7.4 Multithreading en concurrency
In andere programmeertalen
De concepten in andere programmeertalen die het dichtst aanleunen bij Java’s multithreading en concurrency primitieven zijn
- pthreads in C
std::threaden aanverwanten in C++- de
threadingenmultiprocessingmodules in Python - de
System.Threadingnamespace in C#
Wat en waarom?
We maken eerst onderscheid tussen de begrippen parallellisme en concurrency.
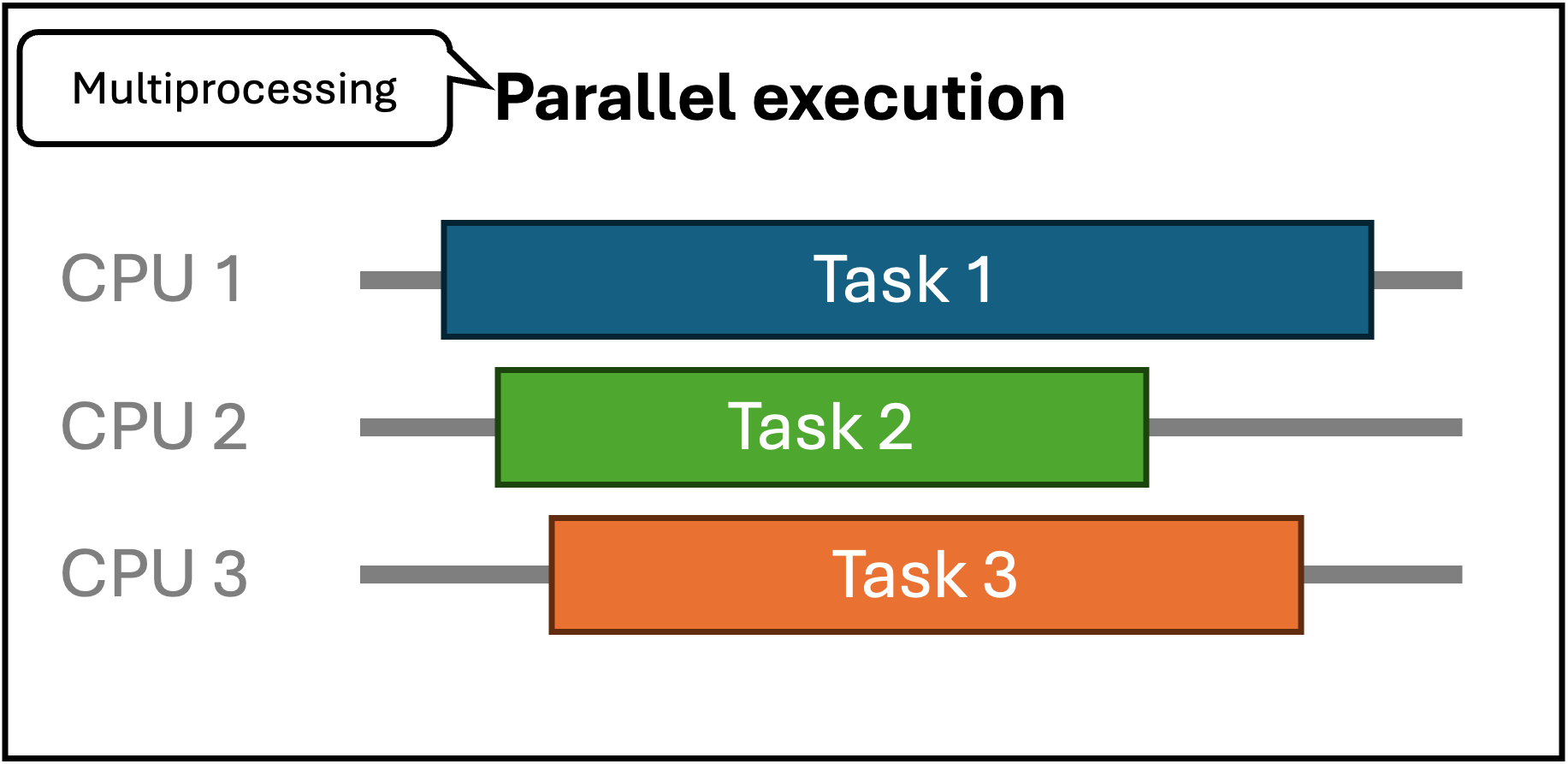
Bij parallellisme (soms ook multiprocessing genoemd) worden meerdere instructies gelijktijdig uitgevoerd. Dit vereist meerdere verwerkingseenheden (machines, CPU’s, CPU cores, …) waarop die instructies uitgevoerd kunnen worden. Parallellisme wordt interessant wanneer er veel instructies uitgevoerd moeten worden die onafhankelijk van elkaar kunnen gebeuren. Hoe meer afhankelijkheden er zijn, hoe meer er gecoördineerd moet worden, wat leidt tot meer overhead.
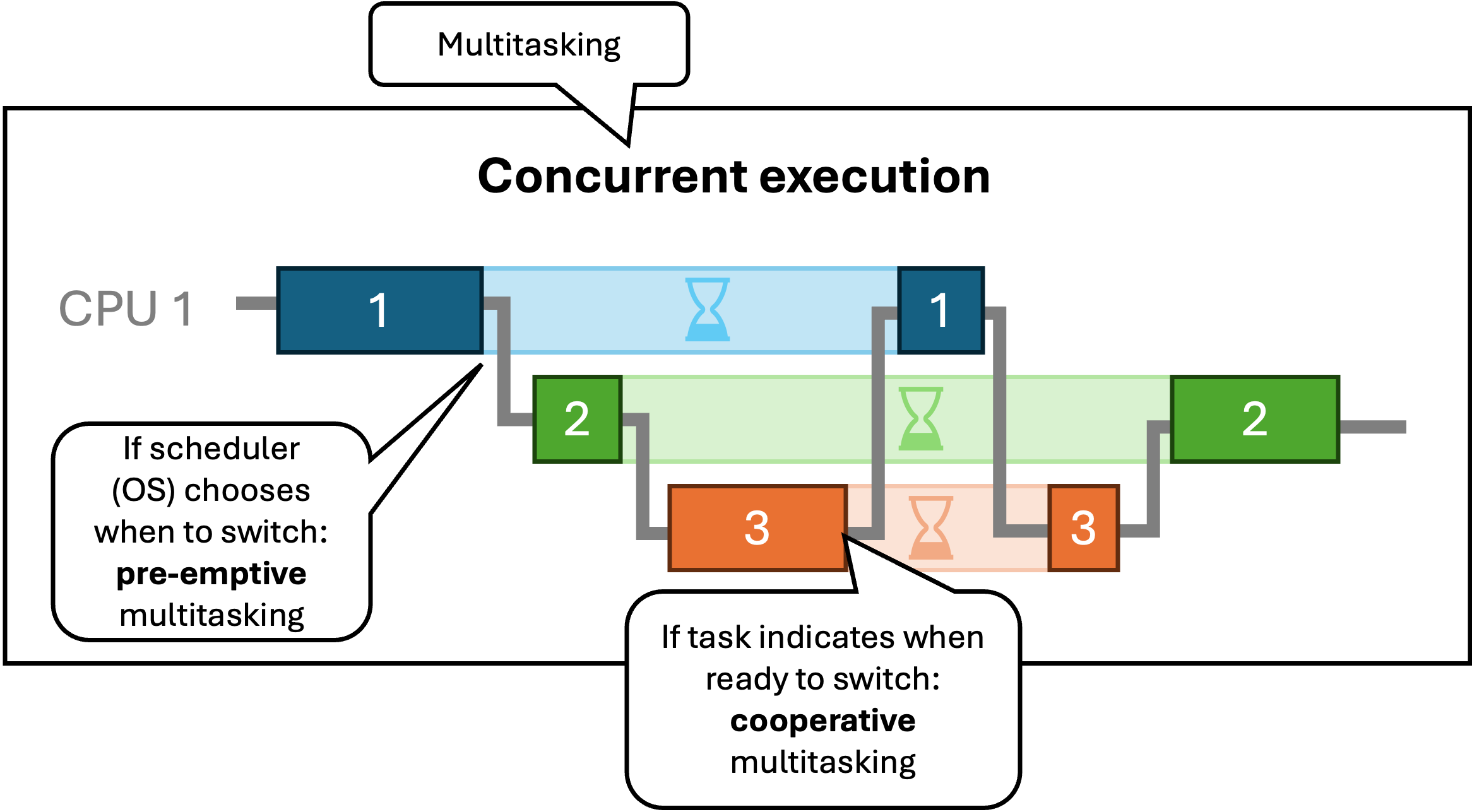
Bij concurrency (soms ook multitasking genoemd) zijn meerdere taken actief op een bepaald moment. Dat betekent dat een tweede taak al kan starten voordat de eerste afgelopen is. Het hoeft echter niet zo te zijn dat er ook gelijktijdig instructies voor elk van die taken uitgevoerd worden. Concurrency impliceert dus geen parallelisme: je kan concurrency hebben met slechts 1 single-core CPU. Er zijn meerdere mogelijkheden om concurrency te bereiken met slechts één CPU:
- pre-emption: een externe scheduler (bijvoorbeeld in het besturingssysteem) beslist wanneer en voor hoelang een bepaalde taak de processor ter beschikking krijgt. Een voorbeeld hiervan is time slicing: het besturingssysteem onderbreekt elke taak na een bepaalde vaste tijd (of aantal instructies), om de controle vervolgens aan een andere taak te geven.
- cooperative multitasking: een taak beslist zelf wanneer die de controle teruggeeft, bijvoorbeeld wanneer er gewacht moet worden op een ’trage’ operatie zoals het lezen van een bestand, het ontvangen van een inkomend netwerkpakket, …. Veel programmeertalen (maar niet Java) ondersteunen coöperatieve multitasking via coroutines en async/await keywords.
Het spreekt voor zich dat, op moderne (multi-core) machines, concurrency en parallelisme vaak gecombineerd worden. Er zijn dus meerdere taken actief, waarvan sommige ook tegelijkertijd uitgevoerd worden.
Multithreading tenslotte is een specifiek concurrency-mechanisme: er worden, binnen eenzelfde proces van het besturingssysteem, meerdere ’threads’ gestart om taken uit te voeren. Deze threads delen hetzelfde geheugen (namelijk dat van het proces), en kunnen daardoor dus efficiënter data uitwisselen dan wanneer elke taak als apart proces gestart zou worden. Op elk moment kunnen er dus meerdere threads bestaan, die (afhankelijk van of er ook parallellisme is in het systeem) al dan niet gelijktijdig instructies uitvoeren. Binnen een Java-programma is multithreading de voornaamste manier om zowel parallelisme als concurrency te bereiken.
IO-bound vs CPU-bound tasks
De taken die al dan niet gelijktijdig uitgevoerd moeten worden, kunnen onderverdeeld worden in zogenaamde CPU-bound en IO-bound taken.
Bij een CPU-bound taak wordt de uitvoeringstijd voornamelijk gedomineerd door de uitvoering van instructies (berekeningen), bijvoorbeeld algoritmes, beeldverwerking, simulaties, …. Hoe sneller de CPU, hoe sneller de taak dus afgewerkt kan worden.
Een IO-bound task daarentegen is vaak aan het wachten op externe gebeurtenissen (interrupts), zoals netwerk- of schijf-toegang, timers, gebruikersinvoer, … Een snellere CPU zal deze taak niet sneller doen gaan.
In het algemeen is parallellisme vooral nuttig wanneer er veel CPU-bound taken zijn. De totale tijd die nodig is om alle taken uit te voeren kan op die manier geminimaliseerd worden. Voor IO-bound tasks is parallelisme niet noodzakelijk een goede oplossing: de verschillende CPU’s zouden gelijktijdig aan het wachten zijn op externe interrupts. Het gebruik van concurrency kan hier wel soelaas bieden: terwijl één taak wacht op een externe gebeurtenis, kan een andere verder uitgevoerd worden.
Threads in Java
De basisklasse in Java om te werken met multithreading is de Thread-klasse.
Typisch geef je een Runnable mee die uitgevoerd moet worden.
Dat kan een object zijn, een lambda, of een method reference.
Een aangemaakte thread start niet automatisch; om de uitvoering van de thread te starten, moet je de start-methode oproepen.
Als je wil wachten tot de thread afgelopen is, kan dat via de join-methode. Deze blokkeert de uitvoering tot de uitvoering van de thread afloopt.
Je kan ook een timeout meegeven aan join, met de maximale tijdsduur dat je wilt wachten. Als deze tijd voorbij is vooraleer de thread afloopt, wordt een InterruptedException gegooid.
Bijvoorbeeld: onderstaande code start een nieuwe thread, die een regel uitprint. Er zijn in het programma dus twee threads actief: (1) de thread die de nieuwe thread aanmaakt, start, en er vervolgens (maximaal 2 seconden) op wacht; en (2) de thread die de boodschap uitprint.
Note
Een exception in een thread komt niet terug terecht in de originele thread; deze kan dus ‘verloren’ gaan.
var t1 = new Thread(() -> {
System.out.println("Hello from a new thread");
});
t1.start();
...
t1.join(Duration.ofSeconds(2));Een standaard Java thread wordt uitgevoerd met een thread van het besturingssysteem (een platform thread, die typisch overeenkomt met een kernel thread). Zo krijg je dus, op machines die het ondersteunen, ook automatisch parallellisme in Java: meerdere threads kunnen effectief tegelijkertijd instructies uitvoeren. Een nadeel hiervan is dat het aantal threads beperkt is: elke platform-thread komt met een zekere overhead.
Sinds Java 21 beschikt Java ook over virtual threads. Dat zijn threads die beheerd worden door de Java Virtual Machine (JVM) zelf, en dus niet 1-1 overeenkomen met een platform thread. Je JVM zal een virtuele thread koppelen aan een platform thread, en deze terug ontkoppelen op het moment dat de virtuele thread moet wachten op een trage operatie. De platform thread is dan terug vrij, en kan gebruikt worden om een andere virtuele thread uit te voeren. Virtual threads zijn het Java-alternatief voor cooperative multitasking. Het teruggeven van de controle wordt echter afgehandeld door de onderliggende bibliotheken, dus als programmeur word je niet geconfronteerd met wachten op blokkerende operaties, of async/await keywords. Je schrijft je code dus gewoon zoals sequentiële code zonder rekening te houden met mogelijk blokkerende operaties. Virtuele threads hebben ook weinig overhead; je kan er zonder probleem duizenden van aanmaken zonder significante impact op de performantie.
We gaan het in de rest van dit hoofdstuk enkel hebben over de gewone (platform) threads, dus niet over virtual threads.
Synchronisatie
Wanneer meerdere threads (of processen) met gedeelde data werken, ontstaat er een nood aan synchronisatie. Het kan immers zijn dat beide threads dezelfde data lezen en/of aanpassen, waardoor de data inconsistent wordt. Dat wordt een race-conditie genoemd.
Race-conditie
Neem het voorbeeld hieronder: één thread verhoogt de waarde van een teller 10.000 keer, de andere verlaagt die 10.000 keer. Welke waarde van de teller verwacht je op het einde van de code?
class Counter {
private int count = 0;
public void increment() { count++; }
public void decrement() { count--; }
public int getCount() { return count; }
}
var counter = new Counter();
var inc = new Thread(() -> {
for (int i = 0; i < 10_000; i++) counter.increment();
});
var dec = new Thread(() -> {
for (int i = 0; i < 10_000; i++) counter.decrement();
});
inc.start(); dec.start();
inc.join(); dec.join();
System.out.println(counter.getCount());Op mijn machine gaven drie uitvoeringen van dit programma achtereenvolgens de waarden -803, -5134, en 3041.
Hoe kan dat? Er worden toch evenveel increments uitgevoerd als decrements, waardoor de teller terug op 0 moet uitkomen?
De reden is dat het lezen en terug wegschrijven van de (verhoogde of verlaagde) variabele (i.e., count++ en count--) twee afzonderlijke operaties zijn,
die door het onderlinge verschil in timing tussen de threads op verschillende momenten kunnen plaatsvinden.
Bijvoorbeeld, stel dat count op een bepaald moment gelijk is aan 40; de inc-thread verhoogt de teller 2 keer, en de dec-thread verlaagt de teller 1 keer,
in onderstaande volgorde:
Thread inc | Thread dec |
|---|---|
| lees count=40 | |
| lees count=40 | |
| zet count=41 | |
| lees count=41 | |
| zet count=42 | |
| zet count=39 |
De teller is nu niet 41 (wat de correcte waarde zou zijn na 2 verhogingen en 1 verlaging), maar 39.
De twee verhogingen hebben dus geen enkel effect gehad.
Door andere volgordes (interleavings) van beide threads kan je zo verschillende resultaten krijgen: count kan (in theorie) elke waarde tussen -10.000 en 10.000 hebben op het einde van het programma.
We zeggen dat de Counter-klasse niet thread-safe is: ze kan niet correct gebruikt worden door meerdere threads zonder extra maatregelen.
Volatile variabelen
Bovenstaande code heeft ook nog een ander probleem: wanneer de code uitgevoerd wordt op meerdere CPU’s of cores, kan het kan zijn de count variabele enkel in het lokale geheugen van één CPU aangepast wordt (bv. een register, L1 cache, …), en nog niet meteen naar het (gedeelde) geheugen teruggeschreven wordt.
Zelfs als de tweede thread de waarde van count pas uitleest nadat deze aangepast is door de eerste thread, kan het zijn dat die nog een oude waarde ziet:
Thread inc | Thread dec |
|---|---|
| lees count=40 | |
| zet count=41 | |
| lees count=41 | |
| zet count=42 | |
| lees count=40 | |
| zet count=39 | |
| schrijf count naar geheugen | |
| schrijf count naar geheugen |
Om dit op te lossen, kan je in Java een variabele als volatile markeren.
Dat garandeert dat alle aanpassingen aan die variabele meteen naar het centrale geheugen geschreven worden, en vermijdt bovenstaande situatie.
class Counter {
private volatile int count = 0;
public void increment() { count++; }
public void decrement() { count--; }
public int getCount() { return count; }
}Een volatile variabele is dus een variabele waarvan alle threads steeds de laatste waarde zien.
Technisch gezien komt volatile eigenlijk met een nog sterkere garantie: als thread B een volatile variabele leest die door thread A geschreven werd, zullen ook alle andere (niet-volatile) variabelen die B daarna leest, de waarde hebben die ze in thread A hadden voordat die thread de volatile variabele aanpaste. Met andere woorden, thread B ziet consistente waarden voor alle variabelen die een invloed gehad zouden kunnen hebben op de huidige waarde van de volatile variabele.
Het schrijven en vervolgens lezen van een volatile variabele is dus een synchronisatie-punt tussen threads.
Bijvoorbeeld, stel dat t, u, v, en w vier variabelen zijn, waarvan enkel v als volatile gemarkeerd is. Alle variabelen hebben oorspronkelijk 0 als waarde.
In de tabel hieronder is met een * aangegeven welke waarden in thread B gegarandeerd de meest recente waarden zijn.
In het bijzonder zal variabele w niet noodzakelijk de laatste waarde hebben, omdat die door thread A na variabele v geschreven werd.
Ook variabele u zal, vooraleer v gelezen wordt, niet noodzakelijk de meest recente waarde bevatten.
| Thread A | Thread B |
|---|---|
| schrijf t=1 | |
| schrijf u=1 | |
| schrijf v=1 (volatile) | |
| schrijf w=1 | |
| lees u=? | |
| lees v=1 (volatile) * | |
| lees t=1 * | |
| lees u=1 * | |
| lees w=? |
Merk wel op dat het gebruik van volatile de race-conditie van hierboven nog steeds niet oplost!
Een variabele als volatile markeren heeft immers enkel invloed op de zichtbaarheid van die variabele. Het biedt geen garanties bij gelijktijdige aanpassingen door meerdere threads.
Daarvoor hebben we synchronisatie nodig.
Synchronizatie-primitieven
Om race condities te voorkomen, moet je toegang tot gedeeld geheugen op een of andere manier synchroniseren. Meer specifiek wil je een sequentie van operaties atomisch kunnen maken: ze moeten worden uitgevoerd alsof ze één primitieve operatie zijn, die niet onderbroken kan worden door een andere thread. In het voorbeeld van hierboven wil je dus dat het lezen, verhogen, en wegschrijven van de teller steeds als één geheel uitgevoerd wordt, in plaats van als twee aparte operaties.
Java biedt meerdere synchronizatie-primitieven aan. Sommigen zitten ingebouwd in de taal (bv. volatile en synchronized; zie later), andere zitten in de packages java.util.concurrent en java.util.concurrent.locks.
We bespreken er hier enkele.
Semafoor
Een Semaphore deelt een gegeven maximum aantal toestemmingen uit aan threads (via acquire()). Alle volgende threads die toestemming willen, moeten wachten tot een van de vorige toestemmingen terug ingeleverd wordt (via release()). Een binaire semafoor (met maximaal 1 toestemming) kan dienen als mutual exclusion lock (mutex). Een semafoor houdt (conceptueel) enkel een teller bij van het resterend aantal toestemmingen, en niet welke thread al toestemming heeft. Er is dan ook geen enkele garantie of verificatie dat een thread die release() oproept effectief zo’n toestemming verkregen had; het aantal beschikbare toestemmingen wordt gewoon terug verhoogd.
Een voorbeeld van het gebruik van een semafoor voor de implementatie van Counter:
class Counter {
private volatile int count = 0;
private final Semaphore sem = new Semaphore(1);
public void increment() throws InterruptedException {
sem.acquire();
try {
count++;
} finally {
sem.release();
}
}
public void decrement() throws InterruptedException {
sem.acquire();
try {
count--;
} finally {
sem.release();
}
}
public int getCount() {
return count;
}
}Met het gebruik van een semafoor voor synchronisatie krijg je ook automatisch zichtbaarheids-garanties; je kan het vrijgeven van de semafoor beschouwen als het schrijven naar een volatile variabele, en het verkrijgen van een toestemming als het lezen van een volatile variabele.
Alle wijzigingen die gedaan worden voor het vrijgeven van de semafoor zijn dus zichtbaar voor alle threads die nadien een toestemming verkrijgen.
Lock
De Lock interface, en de implementaties ReentrantLock, stellen een mechanisme voor waarbij een thread de lock kan verkrijgen (lock()) en terug vrijgeven (unlock()). Hierbij wordt wél nagegaan dat enkel de thread die de lock verkregen heeft, de lock terug kan vrijgeven. ‘Re-entrant’ betekent dat een thread die reeds een lock heeft, verder mag gaan wanneer die een tweede keer lock() oproept (op hetzelfde lock-object).
Een voorbeeld van het gebruik van een ReentrantLock voor de implementatie van Counter:
class Counter {
private volatile int count = 0;
private final Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public void decrement() {
lock.lock();
try {
count--;
} finally {
lock.unlock();
}
}
public int getCount() {
return count;
}
}Net zoals bij een semafoor krijg je bij het gebruik van een lock ook automatisch zichtbaarheids-garanties; je kan ‘unlock()’ beschouwen als het schrijven naar een volatile variabele, en ’lock()’ als het lezen van een volatile variabele.
Alle wijzigingen die gedaan worden voor het unlocken zijn dus zichtbaar voor alle threads die nadien lock uitvoeren.
AtomicInteger
Specifiek voor primitieve types biedt Java ook een verzameling atomische objecten aan, bijvoorbeeld AtomicInteger. Daarop zijn operaties gedefinieerd zoals incrementAndGet, updateAndGet, getAndAdd, …. Bovenstaande counter kan dus ook eenvoudig als volgt geïmplementeerd worden:
class Counter {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() { count.incrementAndGet(); }
public void decrement() { count.decrementAndGet(); }
public int getCount() { return count.get(); }
}Er zijn ook andere klassen, bijvoorbeeld AtomicLong, AtomicBoolean, AtomicIntegerArray, AtomicReferenceArray, …
Deze klassen zijn efficiënt geïmplementeerd, en hebben dus de voorkeur wanneer er enkel gesynchroniseerd moet worden om een primitieve variabele of array aan te passen.
Synchronized
Het gebruiken van een lock is zo alomtegenwoordig dat, in Java, elk object als een lock gebruikt kan worden door middel van het synchronized keyword.
Bijvoorbeeld:
class Counter {
private volatile int count = 0;
private final Object lock = new Object();
public void increment() {
synchronized (lock) {
count++;
}
}
public void decrement() {
synchronized (lock) {
count--;
}
}
public int getCount() {
return count;
}
}Op deze manier beschikt elk Counter-object over een eigen object dat als lock gebruikt wordt. Het synchronized-block geeft aan dat dat lock nodig is om de code in het bijhorende blok uit te voeren, en de lock wordt automatisch terug vrijgegeven op het einde van dat block.
Omdat elk object in Java zo als lock gebruikt kan worden, hoeven we geen apart object aan te maken; we kunnen ook gewoon this gebruiken:
class Counter {
private volatile int count = 0;
public void increment() {
synchronized (this) {
count++;
}
}
public void decrement() {
synchronized (this) {
count--;
}
}
public int getCount() {
return count;
}
}Tenslotte laat Java ook toe om een hele methode als synchronized te definiëren.
Dat heeft hetzelfde effect als de code met synchronized(this) hierboven:
class Counter {
private volatile int count = 0;
public synchronized void increment() {
count++;
}
public synchronized void decrement() {
count--;
}
public int getCount() {
return count;
}
}Code die gebruik maakt van synchronized heeft ook zichtbaarheids-garanties; je kan het einde van een synchronized-block beschouwen als het schrijven naar een volatile variabele (die hoort bij het object waarop gesynchroniseerd wordt), en het begin ervan als het lezen van die volatile variabele.
Alle wijzigingen die gedaan worden voor of in een synchronized-blok of methode zijn dus zichtbaar voor alle threads die nadien een synchronized-blok of methode uitvoeren, tenminste als er gesynchroniseerd wordt op hetzelfde object.
In onderstaande code is er dus geen garantie dat thread B de acties van thread A ziet:
Object lock1 = new Object();
Object lock2 = new Object();
// in thread A
synchronized(lock1) {
// acties van A
}
// later...
// in thread B
synchronized(lock2) {
// acties van B
}Deadlocks
Threads die werken met locks kunnen in een deadlock geraken wanneer ze op elkaar wachten. Geen enkele thread kan dan vooruitgang maken. Bijvoorbeeld, in onderstaande code heeft de counter een apart read- en write-lock. Beide threads proberen om de twee locks te verkrijgen, maar in omgekeerde volgorde.
class Counter {
public final Object readLock = new Object();
public final Object writeLock = new Object();
public volatile int value;
}
var counter = new Counter();
var inc = new Thread(() -> {
for (int i = 0; i < 10_000; i++) {
synchronized (counter.readLock) {
synchronized (counter.writeLock) {
counter.value++;
}
}
}
});
var dec = new Thread(() -> {
for (int i = 0; i < 10_000; i++) {
synchronized (counter.writeLock) {
synchronized (counter.readLock) {
counter.value--;
}
}
}
});
inc.start(); dec.start();
inc.join(); dec.join();
System.out.println(counter.value);In sommige gevallen kan dat leiden tot een deadlock, namelijk wanneer een thread onderbroken wordt tussen het verkrijgen van beide locks:
Thread inc | Thread dec |
|---|---|
| acquire readLock | |
| acquire writeLock | |
| wait (forever) for readLock … | |
| wait (forever) for writeLock… |
Er is geen eenvoudige manier om deadlocks te vermijden, behalve de applicatie erg zorgvuldig te ontwerpen. Enkele technieken die hierbij kunnen helpen zijn:
- niet meer locken dan strikt noodzakelijk
- locks altijd in een welbepaalde volgorde verkrijgen
- timeouts gebruiken
Immutability
Wanneer we praten over concurrency, is het een goed idee om ook immutability te vermelden.
Een immutable object kan nooit van waarde wijzigen: eens aangemaakt blijven alle waardes hetzelfde.
In de praktijk betekent dat dat alle velden van het object als final gedeclareerd worden.
Wanneer meerdere threads eenzelfde immutable object gebruiken, kunnen er per definitie geen race condities optreden; ook beschikt elke thread altijd over de laatste waarde (volatile is dus niet nodig).
Wanneer mogelijk, gebruik je dus best immutable objecten in een applicatie met concurrency.
Records zijn uiterst geschikt om eenvoudig dergelijke immutable objecten te maken, en gaan dus goed samen met concurrency!
Concurrent data structures
Zoals we hierboven gezien hebben, is niet elke klasse automatisch geschikt om (correct) door meerdere threads tegelijk gebruikt te worden.
Ook de ingebouwde collectie-types (bv. ArrayList, LinkedList) zijn niet thread-safe.
Je kan een thread-safe collectie verkrijgen door hulpfuncties in de Collections-klasse, bijvoorbeeld Collections.synchronizedList(unsafeList).
Dat geeft een view op de gegeven collectie terug waarvan alle methodes synchronized zijn.
Dat houdt in de praktijk dus in dat de collectie op elk moment slechts door 1 thread gebruikt kan worden.
Bovendien, wanneer je itereert over de elementen in de collectie, bijvoorbeeld via een iterator of stream (zie later), moet het gebruik van die iterator ook in een sycnhronized blok staan (met de collectie als object), zodat de lijst niet aangepast kan worden tijdens het itereren.
Omdat ook een foreach-lus een iterator gebruikt, moet die lus ook in een synchronized-blok staan:
List myList = Collections.synchronizedList(new ArrayList<E>());
...
synchronized(myList) {
var it = myList.iterator();
while (it.hasNext()) {
...
}
}
...
synchronized(myList) {
for (var element : myList) {
...
}
}Bovenop die manier om ‘gewone’ collecties thread-safe te maken, zijn er ook implementaties die specifiek ontworpen zijn voor concurrency.
Bijvoorbeeld, een CopyOnWriteArrayList is een thread-safe lijst, geschikt voor wanneer er veel vaker gelezen wordt uit de lijst dan dat er naar geschreven wordt.
Deze implementatie dan is efficiënter dan een gewone ArrayList die gesynchroniseerd wordt via de synchronizedList-hulpfunctie.
Zoals de naam zegt wordt de onderliggende array nooit aangepast, maar wel volledig gekopieerd elke keer ernaar geschreven wordt.
Het voordeel is dat lezen kan zonder enige synchronizatie, omdat de inhoud van de array zelf nooit meer aangepast wordt.
Er bestaat ook een ConcurrentHashMap, die een thread-safe Map implementeert.
Ook hier is deze efficiënter dan een gesynchroniseerde Map, omdat nooit de hele datastructuur gelockt wordt.
High-level concurrency abstractions
Totnogtoe hebben we steeds zelf threads aangemaakt. Zoals eerder vermeld komt elke thread echter met een redelijk grote overhead, en wordt het al snel complex om bij te houden welke threads we hebben en hoeveel er zijn. We willen daarom de gebruikte threads makkelijk kunnen beheren.
Executor
Java biedt enkele hoog-niveau abstracties aan om te werken met threads.
De basisklasse daarvoor is een Executor.
Deze ontkoppelt de taak die uitgevoerd moet worden van de thread waarin die uitgevoerd wordt.
Aan een Executor kan je dus Runnable’s (of lambda’s of method references) geven die uitgevoerd moeten worden, zonder zelf de threads te beheren.
Er is ook een subinterface ExecutorService die enkele methodes toevoegt, bijvoorbeeld het afsluiten van een executor.
Tenslotte is er de ScheduledExecutorService die methodes toevoegt om taken te plannen (bijvoorbeeld uitvoeren na een bepaalde tijd, eenmalig of herhaald).
Vaak willen we het aantal threads dat gebruikt wordt beperken, bijvoorbeeld tot ongeveer het aantal aanwezige processoren of cores.
Dat kan met een ThreadPool: een verzameling van threads die, eenmaal aangemaakt, herbruikt kunnen worden.
Er is een ThreadPoolExecutor die exact dat doet.
Je kan die zelf aanmaken, maar dat kan makkelijker via hulpmethodes in de Executors klasse.
Bijvoorbeeld:
var pool = Executors.newFixedThreadPool(5);
pool.submit(() -> someTask());
pool.submit(() -> someOtherTask());
...
pool.close(); // wacht tot alle taken afgelopen zijn.maakt een ExecutorService aan met ten hoogste vijf threads.
Nieuwe taken die aangeboden worden wanneer alle vijf threads bezig zijn met andere taken, belanden in een wachtrij tot ze aan de beurt zijn.
Met de close-methode zorg je ervoor dat er geen nieuwe taken meer kunnen bijkomen, en wacht je tot alle bestaande taken afgelopen zijn.
Er zijn ook andere varianten die je kan aanmaken via de Executors-klasse, bijvoorbeeld
newCachedThreadPool: herbruikt threads indien voorhanden, en maakt anders een nieuwe thread aan. Threads zonder werk worden na een bepaalde tijd beëindigd.newSingleThreadExecutor: een executor met slechts één thread die al het aangeboden werk (na elkaar) uitvoert.newSingleThreadScheduledExecutor: zelf de als hierboven, maar dan met een ScheduledExecutor als resultaat. Hiermee kan je dus bijvoorbeeld taken op regelmatige tijdstippen uitvoeren.
Het aanmaken en vervolgens wachten op alle taken kan ook via een zogenaamd try-with-resources statement. Dat is een eenvoudige manier om te wachten op alle taken en ervoor te zorgen dat de pool altijd afgesloten wordt, ook als er exceptions gegooid worden. (Een try-with-resource statement kan in Java ook voor andere zaken gebruikt worden, in het bijzonder met resources die na gebruik terug gesloten moeten worden, bijvoorbeeld een bestand.)
try (var pool = Executors.newFixedThreadPool(5)) {
pool.submit(() -> someTask());
pool.submit(() -> someOtherTask());
}
// de pool is hier gesloten, en alle taken zijn uitgevoerd.Fork-Join pool
Een fork-join pool is een specifiek type Executor voor taken die (recursief) nieuwe subtaken genereren. Deze subtaken worden dan mee opgenomen in de lijst van uit te voeren taken. Een fork-join pool is vooral nuttig wanneer de taken onafhankelijk van elkaar zijn, en achteraf gecombineerd worden. Er wordt gebruik gemaakt van work stealing: threads in de pool die niets meer te doen hebben, kunnen subtaken beginnen uitvoeren die gegenereerd werden door een andere thread.
We gaan hier niet verder in op het gebruik van een fork-join pool.
Testen van concurrent code
Het testen of bepaalde code thread-safe is, is allesbehalve eenvoudig. Ten eerste moeten we de tests uitvoeren met meerdere threads; concurrency-problemen zijn immers veelal onzichtbaar als er maar één thread in het spel is. Bovendien is een correct resultaat na één uitvoering van de test geen garantie dat de code ook correct is. Er kan immers een probleem zijn dat niet tot uiting kwam bij die specifieke uitvoering (met andere woorden, bij die specifieke interleaving van de threads), maar dat zich wel zou manifesteren bij een andere uitvoeringsvolgorde. De test meerdere keren herhalen kan in zo’n gevallen soelaas bieden.
In Java kunnen we gebruik maken van een library zoals jcstress. Deze library laat toe om testcode te schrijven die onder verschillende regimes uitgevoerd wordt, om zo de kans te vergroten dat thread safety problemen (bv. race-condities) aan het licht komen. De jcstress library wordt ook gebruikt om de concurrency-aspecten van de implementatie van de Java Virtual Machine zelf te testen.
jcstress toevoegen aan je project
Voeg volgende regel toe aan de plugins sectie van je build.gradle:
plugins {
...
id 'io.github.reyerizo.gradle.jcstress' version '0.8.15'
}Zorg ervoor dat IntelliJ je nieuwe Gradle-configuratie verwerkt (klik op het olifantje dat verschijnt).
In je project maak je nu een extra folder onder src, namelijk src/jcstress, en daaronder een folder src/jcstress/java.
Voeg deze java folder toe als ‘Sources root’: rechtsklik op de java folder > Mark Directory As > Sources root.
IntelliJ zou de folder nu blauw moeten kleuren.
Anatomie van een jcstress test
Een test in jcstress maakt geen gebruik van JUnit-annotaties (@Test etc), maar van een eigen set van annotaties.
Hier vind je een voorbeeld en wat meer uitleg over de betekenis annotaties.
We bespreken de belangrijkste annotaties ook hieronder, met als voorbeeld het testen van onze originele Counter-klasse.
package demo;
import org.openjdk.jcstress.annotations.*;
import org.openjdk.jcstress.infra.results.I_Result;
@JCStressTest
@Outcome(id="0", expect = Expect.ACCEPTABLE, desc = "Incremented and decremented atomically")
@Outcome(id="", expect = Expect.FORBIDDEN, desc = "Unexpected counter value")
@State
public class CounterTest {
private final Counter counter = new Counter();
private final int N = 5;
@Actor
public void incrementer() {
for (int i = 0; i < N; i++) {
counter.increment();
}
}
@Actor
public void decrementer() {
for (int i = 0; i < N; i++) {
counter.decrement();
}
}
@Arbiter
public void arbiter(I_Result result) {
result.r1 = counter.getCount();
}
}We zien in de test hetvolgende:
- De annotatie
@JCStressTestduidt aan dat het om een jcstress-test gaat - De annotatie
@Stategeeft aan in welke klasse we de te testen state-variabelen vinden; hier is dat de variabelecounter, in deCounterTestklasse zelf. Het object met@Statezal erg vaak aangemaakt worden, en moet voldoen aan bepaalde voorwaarden (bv. publieke constructor zonder argumenten).
We negeren @Outcome nog even, en kijken naar de actoren en arbiter:
- Elke methode met
@Actorstaat voor de code die door één thread uitgevoerd wordt. Hier hebben we 2 verschillende actoren: eentje die de teller N keer verhoogt, en een andere die de teller N keer verlaagt. Het jcstress framework zal de actoren uitvoeren met zoveel mogelijk verschillende interleavings, in de hoop zo eventuele problemen bloot te leggen. - De methode met
@Arbiter(gewoonlijk 1 per test) wordt uitgevoerd nadat alle actoren helemaal klaar zijn. De arbiter bezorgt de data waaraan we kunnen zien of er zich een probleem voorgedaan heeft. In dit geval kijken we naar de waarde van de counter na afloop van de verhogingen en verlagingen. We kennen die counter-waarde toe aan attribuutr1van het resultaat-object. Dat heeft typeI_Result, wat staat voor een resultaat met 1 integer (I). Er zijn ook andere types beschikbaar in de library, bv.II_Result(2 integers),DBI_Result(een double, een byte, en een integer), etc.
Opmerking
Het is niet strikt noodzakelijk om een @Arbiter-methode te hebben.
Je kan ook één van de @Actor-methodes een result-parameter geven en zonder arbiter werken.
Tenslotte bespreken we de @Outcome-annotaties. Die geven aan welke resultaat-objecten verwacht/acceptabel zijn en welke niet.
In het voorbeeld hierboven:
- Een resultaat met
r1=0is acceptabel; dat is wat we verwachten van een thread-safe counter. Dat geven we aan met@Outcome(id="0", expect = Expect.ACCEPTABLE, ...). Merk op dat deidparameter het verwachte resultaat (uit deI_Resultparameter) voorstelt. - Elk ander resultaat is niet toegelaten:
@Outcome(id="", expect = Expect.FORBIDDEN, ...).
Als we een resultaat met meerdere waarden zouden hebben (bv. een II_Result) dan specifiëren we de outcome bijvoorbeeld als @Outcome(id="0, 1", ...), wat overeenkomt met r1=0 en r1=1.
Tests uitvoeren
Je kan de tests uitvoeren via de jcstress taak in Gradle: ./gradlew jcstress.
Dit genereert uitvoer op de console, en ook een html-bestand in build/reports/jcstress.
Daarin vinden we een tabel zoals onderstaande, die aangeeft hoe vaak elk resultaat bekomen werd:
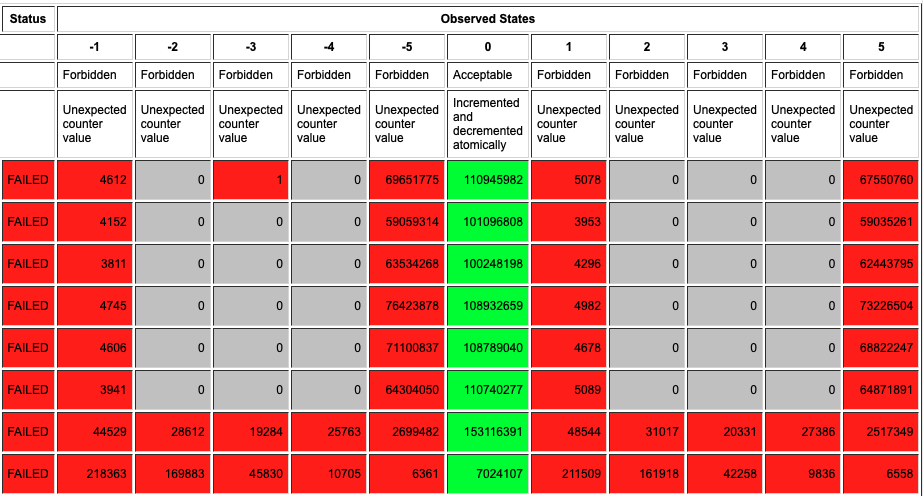
We zien hieruit duidelijk dat onze counter niet thread-safe is: alle waarden van -5 tot 5 werden bekomen in sommige tests.
Oefeningen
Zie oefeningen.