7.6 Streams
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java streams zijn
- ranges in C++
- iterators, generators en comprehensions in Python
- LINQ in C#
Wat en waarom?
Streams vormen een krachtig concept om efficiënt data te verwerken. Ze vormen een abstractie voor sequentiële en parallelle operaties op datasets, zoals filteren, transformeren, en aggregeren, zonder de onderliggende datastructuur te wijzigen. Bovendien maakt het gebruik van streams het mogelijk om declaratief te programmeren: je beschrijft op hoog niveau wát je met de dataset wilt doen, in plaats van stap voor stap te beschrijven hoe dat moet gebeuren.
Een snel voorbeeldje om dat wat concreter te maken is onderstaande code, die streams gebruikt om de gemiddelde leeftijd te berekenen van de eerste 20 meerderjarige Person-objecten in de lijst people (we gaan later dieper in op de details):
Een stream zelf is geen datastructuur of collectie; een stream is een pijplijn — een ketting van operaties die uitgevoerd moeten worden op de data. Die operaties kunnen de data filteren, transformeren, groeperen, reduceren, … Een stream stelt dus één grote bewerking voor op de data, samengesteld uit meerdere operaties. Elke stream bestaat uit 3 delen:
- één bron voor de data (een stroom van data, vandaar de naam). Die bron kan een datastructuur zijn (bv. een array, ArrayList, HashSet, …), maar ook andere bronnen zijn mogelijk (bijvoorbeeld een oneindige sequentie van getallen, zoals de natuurlijke getallen). In het voorbeeld hierboven is de lijst
peoplede bron. - intermediaire operaties (mogelijk meerdere na elkaar) die de data verwerken (transformeren). Elke operatie neemt het resultaat van de vorige operatie (of de bron) en doet daar iets mee; het resultaat daarvan dient als invoer voor de volgende operatie. Zo krijg je een pijplijn waar de data doorheen stroomt terwijl ze bewerkt wordt. In het voorbeeld hierboven zijn
mapToInt,filterenlimitintermediaire operaties. - één terminale operatie: deze beëindigt de ketting en geeft het uiteindelijke resultaat terug. In het voorbeeld hierboven is
averagede terminale operatie.
Notitie
average() geeft een OptionalDouble terug, geen gewone double.
Dat komt omdat de stream leeg kan zijn (er zijn bijvoorbeeld geen meerderjarigen), en de gemiddelde waarde van een lege stream niet berekend kan worden.
We gebruiken daarom bij het uitprinten orElse(...) om 0 terug te geven als er geen ander resultaat is.
graph LR Source --> Op1 --> Op2 --> Op3 --> Terminal style Source stroke:black,fill:#afa style Terminal stroke:black,fill:#faa
Je kan een stream-pijplijn slechts éénmaal doorlopen. Als je na het uitvoeren van de operaties nog een sequentie van operaties wil uitvoeren op dezelfde bron-elementen, moet je een nieuwe stream maken.
Streams zijn ook lazy: er worden slechts zoveel elementen verwerkt als nodig om het resultaat te berekenen. Dat maakt dat de bron oneindig veel elementen mag aanleveren; zolang de rest van de pijplijn er slechts een eindig aantal nodig heeft, vormt dat geen probleem. Enkel elementen die nuttig zijn om het resultaat te bekomen worden gebruikt. We zullen hier later nog op terugkomen.
Een zeer concrete situatie waarin streams nuttig zijn, is wanneer je van plan bent om code te schrijven met volgende vorm:
Dit patroon komt zeer vaak voor in code. Neem, als eenvoudig voorbeeld om te starten, de situatie uit het voorbeeld hierboven: de gemiddelde leeftijd berekenen van de eerste 20 meerderjarige personen in een lijst. Zonder streams zou je dat waarschijnlijk ongeveer als volgt schrijven (merk op hoe dit het patroon van hierboven volgt):
De versie met streams ziet er helemaal anders uit — je schrijft zelf geen lussen, maar focust je op het beschrijven van de uit te voeren operaties. Hier ter vergelijking nogmaals de code met streams:
Beide versies doen hetzelfde, maar in de tweede versie is het veel duidelijker wat de bedoeling is:
- neem eerst van elke persoon de leeftijd (
mapToInt) - kijk dan enkel naar de leeftijden >= 18 (
filter) - kijk vervolgens enkel naar de eerste 20 van die leeftijden (
limit) - neem tenslotte het gemiddelde (
average).
Deze manier van programmeren ligt veel dichter bij bijvoorbeeld SQL:
Weetje
In C# is LINQ het equivalent van streams. Dat is een taal die erg nauw aansluit bij SQL. Het voorbeeld van hierboven kan er in C# als volgt uitzien:
Streams aanmaken
Een stream van T-objecten wordt aangeduid met de interface Stream<T>.
Voor streams van primitieve types zijn er ook specifieke interfaces, bijvoorbeeld IntStream, DoubleStream, …
Om een stream aan te maken, start je steeds met een bron voor de data die verwerkt zal worden. Dat kan op verschillende manieren.
Je kan eenvoudig een stream maken van alle elementen in een collectie: elke collectie heeft een
.stream()operatie die een stream teruggeeft van alle elementen. Dit is de meest courante manier om te werken met streams. Merk op dat een stream zelf geen datastructuur is, en dus ook geen elementen bevat. Een stream lijkt dus meer op een iterator (die de elementen uit de bron een voor een teruggeeft, maar deze niet zelf bevat) dan op een collectie.Stream.of(T t1, T t2, ...)maakt een stream met als data exact de opgegeven objecten. Gelijkaardig kan je bijvoorbeeld ookIntStream.of(int i1, int i2, ...)gebruiken voor een stream van getallen.Specifiek voor
IntStreamis er ookIntStream.rangeenIntStream.rangeClosedom een IntStream te maken van alle getallen in een bepaald bereik.Om een stream te maken van een array, gebruik je
Arrays.stream(arr).Stream.concat(s1, s2)maakt een nieuwe stream door twee streams samen te voegen: eerst komen alle elementen van de eerste stream, daarna die van de tweede stream. Opnieuw is er ook een gelijkaardige operatie opIntStream.Stream.generate(supplier)maakt een stream waarbij de elementen aangeleverd worden door de meegegeven Supplier. Die dient dus als generator voor nieuwe elementen.Stream.iterate(seed, unaryOp)maakt een stream waarvan de elementen gegenereerd worden doorunaryOpherhaald toe te passen, beginnend bij seed. De elementen van de stream zijn dusseed, unaryOp(seed), unaryOp(unaryOp(seed)), .... Dit is bijvoorbeeld een (oneindige) stream van alle strikt positieve getallen1:Je kan ook een stream maken via een
StreamBuilder, die je maakt viaStream.builder(). Dat laat toe om elementen één voor één toe te voegen (viaadd(...)), en daar uiteindelijk een stream van te maken via debuild()-methode. Deze manier geeft je veel controle en is daardoor zeer flexibel, maar zal slechts zeer uitzonderlijk nodig zijn.
Tussentijdse (intermediate) operaties
Tussentijdse (intermediate) operaties worden uitgevoerd op een stream, en geven een nieuwe stream terug.
De elementen in de nieuwe stream zijn gebaseerd op die van de originele stream, na het toepassen van de operatie.
Je kan de operaties dus na elkaar toepassen om een pijplijn te definiëren (dat is precies de bedoeling van een stream).
Het voorbeeld van daarstraks toont 3 tussentijdse operaties die na elkaar toegepast worden: mapToInt, filter, en limit (average is een terminale operatie; zie later).
We bespreken hieronder de meest voorkomende tussentijdse operaties.
De lijst van alle tussentijdse operaties is vooraf vastgelegd door de Stream-interface.
Met behulp van Gatherers kan je sinds Java 24 zelf tussentijdse operaties definiëren; we gaan hier niet dieper op in (zie links onderaan deze pagina voor meer info).
filter
De filter-operatie filtert sommige data-elementen uit de stream: enkel de elementen die voldoen aan het meegegeven predicaat worden verder doorgegeven.
Bijvoorbeeld, onderstaande filter-operatie verwijdert alle klinkers uit een stream van letters:
block-beta columns 1 block:in A B C D E F end arrow<["filter"]>(down) block:out space BB["B"] CC["C"] DD["D"] space FF["F"] end classDef str stroke:black,fill:orange class in,out str
map, mapToInt, mapToLong, mapToDouble, mapToObj
De map-operatie transformeert elk elementen in een stream naar een ander element door een functie toe te passen op elk element.
Bijvoorbeeld, onderstaande map-operatie zet alle strings om naar lowercase:
block-beta columns 1 block:in ALICE Bob ChaRLIe end arrow<["map"]>(down) block:out alice bob charlie end classDef str stroke:black,fill:orange class in,out str
In tegenstelling tot de filter-operatie kan de map-operatie het type van de elementen in de stream veranderen. Bijvoorbeeld, onderstaande code vertrekt van een stream van Strings, en eindigt met een stream van Integer-objecten:
block-beta columns 1 block:in ALICE Bob ChaRLIe end arrow<["map"]>(down) block:out alice bob charlie end arrow2<["map"]>(down) block:out2 5 3 7 end classDef str stroke:black,fill:orange class in,out,out2 str
Er zijn ook specifieke map-operaties voor wanneer het resultaat een int, long, of double is.
Bijvoorbeeld, mapToInt geeft een IntStream terug.
Bij een IntStream, LongStream en DoubleStream geeft de map-operatie altijd opnieuw een stream van hetzelfde type (IntStream, LongStream, of DoubleStream).
Wanneer je de getallen in zo’n stream wil omzetten naar een object, kan dat met mapToObj:
Tip
Werk bij voorkeur met IntStream/LongStream/DoubleStream wanneer je numerieke data verwerkt.
Zo vermijd je onnodige boxing en unboxing van Integer, Long, of Double.
limit en takeWhile
De limit-operatie beperkt de resultaat-stream tot de eerste \( n \) elementen van de bron-stream:
block-beta columns 1 block:in A B C D E F end arrow<["limit"]>(down) block:out AA["A"] BB["B"] CC["C"] space:3 end classDef str stroke:black,fill:orange class in,out str
Merk op dat de plaats van limit (zoals die van de meeste tussentijdse operaties trouwens) belangrijk is:
is iets anders dan
De eerste variant resulteert in de eerste 3 medeklinkers uit de oorspronkelijke stream (je filtert eerst alle klinkers eruit, en neemt dan de eerste 3 overblijvende elementen). In de tweede variant begin je met de eerste 3 letters, en filtert daaruit dan de klinkers weg.
Soms ken je het aantal elementen niet, maar wil je elementen blijven doorgeven zolang aan een bepaalde voorwaarde voldaan is.
Dat kan met takeWhile.
Merk op dat takeWhile niet hetzelfde is als filter: eenmaal de voorwaarde niet meer voldaan is, worden de volgende elementen niet meer bekeken, ook al zouden die opnieuw voldoen aan de voorwaarde.
block-beta columns 1 block:in Alpha Bravo Charlie Delta end arrow<["takeWhile"]>(down) block:out AA["Alpha"] BB["Bravo"] space:2 end classDef str stroke:black,fill:orange class in,out str
skip en dropWhile
De skip-operatie doet het omgekeerde van limit: ze slaat de eerste \( n \) elementen over.
block-beta columns 1 block:in A B C D E F end arrow<["skip"]>(down) block:out space:3 DD["D"] EE["E"] FF["F"] end classDef str stroke:black,fill:orange class in,out str
De dropWhile-operatie is het omgekeerde van takeWhile: ze negeert elementen zolang aan een gegeven voorwaarde voldaan is.
block-beta columns 1 block:in Alpha Bravo Charlie Delta end arrow<["dropWhile"]>(down) block:out space:2 CC["Charlie"] DD["Delta"] end classDef str stroke:black,fill:orange class in,out str
distinct
De distinct-operatie filtert alle dubbele waarden uit de stream. Deze operatie is stateful: de waarden die reeds gezien zijn moeten bijgehouden worden om mee te vergelijken.
block-beta columns 1 block:in A B A2["A"] C A3["A"] D end arrow<["distinct"]>(down) block:out AA["A"] BB["B"] space CC["C"] space DD["D"] end classDef str stroke:black,fill:orange class in,out str
sorted
De sorted-operatie sorteert de waarden in de stream. Deze operatie is stateful (de reeds geziene waarden moeten bijgehouden worden om ze gesorteerd terug te geven), en de operatie vereist ook dat de stream eindig is. Het sorteren kan immers pas uitgevoerd worden wanneer alle elementen gekend zijn.
block-beta columns 1 block:in C D A F E B end arrow<["sorted"]>(down) block:out AA["A"] BB["B"] CC["C"] DD["D"] EE["E"] FF["F"] end classDef str stroke:black,fill:orange class in,out str
peek
De peek-operatie doet eigenlijk niets: ze geeft alle elementen gewoon door, maar laat toe om een functie uit te voeren voor elk element.
Deze operatie kan bijvoorbeeld handig zijn om te debuggen: je kan ze middenin een pijplijn toevoegen om te kijken welke elementen daar voorbijkomen.
block-beta columns 1 block:in A B C D E F end arrow<["limit"]>(down) block:out AA["A"] BB["B"] CC["C"] space:3 end arrow2<["peek"]>(down) block:out2 AAA["A"] BBB["B"] CCC["C"] space:3 end arrow3<["filter"]>(down) block:out3 space BBBB["B"] CCCC["C"] space:3 end classDef str stroke:black,fill:orange class in,out,out2,out3 str
flatMap
De flatMap operatie is gelijkaardig aan de map-operatie, maar wordt gebruikt wanneer het resultaat van de map-functie op één element opnieuw een stream geeft.
Opnieuw bestaan er specifieke versies flatMapToInt, flatMapToLong, en flatMapToDouble voor wanneer het resultaat een IntStream, LongStream of DoubleStream moet worden.
We gebruiken de String::chars methode als voorbeeld; die geeft voor een String een IntStream terug met de char-values van elk karakter (denk: de ASCII of Unicode-waarde van elke letter).
Als we gewoon map zouden toepassen, krijgen we een stream van streams (hier: een stream van 3 streams, elk met 2 elementen):
block-beta columns 1 block:in Aa Bb Cc end arrow<["map"]>(down) block:out columns 3 block:blockA columns 2 A a end block:blockB columns 2 B b end block:blockC columns 2 C c end end classDef str stroke:black,fill:orange classDef str2 stroke:red,fill:yellow class in,out str class blockA,blockB,blockC str2
Vaak is dat niet wat we willen: stel dat we één lange stream van char-waarden (ints) willen maken, met daarin de karakters van alle woorden uit de oorspronkelijke stream na elkaar.
In dat geval gebruiken we flatMap (of, in dit geval, flatMapToInt omdat chars een IntStream teruggeeft):
block-beta columns 1 block:in Aa Bb Cc end arrow<["flatMap"]>(down) block:out columns 6 A a B b C c end classDef str stroke:black,fill:orange class in,out str
flatMap maakt dus in zekere zin een combinatie van een gewone map-operatie (die telkens een stream teruggeeft voor elk element), gevolgd door een concatenatie van al die resulterende streams.
De naam komt van het feit dat de resulterende structuur een ‘flattened’ versie is, waarbij één niveau van nesting weggehaald werd: waar map een stream van streams oplevert (bv. Stream<IntStream>), krijgen we bij flatMap (of hier flatMapToInt) één gewone stream terug (hier een IntStream).
mapMulti
De mapMulti operatie kan je gebruiken wanneer elk object in de bronstream kan leiden tot meerdere objecten in de doelstream, net zoals bij flatMap.
In tegenstelling tot flatMap, waar de mapping-operatie een stream moet teruggeven, werkt mapMulti anders.
Je moet hier namelijk geen stream teruggeven.
Aan mapMulti geef je een BiConsumer mee; dat is een functie met 2 argumenten (we noemen die hier value en output):
- Het eerste argument (
value) is het element uit de bronstream waarvoor de overeenkomstige elementen in de doelstream bepaald moeten worden - Het tweede argument (
output) is een Consumer-functie: elk element wat je daaraan doorgeeft (via deaccept-methode), komt terecht in de doelstream.
De functie die meegegeven wordt aan mapMulti moet dus alle objecten bepalen die voor het gegeven bronobject (value) in de doelstream terecht moeten komen, en die één voor één doorgeven aan output.
Een voorbeeld maakt dit hopelijk wat duidelijker.
Stel dat we de lijst \( [1, 2, 3] \) willen omzetten in \( [1, 2, 2, 3, 3, 3] \): elk getal in de bronstream wordt even vaak als zijn waarde herhaald in de doelstream.
We zouden dat met flatMap kunnen doen, door telkens een stream te maken van het juiste aantal elementen.
Dat doen we hieronder door een oneindige stream te maken (via generate) van telkens hetzelfde element (value), en dan elk van die streams te beperken tot de eerste value elementen:
Dankzij de laziness van streams (zie later) moeten we niet bang zijn dat de oneindige stream zal leiden tot een oneindige uitvoeringstijd; het aantal elementen dat we gebruiken wordt beperkt door de limit-operatie, en er zullen er nooit meer dan dat gegenereerd worden.
De versie met mapMulti ziet er wat anders (en misschien vertrouwder) uit — hier kunnen we gewone imperatieve code (lussen) schrijven:
block-beta columns 1 block:in AA["1"] BB["2"] CC["3"] end arrow<["mapMulti"]>(down) block:out A1["1"] B1["2"] B2["2"] C1["3"] C2["3"] C3["3"] end classDef str stroke:black,fill:orange classDef aa stroke:black,fill:#afa classDef cc stroke:black,fill:#aaf class AA,A1 aa class CC,C1,C2,C3 cc class in,out str
Terminale (terminal) operaties
Een terminale operatie staat op het einde van de pijplijn, na alle tussentijdse operaties. Na een terminale operatie kunnen dus geen extra operaties meer uitgevoerd worden met de elementen uit de stream.
De voorbeelden hierboven hadden geen terminale operaties. Een stream zonder terminale operatie doet niets: er wordt geen enkel element verwerkt, en er wordt geen enkele tussentijdse operatie uitgevoerd. Het is de terminale operatie die alle verwerking in gang zet. De reden daarvoor is de laziness van streams.
Laziness (luiheid)
We zeiden eerder al dat streams lazy zijn. Dat houdt in dat de gedefinieerde operaties niet uitgevoerd worden, tenzij het echt niet anders kan.
Bekijk bijvoorbeeld onderstaande code:
We maken een lijst van 10 getallen, voeren map uit op een stream van die getallen, en beperken het resultaat tot het eerste element.
Aangekomen op punt [1] werd er, misschien verrassend, helemaal niets uitgeprint.
Dat betekent dat de lambda-functie die \( n \) met 1 verhoogt ook niet uitgevoerd werd: er gebeurde helemaal niets met de getallen uit de lijst.
We definiëren met streams enkel de pijplijn: wat moet er later eventueel gebeuren met de getallen?
Pas wanneer we op punt [2] komen, en de terminale operatie forEach (zie later) uitgevoerd werd, werd er voor de eerste keer “Processing 1” uitgeprint.
Maar dan enkel voor het eerste element: door de limit-operatie is er geen nood aan het verwerken van het tweede, derde, … element, dus dat gebeurt ook nooit.
De code hierboven verwerkt dus enkel het eerste element uit de lijst; met alle andere elementen wordt nooit iets gedaan.
Het is dus belangrijk om in het achterhoofd te houden dat stream-operaties enkel uitgevoerd worden wanneer dat noodzakelijk is, en pas op het allerlaatste moment (als gevolg van een terminale operatie). Dat is efficiënt, maar kan soms leiden tot verrassende situaties (zoals hierboven).
We bekijken nu enkele vaak voorkomende terminale operaties.
toList, toArray
De terminale operatie toList maakt een nieuwe lijst met daarin de elementen op het einde van de pijplijn, in de volgorde dat ze daar toekomen.
Bijvoorbeeld:
Gelijkaardig is er ook toArray. Deze maakt een Object[] array aan met daarin de elementen.
Door de beperkingen van generics in Java (i.e., je mag niet new T[n] schrijven voor een generisch type T) kan er enkel een Object[] array gemaakt worden, geen String[].
Indien je dat wel wil, moet je een functie meegeven om een lege array van het juiste type en de juiste lengte aan te maken, bijvoorbeeld:
count
Zoals de naam aangeeft, telt de count()-operatie het aantal elementen op het einde van de stream.
Dat aantal wordt als een long teruggegeven, niet als int.
Bijvoorbeeld:
findFirst en findAny
De operaties findFirst en findAny geven respectievelijk het eerste en een niet nader bepaald element terug uit de stream.
Merk op dat findAny niet ‘random’ is; er zijn gewoon geen garanties over welk element precies teruggegeven wordt.
findAny is vooral nuttig bij parallelle streams (zie later).
Het resultaat van beide methodes is een Optional; die is leeg wanneer de stream leeg is, er dus geen element is om terug te geven.
anyMatch, allMatch, noneMatch
Deze methodes geven true of false terug, afhankelijk van of respectievelijk ten minste één, elk, of geen enkel element in de stream voldoet aan de meegegeven voorwaarde.
min en max
De min en max operaties vereisen een Comparator-object om elementen te vergelijken met elkaar.
Ze geven een Optional terug met het kleinste respectievelijk grootste element, of de lege optional indien de stream geen elementen bevat.
Bijvoorbeeld, onderstaande code geeft het element terug waarin de letter ‘a’ het vaakst voorkomt.
We maken dus een Comparator gebaseerd op het aantal a’s in het woord.
Om dat aantal te tellen, maken we opnieuw gebruik van een stream-pipeline, namelijk chars().filter().count():
Voor een IntStream, LongStream en DoubleStream hoef je geen Comparator mee te geven; daar worden uiteraard gewoon de getallen zelf vergeleken.
sum, average, summaryStatistics
De sum, average en summaryStatistics operaties zijn enkel beschikbaar op IntStream, LongStream en DoubleStream.
De eerste twee geven, weinig verrassend, de som en het gemiddelde van de waarden terug.
average geeft een OptionalDouble terug, omdat een lege stream geen gemiddelde heeft.
De summaryStatistics operatie geeft een object terug met daarin
- het aantal waarden (count)
- de kleinste waarde (min)
- de gemiddelde waarde (average)
- de grootste waarde (max)
- de totale waarde (sum)
Indien je meer dan één van die resultaten zoekt, is het dus efficiënter om deze methode te gebruiken dan de afzonderlijke operaties (die elk een nieuwe stream moeten doorlopen).
Een voorbeeld:
reduce
De reduce-operatie is een zeer veelzijdige operatie.
Ze combineert alle elementen in de stream tot één nieuwe waarde (dit is dus bijna de definitie van een terminale operatie).
We beschouwen hier de versie van reduce met twee argumenten, die een resultaat teruggeeft van hetzelfde type als de elementen in de stream:
- een startwaarde
identityvan typeT - een accumulator-functie
accumulator(een BinaryOperator) die een vorigeTcombineert met de huidigeTuit de stream, en de nieuweTteruggeeft
Met andere woorden, de reduce-operatie op een stream heeft het volgende effect:
Een andere manier om hiernaar te kijken is dat de accumulator een bewerking is die ingevoegd wordt tussen alle elementen van de stream;
de linker-parameter van de accumulator is de waarde tot dan toe, en de rechterparameter de volgende waarde om mee in rekening te brengen.
Bijvoorbeeld, we kunnen de som van alle elementen ook berekenen via reduce in plaats van via sum:
Of grafisch:
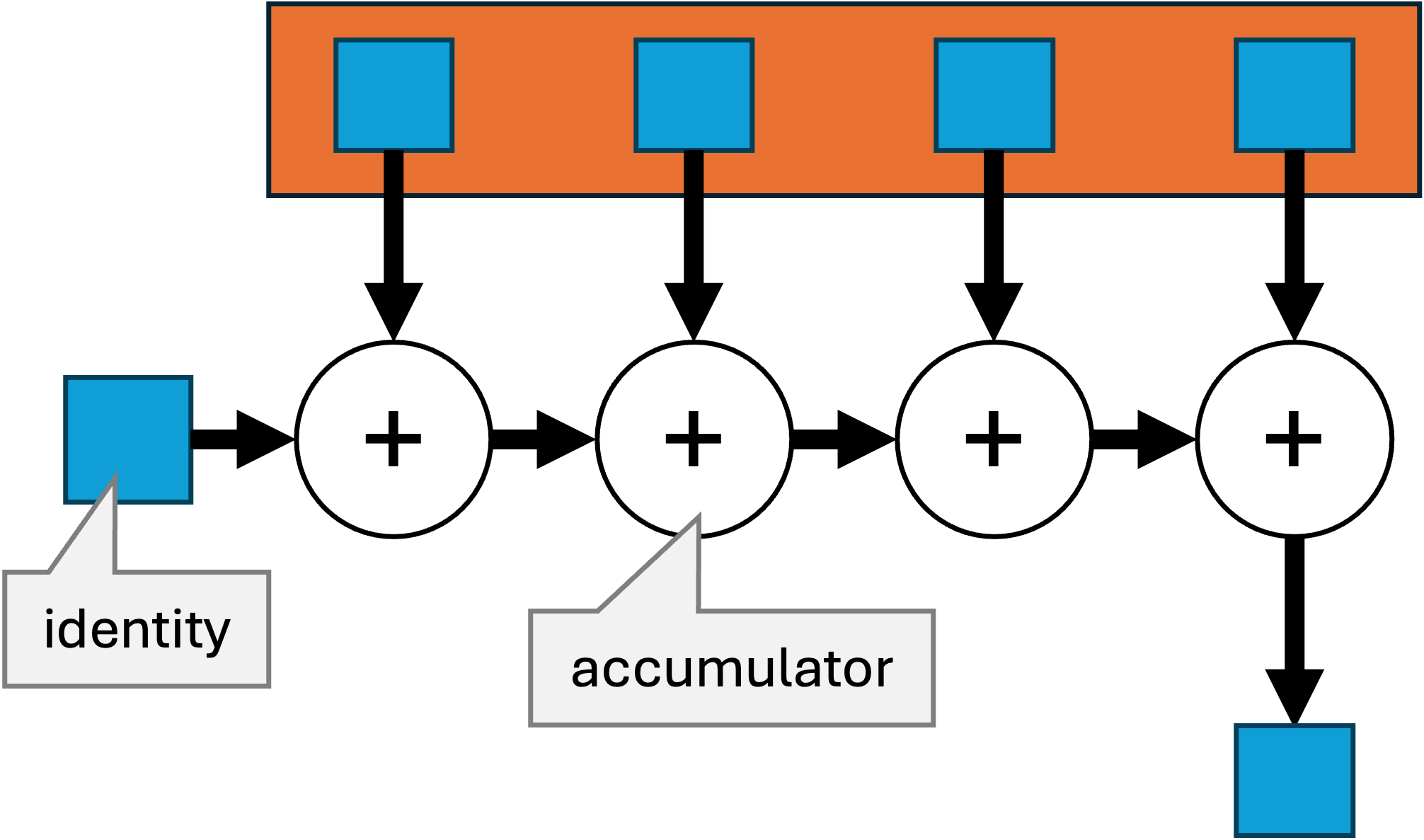
Weetje: in sommige andere programmeertalen wordt reduce ook fold genoemd (en de Java-versie van reduce is meer specifiek foldLeft).
collect
De laatste terminale operatie die we bekijken is collect.
Deze is gelijkaardig aan reduce, maar laat toe om de set van terminale operaties uit te breiden via Collector-objecten.
Een Collector-object bevat 4 elementen:
- een
supplier-functie (type Supplier) die wordt gebruikt om een startwaarde (state) te verkrijgen, vergelijkbaar met deidentitybijreduce - een
accumulator-functie (type BiConsumer) die een nieuw data-element toevoegt aan het voorlopige resultaat (de state); vergelijkbaar met de accumulator vanreduce - een
combiner-functie (type BinaryOperator) die twee voorlopige resultaten kan combineren (vooral nuttig bij parallelle uitvoering; zie later) - een
finisher-functie (type Function) die, op het einde, het voorlopige resultaat omzet naar het finale resultaat.
De supplier, accumulator, combiner en finisher werken conceptueel op de volgende manier:
Schematisch ziet dat er zo uit:
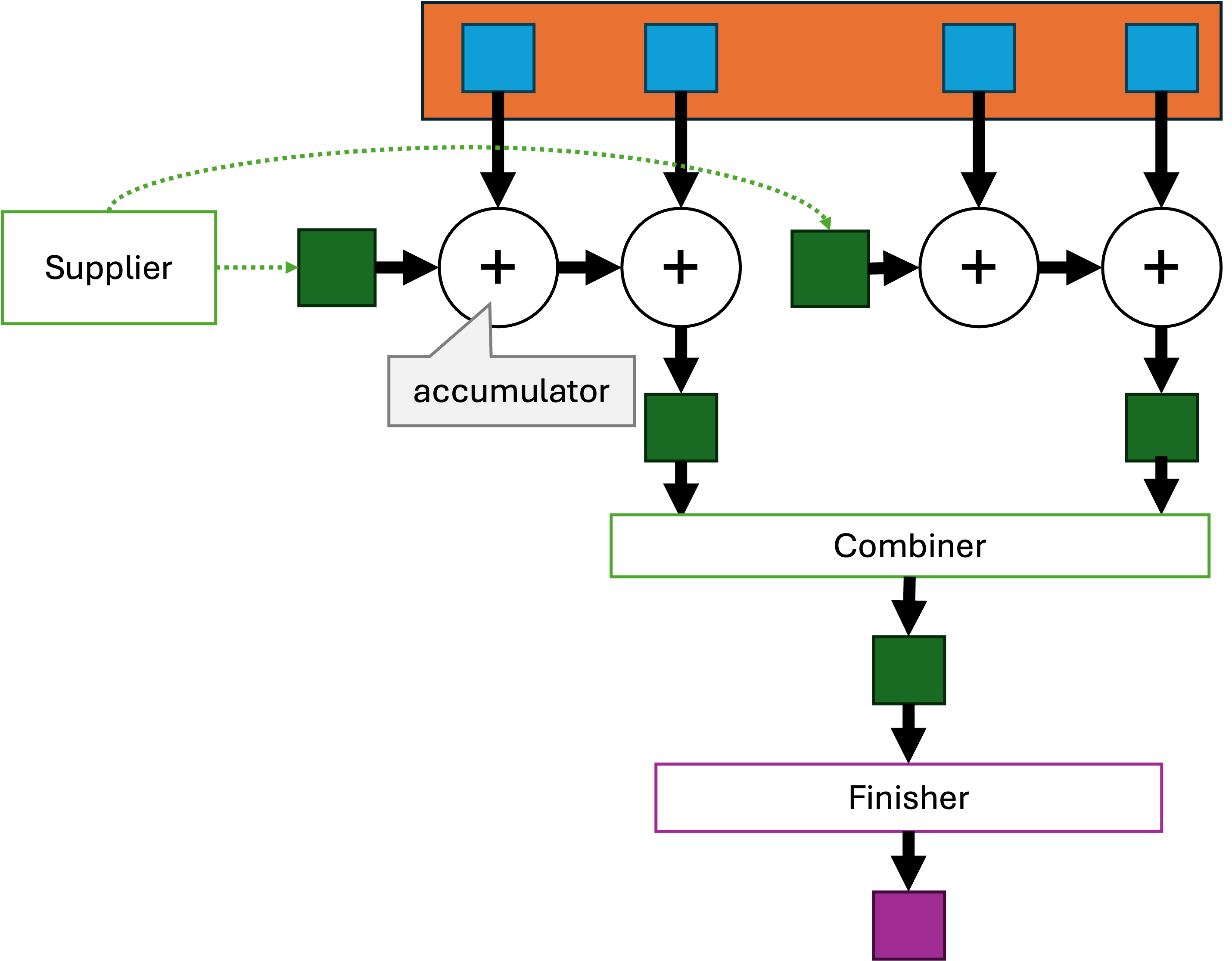
Merk op dat, in tegenstelling tot de accumulator bij reduce, er bij die van een collector niets wordt teruggegeven; de verwachting is dat het tijdelijke resultaat zelf geüpdated wordt (en dus stateful is).
Info
De combiner is enkel nuttig indien er meerdere deelresultaten zijn.
Dat is enkel het geval als de invoer-stream in meerdere delen opgedeeld kan worden.
Gewoonlijk gebeurt dat enkel bij parallelle streams (zie later).
Een gewone (sequentiële) stream heeft geen combiner nodig.
We geven één voorbeeld van een Collector-implementatie, namelijk een collector die (voor een stream van Strings) de Strings aan elkaar plakt tot één lange String, gescheiden door komma’s.
De state van de collector is een object van de klasse JoiningState.
Die state houdt de tot dan toe aan elkaar geplakte string bij (current), alsook of het eerste element nog toegevoegd moet worden (first).
We kunnen deze collector nu als volgt gebruiken:
Java bevat reeds enkele handige voorgedefinieerde collectors.
Deze vind je in de Collectors-klasse. We bekijken er enkele.
Collectors.joining
Deze collector doet wat we hierboven zelf implementeerden: Strings aan elkaar plakken, gescheiden door een separator-string. We hadden onszelf dus wat werk kunnen besparen, en gewoon het volgende schrijven:
Collectors.toList, Collectors.toSet, Collectors.toCollection
Deze collectors doen wat de naam zegt: ze maken een List, Set, of Collection met daarin de elementen van de stream.
De toList terminale operatie die we eerder zagen lijkt op Collectors.toList(), maar er is een belangrijk verschil:
stream.toList()geeft gegarandeerd een unmodifiable lijst terugcollect(Collectors.toList())geeft een lijst terug waarvan het concrete type niet gegarandeerd is; het kan dus aanpasbaar zijn of niet.
Bij toCollection ligt niet vast welk type collectie gemaakt moet worden; je moet zelf een functie meegeven (de collectionFacory) om een lege collectie van het gewenste type te maken:
Collectors.groupingBy
Deze collector groepeert de elementen vanuit een stream (van type T) in een Map<K, List<T>>, volgens de meegegeven functie om de key te bepalen:
Je kan ook een collector meegeven (de downstream collector) die bepaalt hoe de values geaggegregeerd worden in elke groep (als je die niet meegeeft wordt er een lijst gemaakt, zoals in het voorbeeld hierboven).
Deze downstream collector is een collector die de T’s in elke groep kan omzetten naar een resultaattype (V), om zo een Map<K, V> terug te geven.
Het resultaat hoeft dus niet hetzelfde type te hebben als de elementen in de oorspronkelijke stream.
Met andere woorden, groupingBy zet een stream van T’s om in meerdere streams, namelijk één stream per groep, en de downstream collector bepaalt hoe die streams verwerkt worden tot een eindresultaat.
Dat eindresultaat komt als value terecht in de resulterende map, met als key de waarde die bepaald werd door de eerste functie (de classifier).
We geven hier enkele voorbeelden van zo’n nuttige downstream collectors en hun gebruik in groupingBy.
Collectors.counting()
Deze collector telt simpelweg het aantal elementen. Bijvoorbeeld:
De count() terminale operatie van eerder is een kortere manier om bovenstaande te schrijven:
Collectors.counting() is dan ook vooral handig in combinatie met groupingBy.
Bijvoorbeeld, als je het aantal woorden per lengte wil tellen in de stream, kan je dat doen via groupingBy met counting als downstream collector:
Deze functie groepeert dus eerst alle woorden volgens hun aantal letters (met het eerste argument String::length), en telt vervolgens per groep het aantal woorden (met het tweede argument Collectors.counting()).
Je krijgt dus een Map<Integer, Long> terug, waarbij de key de woordlengte is, en de value het aantal woorden met die lengte.
Een visualisatie van het proces (voor een ander voorbeeld) vind je in volgende afbeelding:
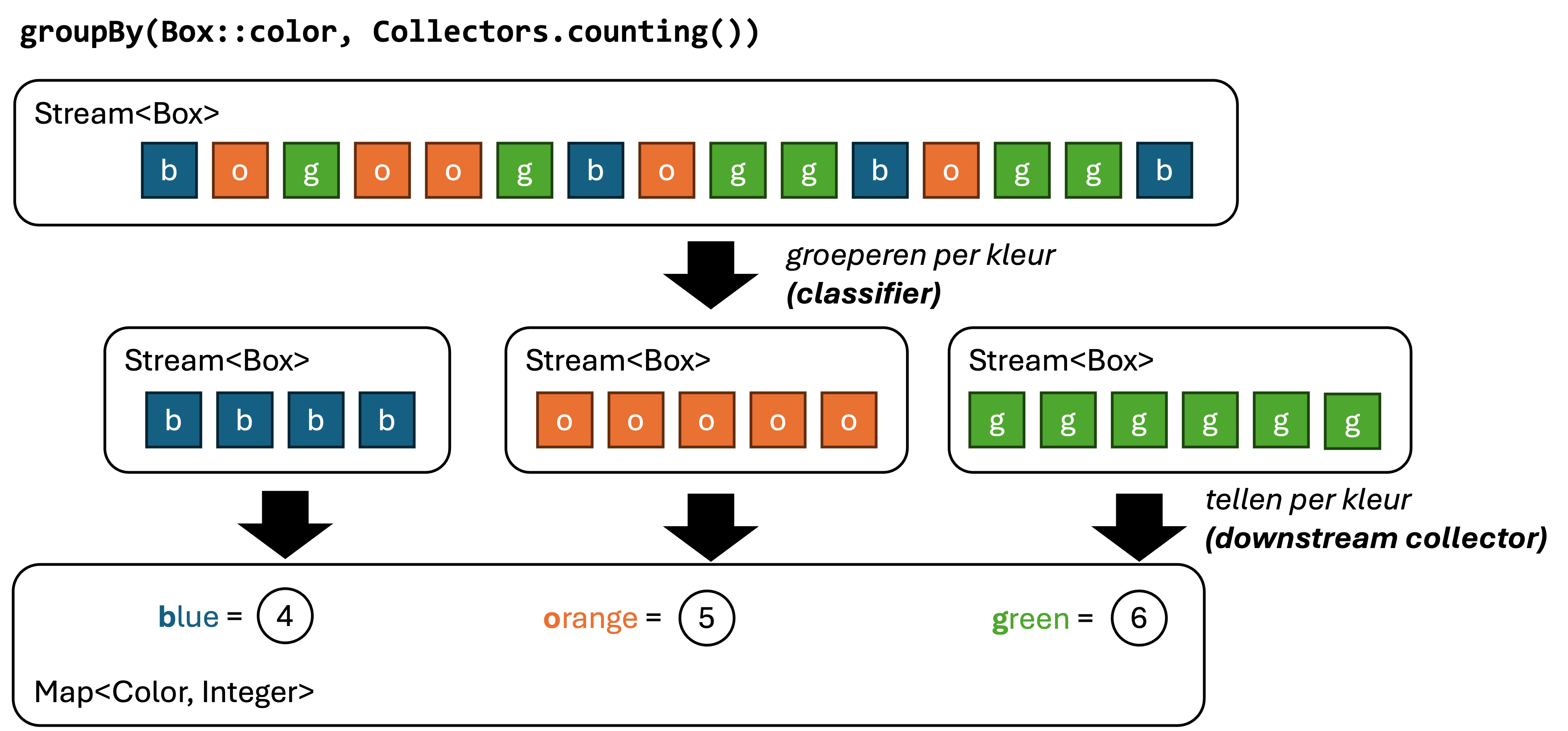
Hier wordt een stream van gekleurde Box-objecten gegroepeerd volgens hun kleur, en vervolgens per kleur het aantal Boxen geteld.
Collectors.summingInt, summingLong, summingDouble
Deze collector zet eerst elk element om naar een int volgens de meegegeven functie (dus equivalent aan een mapToInt) en telt deze vervolgens op.
Er zijn ook gelijkaardige collectors voor long en double.
Bijvoorbeeld, om het totaal aantal karakters te tellen van de woorden in een stream kunnen we summingInt als volgt gebruiken:
Dit konden we ook al via een mapToInt gevolgd door sum:
Het gebruik van summingInt als downstream collector bij groupingBy is ook mogelijk, en nuttiger.
We kunnen dit bijvoorbeeld gebruiken om het totaal aantal karakters te tellen van de woorden per beginletter:
Dus: de woorden die met een ‘a’ beginnen hebben samen 5 letters, en de woorden die met een ‘b’ beginnen hebben samen 12 letters.
Collectors.mapping
Deze collector past een functie toe op elk element, en verwerkt vervolgens de resultaten met een downstream collector.
Bijvoorbeeld, als we de woorden in hoofdletters willen hebben in plaats van kleine letters, kunnen dat doen via mapping:
Dat is uiteraard equivalent aan een gewone map gevolgd door toList:
In combinatie met groupingBy kan dit bijvoorbeeld gebruikt worden om de woorden per beginletter te groeperen, met telkens de lengte van de woorden:
Er zijn dus twee woorden die met ‘a’ beginnen, met respectievelijk 5 en 8 letters, één woord dat met ‘b’ begint en 5 letters heeft, en twee woorden die met ‘c’ beginnen, elk met 7 letters.
Collectors.flatMapping
Deze collector is gelijkaardig aan Collectors.mapping(), maar de functie die je meegeeft moet een stream teruggeven, en de resultaten van al die streams worden samengevoegd tot één stream.
Dat komt overeen met de flatMap-operatie, maar dan in de context van collectors.
Je geeft aan flatMapping dus een functie mee die één element uit de oorspronkelijke stream omzet naar een nieuwe stream, en ook een downstream collector die de elementen van die resulterende streams verwerkt.
Bijvoorbeeld, stel dat we een Stream<String> als bron hebben, en we willen een List<Character> terugkrijgen met alle karakters uit alle woorden, dan kunnen we dat als volgt doen:
boxed
mapToObj() is nodig omdat chars() een IntStream teruggeeft.
Die moet omgezet worden naar een Stream<Character>, omdat flatMapping een Stream<? extends Object> verwacht, en geen IntStream
Zonder mapToObj() zou de code niet compileren.
In combinatie met groupingBy kan dit bijvoorbeeld gebruikt worden om alle letters per woordlengte in een Set te groeperen:
Collectors.partitioningBy
Deze collector groepeert de elementen ook in een Map, maar nu met als key true of false, afhankelijk van of het object voldoet aan de meegegeven voorwaarde of niet:
Ook hier bestaan, net zoals bij groupingBy, varianten waarbij je een downstream collector kan meegeven om de values te aggregeren.
Bijvoorbeeld, als we het aantal korte en lange woorden willen tellen, kunnen we dat doen via partitioningBy met counting als downstream collector:
Collectors.toMap
Met Collectors.toMap maak je een Map door twee argumenten mee te geven: een key-functie en value-functie.
De key-functie bepaalt de key voor elk element in de stream, en de value-functie bepaalt de waarde die aan die key gekoppeld wordt.
Let op: als twee elementen dezelfde key produceren, krijg je standaard een IllegalStateException.
Als duplicate keys mogelijk zijn, geef dan expliciet een merge-functie mee (als derde argument) die aangeeft hoe twee waarden gecombineerd moeten worden tot 1 waarde in de Map:
forEach
De forEach(fn) terminale operatie voert de meegegeven functie fn uit voor elk element dat het einde van de pijplijn bereikt.
Een heel eenvoudig gebruik hiervan is het uitprinten van alle elementen via IO.println:
De forEach-operatie is dus zowat het streams-equivalent van de enhanced for-loop (for (var x : collection)) bij collecties.
Opgelet
Vermijd het gebruik van forEach om een variabele/lijst/… buiten de forEach-lambda aan te passen, zoals het toevoegen aan de result-lijst in onderstaand voorbeeld.
Meestal is dit een antipattern, en is er een betere manier om hetzelfde resultaat te bekomen.
De betere manier hier is uiteraard
Parallelle streams
Vaak kunnen operaties in een stream efficiënt in parallel gebeuren.
Denk bijvoorbeeld aan map of filter: deze gebeuren element per element, en zijn dus onafhankelijk van wat er met de andere elementen gebeurt.
Je kan in Java daarom ook een parallelle stream aanmaken.
Deze zal, bij uitvoering, meerdere threads gebruiken om de stream te verwerken.
Het is eenvoudig om een stream parallel te maken: dat kan via de parallel() intermediate operatie, of de parallelStream()-operatie op collecties.
Er is ook een sequential() operatie die de stream sequentieel maakt.
Merk op dat de mode waarin de stream zich bevindt op het moment van de terminale operatie bepaalt hoe de hele stream uitgevoerd wordt; je kan dus geen deel van de operaties parallel en een ander deel sequentieel uitvoeren.
Parallelle streams zijn niet automatisch sneller: de overhead van het opsplitsen, schedulen en samenvoegen van deelresultaten kan groter zijn dan de winst. Voor kleine datasets of goedkope bewerkingen is een sequentiële stream vaak efficiënter. Meet dus altijd eerst voor je parallelle streams als optimalisatie inzet.
Nog meer streams? (optioneel)
Gatherers
Via de Collector-API kan je, zoals we gezien hebben, zelf al nieuwe collectors toevoegen.
Voor de tussentijdse operaties ben je via de streams API echter beperkt tot de voorgedefinieerde tussentijdse operaties; maar je kan er veel meer bedenken.
Onderstaande presentatie bespreekt Gatherers, de oplossing die sinds Java 24 aangeboden wordt om zelf nieuwe tussentijdse operaties te definiëren.
Gebruik dit enkel als je met Java 24 of nieuwer werkt; in Java 21 is Gatherer nog niet beschikbaar.
Spliterators
Streams (en parallelle streams in het bijzonder) maken gebruik van Spliterators.
Dat is een variant op een iterator, die (naast de elementen overlopen, zoals bij een gewone iterator) ook de elementen van een bron (bv. een collectie) in 2 delen kan splitsen.
Bij parallelle streams zal dan elk van die delen afzonderlijk (in een aparte thread) verwerkt worden.
Meer info over Spliterators vind je in onderstaande presentatie.
Omdat
intmaar een eindig aantal waarden kan hebben (de hoogste waarde is \( 2^{31}-1 \)), zal deze stream ooit negatieve getallen beginnen produceren: …, 2147483646, 2147483647, -2147483648, -2147483647, …. De stream is wel nog steeds oneindig. ↩︎