Hier start het tweede deel van de cursus, waarin we enkele geavanceerdere Java-concepten bekijken.
Deze concepten laten toe om op een moderne, efficiënte manier te programmeren, en vormen de basis om complexere problemen efficiënt op te lossen, bijvoorbeeld door te werken met recursie en backtracking.
We bekijken hier concepten uit Java, maar deze hebben vaak een equivalent in andere talen.
Aan het begin van elk hoofdstuk lijsten we daarom ook telkens kort op welke concepten uit andere programmeertalen hier het dichtst bij aanleunen.
Subsecties van 7. Advanced Java
7.1 Java basics
Als je Java-kennis wat roestig is (of wanneer je meer ervaring hebt in een andere programmeertaal), kan je je Java-kennis even opfrissen aan de hand van deze pagina.
IntelliJ
We maken voor de lessen in dit deel geen gebruik van VSCode, maar schakelen over naar Jetbrains IntelliJ IDEA, een van de vaakst gebruikte professionele Java IDE’s.
De gratis Community Edition volstaat voor dit vak, maar je kan als student ook een gratis licentie voor de Ultimate Edition aanvragen.
Download en installeer IntelliJ op je machine.
In IntelliJ organiseer je je code in projecten.
Elk IntelliJ scherm heeft op elk moment één geopend (actief) project.
Binnen een project heb je één of meer modules.
Een module is een onderdeel van een software-project.
Elke module kan in een verschillende programmeertaal geschreven zijn, en/of met zijn eigen (specifieke) instellingen gecompileerd worden.
Elke module is dus onafhankelijk.
In deel 2 van dit vak zullen we voor elk onderwerp (~elke les) een afzonderlijk project maken, en voor elke oefening een aparte module binnen dat project maken.
Dat zorgt ervoor dat je elke oefening onafhankelijk kan oplossen.
In combinatie met git zullen we één repository per project (en dus per onderwerp) gebruiken.
Je opdracht voor dit deel maak je ook in een apart project (en aparte git repository); zie de instructies bij de opdrachten.
Oefening 1: Hello world
Maak in IntelliJ een leeg project (Empty project) aan (dus geen Java-project!) met volgende instellingen:
Type (links in het scherm): Empty Project
Name: naar keuze (bijvoorbeeld sessie01-basics)
Location: ergens op je Linux/WSL2 installatie (bijvoorbeeld een map \\wsl.localhost\Ubuntu\home\youruser\ses-intellij)
Create git repository: aan
Klik op Create.
IntelliJ opent nu je project. Je kan de projectstructuur tonen en verbergen door links op het map-icontje te drukken.
Maak in de root van het project eerst een nieuw leeg bestand .noai. Dit zet de AI-ondersteuning in dit project uit.
Voeg nu een nieuwe Java-module toe aan het project:
Type (links in het scherm): Java
Name: naar keuze (bijvoorbeeld oef01-helloworld)
Location: zou standaard goed moeten staan (locatie van het project)
Build system: IntelliJ (later zullen we overschakelen naar Gradle)
JDK: een recente versie (25 of hoger)
Add sample code: uit
Klik op Create.
Geen Java 25?
Als je WSL2-installatie geen Java 25 SDK bevat, kan je deze via een terminal installeren met
sudo apt update
sudo apt install openjdk-25-jdk
Je ziet de module nu verschijnen als subfolder van je project.
Maak in de src-folder van deze module een nieuwe klasse HelloWorld, en kopieer volgend programma.
Met deze oefening fris je je geheugen over het gebruik van if en for nog eens op.
Maak een nieuwe Java-module oef02-basis.
Maak in die module een klasse Opteller die een getal n vraagt aan de gebruiker,
vervolgens de som berekent van alle oneven getallen van 1 tot en met n, en tenslotte het resultaat afdrukt.
Bijvoorbeeld:
Geef een getal: 25De som van de oneven getallen van 1 tot en met 25 is 169
Hint: gebruik IO.readln() en IO.println() om te lezen van en schrijven naar de console. Deze methodes zijn nieuw sinds Java 25.
Je kan een String omzetten naar een getal via Integer.parseInt.
Oplossing
classOpteller{publicstaticvoidmain(String[]args){intn=Integer.parseInt(IO.readln("Geef een getal: "));longsom=0;for(inti=1;i<=n;i++){if(i%2==1){som+=i;}}IO.println("De som van de oneven getallen van 1 tot en met "+n+" is "+som);}}
Oefening 3: Klasse en ArrayList
Deze oefening dient om je kennis van klassen en het gebruik van een ArrayList nog eens op te frissen.
Maak een nieuwe Java-module oef03-arraylist.
Maak in die module een nieuwe klasse Persoon met 2 attributen (velden):
een naam (String)
een leeftijd (int)
Maak ook een klasse Programma met een main-methode die aan de gebruiker steeds achtereenvolgens een naam en leeftijd vraagt, telkens een object van klasse Persoon aanmaakt, en deze Persoon-objecten bijhoudt in een ArrayList.
De invoer stopt wanneer de ingegeven naam leeg is.
Vervolgens moeten de gegevens van alle ingegeven personen uitgeprint worden (in de volgorde dat ze ingegeven werden).
Bijvoorbeeld:
Geef de naam van de volgende persoon: Jan
Geef de leeftijd van Jan: 25Geef de naam van de volgende persoon: Marie
Geef de leeftijd van Marie: 28Geef de naam van de volgende persoon:
De ingegeven personen zijn:
- Jan (25 jaar)- Marie (28 jaar)
// Programma.javaimportjava.util.ArrayList;publicclassProgramma{publicstaticvoidmain(){ArrayList<Persoon>personen=newArrayList<>();Stringnaam=IO.readln("Geef de naam van de volgende persoon: ");while(!naam.isBlank()){intleeftijd=Integer.parseInt(IO.readln("Geef de leeftijd van "+naam+": "));Persoonp=newPersoon(naam,leeftijd);personen.add(p);IO.println();naam=IO.readln("Geef de naam van de volgende persoon: ");}IO.println("De ingegeven personen zijn:");for(varp:personen){IO.println("- "+p);}}}
7.2 Java Collecties
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java collections zijn
de Standard Template Library (STL) in C++
enkele ingebouwde types, alsook de collections module in Python
de collecties in System.Collections.Generic in C#
Het komt vaak voor dat we meerdere objecten willen kunnen bijhouden.
Totnogtoe heb je hiervoor in de cursus Software-ontwerp in Java enkel gewerkt met een Java array [] (vaste grootte), en met ArrayList<T> (kan groter of kleiner worden).
In dit hoofdstuk kijken we in meer detail naar ArrayList, en behandelen we ook verschillende andere collectie-types in Java.
De meeste van die types vind je ook (soms onder een andere naam) terug in andere programmeertalen.
Je kan je afvragen waarom we andere collectie-types nodig hebben; uiteindelijk kan je (met genoeg werk) alles toch implementeren met een ArrayList? Dat klopt, maar de collectie-types verschillen in welke operaties snel zijn, en welke meer tijd vragen. Om dat preciezer uit te drukken, kan je gebruik maken van de notie van tijdscomplexiteit. We gaan daar in deze cursus niet verder op in; dat komt uitgebreid aan bod in de cursus Algoritmen en datastructuren.
implementaties van die interfaces (bv. ArrayList, LinkedList, Vector, Stack, ArrayDeque, PriorityQueue, HashSet, LinkedHashSet, TreeSet, en TreeMap)
algoritmes voor veel voorkomende operaties (bv. shuffle, sort, swap, reverse, …)
Je vindt een overzicht van de hele API op deze pagina.
Weetje: andere collectie-types
Behalve de Java Collections API zijn er ook externe bibliotheken met collectie-implementaties die je (bijvoorbeeld via Gradle) kan gebruiken in je projecten.
De twee meest gekende voorbeelden zijn
Collecties maken veelvuldig gebruik van zogenaamde generische (type-)parameters.
Dat zijn parameters die bij de naam van een klasse horen.
Ze staan steeds tussen < en >, bijvoorbeeld de <String> die je vroeger al tegenkwam bij ArrayList<String>.
We zullen generische parameters later in veel meer detail behandelen.
Voorlopig volstaat het om Collectie<E> te lezen als “Collectie van E’s”.
Om (straks bij de oefeningen) een zelfgedefinieerde klasse een generische parameter te geven, voeg je <E> toe achter de klasse-naam (je mag gerust ook andere namen gebruiken dan E, bijvoorbeeld T, Element, …).
Bijvoorbeeld:
classMijnCollectie<E>{voidvoegToe(Eelement){...}}
Binnen in de klasse kan je dan E gebruiken als type voor methode-parameters, lokale variabelen, en velden.
In het voorbeeld hiervoven heeft de parameter element van methode voegToe het type E.
Wat E precies is moet later bepaald worden, bij het gebruik van de klasse (= het aanmaken van een object).
Op dat moment moet je een concrete waarde opgeven voor E.
Bijvoorbeeld, als je een object van MijnCollectie wil maken waaraan je enkel Persoon-objecten kan toevoegen, dan kan dat als volgt:
Je kan het type MijnCollectie<Persoon> dus zien als de klasse MijnCollectie<E> waarin alle voorkomens van E vervangen werden door Persoon.
Iterable en Iterator
De interfaces Iterable<E> en Iterator<E> maken eigenlijk geen deel uit van de Java Collections API, maar zijn er wel sterk aan verwant.
Een Iterable<E> is een object dat meerdere objecten van type E één voor één kan teruggeven.
Er moet slechts één methode geïmplementeerd worden, namelijk iterator(), die een Iterator<E>-object teruggeeft (zie hieronder).
Elke klasse die Iterable implementeert, kan automatisch gebruikt worden in een zogenaamd ’enhanced for-statement’:
Iterable<E>iterable=...for(Eelement:iterable){...// code die element gebruikt}
Een Iterator<E> is een object dat gebruikt kan worden om (éénmalig) door alle elementen van een collectie te lopen.
Een Iterator<E> heeft twee methodes:
boolean hasNext(): geeft aan of er nog objecten zijn om terug te geven
E next(): geeft het volgende object (van type E) terug (als er nog objecten zijn).
Elke keer je next() oproept krijg je dus een ander object, tot hasNext() false teruggeeft. Vanaf dan krijg je een exception (NoSuchElementException).
Een Iterator moet dus een interne toestand bijhouden om te bepalen welke objecten al teruggegeven zijn en welke nog niet.
Eens alle elementen teruggegeven zijn, en hasNext() dus false teruggeeft, is de iterator ‘opgebruikt’.
Als je daarna nog eens over de elementen wil itereren, moet je een nieuwe iterator aanmaken.
Bij een enhanced for-statement wordt achter de schermen een iterator gebruikt.
Het enhanced for-statement van hierboven is equivalent aan volgende code:
Iterable<E>iterable=...Iterator<E>iterator=iterable.iterator();while(iterator.hasNext()){Eelement=iterator.next();...// code die element gebruikt}
Alle collectie-types die een verzameling elementen voorstellen (dus alles behalve Map), implementeren de Iterable interface.
Dat betekent dus dat je elk van die collecties in een enhanced for-lus kan gebruiken.
Je kan daarenboven ook zelf een nieuwe klasse maken die deze interface implementeert, en die vervolgens gebruikt kan worden in een enhanced for-loop.
Dat doen we later in de oefeningen.
Zoals je hierboven zag, kan een Iterable dus enkel elementen opsommen.
De basisinterface Collection erft hiervan over maar is uitgebreider: het stelt een eindige groep objecten voor.
Er zit nog steeds bitter weinig structuur in een Collection:
de volgorde van de elementen in een Collection ligt niet vast
er kunnen wel of geen dubbels in een Collection zitten
De belangrijkste operaties die je op een Collection-object kan uitvoeren zijn (volledige documentatie)
iterator(), geërfd van Iterable
size(): de grootte opvragen
isEmpty(): nagaan of de collectie leeg is
contains en containsAll: nakijken of een of meerdere elementen in de collectie zitten
add en addAll: een of meerdere elementen toevoegen
remove en removeAll: een of meerdere elementen verwijderen
clear: de collectie volledig leegmaken
toArray: alle elementen uit de collectie in een array plaatsen
Alle operaties die een collectie aanpassen (bv. add, addAll, remove, clear, …) zijn optioneel.
Dat betekent dat sommige implementaties een UnsupportedOperationException kunnen gooien als je die methode oproept.
Niet elke collectie hoeft dus alle operaties te ondersteunen.
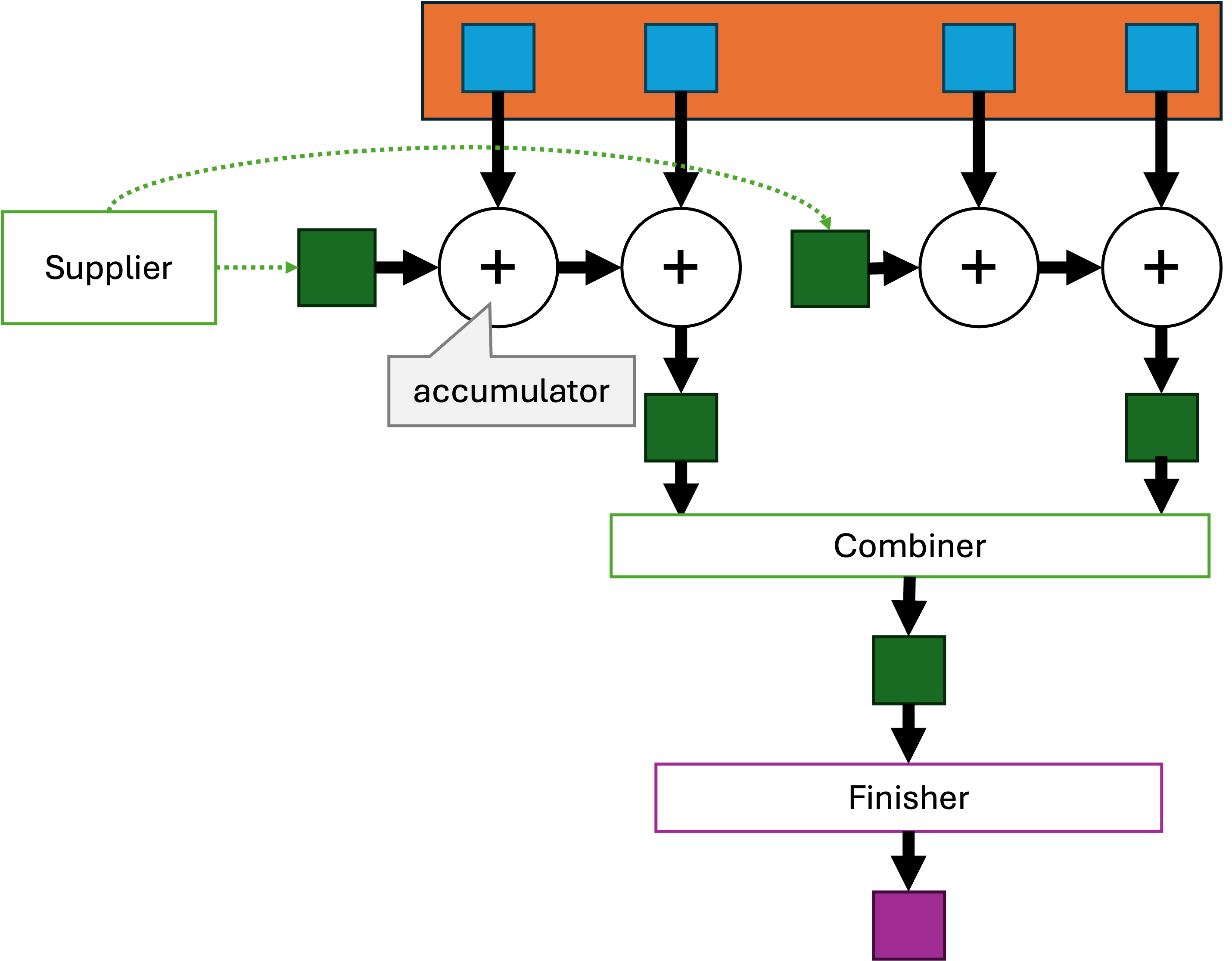
List
classDiagram
Iterable <|-- Collection
Collection <|-- List
class Iterable["Iterable#lt;E>"] { <<interface>> }
class Collection["Collection#lt;E>"] { <<interface>> }
class List["List#lt;E>"] {
<<interface>>
get(int index)
add(int index, E element)
set(int index, E element)
remove(int index)
indexOf(E element)
lastIndexOf(E element)
reversed()
subList(int from, int to)
}
style List fill:#cdf,stroke:#99f
Een lijst is een collectie waar alle elementen een vaste plaats hebben.
De elementen in een lijst zijn dus geordend: je kan spreken over het eerste element, het tweede element, en het laatste element.
Merk op dat een lijst niet noodzakelijk gesorteerd is: het eerste element hoeft niet het kleinste (of grootste) element te zijn.
Een lijst wordt voorgesteld door de List interface, die Collection uitbreidt met operaties die kunnen werken met de plaats (index) van een object.
De ArrayList die je al kent, is een klasse die de List-interface implementeert.
get(int index): het element op een specifieke plaats opvragen
add(int index, E element): een element invoegen op een specifieke plaats (en de latere elementen opschuiven)
set(int index, E element): het element op een specifieke plaats wijzigen
remove(int index): het element op de gegeven index verwijderen (en de latere elementen opschuiven)
indexOf(E element) en lastIndexOf(E): de eerste en laatste index zoeken waarop het gegeven element voorkomt
reversed(): geeft een lijst terug in de omgekeerde volgorde
subList(int from, int to): geeft een lijst terug die een deel (slice) van de oorspronkelijke lijst voorstelt
Merk op dat de laatste twee methodes (reversed en subList) een zogenaamde view teruggeven op de oorspronkelijke lijst.
Het is dus geen nieuwe lijst, maar gewoon een andere manier om naar de oorspronkelijke lijst te kijken.
Bijvoorbeeld, in onderstaande code:
in de lijst rev het laatste element veranderen in X ook de oorspronkelijke lijst aanpast
de sublist cde leegmaken deze elementen ook verwijdert uit de oorspronkelijke lijst, alsook uit de omgekeerde view op de lijst (rev)
De reden is dat zowel rev als cde enkel verwijzen naar de onderliggende lijst alphabet, en zelf geen elementen bevatten:
block-beta
block:brev
space:1
rev
end
space
block:alphabet
columns 6
A B C D E F
end
space
block:bcde
cde
space:1
end
rev --> alphabet
cde --> alphabet
classDef node fill:#faa,stroke:#f00
classDef ptr fill:#ddd,stroke:black
classDef empty fill:none,stroke:none
classDef val fill:#ffc,stroke:#f90
class brev,bcde empty
class alphabet node
class rev,cde ptr
class A,B,C,D,E,F val
Indien je wat Python kent: subList is dus een manier om functionaliteit gelijkaardig aan slices te verkrijgen in Java. Maar, in tegenstelling tot slices in Python, maakt subList geen kopie, en is dus efficiënter!
ArrayList
ArrayList is de eerste concrete implementatie van de List-interface die we bekijken.
In een ArrayList wordt intern een array gebruikt om de elementen bij te houden.
Aangezien arrays in Java een vaste grootte hebben, kan je niet zomaar elementen toevoegen eens die onderliggende array vol is.
Daarom wordt er een onderscheid gemaakt tussen de de grootte van de lijst (het aantal elementen dat er effectief inzit), en de capaciteit van de lijst (de lengte van de onderliggende array).
Zolang de grootte kleiner is dan de capaciteit, gebeurt er niets speciaals. Op het moment dat de volledige capaciteit benut is, en er nog een element toegevoegd wordt, wordt een nieuwe (grotere) array gemaakt (bijvoorbeeld tweemaal zo lang) en worden alle huidige elementen daarin gekopieerd.
Bijvoorbeeld, voor een lijst met capaciteit 3 en twee elementen:
block-beta
columns 1
block:before
columns 12
e0["A"] e1["B"] e2[" "] space:9
end
space
block:after1
columns 12
ee0["A"] ee1["B"] ee2["C"] space:9
end
space
block:after2
columns 12
eee0["A"] eee1["B"] eee2["C"] eee3["D"] eee4[" "] eee5[" "] space:6
end
space
block:after3
columns 12
eeee0["A"] eeee1["B"] eeee2["C"] eeee3["D"] eeee4["E"] eeee5["F"] eeee6["G"] eeee7[" "] eeee8[" "] eeee9[" "] eeee10[" "] eeee11[" "]
end
before --"C toevoegen (behoud capaciteit)"--> after1
after1 --"D toevoegen (verdubbel capaciteit)"--> after2
after2 --"E, F, G toevoegen (verdubbel capaciteit)"--> after3
classDef ok fill:#6c6,stroke:#393,color:#fff
class e0,e1 ok
class ee0,ee1,ee2 ok
class eee0,eee1,eee2,eee3 ok
class eeee0,eeee1,eeee2,eeee3,eeee4,eeee5,eeee6 ok
Verdieping
Stel dat we ervoor zouden kiezen om, elke keer wanneer we een element toevoegen, de array één extra plaats te geven.
We moeten dan telkens alle vorige elementen kopiëren, en dat wordt al snel erg inefficiënt.
Bijvoorbeeld, stel dat we met een lege array beginnen:
om het eerste element toe te voegen, moeten we niets kopiëren
om het tweede element toe te voegen, moeten we één element kopiëren (het eerste element uit de vorige array van lengte 1)
om het derde element toe te voegen, moeten we twee elementen kopieëren (het eerste en tweede element uit de vorige array van lengte 2)
om het vierde element toe te voegen 3 kopieën, enzovoort.
Eén voor één \(n\) elementen toevoegen aan een initieel lege lijst zou dus in totaal \(0+1+…+(n-1) = (n^2-n)/2\) kopieën vereisen.
Dat is erg veel werk als \(n\) groot wordt.
Om die reden wordt de lengte van de array niet telkens met 1 verhoogd, maar meteen vermenigvuldigd met een constante (meestal 2, zodat de lengte van de array verdubbelt).
Onthoud
Een ArrayList is de juiste keuze wanneer je een lijst nodig hebt (geordende elementen) en verwacht dat je vaak elementen op een specifieke positie wil opvragen of vervangen, en/of de verwachte aanpassingen voornamelijk het achteraan toevoegen en verwijderen zijn.
LinkedList
Een gelinkte lijst (LinkedList) is een andere implementatie van de List interface.
Hier wordt geen array gebruikt, maar wordt de lijst opgebouwd uit knopen (nodes).
Elke knoop bevat
een waarde (value)
een verwijzing (next) naar de volgende knoop
(in een dubbel gelinkte lijst) een verwijzing (prev) naar de vorige knoop.
De LinkedList zelf bevat enkel een verwijzing naar de eerste knoop (first), en voor een dubbel gelinkte lijst ook nog een verwijzing naar de laatste knoop van de lijst (last).
Vaak wordt ook het aantal elementen (size) bijgehouden.
Hieronder zie je een grafische voorstelling van een dubbel gelinkte lijst met 3 knopen:
block-beta
block:bf
columns 1
space
first
space
end
space
block:n0
columns 1
e0["A"]
p0["next"]
pp0["prev"]
end
space
block:n1
columns 1
e1["B"]
p1["next"]
pp1["prev"]
end
space
block:n2
columns 1
e2["C"]
p2["next"]
pp2["prev"]
end
space
block:bl
columns 1
space
last
space
end
first --> n0
last --> n2
p0 --> n1
p1 --> n2
pp1 --> n0
pp2 --> n1
classDef node fill:#faa,stroke:#f00
classDef ptr fill:#ddd,stroke:black
classDef empty fill:none,stroke:none
classDef val fill:#ffc,stroke:#f90
class bf,bl empty
class n0,n1,n2 node
class pp0,p0,pp1,p1,pp2,p2,first,last ptr
class e0,e1,e2 val
Een LinkedList is efficiënter voor sommige operaties dan een ArrayList, maar trager voor andere.
Meer specifiek: we moeten nooit elementen kopiëren of verplaatsen als we een gelinkte lijst aanpassen, enkel referenties verleggen.
Dat is erg efficiënt.
Maar: we moeten wel eerst op de juiste plaats (knoop) geraken in de lijst, en daarvoor moeten we eerst wel een aantal referenties volgen (beginnend bij first of last), wat voor een lange lijst inefficiënt is.
Onthoud
Een LinkedList is de juiste keuze wanneer je een lijst nodig hebt (geordende elementen) en verwacht dat je veel aanpassingen aan je lijst zal doen, en die aanpassingen vooral voor- of achteraan zullen plaatsvinden.
Lijsten aanmaken
Je kan natuurlijk steeds een lijst aanmaken door een nieuwe, lege lijst te maken en daaraan je elementen toe te voegen:
Hierbij moet je wel opletten dat de lijst die je zo maakt immutable (onveranderbaar) is. Je kan aan de lijst die je zo gemaakt hebt dus later geen wijzigingen meer aanbrengen via add, remove, etc.:
De List-interface zelf bevat al enkele nuttige operaties op lijsten.
In de Collections-klasse (niet hetzelfde als de Collection-interface!) vind je nog een heleboel extra operaties die je kan uitvoeren op lijsten (of soms op collecties), bijvoorbeeld:
disjoint om na te gaan of twee collecties geen overlappende elementen hebben
sort om een lijst te sorteren
shuffle om een lijst willekeurig te permuteren
swap om twee elementen van plaats te verwisselen
frequency om te tellen hoe vaak een element voorkomt in een lijst
min en max om het grootste element in een collectie te zoeken
indexOfSubList om te zoeken of en waar een lijst voorkomt in een langere lijst
nCopies om een lijst te maken die bestaat uit een aantal keer hetzelfde element
fill om alle elementen in een lijst te vervangen door eenzelfde element
rotate om de elementen in een lijst cyclisch te roteren
Unmodifiable list
Soms wil je als resultaat van een methode een gewone (wijzigbare) lijst teruggeven maar er zeker van zijn dat de ontvanger die lijst niet kan aanpassen.
Bijvoorbeeld:
We willen niet dat een gebruiker van de klasse die lijst zomaar kan aanpassen — dat moet via de borrow-methode gaan.
We kunnen natuurlijk een nieuwe lijst teruggeven met een kopie van de elementen:
Er wordt dan geen nieuwe lijst gemaakt, maar wel een ‘view’ op de originele lijst (net zoals we eerder gezien hebben bij reversed en subList).
Het verschil is dat deze view nu geen wijzigingen toelaat; alle operaties die de lijst wijzigen, gooien een UnsupportedOperationException.
Doordenker
Is er, vanuit het standpunt van de code die getBorrowedBooks() oproept, een verschil tussen een kopie en een unmodifiableList()?
Denk bijvoorbeeld aan de situatie waar de lijst borrowedBooks later aangepast wordt (via borrow)?
Antwoord
Ja, er is wel degelijk een verschil.
Bij een kopie zal een nieuw toegevoegd boek niet verschijnen in die kopie.
De lijst gemaakt via unmodifiableList is echter een view: latere aanpassingen zullen ook onmiddellijk zichtbaar zijn.
Set
classDiagram
Iterable <|-- Collection
Collection <|-- List
Collection <|-- Queue
Collection <|-- Set
class Iterable["Iterable#lt;E>"] { <<interface>> }
class Collection["Collection#lt;E>"] { <<interface>> }
class List["List#lt;E>"] { <<interface>> }
class Queue["Queue#lt;E>"] { <<interface>> }
class Set["Set#lt;E>"] {
<<interface>>
}
style Set fill:#cdf,stroke:#99f
Alle collecties die we totnogtoe gezien hebben, kunnen dubbels bevatten.
Bij een Set is dat niet het geval. Het is een abstractie voor een (eindige) wiskundige verzameling: elk element komt hoogstens één keer voor.
In een wiskundige verzameling is ook de volgorde van de elementen niet van belang.
De Set interface legt geen volgorde van elementen vast, maar er bestaan sub-interfaces van Set (bijvoorbeeld SequencedSet en SortedSet) die wél toelaten dat de elementen een bepaalde volgorde hebben.
De Set interface voegt in feite geen nieuwe operaties toe aan de Collection-interface. Je kan elementen toevoegen, verwijderen, en nagaan of een element in de verzameling zit.
Het is leerrijk om even stil te staan bij hoe een set efficiënt geïmplementeerd kan worden.
Immers, verzekeren dat er geen duplicaten inzitten vereist dat we gaan zoeken tussen de huidige elementen, en dat kan makkelijk traag worden als er veel elementen zijn.
We bekijken één implementatie van een manier om dat efficiënt te doen, namelijk een HashSet.
HashSet
Een HashSet kan gebruikt worden om willekeurige objecten in een set bij te houden.
De objecten worden bijgehouden in een hashtable (in essentie een gewone array).
Om te voorkomen dat we een reeds bestaand element een tweede keer toevoegen, moeten we echter snel kunnen nagaan of het toe te voegen element al in de set voorkomt.
Een HashSet kan efficiënt nagaan of een element bestaat, alsook efficiënt een element toevoegen en verwijderen.
De sleutel om dat te doen is de hashCode() methode die ieder object in Java heeft.
Die methode moet, voor elk object, een hashCode (een int) teruggeven, zodanig dat als twee objecten gelijk zijn volgens hun equals-methode, ook hun hashcodes gelijk zijn.
Gewoonlijk zal je, als je equals zelf implementeert, ook hashCode moeten implementeren en omgekeerd.
De hashCode moet niet uniek zijn: meerdere objecten mogen dezelfde hashCode hebben, ook al zijn ze niet gelijk (al kan dat tot een tragere werking van een HashSet leiden; zie verder). Hoe uniformer de hashCode verdeeld is over alle objecten, hoe beter.
Opmerking
Java records, die we later zullen behandelen, voorzien standaard een zinvolle equals- en hashCode-methode die afhangt van de attributen van het record.
Bij records hoef je dus normaliter niet zelf een hashCode-methode te voorzien.
De hashCode wordt gebruikt om een index te bepalen in de onderliggende hashtable (array).
De plaats in die hashtable is een bucket.
Het element wordt opgeslagen in de bucket op die index.
Als we later willen nagaan of een element al voorkomt in de hashtable, berekenen we opnieuw de index aan de hand van de hashCode en kijken we of het element zich effectief in de overeenkomstige bucket bevindt.
Idealiter geeft elk object dus een unieke hashcode, en zorgen die voor perfecte spreiding van alle objecten in de hashtable.
Er zijn echter twee problemen in de praktijk:
twee verschillende objecten kunnen dezelfde hashCode hebben. Dat is een collision. Hiermee moeten we kunnen omgaan.
als er teveel elementen toegevoegd worden, moet de onderliggende hashtable dynamisch kunnen uitbreiden. Dat maakt dat elementen plots op een andere plaats (index) terecht kunnen komen als voorheen. Uitbreiden vraagt vaak rehashing, oftwel het opnieuw berekenen van de index (nu in een grotere hashtable) aan de hand van de hashcodes. De load factor van de hash table geeft aan hoe vol de hashtable mag zijn voor ze uitgebreid wordt. Bijvoorbeeld, een load factor van 0.75 betekent dat het aantal elementen in de hashtable tot 75% van het aantal buckets mag gaan.
Beide problemen zijn al goed onderzocht in de computerwetenschappen, en zullen in het vak Algoritmen en datastructuren uitgebreider aan bod komen.
SortedSet en TreeSet
Naast Set bestaat ook de interface SortedSet.
In een SortedSet worden de elementen steeds in gesorteerde volgorde opgeslagen en teruggegeven.
In tegenstelling tot een Set, kan een SortedSet geen willekeurige objecten bevatten.
De objecten moeten namelijk gesorteerd kunnen worden.
Met andere woorden, we moeten kunnen bepalen welk van twee objecten het grootste is (net zoals > bij getallen).
Dat kan op twee manieren:
de klasse van het op te slagen element kan zelf de Comparable-interface implementeren, die aangeeft welk van twee elementen het grootst is;
of je kan een Comparator-object meegeven bij het maken van een SortedSet, waarop beroep gedaan wordt om de volgorde van twee elementen te bepalen.
De TreeSet klasse is een efficiënte implementatie van SortedSet die gebruik maakt van een gebalanceerde boomstructuur (een red-black tree — de werking daarvan is hier niet van belang).
Voorbeeld
Een voorbeeld van het gebruik van een HashSet:
Set<String>mySet=newHashSet<>();mySet.add("John");mySet.add("Mary");System.out.println(mySet);// => [John, Mary]mySet.add("John");// John zit al in de setSystem.out.println(mySet);//=>[Mary,John]
Merk op dat er geen garanties zijn over de volgorde van de elementen in de set.
Als we dat wel willen, gebruiken we een SortedSet (met TreeSet als implementatie):
SortedSet<String>mySet=newTreeSet<>();mySet.add("John");mySet.add("Mary");for(Stringel:mySet){System.out.println(el);}// gegarandeerd in alfabetische volgorde:// John//Mary
De String-klasse implementeert Comparable om String-objecten alfabetisch te sorteren.
Onthoud
Gebruik een Set als je een collectie zonder dubbels wil voorstellen.
De elementen in een Set hebben geen vaste positie.
Als je gebruik maakt van een SortedSet kan je de elementen wel sorteren (bv. van klein naar groot).
Map (Dictionary)
De collecties hierboven stellen allemaal een groep elementen voor, en erven over van de Collection-interface.
Een Map is iets anders.
Hier worden sleutels bijgehouden, en bij elke sleutel hoort een waarde (een object).
Denk aan een telefoonboek, waar bij elke naam (de sleutel) een telefoonnummer (de waarde) hoort, of een woordenboek waar bij elk woord (de sleutel) een definitie hoort (de waarde).
Een andere naam voor een map is dan ook een dictionary.
Sleutels mogen slechts één keer voorkomen; eenzelfde waarde mag wel onder meerdere sleutels opgeslagen worden.
De interface Map<K, V> heeft niet één, maar twee generische parameters: een (K) voor het type van de sleutels, een een (V) voor het type van de waarden.
Elementen toevoegen aan een Map<K, V> gaat via de put(K key, V value)-methode.
De waarde opvragen kan via de methode V get(K key).
Verder zijn er methodes om na te gaan of een map een bepaalde sleutel of waarde bevat.
Een Map is sterk geoptimaliseerd voor deze operaties.
Er zijn verder ook drie manieren om een Map<K, V> als een Collection te beschouwen:
de keySet: de verzameling van alle sleutels in de Map (een Set<K>)
de values: de collectie van alle waarden in de Map (een Collection<V>, want dubbels zijn mogelijk)
de entrySet: een verzameling (Set<Entry<K, V>>) van alle sleutel-waarde paren (de entries).
HashMap
Net zoals bij Set kunnen we de Map-interface implementeren met een hashtable.
Dat gebeurt in de HashMap klasse.
Entries in een hashmap worden in een niet-gespecifieerde volgorde bijgehouden.
De werking van een hashmap is zeer gelijkaardig aan wat we besproken hebben bij HashSet hierboven.
Meer zelfs, de implementatie van HashSet in Java maakt gebruik van een HashMap.
Het belangrijkste verschil met de HashSet is dat we in een HashMap, naast de waarde, ook de sleutel moeten bewaren.
SortedMap en TreeMap
Een SortedMap is een map waarbij de sleutels (dus niet de waarden) gesorteerd worden bijgehouden (zoals bij een SortedSet). Een concrete implementatie van de SortedMap-interface is een TreeMap.
Voorbeeld
Een voorbeeld van het gebruik van Map als een telefoonbook:
classPersonimplementsComparable<Person>{...}classPhoneNumber{...}Personmary=newPerson("Mary");Personjohn=newPerson("John");Map<Person,PhoneNumber>phoneBook=newHashMap<>();phoneBook.put(john,newPhoneNumber("0470123456"));phoneBook.put(mary,newPhoneNumber("0480999999"));PersonsomePerson=...PhoneNumbernumberOrInfo;if(phoneBook.containsKey(somePerson)){// geeft `null` terug indien persoon niet gevondennumberOrInfo=phoneBook.get(somePerson);}else{numberOrInfo=newPhoneNumber("1207")}
Een Map bevat ook een getOrDefault-methode, waarmee we bovenstaande if-test kunnen vermijden door meteen aan te geven welke waarde teruggegeven moet worden als de sleutel niet in de map zit:
Aangezien we personen alfabetisch kunnen sorteren (Person hierboven implementeert namelijk Comparable), kunnen we ook een SortedMap gebruiken.
Als implementatie gebruiken we dan een TreeMap in plaats van HashMap:
Gebruik een Map om efficiënt een waarde-object op te slaan bij een gekend sleutel-object.
Het verwachte gebruik is dat je aan de hand van de sleutel de waarde opvraagt — niet omgekeerd.
De elementen in een Map hebben geen vaste positie.
Als je gebruik maakt van een SortedMap kan je de elementen wel sorteren (bv. van klein naar groot).
Oefeningen
Setup
Voor deze oefeningen is er al wat code beschikbaar op GitHub om van te vertrekken.
Je kan deze code in IntelliJ makkelijk inladen als project.
Doe daarvoor hetvolgende:
Kies in IntelliJ voor New > Project from Version Control
Zorg dat Git geselecteerd is, en geef als URL volgende URL in:
Na het laden zie je rechtsonder een pop-up Gradle build scripts found. Klik op Load.
Het project wordt nu ingeladen. Wacht tot de voortgangsbalk rechtsonder verdwenen is.
Gradle en unit tests
In dit project wordt reeds Gradle gebruikt als build system.
Dat is nog niet aan bod gekomen in deel 1.
Je hoeft je hier echter niet veel van aan te trekken; je kan de code gewoon uitvoeren met de play-knop zoals voorheen.
Merk wel op dat de broncode en testcode in verschillende folders staan:
alle broncode (de code van je applicatie) staat in src/main/java
alle testcode staat in src/test/java.
Ook testen (met JUnit/AssertJ) is nog niet aan bod gekomen in deel 1. Weet dat je de tests ook gewoon kan uitvoeren via de play-knop.
Oefening 1: Parking
Maak een klasse Parking die gebruikt wordt voor betalend parkeren.
Kies een of meerdere datastructuren om volgende methodes te implementeren:
void enterParking(String licensePlate): een auto (met gegeven nummerplaat) rijdt de parking binnen
double amountToPay(String licensePlate): bereken het te betalen bedrag voor de gegeven auto (nummerplaat). De parking kost 2 euro per begonnen uur.
void pay(String licensePlate): markeer dat de auto met de gegeven nummerplaat betaald heeft
boolean tryLeaveParking(String licensePlate): geef terug of de gegeven auto de parking mag verlaten (betaald heeft), en verwijder de auto uit het systeem indien betaald werd.
history(): geeft de nummerplaten van de auto’s terug die de parking zijn binnengereden, in volgorde van minst naar meest recent (kies zelf een geschikt terugkeertype).
Om te werken met huidige tijd en intervallen tussen twee tijdstippen, kan je gebruik maken van java.time.Instant. Een Instant verwijst naar een bepaald moment, en kan je verkrijgen via de instant()-methode van een Clock-object.
Omdat je Parking-object dus over een klok moet beschikken, voorzie je een constructor Parking(Clock clock) met een Clock-object als parameter.
Test uit hoe belangrijk het is dat de hashcodes van verschillende objecten in een HashSet goed verdeeld zijn aan de hand van de code hieronder.
Deze code meet hoelang het duurt om een HashSet te vullen met 50000 objecten; de eerste keer met goed verspreide hashcodes, en de tweede keer een keer met steeds dezelfde hashcode. Voer uit; merk je een verschil?
importjava.util.HashSet;importjava.util.concurrent.TimeUnit;importjava.util.function.Function;publicclassTiming{recordDefaultHashcode(inti){}recordCustomHashcode(inti){@OverridepublicinthashCode(){return4;// altijd 4!}}publicstaticvoidmain(String[]args){IO.print("With default hashcode: ");test(DefaultHashcode::new);System.gc();IO.print("With identical hashcode: ");test(CustomHashcode::new);}privatestatic<T>voidtest(Function<Integer,T>ctor){varset=newHashSet<T>();varstart=System.nanoTime();// vul de set op met 50000 nieuwe objectenfor(inti=0;i<50_000;i++){set.add(ctor.apply(i));}varend=System.nanoTime();IO.println("%d elements added in %.3f seconds".formatted(set.size(),TimeUnit.NANOSECONDS.toMillis(end-start)/1000.0));}}
Oefening 3: Veranderende hashcode
Is het nodig dat de hashCode van een object hetzelfde blijft doorheen de levensduur van het object, of mag deze veranderen?
Verklaar je antwoord.
Antwoord
Nee, deze mag niet veranderen. Mocht die wel veranderen, kan het zijn dat je een object niet meer terugvindt in een set, omdat er (door de veranderde hashcode) in een andere bucket gezocht wordt dan waar het object zich bevindt.
We willen een klasse IntRange maken waarmee we een gewone for-lus kunnen vervangen door een enhanced for-lus.
Je moet deze klasse als volgt kunnen gebruiken:
Schrijf eerst een klasse IntRangeIterator die Iterator<Integer> implementeert, en alle getallen teruggeeft tussen twee grensgetallen lowest en highest (beiden inclusief) die je meegeeft in de constructor. Je houdt hiervoor enkel de onder- en bovengrens bij, alsook het volgende terug te geven getal.
Schrijf nu ook een klasse IntRange die Iterable<Integer> implementeert, en die een IntRangeIterator-object aanmaakt en teruggeeft.
Notitie
Java laat niet toe om primitieve types als generische parameters te gebruiken.
Voor elk primitief type bestaat er een wrapper-klasse, bijvoorbeeld Integer voor int.
Daarom gebruiken we hierboven bijvoorbeeld Iterator<Integer> in plaats van Iterator<int>.
Achter de schermen worden int-waarden automatisch omgezet in Integer-objecten en omgekeerd.
Dat heet auto-boxing en -unboxing.
Je kan beide types in je code grotendeels door elkaar gebruiken zonder problemen.
Oefening 5: MultiMap
Schrijf een klasse MultiMap<K, V> die een Map voorstelt, maar waar bij elke key een verzameling (Set) van waarden hoort in plaats van slechts één waarde.
Bijvoorbeeld: een MultiMap<Manager, Employee> kan bijhouden voor welke werknemers (meervoud!) een manager verantwoordelijk is.
Maak gebruik een Map in je implementatie.
Hieronder vind je skeletcode die aangeeft welke methodes je moet voorzien, alsook enkele tests.
Leg uit hoe je een HashSet zou kunnen implementeren gebruik makend van een HashMap.
(Dit is ook wat Java (en Python) doen in de praktijk.)
Antwoord
Je gebruikt de elementen die je in de set wil opslaan als sleutel (key), en als waarde (value) neem je een willekeurig object.
Als het element in de HashMap een geassocieerde waarde heeft, zit het in de set; anders niet.
MyArrayList
Schrijf zelf een simpele klasse MyArrayList<E> die werkt zoals de ArrayList uit Java.
Voorzie in je lijst een initiële capaciteit van 4, maar zonder elementen.
Implementeer volgende operaties:
int size() die de grootte (het huidig aantal elementen in de lijst) teruggeeft
int capacity() die de huidige capaciteit (het aantal plaatsen in de array) van de lijst teruggeeft
E get(int index) om het element op positie index op te vragen (of een IndexOutOfBoundsException indien de index ongeldig is)
void add(E element) om een element achteraan toe te voegen (en de onderliggende array dubbel zo groot te maken indien nodig)
void remove(int index) om het element op plaats index te verwijderen (of een IndexOutOfBoundsException indien de index ongeldig is). De capaciteit moet niet terug dalen als er veel elementen verwijderd werden (dat gebeurt in Java ook niet).
E last() om het laatste element terug te krijgen (of een NoSuchElementException indien de lijst leeg is)
Hier vind je een test die een deel van dit gedrag controleert:
Testcode
@Testpublicvoidtest_my_arraylist(){MyArrayList<String>lst=newMyArrayList<>();// initial capacity and sizeassertThat(lst.capacity()).isEqualTo(4);assertThat(lst.size()).isEqualTo(0);// adding elementsfor(inti=0;i<4;i++){lst.add("item"+i);}assertThat(lst.size()).isEqualTo(4);assertThat(lst.capacity()).isEqualTo(4);assertThat(lst.last()).isEqualTo("item3");// adding more elementsfor(inti=4;i<10;i++){lst.add("item"+i);}assertThat(lst.size()).isEqualTo(10);assertThat(lst.capacity()).isEqualTo(16);assertThat(lst.last()).isEqualTo("item9");// remove an elementlst.remove(3);assertThat(lst.size()).isEqualTo(9);assertThat(lst.capacity()).isEqualTo(16);assertThat(lst.get(3)).isEqualTo("item4");assertThatThrownBy(()->lst.get(10)).isInstanceOf(IndexOutOfBoundsException.class);}
MyLinkedList
Schrijf zelf een klasse MyLinkedList<E> om een dubbel gelinkte lijst voor te stellen. Voorzie volgende operaties:
int size() om het aantal elementen terug te geven
void add(E element) om het gegeven element achteraan toe te voegen
E get(int index) om het element op positie index op te vragen
void remove(int index) om het element op positie index te verwijderen
Hieronder vind je enkele tests voor je klasse. Je zal misschien merken dat je implementatie helemaal juist krijgen niet zo eenvoudig is als het op het eerste zicht lijkt, zeker bij de remove-methode.
Gebruik de visuele voorstelling van eerder, en ga na wat je moet doen om elk van de getekende knopen te verwijderen.
De concepten in andere programmeertalen die het dichtst aanleunen bij Java records, pattern matching en sealed interfaces zijn
structs in C en C++ (pattern matching in C++ is nog niet beschikbaar, maar er wordt gewerkt aan dit toe te voegen aan de taal)
@dataclass en structured pattern matching in Python
(sealed) record types en pattern matching in C#
Wat zijn records
In een object-georiënteerd software-ontwerp brengen we data en gedrag samen binnen één klasse.
We gebruiken dan gewoonlijk encapsulatie: we maken de velden van een klasse privaat, zodat ze worden afgeschermd van andere klassen. Op die manier kunnen we de interne representatie (de velden en hun types) makkelijk aanpassen: zolang de publieke methodes (het gedrag) hetzelfde blijven, heeft zo’n aanpassing aan de interne voorstellingswijze geen effect op de rest van het systeem.
Maar soms is encapsulatie niet echt nodig: sommige klassen zijn niet meer dan een bundeling van verschillende waarden, zonder bijhorend complex gedrag.
Welgekende voorbeelden zijn een coordinaat (bestaande uit een x- en y-attribuut), een geldbedrag (een bedrag en een munteenheid), een adres (straat, huisnummer, postcode, gemeente), etc.
Objecten van deze klassen hoeven ook niet aanpasbaar te zijn; je kan makkelijk een nieuw object maken met andere waarden.
Met andere woorden, de identiteit van het object is van ondergeschikt belang.
We noemen dit data-oriented programming: een ontwerpstrategie waar data een first class citizen is, en niet gekoppeld hoeft te worden aan gedrag.
Voor dergelijke klassen heeft doorgedreven encapsulatie weinig zin.
Een record in Java is een eenvoudige klasse die gebruikt kan worden voor data-oriented programming.
Een record-object dient voornamelijk als data-drager, waarbij verschillende objecten met dezelfde attribuut-waarden gewoonlijk volledig inwisselbaar (equivalent) zijn.
De attributen van een record-object mogen daarom niet veranderen doorheen de tijd (het object is dus immutable).
Als voorbeeld definiëren we een coördinaat-klasse als een record, met 2 attributen: een x- en y-coördinaat.
publicrecordCoordinate(doublex,doubley){}
Merk het verschil op met de definitie van een gewone klasse: de attributen van de record staan hier vlak na de klassenaam, en er is geen constructor nodig.
Objecten van een record maak je gewoon aan met new, zoals elk ander object:
wanneer je een type wil definiëren dat overeenkomt met een ander, reeds bestaand datatype, maar met beperkingen.
recordPositiveNumber(intnumber){publicPositiveNumber{if(number<=0)thrownewIllegalArgumentException("Number must be larger than 0");}}
wanneer je een (immutable) datatype wil maken dat zonder probleem door meerdere threads gebruikt kan worden. We gaan in dit vak niet dieper in op het onderwerp Multithreading en concurrency, maar onthoud dat het gebruik van immutable objecten zeer sterk aangeraden wordt in deze context!
Merk op dat bij records in de eerste plaats gaat over het creëren van een nieuw datatype, door (primitievere) data of andere records te bundelen, of beperkingen op te leggen aan mogelijke waarden.
Je maakt dus als het ware een nieuw ‘primitief’ datatype, zoals int, double, of String.
Dit in tegenstelling tot gewone klassen, waar encapsulatie en mogelijkheden om de toestand van een object aan te passen (mutatie-methodes) ook essentieel zijn.
Onthoud
Gebruik een record wanneer je puur data modelleert, zonder bijhorend gedrag dat de toestand van het object kan veranderen.
Gebruik geen record als je een entiteit modelleert waarvan de toestand kan evolueren doorheen de tijd (met andere woorden, wanneer de identiteit van het object belangrijk is).
Achter de schermen
Een record is eigenlijk een gewone klasse, waarbij de Java-compiler zelf enkele zaken voorziet:
een constructor, die de velden initialiseert;
methodes om de attributen op te vragen;
een toString-methode om een leesbare versie van het record uit te printen; en
een equals- en hashCode-methode, die ervoor zorgen dat objecten met dezelfde parameters als gelijk worden beschouwd.
De klasse is ook final, zodat er geen subklassen van gemaakt kunnen worden.
De coördinaat-record van hierboven is equivalent aan volgende klasse-definitie:
Merk wel op dat, omdat de klasse immutable is, je in een methode geen nieuwe waarde kan toekennen aan de velden. Code als
this.x=5;
in een methode van een record is dus ongeldig, en leidt tot een foutmelding van de compiler.
Constructor van een record
Als je geen enkele constructor definieert, krijgt een record een standaard constructor met de opgegeven attributen als parameters (in dezelfde volgorde).
Maar je kan ook zelf een of meerdere constructoren definiëren voor een record, net zoals bij klassen (je krijgt dan geen default-constructor meer).
Je moet in die constructoren zorgen dat alle attributen van het record geïnitialiseerd worden.
publicrecordCoordinate(doublex,doubley){publicCoordinate(doublex,doubley){this.x=x;this.y=y;}publicCoordinate(doublex){// constructor for points on the x-axisthis(x,0);}}
Er is ook een verkorte notatie, waarbij je de parameters niet meer moet herhalen (die staan immers al achter de naam van het record).
Je hoeft met deze notatie ook de parameters niet toe te kennen aan de velden; dat gebeurt automatisch.
Het belangrijkste nut hiervan is om de geldigheid van de waarden te controleren bij het aanmaken van een object:
publicrecordCoordinate(doublex,doubley){publicCoordinate{if(x<0)thrownewIllegalArgumentException("x must be non-negative");if(y<0)thrownewIllegalArgumentException("y must be non-negative");}}
Records en overerving
Zoals eerder al vermeld werd, komt een record overeen met een final klasse.
Je kan er dus niet van overerven.
Een record zelf kan ook geen subklasse zijn van een andere klasse of record, maar kan wel interfaces implementeren.
Immutable
Een record is immutable (onveranderbaar): de attributen krijgen een waarde wanneer het object geconstrueerd wordt, en kunnen daarna nooit meer wijzigen.
Als je een object wil met andere waarden, moet je dus een nieuw object maken.
Bijvoorbeeld, als we een translate methode willen maken voor Coordinate, dan kunnen we de x- en y-coordinaten niet aanpassen.
We moeten een nieuw Coordinate-object maken, en dat teruggeven:
publicrecordCoordinate(doublex,doubley){publicCoordinatetranslate(doubledeltaX,doubledeltaY){// NIET:// this.x += deltaX; <-- kan niet; de x-waarde mag niet meer gewijzigd worden// WEL: een nieuw object makenreturnnewCoordinate(this.x+deltaX,this.y+deltaY);}}
Let op! Als een van de velden van het record een object is dat zelf wél gewijzigd kan worden (bijvoorbeeld een array of ArrayList), dan kan je de data die geassocieerd wordt met het record dus wel nog wijzigen.
Vermijd deze situatie!
Bijvoorbeeld:
Hier zijn twee record-objecten eerst gelijk, maar later niet meer.
Dat schendt het principe dat, voor data-objecten, de identiteit van het object niet zou mogen uitmaken.
De objecten zijn immers niet meer dan de aggregatie van de data die ze bevatten.
Overal waar playlist1 gebruikt wordt, zou ook playlist2 gebruikt moeten kunnen worden en vice versa.
Twee record-objecten die gelijk zijn, moeten altijd gelijk blijven, onafhankelijk van wat er later nog gebeurt.
Gebruik dus bij voorkeur immutable data types in een record.
Pattern matching
Je kan records ook gebruiken in switch statements.
Dit heet pattern matching, en is vooral nuttig wanneer je meerdere record-types hebt die eenzelfde interface implementeren.
Bijvoorbeeld:
Merk op dat je zowel kan matchen op het object als geheel (Square s in het voorbeeld hierboven), individuele argumenten (Circle(double radius) in het voorbeeld), en zelfs geneste patronen (Rectangle(Coordinate(double topLeftX, double topLeftY), Coordinate bottomRight)).
De switch-expressie hierboven is verschillend van het (oudere) switch-statement in Java:
er wordt -> gebruikt in plaats van :
er is geen break nodig op het einde van elke case
de switch-expressie geeft een waarde terug die kan toegekend worden aan een variabele, of gebruikt kan worden in een return-statement (zoals in het voorbeeld hierboven).
Tenslotte is er in een switch-expressie de mogelijkheid om een conditie toe te voegen door middel van een when-clausule:
publicdoublearea(Shapeshape){returnswitch(shape){caseSquares->s.side()*s.side();caseCircle(doubleradius)->Math.PI*radius*radius;caseRectangle(Coordinate(doubletopLeftX,doubletopLeftY),CoordinatebottomRight)whentopLeftX<=bottomRight.x()&&topLeftY<=bottomRight.y()->// <= when-clausule(bottomRight.x()-topLeftX)*(bottomRight.y()-topLeftY);default->thrownewIllegalArgumentException("Unknown or invalid shape");};}
Op die manier kan je extra voorwaarden toevoegen om een case te laten matchen, bovenop het type van het element.
Sealed interfaces
Wanneer je alle klassen kent die een bepaalde interface zullen implementeren (of van een abstracte klasse zullen overerven), kan je van deze interface (of klasse) een sealed interface (of klasse) maken.
Met een permits clausule kan je aangeven welke klassen de interface mogen implementeren:
Indien je geen permits-clausule opgeeft, zijn enkel de klassen die in hetzelfde bestand staan toegestaan.
Omdat elk Java-bestand slechts 1 publieke top-level klasse (of interface/record) mag hebben, zal je vaak ook zien dat de records in de interface-definitie geplaatst worden:
Omdat de compiler kan nagaan wat alle mogelijkheden zijn, kan je bij pattern matching op een sealed klasse in een switch statement ook de default case weglaten:
Omgekeerd zal de compiler je ook waarschuwen wanneer er een geval ontbreekt.
publicdoublearea(Shapeshape){returnswitch(shape){caseSquares->s.side()*s.side();caseCircle(doubleradius)->Math.PI*radius*radius;// <= compiler error: ontbrekende case voor 'Rectangle'};}
Geef enkele voorbeelden van types die volgens jou best als record gecodeerd worden, en ook enkele types die best als klasse gecodeerd worden.
Kan je, voor een van je voorbeelden, een situatie bedenken waarin je van record naar klasse zou gaan, en omgekeerd?
Antwoord
Records zijn vooral geschikt voor het bijhouden van stateless informatie (objecten zonder gedrag).
Bijvoorbeeld: Money, ISBN, BookInfo, ProductDetails, …
Klassen zijn geschikt als de identiteit van het object van belang is en constant blijft, maar de state (data) doorheen de tijd kan wijzigen.
Bijvoorbeeld: BankAccount, ShoppingCart, GameCharacter, OrderProcessor, …
Overgaan van de ene naar de andere vorm kan wanneer er gedrag toegevoegd of verwijderd wordt.
Bijvoorbeeld, BookInfo zou een klasse kunnen worden indien we er (in de context van een bibliotheek) ook informatie over ontleningen in willen bijhouden. Omgekeerd kan BankAccount van klasse naar object gaan indien het enkel een voorstelling wordt van rekeninginformatie (rekeningnummer en naam van de houder bijvoorbeeld), en de balans en transacties naar een ander object (bv. TransactionHistory) verplaatst worden.
Sealed interface
Kan je een voorbeeld bedenken van een nuttig gebruik van een sealed interface?
Antwoord
Sealed interfaces zijn vooral nuttig om een uitgebreidere vorm van enum’s te maken, waar elke optie ook extra informatie met zich kan meedragen.
Bijvoorbeeld:
sealed interface PaymentMethod om een manier van betalen voor te stellen, met subtypes (records) CreditCard(cardName, cardNumber, expirationDate), PayPal(email), BankTransfer(iban), …
sealed interface Command wat een commando voorstelt dat uitgevoerd kan worden, met subtypes (records) CreateUser(name, email), DeleteUser(uuid), UpdateUser(uuid, newEmail), …
Email
Definieer een Email-record dat een geldig e-mailadres voorstelt.
Het mail-adres wordt voorgesteld door een String.
Controleer de geldigheid van de String bij het aanmaken van een Email-object:
de String mag niet null zijn (anders NullPointerException)
de String moet exact één @-teken bevatten (anders IllegalArgumentException)
de String moet eindigen op “.com” of “.be” (anders IllegalArgumentException)
Schrijf een record die een rechthoek voorstelt.
Een rechthoek wordt gedefinieerd door 2 punten (linksboven en rechtsonder).
Gebruik een Coordinaat-record om deze hoekpunten voor te stellen.
Zorg ervoor dat enkel geldige rechthoeken aangemaakt kunnen worden (dus: het hoekpunt linksboven ligt zowel links als boven het hoekpunt rechtsonder).
Voeg extra methodes toe:
om de twee andere hoekpunten (linksonder en rechtsboven) op te vragen
om na te gaan of een gegeven punt zich binnen de rechthoek bevindt
om na te gaan of een rechthoek overlapt met een andere rechthoek. (Hint: bij twee overlappende rechthoeken ligt minstens één hoekpunt van de ene rechthoek binnen de andere)
Expressie-hierarchie
Maak een set van records om een wiskundige uitdrukking voor te stellen.
Alle records moeten een sealed interface Expression implementeren.
De mogelijke expressies zijn:
een Literal: een constante getal-waarde (een double)
een Variable: een naam (een String), bijvoorbeeld “x”
een Sum: bevat twee expressies, een linker en een rechter
een Product: gelijkaardig aan Som, maar stelt een product voor
een Power: een expressie tot een constante macht
De veelterm \( 3x^2+5 \) kan dus voorgesteld worden als:
Gebruik pattern matching (en TDD) voor elk van volgende opdrachten:
de methode evaluate moet de gegeven expressie evalueren voor de gegeven waarden van de variabelen. Bijvoorbeeld, \( 3x^2+5 \) evalueren met \( x=7 \) geeft \(152\). De parameter variableValues bevat een mapping van variabelen naar hun toegekende waarde.
Schrijf de methode prettyPrint die de gegeven expressie omzet in een String, bijvoorbeeld prettyPrint(poly) geeft (3.0) * ((x)^2.0) + 5.0.
Maak je op dit moment nog geen zorgen over onnodige haakjes.
Hint: voor het pretty-printen van een som, pretty-print je eerst de linker- en rechterterm afzonderlijk.
Zorg er nu voor dat er geen onnodige haakjes verschijnen in het resultaat van prettyPrint, door rekening te houden met de volgorde van de bewerkingen. (Hint: geef elke expressie een numerieke prioriteit)
(uitdagend) De methode simplify moet de gegeven expressie te vereenvoudigen door enkele vereenvoudigingsregels toe te passen. Bijvoorbeeld, het vervangen van \(3 + 7\) door \(10\), vervangen van \(x+0\), \(x*1\), en \(x^1\) door \(x\); vervangen van \(x * 0\) door \(0\), …
(uitdagend) de methode differentiate moet de afgeleide berekenen van de gegeven expressie in de gegeven variabele (bv. \( \frac{d}{dx} 3x^2+5x = 6x+5 \)).
Geef het resultaat zo eenvoudig mogelijk terug (Hint: gebruik simplify).
Denkvraag
Wat is het voor- en nadeel van het gebruik van pattern matching tegenover het gebruik van overerving en dynamische binding?
Met andere woorden, wat is het verschil met bijvoorbeeld de methodes simplify(), evaluate(), … in de interface Expression zelf te definiëren, en ze te implementeren in elke subklasse?
Extra oefeningen
Money
Maak een Money-record dat een geldbedrag (bijvoorbeeld 20) en een munteenheid (bijvoorbeeld “EUR”) bevat.
Voeg ook methodes toe om twee geldbedragen op te tellen. Dit mag enkel wanneer de munteenheid van beiden gelijk is; zoniet moet er een exception gegooid worden.
Interval
Maak een Interval-record dat een periode tussen twee tijdstippen voorstelt, bijvoorbeeld voor een vergadering. Elk tijdstip wordt voorgesteld door een niet-negatieve long-waarde.
Het eind-tijdstip mag niet voor het start-tijdstip liggen.
Voeg een methode toe om na te kijken of een interval overlapt met een ander interval.
Intervallen worden beschouwd als half-open: twee aansluitende intervallen overlappen niet, bijvoorbeeld [15, 16) en [16, 17).
Programmeertaal
Breid de expressies uit de oefening hierboven uit tot je eigen mini-programmeertaal met interpreter.
Voorzie daarvoor een sealed interface Statement met volgende klassen en betekenis:
Assign(name, expr): evalueer expr en sla het resultaat op in de variabele name
Print(expr): evalueer expr en print de waarde uit
If(cond, thenBranch, elseBranch): evalueer expressie cond; indien dit 0 is, voer statement thenBranch uit, anders statement elseBranch
While(cond, body): voer statement body uit zolang expressie cond naar 0 evalueert
Sequence(stmts): voer een lijst van statements stmts (een ‘blok’) na elkaar uit
Voeg dan een klasse Interpreter toe met een methode execute(Statement st) die het meegegeven statement (programma) uitvoert.
In je Interpreter maak je best gebruik van een klasse die de huidige toestand van het programma bijhoudt, met onderstaande interface:
/*
x := 5
while x != 0:
print x
x := x - 1
*/varxvar=newVariable("x");varprogram=newSequence(List.of(newAssign(xvar,newLiteral(5)),newWhile(xvar,newSequence(List.of(newPrint(xvar),newAssign(xvar,newSum(xvar,newLiteral(-1))))))));newInterpreter().execute(program);// 5.0// 4.0// 3.0// 2.0//1.0
7.4 Generics
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java generics zijn
templates in C++
generic types in Python (in de vorm van type hints)
generics in C#
In dit hoofdstuk behandelen we generics. Die worden veelvuldig gebruikt in datastructuren, en een goed begrip ervan is dan ook essentieel.
Generics zijn een manier om klassen en methodes te voorzien van type-parameters.
Bijvoorbeeld, neem de volgende klasse ArrayList1:
Stel dat we deze klasse makkelijk willen kunnen herbruiken, telkens met een ander type van elementen in de lijst.
We kunnen nu nog niet zeggen wat het type wordt van die elementen.
Gaan er Student-objecten in de lijst terechtkomen? Of Animal-objecten?
Dat weten we nog niet.
We daarom voor Object (het meest algemene type in Java) als type van elements, element, en het resultaat van get.
Maar dat betekent ook dat je nu objecten van verschillende, niet-gerelateerde types kan opnemen in één en dezelfde lijst, hoewel dat niet de bedoeling is!
Stel bijvoorbeeld dat je een lijst van studenten wil bijhouden, dan houdt de compiler je niet tegen om ook andere types van objecten toe te voegen:
ArrayListstudents=newArrayList();Studentstudent=newStudent();students.add(student);Animalanimal=newAnimal();students.add(animal);// <-- compiler vindt dit OK 🙁
Om dat tegen te gaan, zou je afzonderlijke klassen ArrayListOfStudents, ArrayListOfAnimals, … kunnen maken, waar het bedoelde type van elementen wel duidelijk is, en ook wordt afgedwongen door de compiler.
Bijvoorbeeld:
De prijs die we hiervoor betalen is echter dat we nu veel quasi-identieke implementaties moeten maken, die enkel verschillen in het type van hun elementen.
Dat leidt tot veel onnodige en ongewenste code-duplicatie.
Met generics kan je een type gebruiken als parameter voor een klasse (of methode, zie later) om code-duplicatie zoals hierboven te vermijden.
Dat ziet er dan als volgt uit (we gaan zodadelijk verder in op de details):
classArrayList<T>{privateT[]elements;// ...}
Generics geven je dus een combinatie van de beste eigenschappen van de twee opties die we overwogen hebben:
er moet slechts één implementatie gemaakt worden (zoals bij ArrayList hierboven), en
deze implementatie kan gebruikt worden om lijsten te maken waarbij het gegarandeerd is dat alle elementen een specifiek type hebben (zoals bij ArrayListOfStudents).
In de volgende secties bekijken we generics in meer detail.
Deze klasse is geïnspireerd op de ArrayList-klasse die standaard in Java zit. ↩︎
Subsecties van 7.4 Generics
7.4.1 Definiëren en gebruiken
Om generics te gebruiken moet je altijd een generische parameter (meestal aangegeven met een enkele letter) toevoegen, zoals de generische parameter T bij ArrayList<T>.
In het algemeen zijn er slechts twee plaatsen in je code waar je een nieuwe generische parameter mag introduceren:
Bij de definitie van een klasse (of interface, record, …)
Bij de definitie van een methode (of constructor)
We kijken eerst naar generische klassen.
Een generische klasse definiëren
Om een generische klasse te definiëren, zet je de type-parameter tussen < en > achter de naam van de klasse die je definieert.
Vervolgens kan je die parameter (bijna1) overal in die klasse gebruiken als type:
classMyGenericClass<E>{// je kan hier (bijna) overal E gebruiken als type}
Bijvoorbeeld, volgende klasse is een nieuwe versie van de ArrayList-klasse van eerder, maar nu met type-parameter E (waar E staat voor ‘het type van de elementen’).
Deze E wordt vervolgens gebruikt als type voor de elements-array, de parameter van de add-method, en het resultaat-type van de get-method:
Je zal heel vaak zien dat generische type-parameters slechts bestaan uit 1 letter (populaire letters zijn bijvoorbeeld E, R, T, U, V). Dat is geen vereiste: onderstaande code mag ook, en is volledig equivalent aan die van hierboven.
De reden waarom vaak met individuele letters gewerkt wordt, is om duidelijk te maken dat het over een type-parameter gaat, en niet over een bestaande klasse.
Naast klassen kan je ook records en interfaces voorzien van een generische parameter.
Weetje
Je kan een generische klasse ook zien als een functie (soms een type constructor genoemd).
Die functie geeft geen object terug op basis van een of meerdere parameters zoals je dat gewoon bent van functies, bijvoorbeeld getPet : (Person p) → Animal, maar geeft een nieuw type (een nieuwe klasse) terug, gebaseerd op de type-parameters.
Bijvoorbeeld, de generische klasse ArrayList<T> kan je beschouwen als een functie ArrayList : (Type T) → Type, die het type ArrayListOfStudents of ArrayListOfAnimals teruggeeft wanneer je ze oproept met respectievelijk T=Student of T=Animal.
In plaats van ArrayListOfStudents schrijven we dat type als ArrayList<Student>.
Een generische klasse gebruiken
Bij het gebruik van een generische klasse (bijvoorbeeld ArrayList<E> van hierboven) moet je een concreet type opgeven voor de type-parameter (E).
Bijvoorbeeld, op plaatsen waar je een lijst met enkel studenten verwacht, gebruik je ArrayList<Student> als type.
Je kan dan de klasse gebruiken op dezelfde manier als de ArrayListOfStudents klasse van hierboven:
ArrayList<Student>students=newArrayList<Student>();StudentsomeStudent=newStudent();students.add(someStudent);// <-- OK 👍// students.add(animal); // <-- niet toegelaten (compiler error) 👍StudentfirstStudent=students.get(0);//<--OK👍
Merk op hoe de compiler afdwingt en garandeert dat er enkel Student-objecten in deze lijst terecht kunnen komen.
Om wat typwerk te besparen, laat Java in veel gevallen ook toe om het type weg te laten bij het instantiëren, met behulp van <>.
Dat type kan immers automatisch afgeleid worden van het type van de variabele:
Een type-parameter <E> zoals we die tot nu toe gezien hebben kan om het even welk type voorstellen.
Soms willen we dat niet, en willen we beperkingen opleggen.
Stel bijvoorbeeld dat we volgende klasse-hierarchie hebben:
De Food-klasse is enkel bedoeld om met Animal (en de subklassen van Animal) gebruikt te worden, bijvoorbeeld Food<Cat> en Food<Dog>.
Maar niets houdt ons op dit moment tegen om ook een Food<Student of een Food<String> te maken.
Daarenboven zal de compiler (terecht) ook een compilatiefout geven in de methode giveTo van Food: er wordt een Animal-specifieke methode opgeroepen (namelijk showLike) op de parameter animal, maar die heeft type A en dat kan eender wat zijn, bijvoorbeeld ook String.
En String biedt natuurlijk geen methode showLike() aan.
We kunnen daarom aangeven dat type A een subtype moet zijn van Animal door bij de definitie van de generische parameter <A extends Animal> te schrijven.
Je zal dan niet langer Food<String> mogen schrijven, aangezien String geen subklasse is van Animal.
We begrenzen dus de mogelijke types die gebruikt kunnen worden voor de type-parameter A tot alle types die overerven van Animal (inclusief Animal zelf).
classFood<AextendsAnimal>{publicvoidgiveTo(Aanimal){/* ... */animal.showLike();// <= OK! 👍}}Food<Cat>catFood=newFood<>();// nog steeds OKFood<String>stringFood=newFood<>();//<--compilererror👍
Notitie
Wanneer je deze materie later opnieuw doorneemt, heb je naast extends ook al gehoord van super en wildcards (?) — dit wordt later besproken.
Het is belangrijk om op te merken dat je super en ?nooit kan gebruiken bij de definitie van een nieuwe generische parameter (de Java compiler laat dit niet toe).
Dat kan enkel op de plaatsen waar je een generische klasse of methode gebruikt.
Onthoud dus: op de plaatsen waar je een nieuwe parameter (een nieuwe ’letter’) introduceert, kan je enkel aangeven dat die een subtype van iets moet zijn met behulp van extends.
Een generische methode definiëren en gebruiken
In de voorbeelden hierboven hebben we steeds een hele klasse generisch gemaakt.
Naast een generische klasse is er ook een tweede manier om een generische parameter te definiëren, namelijk eentje die enkel in één methode gebruikt kan worden.
Dat doe je door de parameter te declareren vóór het terugkeertype van die methode, opnieuw tussen < en >.
Dat kan ook in een klasse die zelf geen type-parameters heeft.
Je kan die parameter dan gebruiken in de methode zelf, en ook in de types van de parameters en het terugkeertype (dus overal na de definitie ervan).
Bijvoorbeeld, onderstaande methodes doSomething en doSomethingElse hebben beiden een generische parameter T.
Die parameter hoort enkel bij elke individuele methode; beide generische types staan dus volledig los van elkaar.
Ook NormalClass is geen generische klasse; enkel de twee methodes zijn generisch.
classNormalClass{public<T>intdoSomething(ArrayList<T>elements){// je kan overal in deze methode type T gebruiken}publicstatic<T>ArrayList<T>doSomethingElse(ArrayList<T>elements,Telement){// deze T is onafhankelijk van die in doSomething}}
Het is trouwens ook mogelijk om generische klassen en generische methodes te combineren:
classFoo<T>{public<U>ArrayList<U>doSomething(ArrayList<T>ts,ArrayList<U>us){// code met T en U}}
Deze methode-definitie maakt zowel gebruik van de generische parameter T (beschikbaar in de hele klasse Foo) als de parameter U (enkel beschikbaar in de methode doSomething).
Type inference
Bij het gebruik van een generische methode zal de Java-compiler zelf proberen om de juiste types te vinden; dit heet type inference. Je kan de methode meestal gewoon oproepen zoals elke andere methode, en hoeft dus (in tegenstelling tot bij klassen) niet zelf aan te geven hoe de generische parameters geïnstantieerd worden.
In de uitzonderlijke gevallen waar type inference faalt, of wanneer je het type van de generische parameter expliciet wil maken, kan je die zelf opgeven als volgt:
Merk op hoe we, tussen het . en de naam van de methode, de generische parameter <Dog> toevoegen.
Voorbeeld
Als voorbeeld definiëren we (in een niet-generische klasse AnimalHelper) een generische (statische) methode findHappyAnimals.
Deze heeft 1 generische parameter T, en we leggen meteen ook op dat dat een subtype van Animal moet zijn (<T extends Animal>).
Merk op dat we het type T zowel gebruiken bij de animals-parameter als bij het terugkeertype van de methode.
Zo kunnen we garanderen dat de teruggegeven lijst precies hetzelfde type elementen heeft als de lijst animals, zonder dat we al moeten vastleggen welk type dier (bv. Cat of Dog) dat precies is.
Dus: als we een ArrayList<Cat> meegeven aan de methode, krijgen we ook een ArrayList<Cat> terug.
Op dezelfde manier kan je ook het type van meerdere parameters (en eventueel het terugkeertype) aan elkaar vastkoppelen.
In het voorbeeld hieronder zie je een methode die paren kan maken tussen dieren; de methode kan gebruikt worden voor elk type dier, maar kan enkel paren maken van dezelfde diersoort.
Je ziet meteen ook een voorbeeld van een generisch record-type AnimalPair.
classAnimalHelper{// voorbeeld van een generisch recordpublicrecordAnimalPair<TextendsAnimal>(Tmale,Tfemale){}publicstatic<TextendsAnimal>ArrayList<AnimalPair<T>>makePairs(ArrayList<T>males,ArrayList<T>females){/* ... */}}ArrayList<Cat>maleCats=...ArrayList<Cat>femaleCats=...ArrayList<Dog>femaleDogs=...ArrayList<AnimalPair<Cat>>pairedCats=makePairs(maleCats,femaleCats);// OKArrayList<AnimalPair<Animal>>pairedMix=makePairs(maleCats,femaleDogs);//nietOK(compilererror)👍
Merk hierboven op hoe, door de parameter T op verschillende plaatsen te gebruiken in de methode, deze methode enkel gebruikt kan worden om twee lijsten met dezelfde diersoorten te koppelen, en er meteen ook gegarandeerd wordt dat de AnimalPair-objecten die teruggegeven worden ook hetzelfde type dier bevatten.
Als het type T niet van belang is omdat het nergens terugkomt (niet in het terugkeertype van de methode, niet bij een andere parameter, en ook niet in de body van de methode), dan heb je strikt gezien geen generische methode nodig.
Zoals we later bij het gebruik van wildcards zullen zien, kan je dan ook gewoon het wildcard-type <? extends X> gebruiken, of <?> indien het type niet begrensd moet worden.
In plaats van
publicstatic<TextendsAnimal>voidfeedAll(ArrayList<T>animals){// code die T nergens vermeldt}
kan je dus ook de generische parameter T weglaten, en hetvolgende schrijven:
Dit is nu geen generische methode meer (er wordt geen nieuwe generische parameter geïntroduceerd); de parameter animals maakt wel gebruik van een generisch type.
Je leest deze methode-signatuur als ‘de methode feedAll neemt als parameter een lijst met elementen van een willekeurig (niet nader bepaald) subtype van Animal’.
Onthoud
Er zijn slechts 2 plaatsen waar je een nieuwe generische parameter (een ’letter’ zoals T of U) mag introduceren:
vlak na de naam van een klasse (of record, interface, …) die je definieert (class Foo<T> { ... }); of
vlak vóór het terugkeertype van een methode (public <T> void doSomething(...) { }).
Op alle andere plaatsen waar je naar een generische parameter verwijst (door de letter te gebruiken), moet je ervoor zorgen dat deze eerst gedefinieerd werd op één van deze twee plaatsen.
Meerdere type-parameters
De ArrayList<E>-klasse hierboven had één generische parameter (E).
Een generische klasse of methode kan ook meerdere type-parameters hebben, bijvoorbeeld een tuple van 3 elementen van mogelijk verschillend type (we maken hier een record in plaats van een klasse):
Bij het gebruik van deze klasse (bijvoorbeeld bij het aanmaken van een nieuw object) moet je dan voor elke parameter (T1, T2, en T3) een concreet type opgeven:
Ook hier kan je met de verkorte notatie <> werken om jezelf niet te moeten herhalen.
Notitie
Het lijkt erg handig om zo’n Tuple-type overal in je code te gebruiken waar je drie objecten samen wil bundelen, maar dat wordt afgeraden.
Niet omdat het drie generische parameters heeft (dat is perfect legitiem), maar wel omdat het niets zegt over de betekenis van de velden (wat zit er in ‘first’, ‘second’, ’third’?).
Gebruik in plaats van een algemene Tuple-klasse veel liever een record waar je de individuele componenten een zinvolle naam geeft.
Bijvoorbeeld: record Enrollment(String student, int year, String courseId) {} of record Point3D(double x, double y, double x) {}.
De generische parameter kan niet gebruikt worden in de statische velden, methodes, inner classes, … van de klasse. ↩︎
7.4.2 Generics en subtyping
Stel we hebben klassen Animal, Mammal, Cat, Dog, en Bird met volgende overervingsrelatie:
Een van de basisregels van object-georiënteerd programmeren is dat overal waar een object van type X verwacht wordt, ook een object van een subtype van X toegelaten wordt.
De Java compiler respecteert deze regel uiteraard.
Volgende toekenningen zijn bijvoorbeeld toegelaten:
maar mammal = new Bird(); is bijvoorbeeld niet toegelaten, want Bird is geen subtype van Mammal.
In onderstaande code is de eerste oproep toegelaten (cat heeft type Cat, en dat is een subtype van Mammal), maar de tweede niet (cat is geen Dog) en de derde ook niet (Cat is geen subtype van Bird):
staticvoidpet(Mammalmammal){/* ... */}staticvoidbark(Dogdog){/* ... */}staticvoidlayEgg(Birdbird){/* ... */}Catcat=newCat();pet(cat);// <- toegelaten (voldoet aan principe)bark(cat);// <- niet toegelaten (compiler error) 👍layEgg(cat);//<-niettoegelaten(compilererror)👍
Subtyping en generische lijsten
Een lijst in Java is een geordende groep van elementen van hetzelfde type.
List<E> is de interface1 die aan de basis ligt van alle lijsten.
ArrayList<E> is een klasse die een lijst implementeert met behulp van een array.
ArrayList<E> is een subtype van List<E>; dus overal waar een List-object verwacht wordt, mag ook een ArrayList gebruikt worden.
In het hoofdstuk rond Collections zagen we ook dat er een interface Collection<E> bestaat, wat een willekeurige groep van elementen voorstelt: niet enkel een lijst, maar bijvoorbeeld ook verzamelingen (Set) of wachtrijen (Queue).
List<E> is een subtype van Collection<E>. Bijgevolg (via transitiviteit) is ArrayList<E> dus ook subtype van Collection<E>.
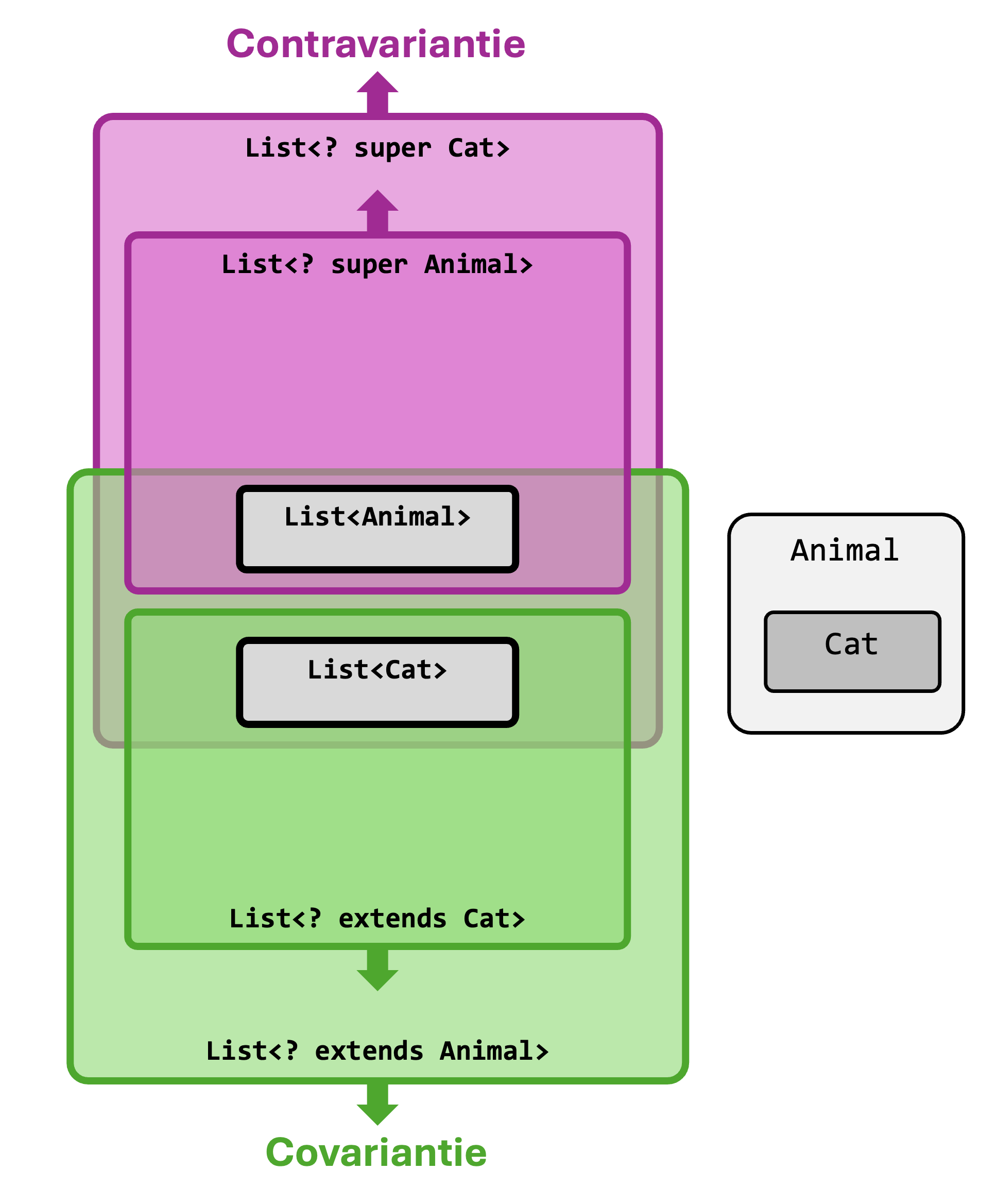
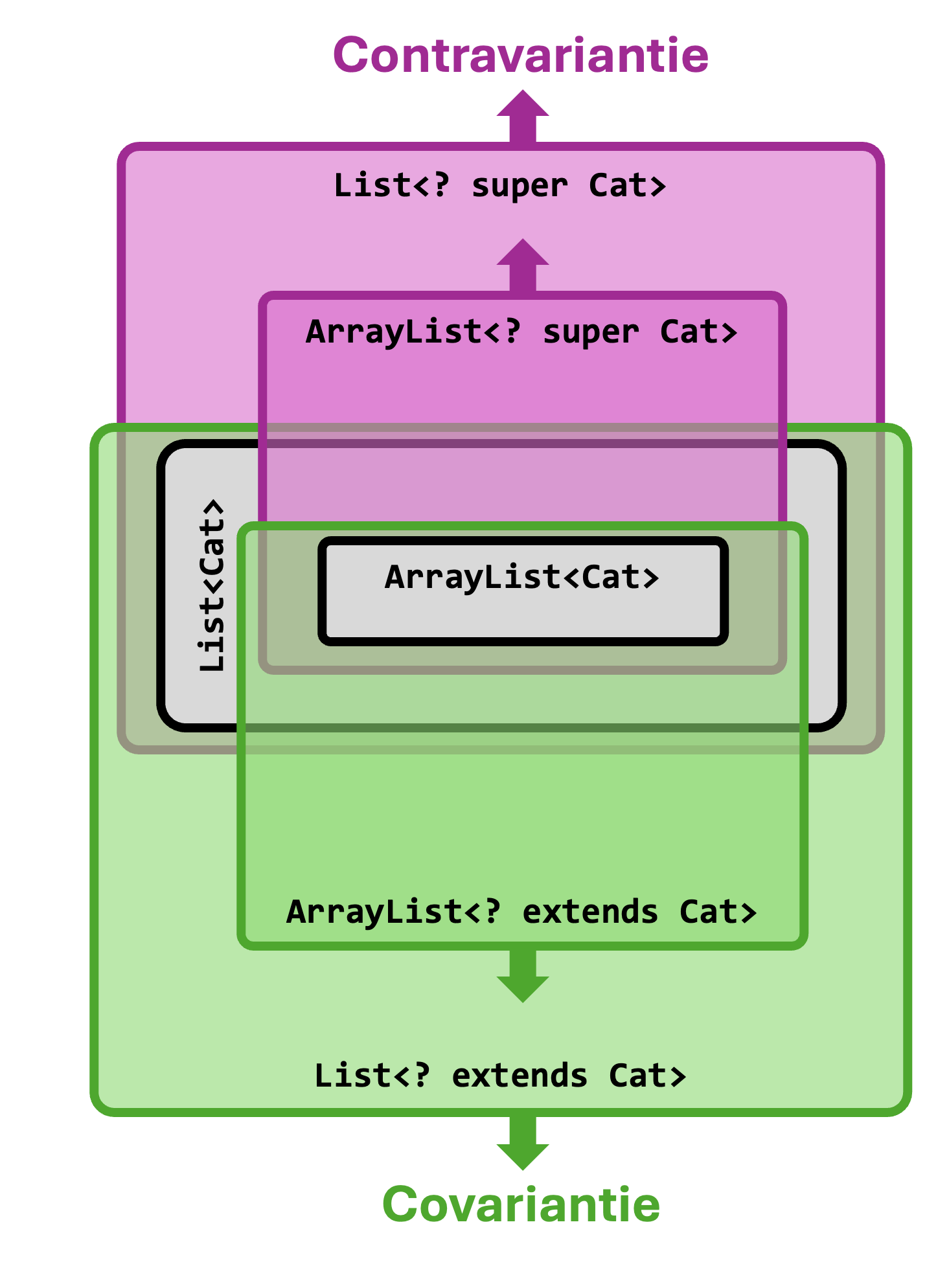
Het lijkt intuïtief misschien logisch dat ArrayList<Cat> ook een subtype moet zijn van ArrayList<Animal>.
Een lijst van katten lijkt tenslotte toch een speciaal geval te zijn van een lijst van dieren?
Maar dat is niet het geval.
Waarom niet?
Stel dat ArrayList<Cat> toch een subtype zou zijn van ArrayList<Animal>. Dan zou volgende code ook geldig zijn:
ArrayList<Cat>cats=newArrayList<Cat>();ArrayList<Animal>animals=cats;// <- dit zou geldig zijn (maar is het niet!)Dogdog=newDog();animals.add(dog);//<-OOPS:erzitnueenhondindelijstvankatten🙁
Je zou dus honden kunnen toevoegen aan je lijst van katten zonder dat de compiler je waarschuwt, en dat is niet gewenst.
Om die reden beschouwt Java ArrayList<Cat> dus niet als subtype van ArrayList<Animal>, ondanks dat Cat wél een subtype van Animal is.
Onthoud
Zelfs als klasse Sub een subtype is van klasse Super, dan is ArrayList<Sub> toch geen subtype van ArrayList<Super>.
Later zullen we zien hoe we hier met wildcards in sommige gevallen wel flexibeler mee kunnen omgaan.
Overerven van een generisch type
Hierboven gebruikten we vooral ArrayList als voorbeeld van een generische klasse.
We hebben echter ook gezien dat je zelf generische klassen kan definiëren, en daarvan kan je uiteraard ook overerven.
Bij de definitie van een subklasse moet je voor de generische parameter van de superklasse een waarde (type) meegeven. Je kan ervoor kiezen om je subklasse zelf generisch te maken (door opnieuw een generische parameter te introduceren), of om een vooraf bepaald type mee te geven.
Bijvoorbeeld:
De superklasse Super heeft een generische parameter T.
De subklasse SubForAnimal definieert zelf een generische parameter A (hier met begrenzing), en gebruikt parameter A als type voor T uit de superklasse.
De klasse SubForCat tenslotte definieert zelf geen nieuwe generische parameter, maar geeft het type Cat op als type voor parameter A uit diens superklasse.
Een interface kan je zien als een abstracte klasse waarvan alle methodes abstract zijn. Het defineert alle methodes die geïmplementeerd moeten worden, maar bevat zelf geen implementatie. ↩︎
7.4.3 Wildcards
We zagen eerder dat de types List<Dog> en List<Animal> niets met elkaar te maken hebben, ondanks het feit dat Dog een subtype is van Animal.
Dat geldt in het algemeen voor generische types.
Als beide generische parameters hetzelfde type hebben, bestaat er wel een overervingsrelatie. Bijvoorbeeld, in volgende situatie:
is AnimalShelter<Dog> wel degelijk een subtype van Shelter<Dog>, om dezelfde reden dat ArrayList<Dog> een subtype is van List<Dog>.
Volgende toekenning en methode-oproep zijn dus toegelaten:
Dat komt omdat AnimalShelter een subtype is van Shelter, en de generische parameter bij beiden hetzelfde is (Dog).
Als de generische parameters verschillend zijn, is er echter geen overervingsrelatie.
Bijvoorveeld, tussen AnimalShelter<Cat> en Shelter<Animal> is er geen overervingsrelatie.
Ook is Shelter<Cat> geen subtype van Shelter<Animal>.
Het volgende is bijgevolg niet toegelaten:
Shelter<Animal>s=newAnimalShelter<Cat>();// NIET toegelatenpublicvoidprotectAnimal(Shelter<Animal>s){...}AnimalShelter<Cat>animalShelter=newAnimalShelter<Cat>();// wel OK!protectAnimal(animalShelter);//NIETtoegelaten
Onthoud
In het algemeen: als class Sub<T> extends Super<T>, dan is Sub<SomeClass> is een subklasse van Super<SomeClass>, maar niet van Super<OtherClass>, zélfs niet als SomeClass een subtype is van OtherClass.
In sommige situaties willen we wel zo’n overervingsrelatie kunnen maken.
We bekijken daarvoor twee soorten relaties, namelijk covariantie en contravariantie.
Notitie
Opgelet: Zowel covariantie als contravariantie gaan enkel over het gebruik van generische klassen.
Meer bepaald beïnvloeden ze wanneer twee generische klassen door de compiler als subtype van elkaar beschouwd worden, wat van belang is voor toekenningen en parameters bij methode-oproepen.
Dat staat los van de definitie van een generische klasse — die definities (en bijhorende begrenzing) blijven onveranderd!
Covariantie (extends)
Wat als we een methode copyFromTo willen schrijven die de dieren uit een gegeven (bron-)lijst toevoegt aan een andere (doel-)lijst van dieren? Bijvoorbeeld:
publicstaticvoidcopyFromTo(ArrayList<Animal>source,ArrayList<Animal>target){for(Animala:source){target.add(a);}}ArrayList<Animal>animals=newArrayList<>();ArrayList<Cat>cats=/* ... */ArrayList<Dog>dogs=/* ... *//* ... */copyFromTo(dogs,animals);// niet toegelaten 🙁copyFromTo(cats,animals);//niettoegelaten🙁
Volgens de regels die we hierboven gezien hebben, kunnen we deze methode niet gebruiken om de dieren uit een lijst van honden (ArrayList<Dog>) of katten (ArrayList<Cat>) te kopiëren naar een lijst van dieren (ArrayList<Animal>).
Maar dat lijkt wel een zinvolle operatie.
Een oplossing kan zijn om verschillende versies van de methode te schrijven:
Merk op dat de oproep target.add(cat), alsook die met dog en bird, toegelaten is, omdat Cat, Dog en Bird subtypes zijn van Animal.
Maar dan lopen we opnieuw tegen het probleem van gedupliceerde code aan.
Een eerste oplossing daarvoor is een generische methode, met een generische parameter die begrensd is (T extends Animal):
Dat werkt, maar de generische parameter T wordt slechts eenmaal gebruikt, namelijk bij de parameter ArrayList<T> source.
In zo’n situatie kunnen we ook gebruik maken van het wildcard-type <? extends X>.
We kunnen bovenstaande methode dus ook zonder generische parameter <T> schrijven als volgt:
Het type ArrayList<? extends Animal> staat dus voor “elke ArrayList waar het element-type een (niet nader bepaald) subtype is van Animal”.
Je kan dit ook bekijken alsof het type ArrayList<? extends Animal> staat voor de hele verzameling van types ArrayList<Animal>, ArrayList<Mammal>, ArrayList<Cat>, ArrayList<Dog>, alsook elke andere lijst van dieren.
Dit heet covariantie: omdat Cat een subtype is van Animal, is ArrayList<Cat> een subtype van ArrayList<? extends Animal>.
De ‘co’ in covariantie wijst erop dat de overervingsrelatie tussen Cat en Animal in dezelfde richting loopt als die tussen ArrayList<Cat> en ArrayList<? extends Animal> (in tegenstelling tot contravariantie, wat zodadelijk aan bod komt).
Dat zie je op de afbeelding hieronder:
Tenslotte kan je in Java ook <?> schrijven (bijvoorbeeld ArrayList<?>); dat is een verkorte notatie voor ArrayList<? extends Object>. Je interpreteert ArrayList<?> dus als een lijst van een willekeurig maar niet gekend type. Merk op dat ArrayList<?> dus niet hetzelfde is als ArrayList<Object>. Een ArrayList<Cat> is een subtype van ArrayList<?>, maar niet van ArrayList<Object>.
Hou er ook rekening mee dat elk voorkomen van ? voor een ander type staat (of kan staan). Hetvolgende kan dus niet:
omdat de eerste ArrayList<? extends Mammal> (source) bijvoorbeeld een ArrayList<Cat> kan zijn, en de tweede (target) een ArrayList<Dog>. Als je de types van beide parameters wil linken aan elkaar, moet je een generische methode gebruiken (zoals we eerder gezien hebben):
De lijst-variabele is gedeclareerd als een ArrayList met elementen van een ongekend type. Op basis van het type van de variabele kan de compiler niet afleiden dat er Strings toegevoegd mogen worden aan de lijst (het zou evengoed een ArrayList van Animals kunnen zijn).
Het feit dat lijst onmiddellijk geinititialiseerd werd met een ArrayList<String> doet hier niet terzake; enkel het type bij de declaratie van lijst is van belang.
Onthoud
Het type ArrayList<? extends Mammal> staat voor de verzameling van types ArrayList<Mammal>, ArrayList<Cat>, ArrayList<Dog>, en elk ander type dat overerft van Mammal.
Contravariantie (super)
Wat als we een methode willen die de objecten uit een gegeven bronlijst van katten kopieert naar een doellijst van willekeurige dieren? Bijvoorbeeld:
publicstaticvoidcopyFromCatsTo(ArrayList<Cat>source,ArrayList<Animal>target){for(Catcat:source){target.add(cat);}}ArrayList<Cat>cats=/* ... */ArrayList<Cat>otherCats=newArrayList<>();ArrayList<Mammal>mammals=newArrayList<>();ArrayList<Animal>animals=newArrayList<>();copyFromTo(cats,otherCats);// niet toegelaten 🙁copyFromTo(cats,mammals);// niet toegelaten 🙁copyFromTo(cats,animals);//OK👍
De eerste twee copyFromTo-regels zijn niet toegelaten, maar zouden opnieuw erg nuttig kunnen zijn.
Co-variantie met extends helpt ook niet (target zou dan immers ook een ArrayList<Dog> kunnen zijn):
publicstaticvoidcopyFromCatsTo(ArrayList<Cat>source,ArrayList<?extendsAnimal>target){for(Catcat:source){target.add(cat);}// ook niet toegelaten 🙁}
En aparte methodes schrijven leidt opnieuw tot code-duplicatie:
Zou het nuttig zijn om een methode copyFromCatsToBirds(ArrayList<Cat> source, ArrayList<Bird> target) te voorzien? Waarom (niet)?
De oplossing in dit geval is gebruik maken van het wildcard-type <? super T>.
Het type ArrayList<? super Cat> staat dus voor “elke ArrayList waar het element-type een supertype is van Cat” (inclusief het type Cat zelf).
Of nog: ArrayList<? super Cat> staat voor de verzameling van types ArrayList<Cat>, ArrayList<Mammal>, ArrayList<Animal>, en ArrayList<Object>, alsook elke andere ArrayList met een supertype van Cat als element-type.
copyFromCatsTo_wildcard(cats,otherCats);// OK 👍copyFromCatsTo_wildcard(cats,mammals);// OK 👍copyFromCatsTo_wildcard(cats,animals);//OK👍
Dit heet contravariantie: hoewel Cat een subtype is van Animal, is ArrayList<? super Cat> een supertype vanArrayList<Animal>.
De ‘contra’ in contravariantie wijst erop dat de overervingsrelatie tussen Cat en Animal in de omgekeerde richting loopt als die tussen ArrayList<? super Cat> en ArrayList<Animal>.
Bekijk volgende figuur aandachtig:
Als we ook ArrayList<Mammal>, ArrayList<? super Mammal>, en ArrayList<? super Animal> toevoegen aan het plaatje, ziet dat er als volgt uit:
graph BT
ALCat["ArrayList#lt;Cat>"]
ALsuperCat["ArrayList#lt;? super Cat>"]
ALsuperMammal["ArrayList#lt;? super Mammal>"]
ALsuperAnimal["ArrayList#lt;? super Animal>"]
ALMammal["ArrayList#lt;Mammal>"]
ALAnimal["ArrayList#lt;Animal>"]
ALCat --> ALsuperCat
ALAnimal --> ALsuperAnimal
ALMammal --> ALsuperMammal
ALsuperAnimal --> ALsuperMammal
ALsuperMammal --> ALsuperCat
Cat --> Mammal
Mammal --> Animal
classDef cat fill:#f99,stroke:#333,stroke-width:4px;
classDef mammal fill:#9f9,stroke:#333,stroke-width:4px;
classDef animal fill:#99f,stroke:#333,stroke-width:4px;
class ALCat,ALsuperCat,Cat cat;
class ALMammal,Mammal,ALsuperMammal mammal;
class ALAnimal,Animal,ALsuperAnimal animal;
Aan de hand van de kleuren kan je snel zien dat de overervingsrelatie links en rechts inderdaad omgekeerd verlopen.
Onthoud
Het type ArrayList<? super Mammal> staat voor de verzameling van types ArrayList<Mammal>, ArrayList<Animal>, ArrayList<Object>, en elk ander type dat een superklasse (of interface) is van Mammal.
Covariantie of contravariantie: PECS
Als we covariantie en contravariantie combineren, krijgen we volgend beeld (we focussen op de extends- en super-relatie vanaf Mammal):
Hier zien we dat ArrayList<? extends Mammal> (covariant) als subtypes ArrayList<Mammal> en ArrayList<Cat> heeft.
Het contravariante ArrayList<? super Mammal> heeft óók ArrayList<Mammal> als subtype, maar ook ArrayList<Animal>.
Hoe weet je nu wanneer je wat gebruikt als type voor een parameter? Wanneer kies je <? extends T>, en wanneer <? super T>?
Een goede vuistregel is het acroniem PECS, wat staat voor Producer Extends, Consumer Super.
Dus:
Wanneer het object gebruikt wordt als een producent van T’s (met andere woorden, het object is een levancier van T-objecten voor jouw code, die ze vervolgens gebruikt), gebruik je <? extends T> (covariantie). Dat is logisch: als jouw code met aangeleverde T’s omkan, dan kan jouw code ook om met de aanlevering van een subklasse van T (basisprincipe objectgeoriënteerd programmeren).
Wanneer het object gebruikt wordt als een consument van T’s (met andere woorden, het neemt T-objecten aan van jouw code), gebruik je <? super T> (contravariantie). Ook dat is logisch: een object dat beweert om te kunnen met elke superklasse van T moet zeker overweg kunnen met een T die jouw code aanlevert.
Wanneer het object zowel als consument als als producent gebruikt wordt, gebruik je gewoon <T> (dus geen co- of contra-variantie, maar invariantie). Er is dan weinig tot geen flexibiliteit meer in het type.
Onthoud
Is de parameter uitsluitend een producent van T’s? Gebruik dan <? extends T>.
Is de parameter uitsluitend een consument van T’s? Gebruik dan <? super T>.
Is de parameter zowel een producent als consument? Gebruik dan gewoon <T>.
Een voorbeeld om PECS toe te passen: we willen een methode copyFromTo die zo flexibel mogelijk is, om elementen uit een lijst van zoogdieren te kopiëren naar een andere lijst.
Met deze methode kunnen we nu alle zinvolle operaties uitvoeren, terwijl de zinloze operaties tegengehouden worden door de compiler:
ArrayList<Cat>cats=/* ... */ArrayList<Dog>dogs=/* ... */ArrayList<Bird>birds=/* ... */ArrayList<Mammal>mammals=/* ... */ArrayList<Animal>animals=/* ... */copyMammalsFromTo(cats,animals);// OK 👍copyMammalsFromTo(cats,mammals);// OK 👍copyMammalsFromTo(cats,cats);// OK 👍copyMammalsFromTo(mammals,animals);// OK 👍copyMammalsFromTo(cats,dogs);// compiler error (Dog is geen supertype van Mammal) 👍copyMammalsFromTo(birds,animals);//compilererror(BirdisgeensubtypevanMammal)👍
Merk op dat het type Mammal in onze laatste versie van copyMammalsFromTo hierboven eigenlijk onnodig is. We kunnen de methode nog verder veralgemenen door er een generische methode van te maken, die werkt voor alle lijsten (niet enkel lijsten van zoogdieren):
Met deze versie kunnen we nu bijvoorbeeld ook Birds kopiëren naar een lijst van dieren:
copyFromTo(birds,animals);//OK👍
Opmerking
Wanneer een parameter zowel een producent als een consument is, gebruik je geen wildcards.
De generische parameter heet dan invariant.
Bijvoorbeeld:
publicstatic<T>voidreverse(List<T>list){intleft=0;intright=list.size()-1;while(left<right){// Producent (get)Ttemp=list.get(left);// Consumer (set)list.set(left,list.get(right));list.set(right,temp);left++;right--;}}
Arrays en type erasure
In tegenstelling tot ArrayLists (en andere generische types), beschouwt Java arrays wél altijd als covariant.
Dat betekent dat Cat[] een subtype is van Animal[].
Volgende code compileert dus (maar gooit een uitzondering bij het uitvoeren):
De reden hiervoor is, in het kort, dat informatie over generics gewist wordt bij het compileren van de code.
Dit heet type erasure.
In de gecompileerde code is een ArrayList<Animal> en ArrayList<Cat> dus exact hetzelfde.
Er kan dus, tijdens de uitvoering, niet gecontroleerd worden of je steeds het juiste type gebruikt.
Daarom moet de compiler dat doen, en die neemt het zekere voor het onzekere: alles wat mogelijk fout zou kunnen aflopen, wordt geweigerd.
Bij arrays wordt er wel type-informatie bijgehouden na het compileren, en kan dus tijdens de uitvoering nog gecontroleerd worden of je geen elementen met een ongeldig type toevoegt. De compiler hoeft het niet af te dwingen — maar het wordt wel nog steeds gecontroleerd tijdens de uitvoering, en kan leiden tot een exception.
Aandachtspunten
Enkel bij generische types!
Tenslotte nog een opmerking (op basis van vaak gemaakte fouten op examens).
Co- en contra-variantie (extends, super, en wildcards dus) zijn enkel van toepassing op generische types.
Alles wat we hierboven gezien hebben is dus enkel nuttig op plaatsen waar je een generisch type (List<T>, Food<T>, …) gebruikt voor een parameter, terugkeertype, variabele, ….
Dergelijke types kan je met behulp van co-/contra-variantie en wildcards verrijken tot bijvoorbeeld List<? extends T>, Food<? super T>, …
Maar je kan deze constructies niet gebruiken op plaatsen waar een gewoon type verwacht wordt, bijvoorbeeld bij een parameter of terugkeertype.
Onderstaande regels code zijn dus allemaal ongeldig:
Deze methode kan óók al opgeroepen worden met een Cat-object, Dog-object, of elk ander type Mammal als argument.
Je hebt hier geen co- of contra-variantie van generische types nodig; je maakt gewoon gebruik van overerving uit objectgeoriënteerd programmeren.
Onthoud
Wildcards (?), co-variantie (? extends) en contra-variantie (? super) zijn enkel van toepassing bij generische types! Je kan ze dus niet gebruiken als een op zichzelf staand type. Je kan ze ook niet gebruiken bij de definitie van een nieuwe generische parameter (voor een klasse of methode), maar enkel bij het gebruik ervan.
Bounds vs. co-/contravariantie en wildcards
Tot slot is het nuttig om nog eens te benadrukken dat er een verschil is tussen het begrenzen van een generische parameter (met extends) enerzijds, en het gebruik van co-variantie, contra-variantie en wildcards (? extends T, ? super T) anderzijds. Het feit dat extends in beide gevallen gebruikt wordt, kan misschien tot wat verwarring leiden.
Een begrenzing (via <T extends SomeClass>) beperkt welke types geldige waarden zijn voor de type-parameter T. Dus: elke keer wanneer je een concreet type wil meegeven in de plaats van T moet dat type voldoen aan bepaalde eisen.
Je kan zo’n begrenzing enkel aangeven op de plaats waar je een nieuwe generische parameter (T) introduceert (dus bij een nieuwe klasse-definitie of methode-definitie).
Bijvoorbeeld: class Food<T extends Animal> laat later enkel toe om Food<X> te schrijven als type wanneer X ook een subtype is van Animal.
Door co- en contra-variantie (met <? extends X> en <? super X>) te gebruiken verbreed je de toegelaten types.
Een methode-parameter met als type Food<? extends Animal> laat een Food<Animal> toe als argument, maar ook een Food<Cat> of Food<Dog>.
Omgekeerd zal een parameter met als type Food<? super Cat> een Food<Cat> toelaten, maar ook een Food<Animal>.
Er wordt in beide gevallen dus meer toegelaten, wat meer flexibiliteit biedt.
Je kan co- en contravariantie toepassen op elke plaats waar je een generisch type gebruikt (en waar dat gepast is volgens de PECS regels).
Het kan dus perfect zijn dat je de ene keer in je code eens Food<Cat> gebruikt, ergens anders Food<? extends Cat>, en nog ergens anders Food<? super Cat>.
Bij begrenzing is dat niet zo; dat legt de grenzen eenmalig vast, en die moeten overal gerespecteerd worden waar het generisch type gebruikt wordt.
Onthoud
Een begrenzing (T extends X) is een eenmalige beperking op het type dat gebruikt kan worden als waarden voor een nieuw geïntroduceerde generische parameter. Dit kan enkel voorkomen in de definitie van een nieuwe generische parameter (bij een generische klasse of methode).
Co-en contravariantie (? extends X, ? super X) met wildcard ?versoepelen de types die aanvaard worden door de compiler. Ze komen enkel voor op plaatsen waar een generisch type gebruikt wordt.
Arrays met generisch type
Als je een array wil maken van een generisch type, laat de Java-compiler dat niet toe:
classMyClass<T>{privateT[]array;publicMyClass(){array=newT[10];// <-- niet toegelaten ☹️}}
De reden is opnieuw type erasure.
Aangezien arrays covariant zijn, moet tijdens de uitvoering gecontroleerd kunnen worden of objecten die in de array terechtkomen een geschikt type hebben.
Aangezien generische parameters verwijderd worden door de compiler, kan dat niet.
Een oplossing voor bovenstaand probleem is om een cast toe te voegen. Met een @SuppressWarning annotatie kan je de waarschuwing die door de compiler gegeven wordt negeren.
Lijn 3 OK: yourPlace heeft type Vehicle, en Bike erft over van Vehicle(de naam van de variabele is wel slecht gekozen)
Lijn 4 OK: ArrayList<Vehicle> (hier ArrayList<>) is een subtype van Collection<Vehicle>
Lijn 5 OK: vehicles kan om het even welk Vehicle bevatten, dus ook een Motorized (type van myCar)
Lijn 6 OK: ArrayList<Car> is een subtype van List<Car>
Lijn 7 niet OK: List<Car> is geen subtype van List<Vehicles>
Lijn 8 OK: ArrayList<Car> is een subtype van List<? extends Motorized>
Lijn 9 niet OK: motorized is een lijst van een onbekend type gemotoriseerde voertuigen; we kunnen daar geen auto aan toevoegen.
Covariantie en contravariantie 1
Maak een schema met de overervingsrelaties tussen
List<Animal>
List<? super Animal>
List<? extends Animal>
List<Cat>
List<? extends Cat>
List<? super Cat>
Antwoord
graph BT
LA["List#lt;Animal>"]
LSA["List#lt;? super Animal>"]
LEA["List#lt;? extends Animal>"]
LC["List#lt;Cat>"]
LSC["List#lt;? super Cat>"]
LEC["List#lt;? extends Cat>"]
LA --> LSA
LA --> LSC
LA --> LEA
LC --> LSC
LC --> LEC
LC --> LEA
LSA --> LSC
LEC --> LEA
In onderstaande figuur worden de verschillende types weergegeven door verzamelingen: een deelverzameling betekent dat het binnenste type overerft van het buitenste.
Covariantie en contravariantie 2
Maak een schema met de overervingsrelaties tussen
List<Cat>
ArrayList<Cat>
List<? super Cat>
ArrayList<? super Cat>
List<? extends Cat>
ArrayList<? extends Cat>
Antwoord
graph BT
LC["List#lt;Cat>"]
LSC["List#lt;? super Cat>"]
LEC["List#lt;? extends Cat>"]
AC["ArrayList#lt;Cat>"]
ASC["ArrayList#lt;? super Cat>"]
AEC["ArrayList#lt;? extends Cat>"]
AC --> LC
AC --> ASC
AC --> LSC
AC --> AEC
AC --> LEC
LC --> LSC
LC --> LEC
AEC --> LEC
ASC --> LSC
In onderstaande figuur worden de verschillende types weergegeven door verzamelingen: een deelverzameling betekent dat het binnenste type overerft van het buitenste.
Repository
Schrijf een generische klasse Repository die een repository van objecten voorstelt. De objecten hebben ook een ID. Zowel het type van objecten als het type van de ID moeten generische parameters zijn.
Definieer en implementeer volgende methodes (maak gebruik van een ArrayList):
add(id, obj): toevoegen van een object
findById(id): opvragen van een object aan de hand van de id
findAll(): opvragen van alle objecten in de repository
update(id, obj): vervangen van een object met gegeven id door het meegegeven object
remove(id): verwijderen van een object aan de hand van een id
Shop
Maak een klasse Shop die een winkel voorstelt die items (subklasse van StockItem) aankoopt.
Af en toe wordt er een inventaris opgemaakt van alle items die op stock zijn.
Een Shop-object wordt geparametriseerd met het type items dat aangekocht kan worden.
We beschouwen hier Fruit en Electronics; daarmee kunnen we dus een fruitwinkel (Shop<Fruit>) en elektronica-winkel (Shop<Electronics>) maken.
De Shop-klasse heeft drie methodes:
buy, die een lijst van items toevoegt aan de stock;
addStockToInventory, die de lijst van items uit de stock toevoegt aan de meegegeven inventaris-lijst (de items blijven bewaard in de stock);
stockSize() die het huidig aantal items in de stock toevoegt.
Daarnaast maak je een statische methode merge waarmee je twee Shop-objecten kan samenvoegen tot een nieuw Shop-object.
De twee Shops die samengevoegd worden hoeven niet hetzelfde type items te hebben. Je kan bijvoorbeeld een fruitwinkel en electronicawinkel samenvoegen tot een supermarkt waar elk soort StockItem verkocht kan worden.
Na een merge is de stock verdwenen uit de oorspronkelijke shops en terechtgekomen in de nieuwe (samengevoegde) winkel.
In de startcode vind je reeds een implementatie van een abstracte klasse StockItem, Fruit, en subklassen Apple en Orange.
Daarnaast is er ook een abstracte klasse Electronics, met als subklasse Smartphone.
Zorg dat onderstaande code (ongewijzigd) compileert en dat de test slaagt:
Vul de types en generische parameters aan op de 7 genummerde plaatsen zodat onderstaande code en main-methode compileert (behalve de laatste regel van de main-methode) en voldaan is aan volgende voorwaarden:
Elk actie-type kan enkel uitgevoerd worden door een bepaald karakter-type. Bijvoorbeeld: een FightAction kan enkel uitgevoerd worden door een karakter dat CanFight implementeert.
doAction mag enkel opgeroepen worden met een actie die uitgevoerd kan worden door alle karakters in de meegegeven lijst.
Als er op een bepaalde plaats geen type of generische parameter nodig is, vul je $\emptyset$ in.
Verklaar je keuze voor de combinatie van (5), (6), en (7).
interfaceCharacter{}interfaceCanFightextendsCharacter{}recordWarrior()implementsCanFight{}recordKnight()implementsCanFight{}recordWizard()implementsCharacter{}// kan niet vechteninterfaceAction<___/* 1 */___>{voidexecute(___/* 2 */____character);}classFightActionimplementsAction<___/* 3 */_____>{@Overridepublicvoidexecute(___/* 4 */______character){System.out.println(character+" fights!");}}classGameEngine{public<___/* 5 */______>voiddoAction(List<___/* 6 */____>characters,Action<___/* 7 */____>action){for(varcharacter:characters){action.execute(character);}}}publicstaticvoidmain(String[]args){varengine=newGameEngine();Action<CanFight>fight=newFightAction();List<Warrior>warriors=List.of(newWarrior(),newWarrior());engine.doAction(warriors,fight);List<Wizard>wizards=List.of(newWizard());engine.doAction(wizards,fight);// deze regel mag NIET compileren}
Antwoord
1: C extends Character : acties kunnen enkel uitgevoerd worden door subtypes van Character
2: C: C is het type van Character dat de actie zal uitvoeren
3: CanFight: FightAction is enkel mogelijk voor characters die CanFight implementeren
4: CanFight: aangezien de generische paremeter C van superinterface Action geinitialiseerd werd met CanFight, moet hier ook CanFight gebruikt worden.
5: T extends Character: we noemen T het type van de objecten in de meegeven lijst; we hebben hier een begrenzing nodig (want we willen enkel subtypes van Character toelaten)
6: T: lijst van T’s, zoals verondersteld in 5
7: ? super T: de meegegeven actie moet een actie zijn die door alle T’s uitgevoerd kan worden (dus door T of een van de supertypes van T).
Redenering met behulp van PECS: de meegegeven actie gebruikt/consumeert het character, dus super.
Alternatieve keuze voor 5/6/7:
5: T extends Character: we noemen T het type dat bij de actie hoort; we hebben hier een begrenzing nodig (want we willen enkel subtypes van Character toelaten)
6: ? extends T: lijst van T’s of subtypes ervan.
Redenering met behulp van PECS: de lijst levert/produceert de characters, dus extends.
7: T: het type van de actie, zoals verondersteld in 5
Extra oefeningen
SuccessOrFail
Schrijf een generische klasse (of record) SuccessOrFail die een object voorstelt dat precies één element bevat.
Dat element heeft 1 van 2 mogelijke types (die types zijn generische parameters).
Het eerste type stelt het type van een succesvol resultaat voor; het tweede type is dat van een fout.
Je kan objecten enkel aanmaken via de statische methodes success en fail.
Een voorbeeld van tests voor die klasse vind je hieronder:
@Testpublicvoidsuccess(){SuccessOrFail<String,Exception>result=SuccessOrFail.success("This is the result");assertThat(result.isSuccess()).isTrue();assertThat(result.successValue()).isEqualTo("This is the result");}@Testpublicvoidfailure(){SuccessOrFail<String,Exception>result=SuccessOrFail.fail(newIllegalStateException());assertThat(result.isSuccess()).isFalse();assertThat(result.failValue()).isInstanceOf(IllegalStateException.class);}
Functie compositie
Java bevat een ingebouwde interface java.util.function.Function<T, R>, wat een functie voorstelt met één parameter van type T, en een resultaat van type R. Deze interface voorziet 1 methode R apply(T value) om de functie uit te voeren.
Schrijf nu een generische methode compose die twee functie-objecten als parameters heeft, en als resultaat een nieuwe functie teruggeeft die de compositie voorstelt: eerst wordt de eerste functie uitgevoerd, en dan wordt de tweede functie uitgevoerd op het resultaat van de eerste.
Dus: voor functies
Function<A,B>f1=...Function<B,C>f2=...
moet compose(f1, f2) een Function<A, C> teruggeven, die als resultaat f2.apply(f1.apply(a)) teruggeeft.
Pas de PECS-regel toe om ook functies te kunnen samenstellen die niet exact overeenkomen qua type.
Bijvoorbeeld, volgende code moet compileren en de test moet slagen:
Schrijf een generische klasse (of record) Maybe die een object voorstelt dat nul of één waarde van een bepaald type kan bevatten.
Dat type wordt bepaald door een generische parameter. Je kan Maybe-objecten enkel aanmaken via de statische methodes some en none.
Hieronder vind je twee tests:
Maak de print-methode hieronder ook generisch, zodat deze niet enkel werkt voor een Maybe<String> maar ook voor andere types dan String.
classMaybePrint{publicstaticvoidprint(Maybe<String>maybe){if(maybe.hasValue()){System.out.println("Contains a value: "+maybe.getValue());}else{System.out.println("No value :(");}}publicstaticvoidmain(String[]args){Maybe<String>maybeAString=Maybe.some("yes");Maybe<String>maybeAnotherString=Maybe.none();print(maybeAString);print(maybeAnotherString);}}
Voeg aan Maybe een generische methode map toe die een java.util.function.Function<T, R>-object als parameter heeft, en die een nieuw Maybe-object teruggeeft, met daarin het resultaat van de functie toegepast op het element als er een element is, of een leeg Maybe-object in het andere geval.
Zie de tests hieronder voor een voorbeeld van hoe deze map-functie gebruikt wordt:
(optioneel) Herschrijf Maybe als een sealed interface met twee record-subklassen None en Some.
Geef een voorbeeld van hoe je deze klasse gebruikt met pattern matching.
Kan je ervoor zorgen dat je getValue() nooit kan oproepen als er geen waarde is (compiler error)?
Info
Java bevat een ingebouwd type gelijkaardig aan de Maybe-klasse uit deze oefening, namelijk Optional<T>.
Animal food
Dit is een uitdagende oefening, voor als je je kennis over generics echt wil testen.
Voeg generics (met grenzen/bounds) toe aan de code hieronder, zodat de code (behalve de laatste regel) compileert,
en de compiler enkel toelaat om kattenvoer te geven aan katten, en hondenvoer aan honden:
publicclassAnimalFood{staticclassAnimal{publicvoideat(Foodfood){System.out.println(this.getClass().getSimpleName()+" says 'Yummie!'");}}staticclassMammalextendsAnimal{publicvoiddrink(Milkmilk){this.eat(milk);}}staticclassCatextendsMammal{}staticclassKittenextendsCat{}staticclassDogextendsMammal{}staticclassFood{}staticclassMilkextendsFood{}staticclassMain{publicstaticvoidmain(String[]args){FoodcatFood=newFood();MilkcatMilk=newMilk();FooddogFood=newFood();MilkdogMilk=newMilk();Catcat=newCat();Dogdog=newDog();Kittenkitten=newKitten();cat.eat(catFood);// OK 👍cat.drink(catMilk);// OK 👍dog.eat(dogFood);// OK 👍dog.drink(dogMilk);// OK 👍kitten.eat(catFood);// OK 👍kitten.drink(catMilk);// OK 👍cat.eat(dogFood);// <- moet een compiler error geven! ❌kitten.eat(dogFood);// <- moet een compiler error geven! ❌kitten.drink(dogMilk);// <- moet een compiler error geven! ❌}}}
(Hint: Begin met het type Food te parametriseren met een generische parameter die het Animal-type voorstelt dat dit voedsel eet.)
Self-type
Dit is een uitdagende oefening, voor als je je kennis over generics echt wil testen.
Heb je je al eens afgevraagd hoe assertThat(obj) uit AssertJ werkt?
Afhankelijk van het type van obj dat je meegeeft, worden er andere assertions beschikbaar die door de compiler aanvaard worden:
// een List<String>List<String>someListOfStrings=List.of("hello","there","how","are","you");assertThat(someListOfStrings).isNotNull().hasSize(5).containsItem("hello");// een StringStringsomeString="hello";assertThat(someString).isNotNull().isEqualToIgnoringCase("hello");// een IntegerintsomeInteger=4;assertThat(someInteger).isNotNull().isGreaterThan(4);assertThat(someInteger).isNotNull().isEqualToIgnoringCase("hello");//<=compileertniet❌
Sommige assertions (zoals isNotNull) zijn echter generiek, en wil je slechts op 1 plaats implementeren.
Probeer zelf een assertThat-methode te schrijven die werkt zoals bovenstaande, maar waar isNotNull slechts op 1 plaats geïmplementeerd is.
De assertThat-methode moet een Assertion-object teruggeven, waarop de verschillende methodes gedefinieerd zijn afhankelijk van het type dat meegegeven wordt aan assertThat.
Hint 1: maak verschillende klassen, bijvoorbeeld ListAssertion, StringAssertion, IntegerAssertion die de type-specifieke methodes bevatten. Begin met isNotNull toe te voegen aan elk van die klassen (dus door de implementatie te kopiëren).
Hint 2: in een zogenaamde ‘fluent interface’ geeft elke operatie zoals isNotNull en hasSize het this-object op het einde terug (return this), zodat je oproepen na elkaar kan doen. Bijvoorbeeld .isNotNull().hasSize(5).
Hint 3: maak nu een abstracte klasse GenericAssertion die isNotNull bevat, en waarvan de andere assertions overerven. Verwijder de andere implementaties van isNotNull.
Hint 4: In isNotNull is geen informatie beschikbaar over het type dat gebruikt moet worden als terugkeertype van isNotNull. assertThat(someString).isNotNull() moet bijvoorbeeld opnieuw een StringAssertion teruggeven. Dat kan je oplossen met generics, en een abstracte methode die het juiste object teruggeeft.
Hint 5: Je zal een zogenaamd ‘self-type’ moeten gebruiken. Dat is een generische parameter die wijst naar de (sub)klasse zelf.
Hint 6: op deze pagina wordt uitgelegd hoe AssertJ dit doet. Probeer eerst zelf, zonder dit te lezen!
7.5 Lambdas
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java lambda’s zijn
in Python: lambda’s (met het keyword lambda) en callables
in C++: lambda expressies, function pointers
in C#: lambda expressies
Daarenboven zijn lambda’s en methode-referenties alomtegenwoordig in zogenaamde pure functionele programmeertalen (bv. Haskell).
Wat en waarom?
Met lambda-functies kun je in Java kort en bondig een functie schrijven zonder de functie een naam te geven.
Dat is handig als je de functie maar op één plaats zal gebruiken.
Bijvoorbeeld, stel dat we een record Person hebben:
en we willen die sorteren volgens "Voornaam Achternaam", maar ons Person-record heeft geen methode fullName().
In plaats van die functie te schrijven, enkel voor het sorteren, kunnen we een lambda-functie gebruiken.
Een lambda-functie die de voor- en achternaam van een persoon aan elkaar plakt met een spatie ziet er als volgt uit:
(Personp)->p.firstName()+" "+p.lastName()
De -> wijst op een lambda-functie. Links ervan staan de parameters, rechts de body van de methode.
Je kan met zo’n lambda-functie dan een Comparator maken die gebruikt wordt om een lijst van personen sorteert volgens hun voor- en achternaam:
Exact 1 parameter (haakjes mogen weg als je geen expliciet type schrijft):
x->x*x
Meerdere parameters:
(a,b)->a+b
Body met meerdere statements:
(a,b)->{intsom=a+b;returnsom*2;}
Notitie
Gebruik je een blok-body met { ... }, dan moet je return expliciet schrijven (behalve bij void-lambdas).
Bij een expression-body (x -> x + 1) gebeurt de return impliciet.
Methode-referenties
Methode-referenties zijn een manier om direct te verwijzen naar een reeds bestaande methode, in plaats van er een lambda voor te schrijven.
Waar je een lambda van de vorm (Person p) -> p.age() zou gebruiken, kun je ook gewoon Person::age schrijven.
De :: wijst op een methode-referentie. Links ervan staat de naam van de klasse, rechts de naam van de (bestaande) methode.
Merk op dat er geen haakjes () staan (dus nietPerson::age()). Het is enkel een verwijzing naar de methode; de methode zelf wordt niet meteen opgeroepen.
Een methode-referentie is vooral handig als de lambda precies één methode-aanroep doet.
Achter de schermen gebeurt hetzelfde, maar de code is wat compacter.
Om bijvoorbeeld de lijst people te sorteren volgens hun leeftijd, kan je een methode-referentie gebruiken als volgt:
people.sort(Comparator.comparing(Person::age));
Java kent vier standaardvormen van methode-referenties:
Merk op dat alle variabelen hierboven (toInt, print, lower, emptyList) verwijzen naar een methode (of functie), en niet naar een waarde (int, String, …) zoals je gewoon bent.
Deze variabelen hebben type Function<String, Integer>, Consumer<Object>, etc.
We gaan zodadelijk dieper in op deze types.
Het is erg belangrijk om te begrijpen dat in het voorbeeld hierboven geen van de methodes (parseInt, println, toLowerCase, of de constructor van ArrayList) opgeroepen of uitgevoerd wordt.
We maken enkel de verwijzing naar deze methode, en kennen die toe aan een variabele.
We kunnen deze variabelen nadien wel gebruiken om de methodes effectief uit te voeren, bijvoorbeeld:
ArrayList<String>newList=emptyList.get();// roept constructor van ArrayList opStringelement=lower.apply("HeLLo");// zet "HeLLo" om in "hello"newList.add(element);print.accept(newList.get(0));// print "hello" uitintx=toInt.apply("123");// zet "123" om naar 123print.accept(x);//print123uit
Types van lambda’s en methode-referenties
Omdat Java een sterk getypeerde taal is, moeten lambda-functies en methode-referenties ook een type hebben.
Dat gebeurt door een interface te definiëren.
Functional interface
Elke interface met daarin precies één methode kan automatisch gebruikt worden als type voor lambda-functies en methode-referenties, tenminste als de types van parameters en het resultaat overeen komen.
Als het expliciet de bedoeling is om de interface op deze manier te gebruiken, kan je die interface ook met @FunctionalInterface annoteren; de compiler komt dan klagen als je later een extra methode zou proberen toe te voegen aan die interface.
Bijvoorbeeld:
@FunctionalInterfaceinterfacePersonPredicate{booleantest(Personperson);// slechts één methode (van Person naar boolean)}
In de code hierboven zie je de PersonPredicate-interface, geannoteerd met @FunctionalInterface.
Deze definieert één methode die true of false teruggeeft voor een persoon.
De methode selectPeople hieronder gebruikt de PersonPredicate interface om alle personen te selecteren die voldoen aan de meegegeven voorwaarde.
We overlopen nu vier manieren om de selectPeople methode te gebruiken.
Een eerste manier is een klasse maken (bv. IsAdult) die de interface implementeert, en die nagaat of de persoon meerderjarig is.
Dat werkt, maar is nogal omslachtig, zeker als we dit slechts op 1 plaats nodig hebben:
Een tweede optie is om een anonieme klasse te gebruiken. In het voorbeeld gaat de anonieme klasse na of de achternaam van de persoon begint met “Do”.
Ook dat blijft omslachtig, het bespaart ons enkel de moeite om een naam voor een klasse te verzinnen:
Met lambda-functies kan je dergelijke code veel eenvoudiger schrijven.
In codefragment 3 en 4 hieronder zie je hoe je een lambda-functie kan gebruiken die hetzelfde doet als de vorige voorbeelden, maar dan zonder een klasse te schrijven.
Merk op dat het toegelaten is om de lambda-functies te gebruiken waar een PersonPredicate verwacht wordt.
De twee lambda-functies hieronder zijn inderdaad functies die een Person-object als argument hebben, en een boolean teruggeven, en komen dus qua type overeen met de test-methode in PersonPredicate.
Dat is vooral nuttig als deze methode al bestaat en je er gebruik van wil maken.
Voorgedefinieerde types voor functies
In plaats van zelf een interface zoals PersonPredicate te schrijven, kan je vaak ook beroep doen op een voorgedefinieerde functie-interface.
Je vindt de lijst daarvan in de documentatie.
We lijsten hier de belangrijkste reeds bestaande functionele interfaces op die gebruikt worden:
Function<T, R>: stelt een functie met 1 parameter voor die een T omzet in een R:
Supplier<T>: stelt een operatie zonder parameters voor die een T teruggeeft:
@FunctionalInterfaceinterfaceSupplier<T>{Tget();}
Een invocatie van de supplier mag telkens hetzelfde object teruggeven, maar ook elke keer een ander object en alles daartussenin. Een supplier kan dus beschouwd worden als generator. Bijvoorbeeld:
Op zich maakt het niet uit welke interface er gebruikt wordt, zolang de types van de enige methode erin maar overeenkomen met die van de lambda-expressie.
Bijvoorbeeld, de lambda
(Personp)->p.age()>=18
kan dus overal gebruikt worden waar onze zelfgedefinieerde PersonPredicate-interface verwacht wordt, maar ook overal waar een Predicate<Person> of een Function<Person, Boolean> verwacht wordt.
De compiler gaat enkel na of de types van parameters en resultaat overeenkomen met die van de enige methode in de interface; de naam van de interface en de naam van de methode in deze interface doen niet terzake.
Capturing en ’effectively final’
Een lambda mag variabelen uit de omliggende scope gebruiken.
Dat heet capturing.
Zo’n variabele (minAge hierboven) moet wel effectively final zijn: je mag ze na initialisatie niet meer aanpassen.
Met andere woorden: je zou de variabele final moeten kunnen maken zonder dat dat problemen geeft.
De Java compiler zal zelf uitzoeken of de variabelen die gebruikt worden in een lambda inderdaad effectively final zijn, en een fout geven als dat niet zo is.
Dit voorkomt verwarrende situaties rond toestand en lifetime van variabelen.
Bijvoorbeeld:
Als de code hierboven wel zou compileren, is het niet duidelijk welke leeftijd gebruikt zou moeten worden: 18 of 21?
De makkelijkste manier om hier geen last van te hebben is door geen variabelen te gebruiken die buiten de lambda gedefinieerd worden, en dat is dan ook ten zeerste aanbevolen.
Deze oefening is ook een extra oefening op generics.
Schrijf een generische methode compose die twee functies als parameters heeft, en als resultaat een nieuwe functie teruggeeft die de compositie voorstelt: eerst wordt de eerste functie uitgevoerd, en dan wordt de tweede functie uitgevoerd op het resultaat van de eerste.
Dus: voor functies
Function<A,B>f1=...Function<B,C>f2=...
moet compose(f1, f2) een Function<A, C> teruggeven, die als resultaat f2.apply(f1.apply(a)) teruggeeft.
Pas de PECS-regel toe om ook functies te kunnen samenstellen die niet exact overeenkomen qua type.
Bijvoorbeeld, volgende code moet compileren en de test moet slagen:
Java heeft geen interface voor een functie met 3 parameters.
Definieer zelf een (generische) functionele interface TriFunction die een functie voorstelt met 3 parameters (van een verschillend type).
Definieer een functie zip3 die 3 lijsten als parameters heeft, samen met een TriFunction.
De 3 lijsten moeten even lang zijn.
Deze functie geeft een lijst terug waarvan het i-de element gevormd wordt door de meegegeven tri-functie toe te passen op het i-de element van elk van de drie parameter-lijst.
Een voorbeeld van het gebruik van zip3 om een lijst van personen te maken op basis van een lijst van voornamen, achternamen, en leeftijden:
Schrijf een generische klasse Dispatcher<E> waar klassen zich kunnen inschrijven om op de hoogte gebracht te worden van een event.
Het event heeft generisch type E.
Voorzie twee methodes:
Een methode subscribe waar je een methode kan registreren die opgeroepen moet worden telkens een event E gepubliceerd wordt.
Een methode publish(E event) die alle geregistreerde methodes oproept met het meegegeven event.
Een voorbeeld van het gebruik van de Dispatcher-klasse (met String als event-type):
De concepten in andere programmeertalen die het dichtst aanleunen bij Java streams zijn
ranges in C++
iterators, generators en comprehensions in Python
LINQ in C#
Wat en waarom?
Streams vormen een krachtig concept om efficiënt data te verwerken.
Ze vormen een abstractie voor sequentiële en parallelle operaties op datasets, zoals filteren, transformeren, en aggregeren, zonder de onderliggende datastructuur te wijzigen.
Bovendien maakt het gebruik van streams het mogelijk om declaratief te programmeren: je beschrijft op hoog niveau wát je met de dataset wilt doen, in plaats van stap voor stap te beschrijven hoe dat moet gebeuren.
Een snel voorbeeldje om dat wat concreter te maken is onderstaande code, die streams gebruikt om de gemiddelde leeftijd te berekenen van de eerste 20 meerderjarige Person-objecten in de lijst people (we gaan later dieper in op de details):
Een stream zelf is geen datastructuur of collectie; een stream is een pijplijn — een ketting van operaties die uitgevoerd moeten worden op de data.
Die operaties kunnen de data filteren, transformeren, groeperen, reduceren, …
Een stream stelt dus één grote bewerking voor op de data, samengesteld uit meerdere operaties.
Elke stream bestaat uit 3 delen:
één bron voor de data (een stroom van data, vandaar de naam). Die bron kan een datastructuur zijn (bv. een array, ArrayList, HashSet, …), maar ook andere bronnen zijn mogelijk (bijvoorbeeld een oneindige sequentie van getallen, zoals de natuurlijke getallen). In het voorbeeld hierboven is de lijst people de bron.
intermediaire operaties (mogelijk meerdere na elkaar) die de data verwerken (transformeren). Elke operatie neemt het resultaat van de vorige operatie (of de bron) en doet daar iets mee; het resultaat daarvan dient als invoer voor de volgende operatie. Zo krijg je een pijplijn waar de data doorheen stroomt terwijl ze bewerkt wordt. In het voorbeeld hierboven zijn mapToInt, filter en limit intermediaire operaties.
één terminale operatie: deze beëindigt de ketting en geeft het uiteindelijke resultaat terug. In het voorbeeld hierboven is average de terminale operatie.
Notitie
average() geeft een OptionalDouble terug, geen gewone double.
Dat komt omdat de stream leeg kan zijn (er zijn bijvoorbeeld geen meerderjarigen), en de gemiddelde waarde van een lege stream niet berekend kan worden.
We gebruiken daarom bij het uitprinten orElse(...) om 0 terug te geven als er geen ander resultaat is.
Je kan een stream-pijplijn slechts éénmaal doorlopen. Als je na het uitvoeren van de operaties nog een sequentie van operaties wil uitvoeren op dezelfde bron-elementen, moet je een nieuwe stream maken.
Streams zijn ook lazy: er worden slechts zoveel elementen verwerkt als nodig om het resultaat te berekenen.
Dat maakt dat de bron oneindig veel elementen mag aanleveren; zolang de rest van de pijplijn er slechts een eindig aantal nodig heeft, vormt dat geen probleem.
Enkel elementen die nuttig zijn om het resultaat te bekomen worden gebruikt.
We zullen hier later nog op terugkomen.
Een zeer concrete situatie waarin streams nuttig zijn, is wanneer je van plan bent om code te schrijven met volgende vorm:
Dit patroon komt zeer vaak voor in code.
Neem, als eenvoudig voorbeeld om te starten, de situatie uit het voorbeeld hierboven: de gemiddelde leeftijd berekenen van de eerste 20 meerderjarige personen in een lijst.
Zonder streams zou je dat waarschijnlijk ongeveer als volgt schrijven (merk op hoe dit het patroon van hierboven volgt):
De versie met streams ziet er helemaal anders uit — je schrijft zelf geen lussen, maar focust je op het beschrijven van de uit te voeren operaties.
Hier ter vergelijking nogmaals de code met streams:
Een stream van T-objecten wordt aangeduid met de interface Stream<T>.
Voor streams van primitieve types zijn er ook specifieke interfaces, bijvoorbeeld IntStream, DoubleStream, …
Om een stream aan te maken, start je steeds met een bron voor de data die verwerkt zal worden.
Dat kan op verschillende manieren.
Je kan eenvoudig een stream maken van alle elementen in een collectie: elke collectie heeft een .stream() operatie die een stream teruggeeft van alle elementen. Dit is de meest courante manier om te werken met streams. Merk op dat een stream zelf geen datastructuur is, en dus ook geen elementen bevat. Een stream lijkt dus meer op een iterator (die de elementen uit de bron een voor een teruggeeft, maar deze niet zelf bevat) dan op een collectie.
people.stream()
Stream.of(T t1, T t2, ...) maakt een stream met als data exact de opgegeven objecten. Gelijkaardig kan je bijvoorbeeld ook IntStream.of(int i1, int i2, ...) gebruiken voor een stream van getallen.
Stream.of(person1,person2,person3)
Specifiek voor IntStream is er ook IntStream.range en IntStream.rangeClosed om een IntStream te maken van alle getallen in een bepaald bereik.
Stream.concat(s1, s2) maakt een nieuwe stream door twee streams samen te voegen: eerst komen alle elementen van de eerste stream, daarna die van de tweede stream.
Opnieuw is er ook een gelijkaardige operatie op IntStream.
Stream.generate(supplier) maakt een stream waarbij de elementen aangeleverd worden door de meegegeven Supplier. Die dient dus als generator voor nieuwe elementen.
Stream.iterate(seed, unaryOp) maakt een stream waarvan de elementen gegenereerd worden door unaryOp herhaald toe te passen, beginnend bij seed. De elementen van de stream zijn dus seed, unaryOp(seed), unaryOp(unaryOp(seed)), .... Dit is bijvoorbeeld een (oneindige) stream van alle strikt positieve getallen1:
Stream.iterate(1,(n)->n+1)//=>1,2,3,4,...
Je kan ook een stream maken via een StreamBuilder, die je maakt via Stream.builder(). Dat laat toe om elementen één voor één toe te voegen (via add(...)), en daar uiteindelijk een stream van te maken via de build()-methode. Deze manier geeft je veel controle en is daardoor zeer flexibel, maar zal slechts zeer uitzonderlijk nodig zijn.
Tussentijdse (intermediate) operaties worden uitgevoerd op een stream, en geven een nieuwe stream terug.
De elementen in de nieuwe stream zijn gebaseerd op die van de originele stream, na het toepassen van de operatie.
Je kan de operaties dus na elkaar toepassen om een pijplijn te definiëren (dat is precies de bedoeling van een stream).
Het voorbeeld van daarstraks toont 3 tussentijdse operaties die na elkaar toegepast worden: mapToInt, filter, en limit (average is een terminale operatie; zie later).
We bespreken hieronder de meest voorkomende tussentijdse operaties.
De lijst van alle tussentijdse operaties is vooraf vastgelegd door de Stream-interface.
Met behulp van Gatherers kan je sinds Java 24 zelf tussentijdse operaties definiëren; we gaan hier niet dieper op in (zie links onderaan deze pagina voor meer info).
filter
De filter-operatie filtert sommige data-elementen uit de stream: enkel de elementen die voldoen aan het meegegeven predicaat worden verder doorgegeven.
Bijvoorbeeld, onderstaande filter-operatie verwijdert alle klinkers uit een stream van letters:
block-beta
columns 1
block:in
A B C D E F
end
arrow<["filter"]>(down)
block:out
space BB["B"] CC["C"] DD["D"] space FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
map, mapToInt, mapToLong, mapToDouble, mapToObj
De map-operatie transformeert elk elementen in een stream naar een ander element door een functie toe te passen op elk element.
Bijvoorbeeld, onderstaande map-operatie zet alle strings om naar lowercase:
block-beta
columns 1
block:in
ALICE Bob ChaRLIe
end
arrow<["map"]>(down)
block:out
alice bob charlie
end
classDef str stroke:black,fill:orange
class in,out str
In tegenstelling tot de filter-operatie kan de map-operatie het type van de elementen in de stream veranderen. Bijvoorbeeld, onderstaande code vertrekt van een stream van Strings, en eindigt met een stream van Integer-objecten:
block-beta
columns 1
block:in
ALICE Bob ChaRLIe
end
arrow<["map"]>(down)
block:out
alice bob charlie
end
arrow2<["map"]>(down)
block:out2
5 3 7
end
classDef str stroke:black,fill:orange
class in,out,out2 str
Er zijn ook specifieke map-operaties voor wanneer het resultaat een int, long, of double is.
Bijvoorbeeld, mapToInt geeft een IntStream terug.
Bij een IntStream, LongStream en DoubleStream geeft de map-operatie altijd opnieuw een stream van hetzelfde type (IntStream, LongStream, of DoubleStream).
Wanneer je de getallen in zo’n stream wil omzetten naar een object, kan dat met mapToObj:
Werk bij voorkeur met IntStream/LongStream/DoubleStream wanneer je numerieke data verwerkt.
Zo vermijd je onnodige boxing en unboxing van Integer, Long, of Double.
limit en takeWhile
De limit-operatie beperkt de resultaat-stream tot de eerste \( n \) elementen van de bron-stream:
block-beta
columns 1
block:in
A B C D E F
end
arrow<["limit"]>(down)
block:out
AA["A"] BB["B"] CC["C"] space:3
end
classDef str stroke:black,fill:orange
class in,out str
Merk op dat de plaats van limit (zoals die van de meeste tussentijdse operaties trouwens) belangrijk is:
De eerste variant resulteert in de eerste 3 medeklinkers uit de oorspronkelijke stream (je filtert eerst alle klinkers eruit, en neemt dan de eerste 3 overblijvende elementen).
In de tweede variant begin je met de eerste 3 letters, en filtert daaruit dan de klinkers weg.
Soms ken je het aantal elementen niet, maar wil je elementen blijven doorgeven zolang aan een bepaalde voorwaarde voldaan is.
Dat kan met takeWhile.
Merk op dat takeWhile niet hetzelfde is als filter: eenmaal de voorwaarde niet meer voldaan is, worden de volgende elementen niet meer bekeken, ook al zouden die opnieuw voldoen aan de voorwaarde.
block-beta
columns 1
block:in
A B C D E F
end
arrow<["skip"]>(down)
block:out
space:3 DD["D"] EE["E"] FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
De dropWhile-operatie is het omgekeerde van takeWhile: ze negeert elementen zolang aan een gegeven voorwaarde voldaan is.
block-beta
columns 1
block:in
Alpha Bravo Charlie Delta
end
arrow<["dropWhile"]>(down)
block:out
space:2 CC["Charlie"] DD["Delta"]
end
classDef str stroke:black,fill:orange
class in,out str
distinct
De distinct-operatie filtert alle dubbele waarden uit de stream. Deze operatie is stateful: de waarden die reeds gezien zijn moeten bijgehouden worden om mee te vergelijken.
block-beta
columns 1
block:in
A B A2["A"] C A3["A"] D
end
arrow<["distinct"]>(down)
block:out
AA["A"] BB["B"] space CC["C"] space DD["D"]
end
classDef str stroke:black,fill:orange
class in,out str
sorted
De sorted-operatie sorteert de waarden in de stream. Deze operatie is stateful (de reeds geziene waarden moeten bijgehouden worden om ze gesorteerd terug te geven), en de operatie vereist ook dat de stream eindig is. Het sorteren kan immers pas uitgevoerd worden wanneer alle elementen gekend zijn.
block-beta
columns 1
block:in
C D A F E B
end
arrow<["sorted"]>(down)
block:out
AA["A"] BB["B"] CC["C"] DD["D"] EE["E"] FF["F"]
end
classDef str stroke:black,fill:orange
class in,out str
peek
De peek-operatie doet eigenlijk niets: ze geeft alle elementen gewoon door, maar laat toe om een functie uit te voeren voor elk element.
Deze operatie kan bijvoorbeeld handig zijn om te debuggen: je kan ze middenin een pijplijn toevoegen om te kijken welke elementen daar voorbijkomen.
Stream.of("A","B","C","D","E","F").limit(3).peek(IO::println)// => A, B, C.filter(l->!"AEIOUY".contains(l))
block-beta
columns 1
block:in
A B C D E F
end
arrow<["limit"]>(down)
block:out
AA["A"] BB["B"] CC["C"] space:3
end
arrow2<["peek"]>(down)
block:out2
AAA["A"] BBB["B"] CCC["C"] space:3
end
arrow3<["filter"]>(down)
block:out3
space BBBB["B"] CCCC["C"] space:3
end
classDef str stroke:black,fill:orange
class in,out,out2,out3 str
flatMap
De flatMap operatie is gelijkaardig aan de map-operatie, maar wordt gebruikt wanneer het resultaat van de map-functie op één element opnieuw een stream geeft.
Opnieuw bestaan er specifieke versies flatMapToInt, flatMapToLong, en flatMapToDouble voor wanneer het resultaat een IntStream, LongStream of DoubleStream moet worden.
We gebruiken de String::chars methode als voorbeeld; die geeft voor een String een IntStream terug met de char-values van elk karakter (denk: de ASCII of Unicode-waarde van elke letter).
Als we gewoon map zouden toepassen, krijgen we een stream van streams (hier: een stream van 3 streams, elk met 2 elementen):
block-beta
columns 1
block:in
Aa Bb Cc
end
arrow<["map"]>(down)
block:out
columns 3
block:blockA
columns 2
A a
end
block:blockB
columns 2
B b
end
block:blockC
columns 2
C c
end
end
classDef str stroke:black,fill:orange
classDef str2 stroke:red,fill:yellow
class in,out str
class blockA,blockB,blockC str2
Vaak is dat niet wat we willen: stel dat we één lange stream van char-waarden (ints) willen maken, met daarin de karakters van alle woorden uit de oorspronkelijke stream na elkaar.
In dat geval gebruiken we flatMap (of, in dit geval, flatMapToInt omdat chars een IntStream teruggeeft):
block-beta
columns 1
block:in
Aa Bb Cc
end
arrow<["flatMap"]>(down)
block:out
columns 6
A a
B b
C c
end
classDef str stroke:black,fill:orange
class in,out str
flatMap maakt dus in zekere zin een combinatie van een gewone map-operatie (die telkens een stream teruggeeft voor elk element), gevolgd door een concatenatie van al die resulterende streams.
De naam komt van het feit dat de resulterende structuur een ‘flattened’ versie is, waarbij één niveau van nesting weggehaald werd: waar map een stream van streams oplevert (bv. Stream<IntStream>), krijgen we bij flatMap (of hier flatMapToInt) één gewone stream terug (hier een IntStream).
mapMulti
De mapMulti operatie kan je gebruiken wanneer elk object in de bronstream kan leiden tot meerdere objecten in de doelstream, net zoals bij flatMap.
In tegenstelling tot flatMap, waar de mapping-operatie een stream moet teruggeven, werkt mapMulti anders.
Je moet hier namelijk geen stream teruggeven.
Aan mapMulti geef je een BiConsumer mee; dat is een functie met 2 argumenten (we noemen die hier value en output):
Het eerste argument (value) is het element uit de bronstream waarvoor de overeenkomstige elementen in de doelstream bepaald moeten worden
Het tweede argument (output) is een Consumer-functie: elk element wat je daaraan doorgeeft (via de accept-methode), komt terecht in de doelstream.
De functie die meegegeven wordt aan mapMulti moet dus alle objecten bepalen die voor het gegeven bronobject (value) in de doelstream terecht moeten komen, en die één voor één doorgeven aan output.
Een voorbeeld maakt dit hopelijk wat duidelijker.
Stel dat we de lijst \( [1, 2, 3] \) willen omzetten in \( [1, 2, 2, 3, 3, 3] \): elk getal in de bronstream wordt even vaak als zijn waarde herhaald in de doelstream.
We zouden dat met flatMap kunnen doen, door telkens een stream te maken van het juiste aantal elementen.
Dat doen we hieronder door een oneindige stream te maken (via generate) van telkens hetzelfde element (value), en dan elk van die streams te beperken tot de eerste value elementen:
Dankzij de laziness van streams (zie later) moeten we niet bang zijn dat de oneindige stream zal leiden tot een oneindige uitvoeringstijd; het aantal elementen dat we gebruiken wordt beperkt door de limit-operatie, en er zullen er nooit meer dan dat gegenereerd worden.
De versie met mapMulti ziet er wat anders (en misschien vertrouwder) uit — hier kunnen we gewone imperatieve code (lussen) schrijven:
block-beta
columns 1
block:in
AA["1"] BB["2"] CC["3"]
end
arrow<["mapMulti"]>(down)
block:out
A1["1"]
B1["2"]
B2["2"]
C1["3"]
C2["3"]
C3["3"]
end
classDef str stroke:black,fill:orange
classDef aa stroke:black,fill:#afa
classDef cc stroke:black,fill:#aaf
class AA,A1 aa
class CC,C1,C2,C3 cc
class in,out str
Terminale (terminal) operaties
Een terminale operatie staat op het einde van de pijplijn, na alle tussentijdse operaties.
Na een terminale operatie kunnen dus geen extra operaties meer uitgevoerd worden met de elementen uit de stream.
De voorbeelden hierboven hadden geen terminale operaties.
Een stream zonder terminale operatie doet niets: er wordt geen enkel element verwerkt, en er wordt geen enkele tussentijdse operatie uitgevoerd.
Het is de terminale operatie die alle verwerking in gang zet.
De reden daarvoor is de laziness van streams.
Laziness (luiheid)
We zeiden eerder al dat streams lazy zijn.
Dat houdt in dat de gedefinieerde operaties niet uitgevoerd worden, tenzij het echt niet anders kan.
Bekijk bijvoorbeeld onderstaande code:
varlist=List.of(1,2,3,4,5,6,7,8,9,10);Stream<Integer>incrementAll=list.stream().peek(n->IO.println("Processing "+n)).map(n->n+1).limit(1);// [1] hier werd nog niets uitgeprintincrementAll.forEach(n->{IO.println("Got "+n);});//[2]print"Processing 1"envervolgens"Got 2"
We maken een lijst van 10 getallen, voeren map uit op een stream van die getallen, en beperken het resultaat tot het eerste element.
Aangekomen op punt [1] werd er, misschien verrassend, helemaal niets uitgeprint.
Dat betekent dat de lambda-functie die \( n \) met 1 verhoogt ook niet uitgevoerd werd: er gebeurde helemaal niets met de getallen uit de lijst.
We definiëren met streams enkel de pijplijn: wat moet er later eventueel gebeuren met de getallen?
Pas wanneer we op punt [2] komen, en de terminale operatie forEach (zie later) uitgevoerd werd, werd er voor de eerste keer “Processing 1” uitgeprint.
Maar dan enkel voor het eerste element: door de limit-operatie is er geen nood aan het verwerken van het tweede, derde, … element, dus dat gebeurt ook nooit.
De code hierboven verwerkt dus enkel het eerste element uit de lijst; met alle andere elementen wordt nooit iets gedaan.
Het is dus belangrijk om in het achterhoofd te houden dat stream-operaties enkel uitgevoerd worden wanneer dat noodzakelijk is, en pas op het allerlaatste moment (als gevolg van een terminale operatie).
Dat is efficiënt, maar kan soms leiden tot verrassende situaties (zoals hierboven).
We bekijken nu enkele vaak voorkomende terminale operaties.
toList, toArray
De terminale operatie toList maakt een nieuwe lijst met daarin de elementen op het einde van de pijplijn, in de volgorde dat ze daar toekomen.
Bijvoorbeeld:
Door de beperkingen van generics in Java (i.e., je mag niet new T[n] schrijven voor een generisch type T) kan er enkel een Object[] array gemaakt worden, geen String[].
Indien je dat wel wil, moet je een functie meegeven om een lege array van het juiste type en de juiste lengte aan te maken, bijvoorbeeld:
Zoals de naam aangeeft, telt de count()-operatie het aantal elementen op het einde van de stream.
Dat aantal wordt als een long teruggegeven, niet als int.
Bijvoorbeeld:
De operaties findFirst en findAny geven respectievelijk het eerste en een niet nader bepaald element terug uit de stream.
Merk op dat findAny niet ‘random’ is; er zijn gewoon geen garanties over welk element precies teruggegeven wordt.
findAny is vooral nuttig bij parallelle streams (zie later).
Het resultaat van beide methodes is een Optional; die is leeg wanneer de stream leeg is, er dus geen element is om terug te geven.
Deze methodes geven true of false terug, afhankelijk van of respectievelijk ten minste één, elk, of geen enkel element in de stream voldoet aan de meegegeven voorwaarde.
De min en max operaties vereisen een Comparator-object om elementen te vergelijken met elkaar.
Ze geven een Optional terug met het kleinste respectievelijk grootste element, of de lege optional indien de stream geen elementen bevat.
Bijvoorbeeld, onderstaande code geeft het element terug waarin de letter ‘a’ het vaakst voorkomt.
We maken dus een Comparator gebaseerd op het aantal a’s in het woord.
Om dat aantal te tellen, maken we opnieuw gebruik van een stream-pipeline, namelijk chars().filter().count():
Voor een IntStream, LongStream en DoubleStream hoef je geen Comparator mee te geven; daar worden uiteraard gewoon de getallen zelf vergeleken.
sum, average, summaryStatistics
De sum, average en summaryStatistics operaties zijn enkel beschikbaar op IntStream, LongStream en DoubleStream.
De eerste twee geven, weinig verrassend, de som en het gemiddelde van de waarden terug.
average geeft een OptionalDouble terug, omdat een lege stream geen gemiddelde heeft.
De summaryStatistics operatie geeft een object terug met daarin
het aantal waarden (count)
de kleinste waarde (min)
de gemiddelde waarde (average)
de grootste waarde (max)
de totale waarde (sum)
Indien je meer dan één van die resultaten zoekt, is het dus efficiënter om deze methode te gebruiken dan de afzonderlijke operaties (die elk een nieuwe stream moeten doorlopen).
De reduce-operatie is een zeer veelzijdige operatie.
Ze combineert alle elementen in de stream tot één nieuwe waarde (dit is dus bijna de definitie van een terminale operatie).
We beschouwen hier de versie van reduce met twee argumenten, die een resultaat teruggeeft van hetzelfde type als de elementen in de stream:
een startwaardeidentity van type T
een accumulator-functie accumulator (een BinaryOperator) die een vorige T combineert met de huidige T uit de stream, en de nieuwe T teruggeeft
Met andere woorden, de reduce-operatie op een stream heeft het volgende effect:
Een andere manier om hiernaar te kijken is dat de accumulator een bewerking is die ingevoegd wordt tussen alle elementen van de stream;
de linker-parameter van de accumulator is de waarde tot dan toe, en de rechterparameter de volgende waarde om mee in rekening te brengen.
Bijvoorbeeld, we kunnen de som van alle elementen ook berekenen via reduce in plaats van via sum:
Weetje: in sommige andere programmeertalen wordt reduce ook fold genoemd (en de Java-versie van reduce is meer specifiek foldLeft).
collect
De laatste terminale operatie die we bekijken is collect.
Deze is gelijkaardig aan reduce, maar laat toe om de set van terminale operaties uit te breiden via Collector-objecten.
Een Collector-object bevat 4 elementen:
een supplier-functie (type Supplier) die wordt gebruikt om een startwaarde (state) te verkrijgen, vergelijkbaar met de identity bij reduce
een accumulator-functie (type BiConsumer) die een nieuw data-element toevoegt aan het voorlopige resultaat (de state); vergelijkbaar met de accumulator van reduce
een combiner-functie (type BinaryOperator) die twee voorlopige resultaten kan combineren (vooral nuttig bij parallelle uitvoering; zie later)
een finisher-functie (type Function) die, op het einde, het voorlopige resultaat omzet naar het finale resultaat.
De supplier, accumulator, combiner en finisher werken conceptueel op de volgende manier:
Merk op dat, in tegenstelling tot de accumulator bij reduce, er bij die van een collector niets wordt teruggegeven; de verwachting is dat het tijdelijke resultaat zelf geüpdated wordt (en dus stateful is).
Info
De combiner is enkel nuttig indien er meerdere deelresultaten zijn.
Dat is enkel het geval als de invoer-stream in meerdere delen opgedeeld kan worden.
Gewoonlijk gebeurt dat enkel bij parallelle streams (zie later).
Een gewone (sequentiële) stream heeft geen combiner nodig.
We geven één voorbeeld van een Collector-implementatie, namelijk een collector die (voor een stream van Strings) de Strings aan elkaar plakt tot één lange String, gescheiden door komma’s.
De state van de collector is een object van de klasse JoiningState.
Die state houdt de tot dan toe aan elkaar geplakte string bij (current), alsook of het eerste element nog toegevoegd moet worden (first).
Java bevat reeds enkele handige voorgedefinieerde collectors.
Deze vind je in de Collectors-klasse. We bekijken er enkele.
Collectors.joining
Deze collector doet wat we hierboven zelf implementeerden: Strings aan elkaar plakken, gescheiden door een separator-string.
We hadden onszelf dus wat werk kunnen besparen, en gewoon het volgende schrijven:
Deze collectors doen wat de naam zegt: ze maken een List, Set, of Collection met daarin de elementen van de stream.
De toList terminale operatie die we eerder zagen lijkt op Collectors.toList(), maar er is een belangrijk verschil:
stream.toList() geeft gegarandeerd een unmodifiable lijst terug
collect(Collectors.toList()) geeft een lijst terug waarvan het concrete type niet gegarandeerd is; het kan dus aanpasbaar zijn of niet.
Bij toCollection ligt niet vast welk type collectie gemaakt moet worden; je moet zelf een functie meegeven (de collectionFacory) om een lege collectie van het gewenste type te maken:
Je kan ook een collector meegeven (de downstream collector) die bepaalt hoe de values geaggegregeerd worden in elke groep (als je die niet meegeeft wordt er een lijst gemaakt, zoals in het voorbeeld hierboven).
Deze downstream collector is een collector die de T’s in elke groep kan omzetten naar een resultaattype (V), om zo een Map<K, V> terug te geven.
Het resultaat hoeft dus niet hetzelfde type te hebben als de elementen in de oorspronkelijke stream.
Met andere woorden, groupingBy zet een stream van T’s om in meerdere streams, namelijk één stream per groep, en de downstream collector bepaalt hoe die streams verwerkt worden tot een eindresultaat.
Dat eindresultaat komt als value terecht in de resulterende map, met als key de waarde die bepaald werd door de eerste functie (de classifier).
We geven hier enkele voorbeelden van zo’n nuttige downstream collectors en hun gebruik in groupingBy.
Collectors.counting()
Deze collector telt simpelweg het aantal elementen.
Bijvoorbeeld:
Collectors.counting() is dan ook vooral handig in combinatie met groupingBy.
Bijvoorbeeld, als je het aantal woorden per lengte wil tellen in de stream, kan je dat doen via groupingBy met counting als downstream collector:
Deze functie groepeert dus eerst alle woorden volgens hun aantal letters (met het eerste argument String::length), en telt vervolgens per groep het aantal woorden (met het tweede argument Collectors.counting()).
Je krijgt dus een Map<Integer, Long> terug, waarbij de key de woordlengte is, en de value het aantal woorden met die lengte.
Een visualisatie van het proces (voor een ander voorbeeld) vind je in volgende afbeelding:
Hier wordt een stream van gekleurde Box-objecten gegroepeerd volgens hun kleur, en vervolgens per kleur het aantal Boxen geteld.
Collectors.summingInt, summingLong, summingDouble
Deze collector zet eerst elk element om naar een int volgens de meegegeven functie (dus equivalent aan een mapToInt) en telt deze vervolgens op.
Er zijn ook gelijkaardige collectors voor long en double.
Bijvoorbeeld, om het totaal aantal karakters te tellen van de woorden in een stream kunnen we summingInt als volgt gebruiken:
Het gebruik van summingInt als downstream collector bij groupingBy is ook mogelijk, en nuttiger.
We kunnen dit bijvoorbeeld gebruiken om het totaal aantal karakters te tellen van de woorden per beginletter:
Dus: de woorden die met een ‘a’ beginnen hebben samen 5 letters, en de woorden die met een ‘b’ beginnen hebben samen 12 letters.
Collectors.mapping
Deze collector past een functie toe op elk element, en verwerkt vervolgens de resultaten met een downstream collector.
Bijvoorbeeld, als we de woorden in hoofdletters willen hebben in plaats van kleine letters, kunnen dat doen via mapping:
Er zijn dus twee woorden die met ‘a’ beginnen, met respectievelijk 5 en 8 letters, één woord dat met ‘b’ begint en 5 letters heeft, en twee woorden die met ‘c’ beginnen, elk met 7 letters.
Collectors.flatMapping
Deze collector is gelijkaardig aan Collectors.mapping(), maar de functie die je meegeeft moet een stream teruggeven, en de resultaten van al die streams worden samengevoegd tot één stream.
Dat komt overeen met de flatMap-operatie, maar dan in de context van collectors.
Je geeft aan flatMapping dus een functie mee die één element uit de oorspronkelijke stream omzet naar een nieuwe stream, en ook een downstream collector die de elementen van die resulterende streams verwerkt.
Bijvoorbeeld, stel dat we een Stream<String> als bron hebben, en we willen een List<Character> terugkrijgen met alle karakters uit alle woorden, dan kunnen we dat als volgt doen:
mapToObj() is nodig omdat chars() een IntStream teruggeeft.
Die moet omgezet worden naar een Stream<Character>, omdat flatMapping een Stream<? extends Object> verwacht, en geen IntStream
Zonder mapToObj() zou de code niet compileren.
In combinatie met groupingBy kan dit bijvoorbeeld gebruikt worden om alle letters per woordlengte in een Set te groeperen:
Deze collector groepeert de elementen ook in een Map, maar nu met als key true of false, afhankelijk van of het object voldoet aan de meegegeven voorwaarde of niet:
Ook hier bestaan, net zoals bij groupingBy, varianten waarbij je een downstream collector kan meegeven om de values te aggregeren.
Bijvoorbeeld, als we het aantal korte en lange woorden willen tellen, kunnen we dat doen via partitioningBy met counting als downstream collector:
Met Collectors.toMap maak je een Map door twee argumenten mee te geven: een key-functie en value-functie.
De key-functie bepaalt de key voor elk element in de stream, en de value-functie bepaalt de waarde die aan die key gekoppeld wordt.
Let op: als twee elementen dezelfde key produceren, krijg je standaard een IllegalStateException.
Als duplicate keys mogelijk zijn, geef dan expliciet een merge-functie mee (als derde argument) die aangeeft hoe twee waarden gecombineerd moeten worden tot 1 waarde in de Map:
De forEach(fn) terminale operatie voert de meegegeven functie fn uit voor elk element dat het einde van de pijplijn bereikt.
Een heel eenvoudig gebruik hiervan is het uitprinten van alle elementen via IO.println:
De forEach-operatie is dus zowat het streams-equivalent van de enhanced for-loop (for (var x : collection)) bij collecties.
Opgelet
Vermijd het gebruik van forEach om een variabele/lijst/… buiten de forEach-lambda aan te passen, zoals het toevoegen aan de result-lijst in onderstaand voorbeeld.
Meestal is dit een antipattern, en is er een betere manier om hetzelfde resultaat te bekomen.
Vaak kunnen operaties in een stream efficiënt in parallel gebeuren.
Denk bijvoorbeeld aan map of filter: deze gebeuren element per element, en zijn dus onafhankelijk van wat er met de andere elementen gebeurt.
Je kan in Java daarom ook een parallelle stream aanmaken.
Deze zal, bij uitvoering, meerdere threads gebruiken om de stream te verwerken.
Het is eenvoudig om een stream parallel te maken: dat kan via de parallel() intermediate operatie, of de parallelStream()-operatie op collecties.
Er is ook een sequential() operatie die de stream sequentieel maakt.
Merk op dat de mode waarin de stream zich bevindt op het moment van de terminale operatie bepaalt hoe de hele stream uitgevoerd wordt; je kan dus geen deel van de operaties parallel en een ander deel sequentieel uitvoeren.
Parallelle streams zijn niet automatisch sneller: de overhead van het opsplitsen, schedulen en samenvoegen van deelresultaten kan groter zijn dan de winst.
Voor kleine datasets of goedkope bewerkingen is een sequentiële stream vaak efficiënter.
Meet dus altijd eerst voor je parallelle streams als optimalisatie inzet.
Nog meer streams? (optioneel)
Gatherers
Via de Collector-API kan je, zoals we gezien hebben, zelf al nieuwe collectors toevoegen.
Voor de tussentijdse operaties ben je via de streams API echter beperkt tot de voorgedefinieerde tussentijdse operaties; maar je kan er veel meer bedenken.
Onderstaande presentatie bespreekt Gatherers, de oplossing die sinds Java 24 aangeboden wordt om zelf nieuwe tussentijdse operaties te definiëren.
Gebruik dit enkel als je met Java 24 of nieuwer werkt; in Java 21 is Gatherer nog niet beschikbaar.
Spliterators
Streams (en parallelle streams in het bijzonder) maken gebruik van Spliterators.
Dat is een variant op een iterator, die (naast de elementen overlopen, zoals bij een gewone iterator) ook de elementen van een bron (bv. een collectie) in 2 delen kan splitsen.
Bij parallelle streams zal dan elk van die delen afzonderlijk (in een aparte thread) verwerkt worden.
Meer info over Spliterators vind je in onderstaande presentatie.
Omdat int maar een eindig aantal waarden kan hebben (de hoogste waarde is \( 2^{31}-1 \)), zal deze stream ooit negatieve getallen beginnen produceren: …, 2147483646, 2147483647, -2147483648, -2147483647, …. De stream is wel nog steeds oneindig. ↩︎
Subsecties van 7.6 Streams
Oefeningen
Alle oefeningen moeten opgelost worden zonder if-statements, zonder for- of while-lussen, en zonder extra variabelen.
Elke methode bevat slechts één return-statement met daarachter een streams-pipeline.
Gebruik waar mogelijk methode-referenties.
We werken met een dataset van personen, onderverdeeld in volwassenen en kinderen:
4. ★ Geef enkele statistieken (minimum, maximum, gemiddelde) van de leeftijd van alle volwassenen in de dataset die ten minste 30 jaar oud zijn.
Modeloplossing
7. ★★★ Geef een String met de 5 oudste volwassenen terug, in het formaat "voornaam achternaam leeftijd", gesorteerd volgens voornaam, 1 persoon per lijn.
Modeloplossing
18. ★★ Maak een Map<String, Long> die voor elke postcode het aantal volwassenen met die postcode bevat.
Hint: gebruik Collectors.counting() in combinatie met groupingBy
19. ★★★ Geef een alfabetisch gesorteerde lijst van alle achternamen van volwassenen die minstens 2 keer voorkomen in de lijst van volwassenen.
Modeloplossing
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
20. ★★ Zoek de jongste volwassene zonder kinderen.
Modeloplossing
22. ★★ Maak een Map<String, Long> met de frequentie van kind-voornamen (case-insensitive), bijvoorbeeld "alice" en "Alice" samen tellen.
Modeloplossing
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
24. ★★★★ Zoek alle volwassenen met een twee- of meerling (twee of meer van hun kinderen hebben dezelfde leeftijd).
Modeloplossing
Merk op dat .collect(...).values().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
25. ★★★★★ Maak een lijst van AvgAgeZip-objecten voor alle postcodes waar een volwassene met minstens één kind woont, gesorteerd volgens postcode.
Merk op dat .collect(...).entrySet().stream() inhoudt dat een tussentijdse datastructuur (een Map) gecreëerd wordt. Dit is dus niet één stream pipeline, maar zijn er twee na elkaar.
26. ★★★ Schrijf, gebruik makend van streams, een generische methode mapAllValues(map, function) die op basis van de gegeven Map een nieuwe Map maakt waarbij alle values vervangen zijn door de gegeven functie erop toe te passen. Denk na over geschikte grenzen voor je generische parameters (PECS).
Modeloplossing