H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAH0BAC H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAm["29: Move B to C"]:::move H4ACBH3BCAH2BACH1BCAH0ACB["30: hanoi(0,A,C,B)"] H4ACBH3BCAH2BACH1BCA --> H4ACBH3BCAH2BACH1BCAH0ACB H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACH1BCA H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACm["31: Move B to A"]:::move H4ACBH3BCAH2BACH1CAB["32: hanoi(1,C,A,B)"] H4ACBH3BCAH2BACH1CABH0CBA["33: hanoi(0,C,B,A)"] H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABH0CBA H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABm["34: Move C to A"]:::move H4ACBH3BCAH2BACH1CABH0BAC["35: hanoi(0,B,A,C)"] H4ACBH3BCAH2BACH1CAB --> H4ACBH3BCAH2BACH1CABH0BAC H4ACBH3BCAH2BAC --> H4ACBH3BCAH2BACH1CAB H4ACBH3BCA --> H4ACBH3BCAH2BAC H4ACBH3BCA --> H4ACBH3BCAm["36: Move B to C"]:::move H4ACBH3BCAH2ACB["37: hanoi(2,A,C,B)"] H4ACBH3BCAH2ACBH1ABC["38: hanoi(1,A,B,C)"] H4ACBH3BCAH2ACBH1ABCH0ACB["39: hanoi(0,A,C,B)"] H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCH0ACB H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCm["40: Move A to B"]:::move H4ACBH3BCAH2ACBH1ABCH0CBA["41: hanoi(0,C,B,A)"] H4ACBH3BCAH2ACBH1ABC --> H4ACBH3BCAH2ACBH1ABCH0CBA H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBH1ABC H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBm["42: Move A to C"]:::move H4ACBH3BCAH2ACBH1BCA["43: hanoi(1,B,C,A)"] H4ACBH3BCAH2ACBH1BCAH0BAC["44: hanoi(0,B,A,C)"] H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAH0BAC H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAm["45: Move B to C"]:::move H4ACBH3BCAH2ACBH1BCAH0ACB["46: hanoi(0,A,C,B)"] H4ACBH3BCAH2ACBH1BCA --> H4ACBH3BCAH2ACBH1BCAH0ACB H4ACBH3BCAH2ACB --> H4ACBH3BCAH2ACBH1BCA H4ACBH3BCA --> H4ACBH3BCAH2ACB H4ACB --> H4ACBH3BCA classDef move stroke:green,fill:#afa
Recursie vs. iteratie
In sommige gevallen kan je een for- of while-lus eenvoudig herschrijven tot een recursieve methode en omgekeerd. Die omzetting volgt vaak eenzelfde patroon. Gegeven volgende while- of for-lus (in pseudocode):
kunnen we volgende equivalente recursieve versie schrijven (opnieuw in pseudo-code):
Bijvoorbeeld, de iteratieve versie om faculteit te berekenen met een for-lus ziet er als volgt uit:
En de bijhorende recursieve versie (volgens bovenstaand schema):
De factorial_worker methode kunnen we ook nog wat korter schrijven:
Deze recursieve oplossing bestaat uit 2 methodes; je herinnert je misschien nog dat de fac-methode aan het begin van deze pagina uit slechts 1 recursieve methode bestond:
Het verschil is dat we bij factorial gebruik maakten van het worker-wrapper patroon voor recursie.
Dat patroon zie je vaak opduiken.
De recursieve factorial_worker-methode (met 2 parameters) is de worker (daar gebeurt het eigenlijke werk), en de (niet-recursieve) factorial-methode met 1 parameter is de wrapper (die roept enkel de worker op met beginwaarden voor de extra parameters).
Hulpvariabelen (hier het voorlopige resultaat, namelijk result) worden doorgegeven als parameters van de worker-methode.
Die parameter wordt ook vaak de ‘accumulator’ genoemd, aangezien die het resultaat bijhoudt van al het werk dat tot dan toe gebeurd is.
De factorial_worker-methode is ook tail-recursive.
Dat betekent dat de recursieve oproep de laatste bewerking is die gebeurt voor de functie eindigt (ze staat direct achter de ‘return’).
In sommige programmeertalen (maar niet in Java) worden dergelijke tail-recursive oproepen geoptimaliseerd door de compiler: aangezien er geen werk meer uitgevoerd moet worden na de recursieve oproep, kan het stackframe meteen ook verwijderd worden. Je loopt dan geen risico op een stack overflow door teveel recursieve oproepen.
Tail-recursie (maar dan in C++) zal in meer detail behandeld worden in het vak Algoritmen en datastructuren.
Efficiëntie
Wie goed kijkt naar de uitvoeringsboom van fib(5) hierboven kan zien dat er delen van de boom zijn die terugkeren.
Bijvoorbeeld, fib(3) wordt tweemaal opnieuw berekend, fib(2) driemaal, en fib(1) komt vijfmaal voor.
Dat is natuurlijk niet erg efficiënt.
Technieken zoals ‘dynamisch programmeren’ (dynamic programming) en memoization kunnen hier soelaas bieden. We gebruiken deze technieken niet verder binnen deze cursus, maar deze komen later wel aan bod binnen het opleidingsonderdeel Algoritmen en datastructuren.
Patronen om het probleem te verkleinen
Zoals eerder gezegd, gaan we bij recursie kijken of/hoe de oplossing voor hetzelfde maar kleiner probleem ons kan helpen om het volledige probleem op te lossen. Er zijn enkele vaak voorkomende manieren om dat te doen, die we hier kort oplijsten. Alle manieren komen in essentie natuurlijk op hetzelfde neer: een geschikt deelprobleem zoeken dat je helpt om het volledige probleem op te lossen.
Een numerieke parameter rechtstreeks verkleinen. Bijvoorbeeld, de oplossing voor parameter
xberekenen aan de hand van de oplossing voorx-1,x-2,x/2, …Het eerste/laatste element van de invoer weglaten. Bijvoorbeeld, de oplossing voor de hele invoerlijst
lstberekenen aan de hand van de oplossing voor de invoerlijst maar dan zonder het eerste of laatste element (bv.lst.subList(1, lst.size()))). Hetzelfde idee kan je toepassen op Strings (metsubstring).De invoer halveren. Bijvoorbeeld, de oplossing voor de hele lijst
lstberekenen aan de hand van de oplossing voor de eerste en tweede helft van de invoerlijst (bv.lst.subList(0, lst.size()/2)). Ook dit idee kan toegepast worden op Strings (metsubstring).Twee situaties beschouwen. Dit is een variant van het weglaten van het eerste/laatste element die vooral handig is bij problemen waar de oplossing gevormd wordt met een combinatie van sommige invoerelementen. Je beschouwt dan twee deelproblemen:
- je zoekt eerst naar een oplossing waarbij je ervan uitgaat dat het eerste (of laatste, middelste, …) element deel uitmaakt van de oplossing.
- Daarnaast zoek je ook naar een oplossing waarbij je ervan uitgaat dat dat element geen deel uitmaakt van de oplossing.
Voor elk van die twee situaties los je dan een kleiner (en waarschijnlijk aangepast) probleem op waarbij je verder geen rekening meer houdt met dat ene element. Achteraf combineer je de oplossingen voor beide deelproblemen op een gepaste manier. Zie de oefeningen voor concrete voorbeelden (in het bijzonder de oefening over gepast betalen).
Recursie: oefeningen
Je vind tests en skelet-code voor de oefeningen rond recursie op Github:
Palindroom
Schrijf een recursieve functie isPalindrome die nagaat of een String een palindroom is.
Een String is een palindroom als die hetzelfde is van links naar rechts als van rechts naar links, bijvoorbeeld
racecarleveldeifiedlepeldroomoordreddermeetsysteemkoortsmeetsysteemstrook
String omkeren
Schrijf een recursieve methode reverse om een String om te keren, bijvoorbeeld:
Hello->olleHracecar->racecar
Element zoeken in lijst
Schrijf een recursieve functie <T> int search(List<T> list, T element) die nagaat of het gegeven element voorkomt in de gegeven lijst.
Als het element voorkomt, wordt de index teruggegeven, anders -1.
- Maak eerst een versie die werkt voor een willekeurige (niet-gesorteerde) lijst.
- Maar vervolgens een snellere versie die werkt voor een gesorteerde lijst, door het te doorzoeken stuk van de lijst telkens halveert en slechts in één van die helften verder gaat zoeken. (Dit is ‘binary search’)
Duplicaten verwijderen
Schrijf een recursieve methode removeDuplicateCharacters die opeenvolgende dezelfde karakters uit een String verwijdert.
Bijvoorbeeld:
aaaaa->akoortsmeetsysteemstrook->kortsmetsystemstrokAAAbbCdddAAA->AbCdA
Trap beklimmen
Schrijf een functie om te berekenen hoeveel verschillende manieren er zijn om een trap met \( n \) treden op te gaan, als je bij elke stap kan kiezen om 1 of 2 treden tegelijk te nemen. Bijvoorbeeld, een trap met \( n = 4 \) treden kan je op 5 verschillende manieren beklimmen:
- 1 trede, 1 trede, 1 trede, 1 trede
- 1 trede, 1 trede, 2 treden
- 1 trede, 2 treden, 1 trede
- 2 treden, 1 trede, 1 trede
- 2 treden, 2 treden
Alle permutaties van een lijst berekenen
Schrijf een functie allPermutations die een Set teruggeeft met alle permutaties van een gegeven lijst.
Bijvoorbeeld:
allPermutations(List.of("A", "B")) = [ [A, B], [B, A] ]allPermutations(List.of("A", "B", "C")) = [ [A, B, C], [A, C, B], [B, A, C], [B, C, A], [C, A, B], [C, B, A] ]
Gepast betalen
Schrijf een recursieve methode boolean kanGepastBetalen(int bedrag, List<Integer> munten) die nagaat of je het gegeven bedrag (uitgedrukt in eurocent) gepast kan betalen met (een deel van) de gegeven munten (en briefjes). Elke munt in de lijst mag slechts één keer gebruikt worden.
Bijvoorbeeld:
kanGepastBetalen(20, List.of(50, 10, 10, 5))geeft true terug, want 10+10 = 20.kanGepastBetalen(125, List.of(100, 100, 50, 20, 10, 5 ))geeft true terug, want 100+20+5 = 125.kanGepastBetalen(260, List.of(100, 100, 50, 20, 5 ))geeft false terug: er is geen combinatie van munten die samen 260 geeft.
Gepast betalen (bis)
Gegeven een lijst van muntwaarden (bv. 5, 10, 20, 50, 100, 200), schrijf een recursieve methode int countChange(int amount, List<Integer> coinValues) die bepaal op hoeveel manieren je een specifiek bedrag kan betalen.
Je mag nu veronderstellen dat je een voldoende aantal (of oneindig veel) munten van elke opgegeven waarde hebt.
Met andere woorden, je mag een munt(waarde) meerdere keren gebruiken.
Bijvoorbeeld, met bovenstaande muntwaarden
countChange(35, List.of(5, 10, 20, 50, 100, 200)) == 6: je kan een bedrag van 35 betalen op 6 manieren:- 7×5
- 1×10 en 5×5
- 1×10 en 1×20 en 1×5
- 2×10 en 3×5
- 3×10 en 1×5
- 1×20 en 3×5
countChange(260, List.of(5, 10, 20, 50, 100, 200)) == 646: je kan een bedrag van 260 betalen op 646 manierencountChange(1000, List.of(5, 10, 20, 50, 100, 200)) == 98411: je kan een bedrag van 1000 betalen op 98411 manieren
Alle prefixen van een String
Schrijf een recursieve functie allPrefixes die een Set teruggeeft met alle prefixen van een gegeven String.
Bijvoorbeeld:
allPrefixes("cat") == { "", "c", "ca", "cat" }allPrefixes("Hello") == { "", "H", "He", "Hel", "Hell", "Hello" }
Alle interleavings van twee strings
Schrijf een recursieve functie allInterleavings(String s1, String s2) die een Set teruggeeft met alle interleavings van de twee strings s1 en s2.
Een interleaving is een nieuwe string met daarin alle karakters van de eerste en de tweede string, in dezelfde volgorde waarin ze in elk van de originele strings voorkomen, maar mogelijk afwisselend.
Bijvoorbeeld:
allInterleavings("A", "B") = [AB, BA]allInterleavings("ABC", "x") = [ABCx, ABxC, AxBC, xABC]allInterleavings("AB", "xy") = [ABxy, AxBy, AxyB, xABy, xAyB, xyAB]allInterleavings("ABC", "xy") = [ABCxy, ABxCy, ABxyC, AxBCy, AxByC, AxyBC, xABCy, xAByC, xAyBC, xyABC]
Sum of digits
Schrijf een recursieve methode int sumOfDigits(long number) die de som van de cijfers van een (niet-negatief) getal berekent, en dat herhaalt tot die som kleiner is dan 10.
Bijvoorbeeld: 62984 geeft 6+2+9+8+4 = 29; dat wordt vervolgens 2+9 = 11; en dat wordt uiteindelijk 1+1 = 2.
Het resultaat is dus 2.
Vliegtuigreis
Gegeven een record Item:
wat een item voorstelt dat je mee wil nemen op reis. Het item heeft een naam, een gewicht (> 0), en een waarde (hoe graag je het mee wil, > 0).
Schrijf een methode List<Item> pack(List<Item> choices, int maxWeight) die een keuze maakt uit de gegeven lijst van items, zodanig dat de items met een zo groot mogelijke totaalwaarde kan meenemen zonder dat het totale gewicht hoger wordt dan het maximumgewicht (opgelegd door de vliegtuigmaatschappij).
Bijvoorbeeld, met vier items (A, 50kg, 10), (B, 20kg, 5), (C, 10kg, 2), en (D, 5kg, 1):
- met een totaal toegelaten gewicht van 100kg kan je alle items meenemen, voor een totale waarde van 18;
- met een totaal toegelaten gewicht van 60kg kan je best items A en C meenemen, voor een totale waarde van 12;
- met een totaal toegelaten gewicht van 20kg kan je best item B meenemen, voor een totale waarde van 5;
Powerset
Schrijf een recursieve functie Set<Set<T>> powerset(Set<T> s) die de powerset berekent van de gegeven set s.
De powerset is de set van alle deelverzamelingen van s.
Bijvoorbeeld:
powerset(Set.of("A", "B")) = [[], [A], [B], [A, B]]powerset(Set.of("A", "B", "C")) = [[], [A], [B], [C], [A, B], [A, C], [B, C], [A, B, C]]
Gebalanceerde haakjes
Schrijf met behulp van recursie een methode boolean balancedParentheses(String s) die nagaat of alle haakjes in de gegeven string gebalanceerd zijn.
Bijvoorbeeld:
()geeft true terug())geeft false terug()()geeft true terug)(geeft false terug((geeft false terugabc(def(xy))zgeeft true teruga(bc(def(xy))zgeeft false terug
Longest common subsequence
Schrijf een recursieve methode String longestCommonSubsequence(String s1, String s2) die de langste reeks karakters teruggeeft die in beide strings in dezelfde volgorde terugkomen (niet noodzakelijk aaneensluitend). Als er meerdere oplossingen zijn, maakt het niet uit welke je teruggeeft.
Bijvoorbeeld:
longestCommonSubsequence("gitaarsnaar", "imaginair") == "ginar" of "ianar":gitaarsnaar
enimaginair
, ofgitaarsnaar
enimaginair
longestCommonSubsequence("aardappel", "adoptie") == "adpe":aardappel
enadoptie
longestCommonSubsequence("sterrenstelselsamenstellingsanalyseinstrument", "restaurantkeukenapparatuurontwerpmethodiek") == "restantenaantrmet"(met dank aan ChatGPT voor de suggestie):sterrenstelselsamenstellingsanalyseinstrument
enrestaurantkeukenapparatuurontwerpmethodiek
Het laatste voorbeeld zal waarschijnlijk veel te lang duren. Je kan nadenken of je je algoritme wat ‘slimmer’ kan maken.
Stack omkeren
Schrijf een recursieve methode <T> void reverse(Deque<T> stack) die de volgorde van de items in een stack (Deque) omdraait, zonder gebruik te maken van een extra datastructuur (dus zonder een andere array, lijst, set, …).
Maak enkel gebruik van de isEmpty()-, pollFirst() en addFirst()-methodes van de Deque-interface.
Denkvraag: ondanks dat je geen extra datastructuur mag gebruiken in je oplossing, wordt er toch een vorm van extra opslag gebruikt om de stack te kunnen omkeren. Waar bevindt die opslag zich?
Toren van Hanoi (uitbreiding)
Los de toren van Hanoi op voor \( n\) schijven op 4 stapels (dus 2 hulpstapels). Je kan je oplossing manueel uittesten via deze simulator. (In de simulator moet je klikken, niet slepen)
Sorteren van een lijst
Schrijf een recursieve methode om een lijst van getallen te sorteren. De sortering moet in-place gebeuren (je past de lijst zelf aan door elementen van volgorde te wisselen, en geeft dus geen nieuwe lijst terug).
reduce
Schrijf een recursieve reduce-operatie die werkt op een lijst, naar analogie met de reduce-operatie op streams.
Boomstructuur
In deze oefening maken we gebruik van een boomstructuur. Deze structuur zal in het vak rond algoritmen en datastructuren een belangrijke rol spelen en daar dan ook uitgebreid aan bod komen. We gebruiken deze hier enkel als voorbeeld.
Gegeven onderstaande record om een boomstructuur op te bouwen:
De boom
kan je hiermee aanmaken als:
- Schrijf een recursieve methode
int treeSize(TreeNode<?> tree)om het totale aantal knopen in de boom te berekenen. Voor de boom hierboven is de grootte 6. - Schrijf een recursieve methode
int treeHeight(TreeNode<?> tree)om de hoogte van de boom te berekenen. De hoogte is het maximum aantal stappen van de wortel (“A” hierboven) tot een kind (“C”, “D”, of “F”). In het voorbeeld is de hoogte dus 2. - Schrijf een recursieve methode
<T> void visitDepthFirstPreOrder(TreeNode<T> tree, Consumer<T> consumer)die de elementen van de boom overloopt in depth-first, pre-order volgorde. Dat houdt in: eerst de huidige knoop, dan de knopen van de linkertak (opnieuw in depth-first pre-order volgorde) en daarna die van de rechtertak. Voor de boom hierboven worden dus achtereenvolgens knopen “A”, “B”, “C”, “D”, “E”, en “F” bezocht en doorgegeven aan de consumer. Een voorbeeld van het gebruik van de methode om de knopen uit te printen: - Schrijf een recursieve methode
<T> void visitDepthFirstInOrder(TreeNode<T> tree, Consumer<T> consumer)die de elementen van de boom overloopt in depth-first, in-order volgorde. Dat houdt in: eerst de linkertak (in depth-first in-order volgorde), dan de knoop zelf, dan de rechtertak. Voor de boom hierboven worden dus achtereenvolgens knopen “C”, “B”, “D”, “A”, “F”, en “E” bezocht en doorgegeven aan de consumer. - Schrijf een recursieve methode
<T> TreeNode<T> mirrorTree(TreeNode<T> tree)om een willekeurige boom te spiegelen: het resultaat moet een nieuwe boom zijn, waar de linker-takken de rechtertakken geworden zijn en omgekeerd. De gespiegelde versie van de boom hierboven is dus:
- (extra) Schrijf een methode
String prettyPrint(TreeNode<?> tree)die een ASCII-voorstelling van de boom maakt. De voorbeeldboom wordt bijvoorbeeld:
Expressie (uit records)
De oefeningen over de expressie-hierarchie uit de les rond records maken ook gebruik van recursie.
8.2 Backtracking
Wat is backtracking?
Backtracking is een techniek om oplossingen te vinden voor zoekproblemen. Een eenvoudig voorbeeld waar je backtracking kan toepassen is de weg zoeken in een doolhof: op elke splitsing waar je kan kiezen welke richting je uitgaat, maak je een keuze. Als die keuze niet leidde tot een oplossing, keer je terug naar die splitsing en probeer je een van de andere richtingen.
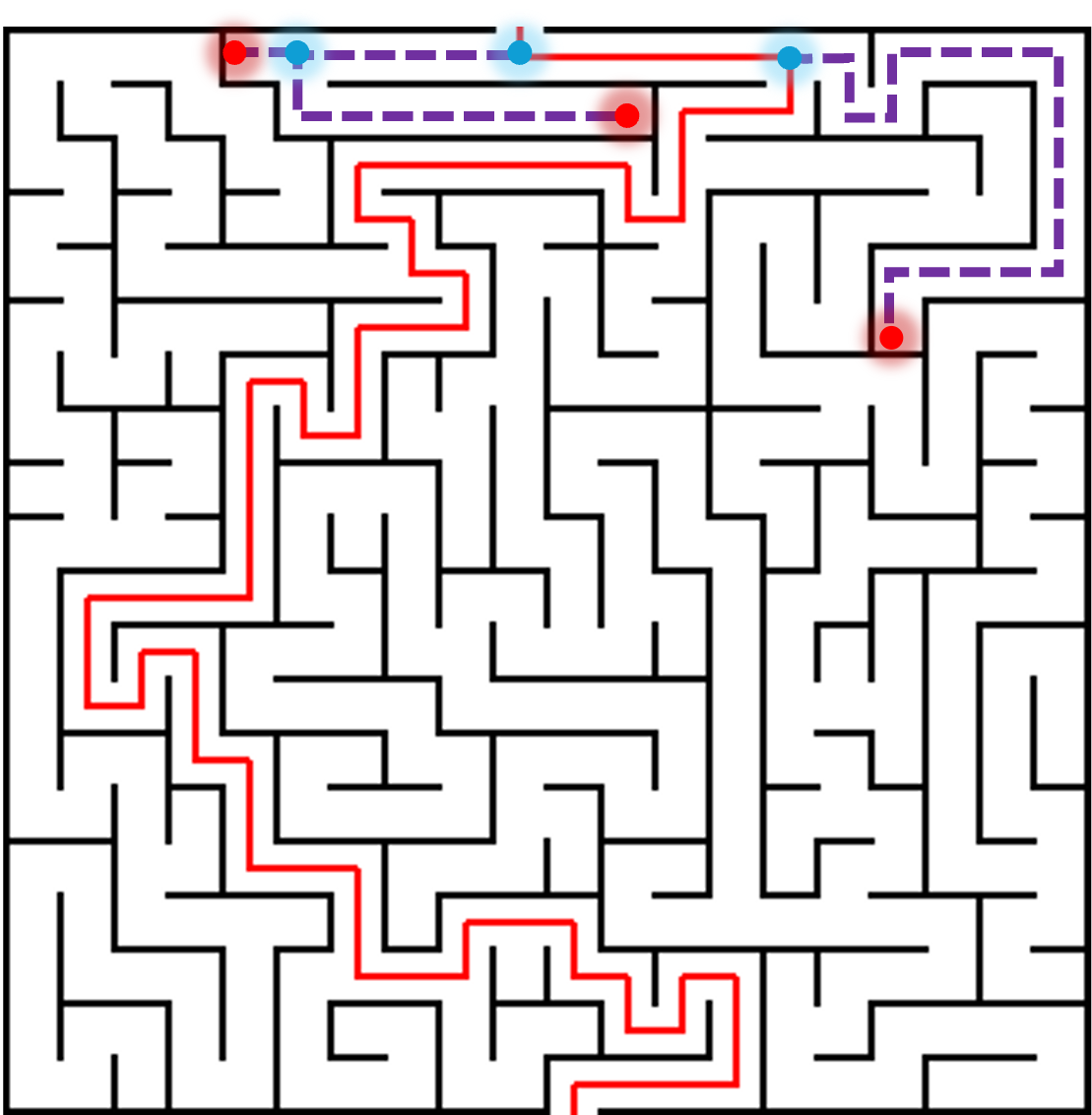
Meer algemeen werkt een backtracking-algoritme als volgt:
- je vertrekt van een gedeeltelijke oplossing (in het begin is die leeg). In het voorbeeld van de doolhof: het pad dat je al afgelegd hebt om tot bij een splitsing te komen.
- je breidt die gedeeltelijke oplossing stapsgewijs uit naar een volledige(re) oplossing, waar je bij elke uitbreiding een keuze maakt. Wanneer die keuze later niet blijkt te leiden tot een geschikte oplossing, keer je terug naar dat keuzepunt (backtracking) en maak je een andere keuze. In het voorbeeld van de doolhof: als je vastzit, keer keer je terug naar de vorige splitsing, en je kiest een andere gang. Als je alle gangen geprobeerd hebt zonder resultaat, keer je terug naar de splitsing daarvoor, etc.
Een backtracking-algoritme maakt meestal gebruik van recursie. De stack die impliciet gebruikt wordt bij recursie is immers heel handig om bij te houden welke keuzes al gemaakt werden, en in welke volgorde.
Voorbeeld: token segmentatie
Het token segmentatie probleem bestaat erin na te gaan of je een gegeven string kan bekomen als sequentie van een of meerdere tokens uit een gegeven lijst van tokens.
Bijvoorbeeld: voor de string "catsanddogs" en de tokenlijst [s, an, ca, cat, dog, and, sand, dogs] zijn volgende segmentaties mogelijk:
cat sand dogscat sand dog scat s and dog scat s and dogs
Met dezelfde woordenlijst kan de string acatandadog niet gesegmenteerd worden.
We bespreken hieronder hoe we dit probleem kunnen oplossen met backtracking. We beschouwen drie varianten:
- uitzoeken of er minstens één segmentatie bestaat (en die teruggeven)
- alle mogelijke segmentaties teruggeven
- de segmentatie die het minst aantal tokens gebruikt teruggeven.
Eén (willekeurige) oplossing zoeken
De essentie van een backtracking-algoritme is het zoeken van één oplossing. Dit ligt ook aan de basis van de andere twee varianten (zoeken van alle oplossingen en zoeken van een optimale oplossing). Het achterliggend idee is zeer eenvoudig: probeer telkens iets, en als dat niet tot een oplossing leidt, keer terug en probeer iets anders, tot je een oplossing gevonden hebt of alles geprobeerd hebt (dan is er geen oplossing). We bekijken nu hoe we dit idee concreet kunnen beschrijven met een algoritme.
Voorbeeld: token segmentatie
Stel: we willen voor het segmentatie-probleem een (willekeurige) oplossing teruggeven (als die bestaat). De oplossing zoeken met een backtracking-algoritme zal, zoals gezegd, gebaseerd zijn op recursie. Dus: om token segmentatie voor een string van lengte \( n \) te doen, veronderstellen we dat we dit al kunnen oplossen voor alle strings van lengte \( n' < n \). Het basisgeval is een lege string segmenteren; we moeten dan geen tokens gebruiken.
We moeten nu enkel nog nadenken over hoe een oplossing voor een kortere string ons precies kan helpen om het hele probleem op te lossen.
Denk hier zelf even over na
Hier is een idee: wat als we, voor elke mogelijke token, nagaan of die overeenkomt met het begin van de string, en als dat zo is, die token wegknippen uit het begin van de string? Zo wordt de string korter, en kunnen we recursie gebruiken om het probleem verder op te lossen voor die kortere string. De oplossing voor het hele probleem bestaat dan uit de weggeknipte token, gevolgd door de tokens die nodig zijn om de kortere string op te bouwen (die bekomen we via de recursie).
We maken dus telkens één keuze, namelijk welk token (uit de lijst van mogelijke tokens) we proberen te matchen met het begin van de string.
Hieronder zie je een zoekboom die een mogelijke uitvoering van dat idee weergeeft voor de string catsanddogs en de tokenlijst [s, an, ca, cat, dog, and, sand, dogs].
Om die te begrijpen, beginnen we bovenaan.
In de rechthoeken staat telkens de lijst van tokens die we tot dan toe gekozen hebben, en de resterende string.
In het begin hebben we nog geen tokens gekozen ([]), en is de resterende string nog gelijk aan de volledige string catsanddogs.
De pijltjes geven aan welke token we kiezen (we tonen enkel de tokens die overeenkomen met het begin van de string; de anderen leiden sowieso tot niets).
We volgen steeds eerst de linkerpijl naar beneden.
De gestippelde lijnen geven aan waar we backtracken.
Een situatie die niet tot een oplossing kan leiden (geen enkele token komt overeen met het begin van de string) wordt rood gekleurd; we gaan dan terug een knoop naar boven en nemen de volgende tak. De gevonden oplossing wordt in het groen aangeduid. Eens deze gevonden is, zoeken we niet meer verder.
graph TB start["[], catsanddogs"] start -->|ca| ca ca["[ca], tsanddogs"] class ca fail ca -.-> start start -->|cat| cat cat["[cat], sanddogs"] cat -->|s| cat_s cat_s["[cat, s], anddogs"] cat_s -->|an| cat_s_an cat_s_an["[cat, s, an], ddogs"] class cat_s_an fail cat_s_an -.-> cat_s cat_s -->|and| cat_s_and cat_s_and["[cat, s, and], dogs"] cat_s_and -->|dog| cat_s_and_dog cat_s_and_dog["[cat, s, and, dog], s"] cat_s_and_dog -->|s| cat_s_and_dog_s cat_s_and_dog_s["[cat, s, and, dog, s], "] class cat_s_and_dog_s success classDef success fill:#2c2,stroke:#393,stroke-width:3,color:white; classDef fail fill:#c22,stroke:#933,stroke-width:3,color:white;
De informatie in de rechthoeken stelt de gedeeltelijke/partiële oplossing voor die we bijhouden. Die bevat hier dus twee zaken:
- de reeds gebruikte token-sequentie (initieel een lege lijst)
- het deel van de string dat nog overblijft (initieel de hele string)
Nadat we een token gekozen hebben, moeten we deze gedeeltelijke oplossing uitbreiden (aanpassen) op basis van die keuze. Om dat te doen, moeten we
- nakijken of het gekozen token voorkomt aan het begin van de resterende string
- dat token toevoegen aan de lijst van gebruikte tokens
- de resterende string inkorten, door het token vooraan te verwijderen
Eens we dat gedaan hebben, kiezen we opnieuw een token en doen we hetzelfde. Die herhaling gebeurt door middel van recursie.
We hebben een oplossing gevonden wanneer het overblijvende deel van de string leeg is.
Als later zou blijken dat een gemaakte keuze fout was (dus dat we met die keuze niet tot een oplossing komen), moeten we deze keuze ongedaan maken (backtracken, overeenkomstig de gestippelde pijlen). Om dat te doen, verwijderen we het laatste token terug uit de token-sequentie, en moeten we zorgen dat we terug de niet-ingekorte string gebruiken. We proberen dan opnieuw met een ander token.
Hoe ziet dat eruit in code? Zo:
De gedeeltelijke oplossing wordt voorgesteld met de twee parameters remainingString en tokensUsedSoFar.
Het basisgeval komt overeen met een lege string; we hebben dan een oplossing gevonden.
Die oplossing zit in de parameter tokensUsedSoFar.
Als de string niet leeg is, proberen we alle tokens beurt om de beurt uit.
- Als een token niet overeenkomt met het begin van de string, kunnen we die token meteen overslaan.
- Als die wel overeenkomt met het begin, voegen we de token toe aan de lijst met gebruikte keuzes en korten we de string in door de token vooraan te verwijderen.
We zoeken vervolgens recursief verder naar een oplossing.
Als we een oplossing vinden, hebben we meteen ook een oplossing voor het hele probleem.
Zo niet, dan verwijderen we onze token terug uit de lijst van gebruikte tokens, vooraleer we opnieuw proberen met de volgende token.
(De string hoeven we niet terug langer te maken; we kunnen gewoon
remainingStringblijven gebruiken)
Als we alle tokens geprobeerd hebben zonder een oplossing te vinden (return solution werd nooit uitgevoerd), dan is er geen oplossing en geven we null terug.
Om deze methode wat eenvoudiger bruikbaar te maken, kunnen we het worker-wrapper patroon toepassen.
We voegen dan een tweede findAny-methode toe, die geen lijst van gebruikte tokens bevat, en de methode hierboven oproept met een lege lijst.
Skelet-programma (algemeen)
Backtracking-algoritmes volgen vaak een gelijkaardige structuur. Naast een voorbeeld geven we daarom telkens ook een skelet-programma: een algemene structuur die je vaak kan herbruiken. Backtracking-algoritmes draaien allemaal rond het gebruik van een partiële oplossing: dat is de sequentie van keuzes die je reeds gemaakt hebt, en de toestand waarin je je daardoor bevindt. Voor elk probleem zal je een geschikte representatie (datastructuur) moeten kiezen voor je partiële oplossing. Om de skelet-programma’s algemeen te houden, gebruiken we hiervoor volgende interfaces (het zal later duidelijk worden waarvoor de verschillende methodes precies dienen):
In de algoritmes die je zelf schrijft zal je natuurlijk niet exact deze interfaces gebruiken, maar kan je zelf kiezen hoe je de oplossingen best voorstelt. Maar zelfs zonder deze interfaces te gebruiken is het vaak wel nuttig om eens na te denken over hoe je de operaties uit de interfaces kan uitvoeren met jouw voorstelling.
Skelet-programma: een willekeurige oplossing zoeken
Onderstaande code geeft het skelet om eender welke oplossing voor het probleem te vinden.
We maken gebruik van het worker-wrapper patroon.
Het eigenlijke werk gebeurt in de recursieve findAnySolution-methode.
Die zoekt een oplossing voor het hele probleem, vertrekkend van een gegeven partiële oplossing.
- We gaan eerst na of de huidige partiële oplossing toevallig al een oplossing is voor het hele probleem (hier via de
isComplete()-methode). Dit is het basisgeval voor de recursie. Als dat zo is, moeten we niet verder zoeken, en geven we de oplossing terug. Soms moeten we nog enkele bewerkingen doen om de partiële oplossing om te zetten in het verwachte formaat van de oplossing. Dat wordt hier aangeduid met detoSolution()-methode. - Soms kan je op voorhand al snel zien dat een partiële oplossing nooit tot een oplossing kan leiden (
shouldAbort()). Dan geven we meteen op, en geven wenullterug (geen oplossing). - In alle andere gevallen overlopen we elke mogelijke uitbreiding (keuze) van de partiële oplossing (gegenereerd met
extensions()). We veranderen de partiële oplossing door elk van de uitbreidingen (één voor één) toe te passen (apply()). Dan zoeken we recursief naar een volledige oplossing, vertrekkend van die uitgebreide partiële oplossing. Zodra we zo een (volledige) oplossing bekomen, geven we die terug. Als een uitbreiding niet tot een oplossing leidt, maken we ze ongedaan (undo()) en proberen we de volgende uitbreiding. - Als we alle mogelijke uitbreidingen overlopen hebben, en geen oplossing gevonden hebben, geven we op.
We geven
nullterug.
Vergelijk
Vergelijk deze skelet-code met de code voor het token segmentatie voorbeeld. Herken je de verschillende onderdelen?
(Onze code voor token segmentatie bevat geen code die overeenkomt met shouldAbort.)
Alle oplossingen zoeken
Een variant van het zoeken van één oplossing is het zoeken van alle oplossingen. Om dat te doen, doen we in essentie hetzelfde als bij het zoeken van één oplossing. Nadat we een oplossing gevonden hebben, stoppen we echter niet: we houden de gevonden oplossing bij en gaan (met backtracking) verder op zoek naar eventuele andere oplossingen.
Voorbeeld: token segmentatie
Stel: we willen niet één, maar alle mogelijke segmentaties zoeken. We kunnen vertrekken van de versie om één oplossing te zoeken, maar moeten dan enkele wijzigingen doorvoeren.
Een eerste duidelijke wijziging is het terugkeertype. In plaats van één lijst van tokens, moeten we nu meerdere lijsten van tokens kunnen teruggeven.
We kiezen daarom voor List<List<String>> als terugkeertype.
Een tweede wijziging komt voort vanuit het volgende inzicht.
Waar we bij het zoeken van 1 oplossing meteen konden stoppen eens we een oplossing gevonden hadden, zullen we bij het zoeken naar alle oplossingen verder moeten backtracken nadat we een oplossing tegengekomen zijn.
Dat betekent dat, op het moment dat we een oplossing vinden, we die ergens willen ‘wegschrijven’.
We voegen daarom een extra parameter toe, een lijst solutionsSoFar, die alle oplossingen voorstelt die we eerder al gevonden hebben.
Telkens we een nieuwe oplossing tegenkomen, voegen we die toe aan solutionsSoFar.
Nadat we (via backtracking) alle keuzes doorlopen hebben, bevat solutionsSoFar dan ook alle gevonden oplossingen.
Een derde wijziging is dat we geen null meer teruggeven als we geen oplossing vinden; als er geen oplossingen zijn voor het probleem, vertaalt zich dat in een lege lijst van oplossingen.
In code:
Belangrijk om op te merken is dat we de lijst tokensUsedSoFar kopiëren wanneer we die toevoegen aan de lijst solutionsSoFar.
Dat is noodzakelijk: de tokensUsedSoFar-lijst is immers deel van de partiële oplossing, en die lijst zal later nog aangepast (bijvoorbeeld met .removeLast()) wanneer we verder naar oplossingen zoeken.
In het vorige voorbeeld was dit niet essentieel; zodra we een oplossing vonden, gaven we de gevonden lijst meteen terug en stopten we met zoeken.
In de uitvoeringsboom voor het zoeken van alle oplossingen zien we dat alle mogelijkheden overlopen en teruggegeven worden.
Alle groene knopen zijn oplossingen, en zullen (van links naar rechts) aan de lijst solutionsSoFar toegevoegd worden.
graph TB start["[], catsanddogs"] start -->|ca| ca ca["[ca], tsanddogs"] class ca fail start -->|cat| cat cat["[cat], sanddogs"] cat -->|s| cat_s cat_s["[cat, s], anddogs"] cat_s -->|an| cat_s_an cat_s_an["[cat, s, an], ddogs"] class cat_s_an fail cat_s -->|and| cat_s_and cat_s_and["[cat, s, and], dogs"] cat_s_and -->|dog| cat_s_and_dog cat_s_and_dog["[cat, s, and, dog], s"] cat_s_and_dog -->|s| cat_s_and_dog_s cat_s_and_dog_s["[cat, s, and, dog, s], "] class cat_s_and_dog_s success cat_s_and -->|dogs| cat_s_and_dogs cat_s_and_dogs["[cat, s, and, dogs], "] class cat_s_and_dogs success cat -->|sand| cat_sand cat_sand["[cat, sand], dogs"] cat_sand -->|dog| cat_sand_dog cat_sand_dog["[cat, sand, dog], s"] cat_sand_dog -->|s| cat_sand_dog_s cat_sand_dog_s["[cat, sand, dog, s], "] class cat_sand_dog_s success cat_sand -->|dogs| cat_sand_dogs cat_sand_dogs["[cat, sand, dogs], "] class cat_sand_dogs success classDef success fill:#2c2,stroke:#393,stroke-width:3,color:white; classDef fail fill:#c22,stroke:#933,stroke-width:3,color:white;
Dit duurt uiteraard een stuk langer dan enkel de eerste oplossing teruggeven. We doorlopen immers steeds alle mogelijkheden.
Skelet-programma: alle oplossingen zoeken
We geven opnieuw een skelet-programma, dit keer om alle oplossingen voor het probleem te vinden.
Het eigenlijke werk gebeurt in de recursieve findAllSolutions-methode.
Die doet grotendeels hetzelfde als de findAnySolution-methode uit het skelet-programma voor één oplossing.
Het verschil is dat er nu een extra parameter is, namelijk een collectie van alle tot dan toe gevonden (volledige) oplossingen, solutionsSoFar.
Elke keer een nieuwe oplossing gevonden wordt, voegen we die toe aan solutionsSoFar.
De extra parameter wordt geïnitialiseerd in solve met een lege lijst.
Vergelijk
Vergelijk deze skelet-code opnieuw met de code voor het token segmentatie voorbeeld. Herken je de verschillende onderdelen?
Een optimale oplossing zoeken
De laatste variant die we beschouwen is het zoeken van een optimale oplossing voor een probleem. Je zou dat kunnen doen door eerst alle oplossingen te zoeken, en dan in die lijst van oplossingen de meest optimale oplossing te zoeken. Het bijhouden van alle oplossingen kan in sommige gevallen echter leiden tot een te hoog geheugengebruik. In plaats van alle oplossingen bij te houden, is het daarom beter om enkel de (tot dantoe) beste oplossing te bewaren.
Het zoeken van een optimale oplossing duurt dus meestal even lang als het zoeken van alle oplossingen, maar niet altijd. Soms is het zinloos om nog naar oplossingen te blijven zoeken als die sowieso nooit beter kunnen zijn dan een reeds eerder gevonden oplossing. Je kan dus meteen stoppen met zoeken wanneer je weet dat de huidige partiële oplossing nooit meer tot een betere finale oplossing kan leiden dan de tot dan toe beste oplossing. Dat kan een hoop werk besparen, en de tijd gevoelig inkorten.
Voorbeeld: token segmentatie
De optimale oplossing wordt gedefinieerd als de oplossing die de string splitst in het minst aantal tokens.
De wijzigingen ten opzichte van het algoritme om alle oplossingen te zoeken zijn devolgende:
- Ten eerste hoeven we geen lijst van oplossingen meer bij te houden, maar enkel de tot dan toe beste oplossing.
Dat doen we in een variabele
bestSoFar. Die variabele isnullwanneer er nog geen oplossing gevonden werd (bijvoorbeeld bij de start van de zoektocht). - Ten tweede moeten we, wanneer we een oplossing gevonden hebben, nagaan of die beter is dan de vorige beste oplossing (als die er is). Aangezien we zoeken naar de splitsing met het minst aantal tokens, vergelijken we op basis van de lengte van de oplossing. We geven de kortste van de twee terug.
- Tenslotte kijken we of we de zoektocht voortijdig kunnen staken. Wanneer de huidige splitsing al meer tokens bevat dan de beste splitsing die we op dat moment kennen, heeft het geen zin om nog verder te zoeken. Er kunnen immers enkel nog extra tokens bijkomen, waardoor de oplossing enkel langer kan worden, nooit korter.
Zoek deze wijzigingen in onderstaande code:
Merk op dat we na de recursieve oproep de variabele bestSoFar aanpassen met het resultaat van die oproep, voor het geval de recursieve oproep een betere oplossing opgeleverd heeft.
De uitvoeringsboom ziet er als volgt uit. De gele knopen zijn oplossingen die op een bepaald moment de beste oplossing waren, maar later vervangen zijn door een nog betere oplossing.
graph TB start["[], catsanddogs"] start -->|ca| ca ca["[ca], tsanddogs"] class ca fail start -->|cat| cat cat["[cat], sanddogs"] cat -->|s| cat_s cat_s["[cat, s], anddogs"] cat_s -->|an| cat_s_an cat_s_an["[cat, s, an], ddogs"] class cat_s_an fail cat_s -->|and| cat_s_and cat_s_and["[cat, s, and], dogs"] cat_s_and -->|dog| cat_s_and_dog cat_s_and_dog["[cat, s, and, dog], s"] cat_s_and_dog -->|s| cat_s_and_dog_s cat_s_and_dog_s["[cat, s, and, dog, s], "] class cat_s_and_dog_s bestsofar cat_s_and -->|dogs| cat_s_and_dogs cat_s_and_dogs["[cat, s, and, dogs], "] class cat_s_and_dogs bestsofar cat -->|sand| cat_sand cat_sand["[cat, sand], dogs"] cat_sand -->|dog| cat_sand_dog cat_sand_dog["[cat, sand, dog], s"] cat_sand_dog -->|s| cat_sand_dog_s cat_sand_dog_s["[cat, sand, dog, s], "] cat_sand -->|dogs| cat_sand_dogs cat_sand_dogs["[cat, sand, dogs], "] class cat_sand_dogs success classDef success fill:#2c2,stroke:#393,stroke-width:3,color:white; classDef bestsofar fill:#cc2,stroke:#993,stroke-width:3,color:black; classDef fail fill:#c22,stroke:#933,stroke-width:3,color:white;
Skelet-programma: optimale oplossing
Ook het zoeken naar een optimale oplossing via backtracking heeft vaak dezelfde vorm. We bespreken daarom een derde skelet-programma.
Het eigenlijke werk gebeurt opnieuw in de recursieve findOptimalSolution-methode.
Die doet grotendeels hetzelfde als bij het programma om één of alle oplossingen te zoeken.
Het speciale hier is een extra parameter, namelijk de beste tot dan toe gevonden (volledige) oplossing bestSoFar.
Elke keer een nieuwe oplossing gevonden wordt, vergelijken we die met de beste tot dan toe (via isBetterThan), en geven de betere van de twee terug.
De extra parameter wordt geïnitialiseerd in solve met null: er is nog geen oplossing om mee te vergelijken.
Merk op dat we dus niet eerst alle oplossingen zoeken en bijhouden om daarna de beste te selecteren; we houden enkel de beste oplossing tot dan toe bij en vergelijken daarmee.
Daarenboven voegen we nog een optimalisatie toe: als we op een bepaald moment merken dat de huidige partiële oplossing nooit meer kan uitgroeien tot een oplossing die beter is dan de beste reeds gekende oplossing, dan stoppen we met zoeken op basis van die partiële oplossing.
Bijvoorbeeld, wanneer we een kortste pad zoeken in een doolhof en het huidige pad (waarmee we nog niet uit het doolhof zijn) is al langer dan het tot dan toe beste pad (dat wel reeds heel het doolhof oploste), dan hoeven we niet meer verder te zoeken: extra stappen toevoegen zal immers nooit kunnen leiden tot een korter pad.
We modelleren dit met de canImproveUpon-methode.
Vergelijk
Vergelijk deze skelet-code opnieuw met de code voor het token segmentatie voorbeeld. Herken je de verschillende onderdelen?
Efficiëntie van backtracking
Backtracking is vaak niet heel efficiënt, zeker niet als je alle oplossingen of een optimale oplossing zoekt. Bijvoorbeeld, als er \( k \) keuzepunten zijn, en je bij elke keuzepunt precies \( m\) mogelijkheden hebt, dan zijn er in totaal \( m^k \) mogelijke paden die je moet proberen. Door snel te herkennen wanneer een partiële oplossing niet zal leiden tot een geschikte oplossing, en de zoekoperatie dan onmiddellijk af te breken, kan je het algoritme soms wel een pak efficiënter maken.
Kopiëren vs. aanpassen en herstellen
In de skelet-code hierboven maakten we steeds gebruik van apply() en undo(): we passen de partiële oplossing aan (door ze uit te breiden), en maken die aanpassing later weer ongedaan.
Dat gaat makkelijk als de aanpassing eenvoudig ongedaan te maken is, bijvoorbeeld een element toevoegen aan een lijst en dat nadien weer verwijderen.
Als het ongedaan maken niet zo eenvoudig is (bijvoorbeeld omdat er na de aanpassing heel wat herberekend wordt), is het vaak eenvoudiger om de volledige toestand eerst te kopiëren en verder te werken met deze kopie. Dat heeft als nadeel een hoger geheugengebruik, maar vereenvoudigt het uitbreiden en herstellen van de partiële oplossing wel aanzienlijk. Je hoeft immers niets ongedaan te maken; aangezien alle aanpassingen op een kopie gebeurd zijn, kan je gewoon teruggrijpen naar de originele toestand. Die is ongewijzigd, aangezien alle aanpassingen op een kopie gebeurden.
Hieronder zie je een voorbeeld hiervan (een variant om één oplossing te zoeken voor het token segmentatie probleem). De commentaarregels geven aan wat er van belang is.
Backtracking: oefeningen
Je vindt de startcode voor deze oefeningen in deze GitHub repository:
Variant op token-segmentatie
In het voorbeeld van token-segmentatie mocht een token meermaals gebruikt worden. Schrijf nu een algoritme dat uitzoekt of een string gesegmenteerd kan worden op een manier waarbij elke token hoogstens één keer gebruikt wordt. Doe dat voor de drie varianten:
- één oplossing
- alle oplossingen
- optimale oplossing, waarbij de optimale oplossing deze keer de segmentatie is met het grootste aantal tokens.
Als er geen oplossing is, geef dan null terug (voor variant 1 en 3) of een lege Set (voor variant 2).
8-queens / n-queens
Dit is de klassieker onder de backtracking-algoritmes. Schrijf een backtracking-algoritme om te zoeken hoe je, op een schaakbord van 8x8 vakjes, 8 koninginnen kan plaatsen zodat ze elkaar niet kunnen slaan.
Voor wie niet thuis is in schaken: een koningin (queen, ‘Q’) kan elke andere koningin slaan die zich in dezelfde rij, kolom, of diagonaal bevindt:
Uitbreiding 1: Doe dit voor een schaakbord van willekeurige grootte n, in plaats van 8.
Uitbreiding 2: Zoek alle oplossingen in plaats van 1 oplossing (voor een bord van willekeurige grootte n, maar probeer met 5x5).
Knight’s tour
Nog een klassieker met een schaakbord. Schrijf een backtracking-algoritme om met een paard, beginnend op positie (0, 0), precies één keer op elk vakje van het bord te komen.
Een paard (knight, ‘N’) beweegt 2 vakjes in een richting, en 1 vakje in de orthogonale richting:
Hint als je oplossing te lang duurt: Begin met een kleiner bord (5x5), en overloop de mogelijke volgende posities van het paard steeds volgens de wijzers van de klok.
Uitbreiding: Zoek alle oplossingen in plaats van 1 oplossing, voor een klein bord (5x5). Begin nog steeds op (0, 0). Zoek ook online op hoeveel oplossingen er bestaan voor een 8x8 bord.
SEND+MORE=MONEY
Schrijf een backtracking-algoritme om een letterpuzzel op te lossen zodanig dat de som klopt.
- Elke letter komt in de hele puzzel overeen met hetzelfde cijfer (0–9).
- Twee verschillende letters staan altijd voor verschillende cijfers.
- De getallen beginnen niet met 0 (geen leading zeros).
Bijvoorbeeld:
of
ONE + TWO = SIXSUN + FUN = SWIMCRACK + HACK = ERRORMATH + MYTH = HARDBASE + BALL = GAMES
Hint: onderstaande hulpfuncties kunnen misschien handig zijn. Ook Integer.parseInt(String s) om een String om te zetten naar een int kan nuttig zijn.
Uitbreiding: Laat toe om meer dan twee termen op te tellen, bijvoorbeeld ONE + TWO + SIX = NINE.
Uitbreiding: Zoek alle oplossingen.
Uurrooster planner
Schrijf een programma om een conflict-vrije uurrooster te maken voor een lijst van vakken. Bij elk vak hoort een verzameling van personen (bv. leerkracht en studenten). We vereenvoudigen het uurrooster tot een verzameling van vaste slots waarop vakken ingepland kunnen worden. Elk slot stellen we voor door een positief getal, beginnend bij 1. Zo kan slot 1 bijvoorbeeld staan voor maandagmorgen om 8u30, slot 2 voor maandagmorgen om 10u30, etc.
Enkele beperkingen waaraan het rooster moet voldoen:
- (compleet) Elk vak moet ingepland worden op precies 1 slot.
- (beperkt) Er moet rekening gehouden worden met een maximaal aantal slots (bv. 10).
- (optimaal) Het uiteindelijke uurrooster moet gebruik maken van zo weinig mogelijk slots, met de voorkeur om lagere slotnummers eerst te gebruiken.
- (conflict-vrij) Een persoon mag nooit voor 2 of meer verschillende vakken in hetzelfde slot ingeroosterd worden.
- (capaciteitsconform) Er mogen nooit meer dan 3 vakken op hetzelfde slot ingepland worden, zodat er steeds voldoende lokalen zijn.
Woorden samentrekken
Maak een methode die de kortste samentrekking zoekt van een gegeven verzameling van woorden.
We spreken van een samentrekking wanneer het einde van een woord overeenkomt met het begin van het woord dat daarop volgt (minstens 1 overlappende letter).
Bijvoorbeeld: banaananas is een samentrekking van ananas en banaan, waar we beginnen met het woord banaan, en de letters an overlappen.
Voor de woorden
"besturend", "declaratiesysteem", "deelgemeente", "gemeentebesturen", "merendeel", "programmeren", "sturende", "urendeclaraties"bekom je als kortste samentrekking"programmerendeelgemeentebesturendeclaratiesysteem".Voor
[samentrekking, trekkingsdata, datavoorziening, voorzieningsfonds, fondsmanager, managersfuncties, functiesysteem, systeemdata]wordt datsamentrekkingsdatavoorzieningsfondsmanagersfunctiesysteemdata.
Soms bestaat er geen samentrekking.
Uitbreiding: Zoek ook de langste samentrekking. Voor het eerste voorbeeld hierboven is dat programmerendeelgemeentebesturendeclaratiesturendeclaratiesysteem. Voor het tweede functiesysteemdatavoorzieningsfondsmanagersfunctiesamentrekkingsdata.
Traveling sales person
Gegeven een lijst van plaatsen met bijhorende (x, y)-coördinaten en een startplaats, zoek de kortste tour (dus met de kleinste totale afgelegde afstand) die terug uitkomt op de startplaats en onderweg elke gegeven plaats exact één keer bezoekt.
Bijvoorbeeld, voor de volgende lijst van locaties (hieronder visueel weergegeven) heeft de kortste tour vertrekkend en eindigend bij A een lengte 3.7485395:
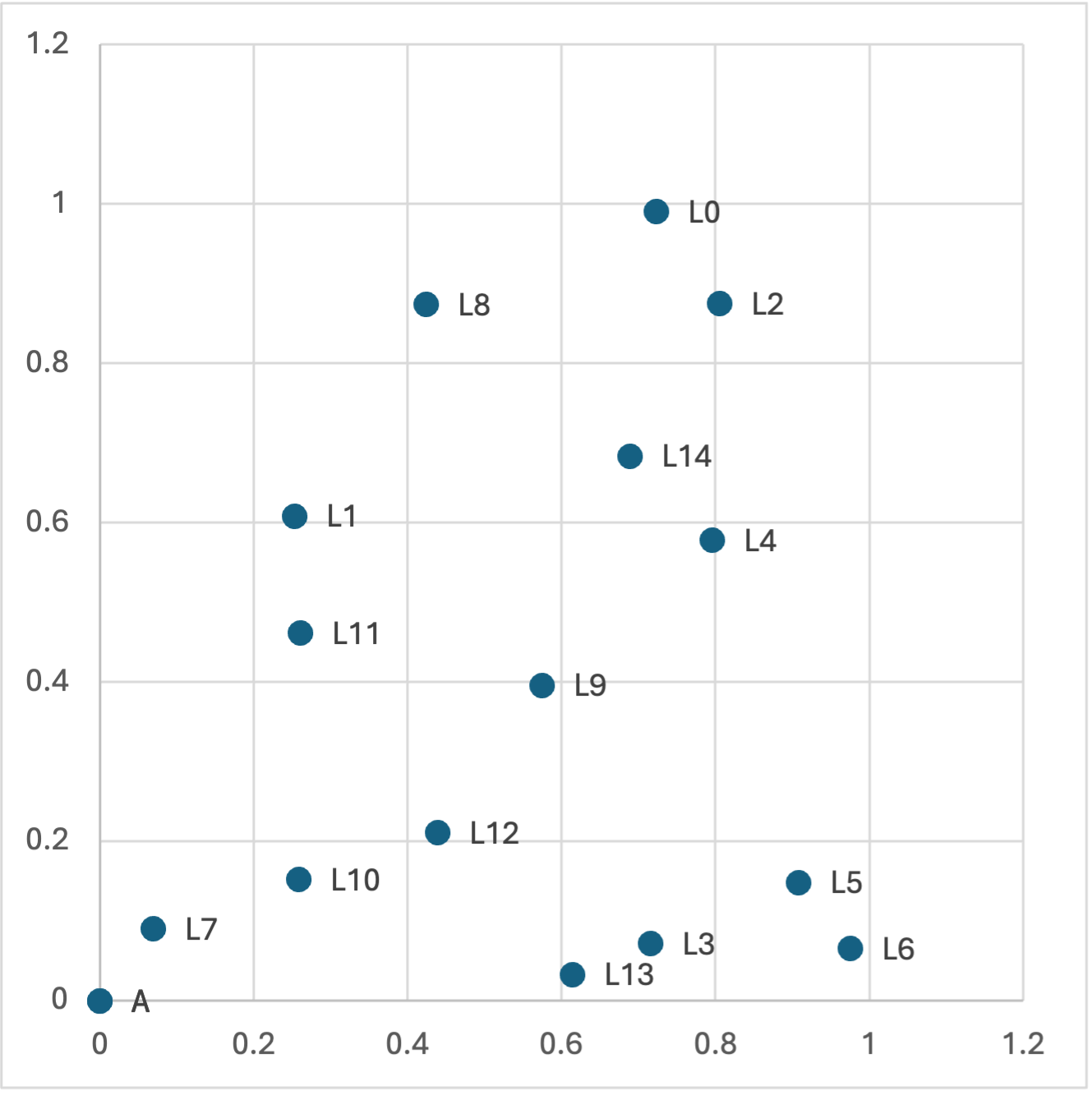
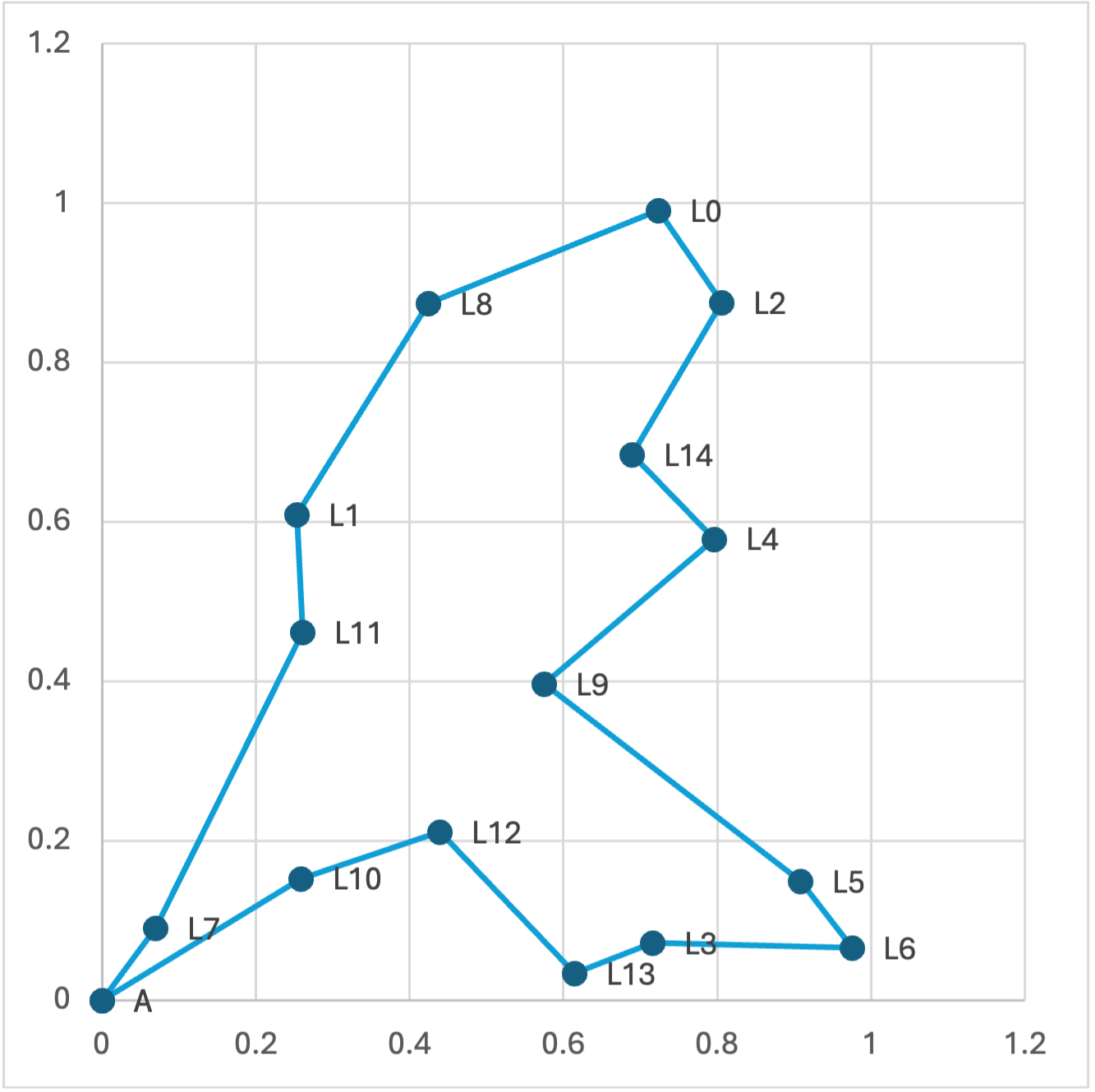
Uitbreiding: Alle volgordes van locaties proberen leidt tot enorm veel mogelijkheden (hoeveel?), en dus een zeer traag algoritme. Bedenk één of meer opties om de zoektocht wat te versnellen (al zal het algoritme traag blijven voor veel coördinaten; hoop niet op een oplossing die voldoende snel werkt voor meer dan een 20-tal locaties).
Doolhof
Schrijf een functie om het kortste pad door een doolhof te vinden van het begin- naar een eindpunt (er kunnen meerdere eindpunten zijn). Een doolhof wordt voorgesteld als een string, met
@voor het startpunt (steeds exact één per doolhof)$voor een eindpunt (minstens één per doolhof).voor een vrije cel (hier kan je doorgaan)Xvoor een cel met een muur (hier kan je niet doorheen gaan)
Bijvoorbeeld:
Je kan je enkel horizontaal of verticaal verplaatsen naar een naburige vrije cel.
Voor het voorbeeld hierboven heeft het kortste pad lengte 24 (inclusief start- en eindpunt):
Handdoeken
Maak de eerste opgave van dag 19 van de Advent of code 2024. Deze gaat (samengevat) als volgt.
Je krijgt een lijst van kleurpatronen voor een handdoek (gekleurde strepen van links naar rechts), bv. r, wr, b, g, bwu wat staat voor red, white-red, black, green, black-white-blue.
Je krijgt ook een lijst van voorgestelde designs (bv. brwrr).
De vraag is om na te gaan hoeveel van de voorgestelde designs je kan maken door handdoeken met de gegeven patronen naast elkaar te leggen.
Het design brwrr kan je bijvoorbeeld maken met de gegeven patronen (r, wr, b, g, bwu) door 4 handdoeken naast elkaar te leggen: b + r + wr + r = brwrr.
Merk op dat je meerdere handdoeken met hetzelfde patroon mag gebruiken (bv. r in dit voorbeeld).
Je mag echter geen handdoeken in stukken knippen (dus je kan bv. bwu niet gebruiken om bw te maken).
Schrijf een functie nbPossibleDesigns om te tellen hoeveel van de voorgestelde designs je kan maken met behulp van handdoeken met de gegeven patronen.
Bijvoorbeeld: voor onderstaande invoer (eerste lijn zijn de patronen, en na een lege lijn volgen de voorgestelde designs):
moet het algoritme 6 teruggeven, omdat:
brwrrgemaakt kan worden met eenbrhanddoek, dan eenwrhanddoek, en tenslotte eenrhanddoek.bggrgemaakt kan worden met eenbhanddoek, tweeghanddoeken, en tenslotte eenrhanddoek.gbbrgemaakt kan worden met eengbhanddoek en dan eenbrhanddoek.rrbgbrgemaakt kan worden met eenr,rb,g, andbr.ubwuis onmogelijk.bwurrggemaakt kan worden met eenbwu,r,r, andg.brgrgemaakt kan worden met eenbr,g, andr.bbrgwbis onmogelijk.
Hint: Je eerste backtracking-algoritme zal waarschijnlijk werken voor kleine problemen, maar heel traag zijn voor het grote probleem in de meegeleverde tests. Je kan het heel wat versnellen door gebruik te maken van een cache (die het resultaat van vorige sub-patronen bijhoudt).
Uitbreiding: maak nu ook een methode countDifferentRealizations die het aantal verschillende manieren zoekt om een design te maken. Bijvoorbeeld, gbbr kan gemaakt worden op 4 verschillende manieren met de patronen van hierboven, namelijk
g,b,b,rg,b,brgb,b,rgb,br
De methode countDifferentRealizations moet dus het getal 4 teruggeven voor het design gbbr en de patronen van hierboven.
Ook hier zal caching nuttig zijn om het algoritme sneller te maken.
Snakefill
Oud-examenvraag
Dit is een oud-examenvraag.
In het spel SnakeFill beweeg je het hoofd van een slang over een bord in een bepaalde richting. Het bord bestaat uit vrije cellen en muren. De slang wordt steeds langer, en beweegt steeds verder in dezelfde richting tot die een obstakel (een muur, de rand van het bord, of een deel van zichzelf) tegenkomt. Pas dan kan je de richting veranderen. Het hoofd van de slang beweegt dus steeds van obstakel tot obstakel.
Het doel van het spel is om alle vakjes van het bord te vullen met de slang. Hieronder zie je een voorbeeld. Het hoofd van de slang begint (fig. A) linksboven op positie (0, 0), beweegt dan naar onder (B), dan naar rechts (C), etc. Helemaal rechts (fig. D) zie je een traject dat het hele bord vult. Dit komt overeen met de bewegingen [DOWN, RIGHT, UP, LEFT, UP, RIGHT, DOWN, RIGHT, UP, LEFT].
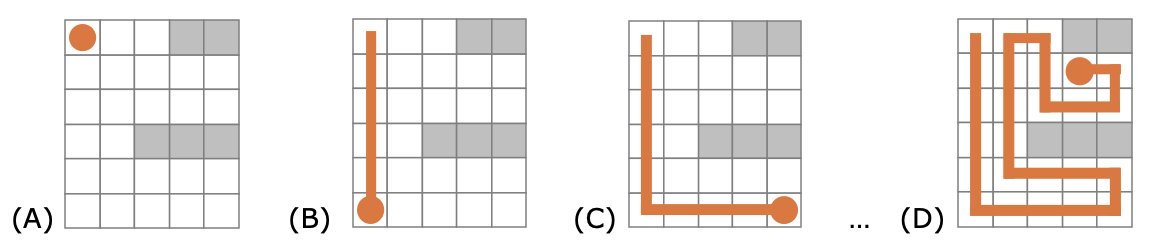
Ontwerp een backtracking-algoritme om, met zo weinig mogelijk bewegingen, het hele bord te vullen. Je geeft de oplossing terug als een lijst van bewegingen (Directions). Indien er geen oplossing is, geef je null terug. Je moet een solve-methode schrijven die opgeroepen wordt zoals getoond in de gegeven main-methode. In de solve-methode mag je gebruik maken van zelfgeschreven hulpmethodes.
Je krijgt alvast de interface van een Board-klasse om het bord van SnakeFill voor te stellen. Je mag ervan uitgaan dat er hiervan een implementatie beschikbaar is die correct werkt; je moet deze dus niet zelf schrijven. Er zijn ook hulpklassen gegeven om posities en richtingen voor te stellen. In principe volstaan de gegeven methodes in deze klassen om het probleem op te lossen. Je mag elk van deze klassen echter verder uitbreiden met extra methodes die je nuttig acht. Schrijf daarvoor de methode-hoofding en een beschrijving van wat de methode moet doen. Je hoeft de methode zelf niet te implementeren.