Hoe ga je van broncode naar een werkende software applicatie
In de wereld van software engineering vormt de compiler een essentieel hulpmiddel dat de kloof overbrugt tussen de door ontwikkelaars geschreven broncode en de uitvoerbare machinecode die door de computer wordt begrepen. Wanneer programmeurs een programma schrijven, doen zij dit vaak in een hoog-niveau taal die leesbaar en begrijpelijk is voor mensen. De compiler vertaalt deze code vervolgens naar een lager-niveau, binaire instructies die specifiek zijn voor de hardware (CPU architecture) waarop het programma draait.
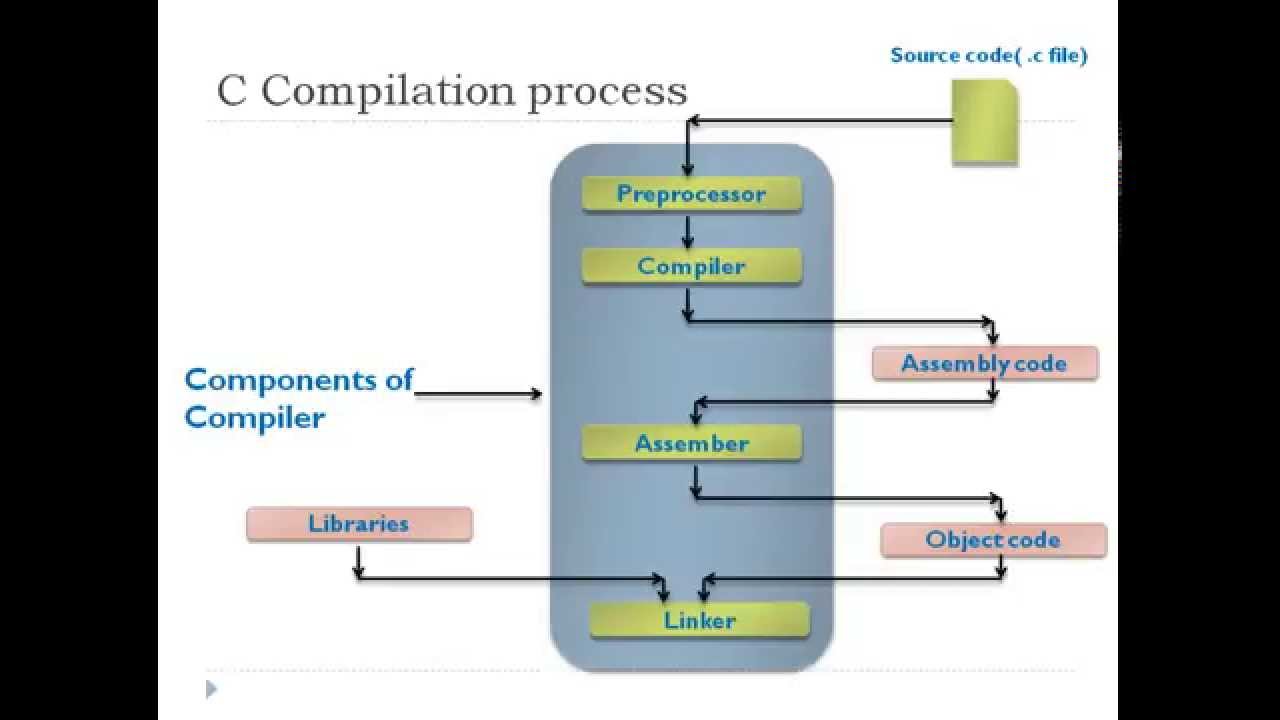
Het compilatieproces bestaat doorgaans uit verschillende stappen die gezamenlijk zorgen voor een correcte en efficiënte omzetting van de broncode.
Allereerst vindt een lexicale analyse plaats, waarbij de broncode wordt opgesplitst in basiselementen, of tokens.
Vervolgens controleert de parser of deze tokens in de juiste volgorde staan volgens de grammaticale regels van de taal, waardoor een abstracte syntaxisboom ontstaat.
Hierna volgt een semantische analyse om te verifiëren dat de code logisch en consistent is.
Optimalisatiefasen kunnen daarna ingrijpen om de prestaties te verbeteren, waarna de codegenerator de uiteindelijke machinecode produceert.
Ten slotte wordt deze code vaak gekoppeld/gelinkt met externe bibliotheken en modules, zodat er een volledig functioneel uitvoerbaar bestand ontstaat, ook wel een executable of binary genoemd.
Naast de technische vertaalslag biedt het gebruik van een compiler ook andere belangrijke voordelen.
Zo kan de compiler programmeerfouten al vroeg in het ontwikkelproces opsporen, zoals syntaxis- of typefouten, waardoor deze sneller gecorrigeerd kunnen worden.
Tevens zorgt de optimalisatie tijdens de compilatie ervoor dat de uiteindelijke applicatie efficiënter draait, wat cruciaal is in productieomgevingen.
Deze scheiding tussen broncode en machinecode maakt het bovendien mogelijk voor ontwikkelaars om zich te richten op de logica en architectuur van hun programma, terwijl de compiler de complexe taak van vertalen en optimaliseren op zich neemt.
Build systems
Naast het compileren en linken van code, kunnen build-systems het manuele werk aanzienlijk vereenvoudigen voor developers. Build-systems automatiseren niet alleen het proces van compileren en linken, maar beheren vaak ook dependencies, voeren tests uit en zorgen voor een consistente en reproduceerbare build-omgeving. Dit betekent dat ontwikkelaars niet langer handmatig complexe commando’s hoeven uit te voeren voor elke stap in het buildproces.
Door alleen de gewijzigde onderdelen opnieuw te compileren, optimaliseren build-systems de efficiëntie en verminderen ze de kans op menselijke fouten. Bovendien dragen ze bij aan een gestandaardiseerde workflow, wat vooral binnen teams zorgt voor een soepelere samenwerking en minder integratieproblemen.
In de volgende onderdelen leer je hoe dit er praktisch uitziet voor verschillende programmeertalen
Subsecties van 3. Build systems and Makefiles
Cmdline C Compiling
C programma’s compilen
Source code en header files
De ontwikkeling begint met het schrijven van de broncode in .c-bestanden en het definiëren van functies en variabelen in header files (.h-bestanden). Header files bevatten vaak declaraties van functies en macro’s die in meerdere bronbestanden worden gebruikt.
De preprocessor voert tekstvervangingen uit voordat de daadwerkelijke compilatie begint. Dit omvat het verwerken van #include-directives, het vervangen van macro’s en het uitvoeren van voorwaardelijke compilatie.
De #ifndef-directive staat voor “if not defined” en wordt gebruikt om te voorkomen dat een header file meerdere keren wordt ingeladen, wat kan leiden tot dubbele declaraties en andere problemen. Dit wordt ook wel een include guard genoemd.
Compiler
De compiler vertaalt de preprocessed broncode naar assembly code. Dit is een laag-niveau representatie van de code die specifiek is voor de CPU-architectuur.
gcc -c main.c header.c
Assembler
De assembler vertaalt de assembly code naar objectbestanden (.o-bestanden). Deze objectbestanden bevatten machinecode die door de processor kan worden uitgevoerd, maar zijn nog niet zelfstandig uitvoerbaar.
Linker
De linker neemt de objectbestanden en eventuele bibliotheken en combineert deze tot een enkel uitvoerbaar bestand. De linker lost symbolen op (zoals functie- en variabelenamen) en zorgt ervoor dat alle verwijzingen correct zijn. Bijvoorbeeld:
gcc -o output.bin main.o header.o
Libraries
Libraries bevatten vooraf gecompileerde code die kan worden hergebruikt in verschillende programma’s. Er zijn statische bibliotheken (.a-bestanden) en dynamische bibliotheken (.so-bestanden). Hier komen we later bij dependency management nog op terug.
De Binary
Het eindresultaat is een binary executable die direct door het besturingssysteem kan worden uitgevoerd. Dit bestand bevat de machinecode, evenals alle benodigde symbolen en verwijzingen naar bibliotheken. Je kan je programma runnen met volgende commando:
./output.bin
Door die stappen te doorlopen, wordt de broncode omgezet in een uitvoerbaar programma dat op de doelmachine kan draaien.
C compilation proces
De GNU Compiler Collection: gcc
GCC is een krachtige en veelzijdige compiler die wordt gebruikt voor het compileren van verschillende programmeertalen zoals C, C++, Objective-C, Fortran, Ada en meer. GCC is een essentieel onderdeel van de GNU-toolchain en wordt veel gebruikt in de open-source gemeenschap vanwege zijn flexibiliteit en robuustheid. Het biedt uitgebreide optimalisatiemogelijkheden, foutdetectie en ondersteuning voor verschillende architecturen.
compileren naar .o files: gcc -c ./src/main.c -o ./build/main.o
linken van de .o files: gcc -o program.bin ./build/*.o
Info
Hier enkele veelgebruikte flags voor gcc:
-Wall: Deze flag schakelt de meeste waarschuwingen in, zodat je tijdens het compileren meldingen krijgt over mogelijke problemen in je code. Dit helpt om fouten en onbedoelde gedragingen op te sporen.
-Wextra:Met deze flag worden extra waarschuwingen ingeschakeld die niet door -Wall worden gedekt. Hierdoor krijg je nog meer informatie over potentiële problemen of verbeterpunten in je code.
-std=c11:Deze flag geeft aan dat de compiler de C-standaard uit 2011 (C11) moet gebruiken. Dit zorgt ervoor dat je code voldoet aan de specificaties en functionaliteiten die in deze standaard zijn gedefinieerd.
Automatiseren met een shell script
Het handmatig compileren van bronbestanden kan tijdrovend en foutgevoelig zijn, vooral bij grotere projecten met veel bestanden. Daarom geven we de voorkeur aan het automatiseren van dit proces. Dit kan je eventueel doen met behulp van een Shell script.
Door een script te gebruiken, kunnen we ervoor zorgen dat alle stappen consistent en correct worden uitgevoerd, zonder dat we elke keer dezelfde commando’s hoeven in te typen. Dit vermindert de kans op menselijke fouten, zoals het vergeten van een bestand of het verkeerd typen van een commando. Bovendien maakt automatisering het eenvoudiger om het compilatieproces te herhalen, wat handig is bij het ontwikkelen en testen van software. Het gebruik van scripts verhoogt de efficiëntie en betrouwbaarheid van het ontwikkelproces, waardoor ontwikkelaars zich kunnen concentreren op het schrijven van code in plaats van op het compileren ervan.
Oefening
Extract alle files in dit zip bestand naar een directory naar keuze OF clone de repository. Schrijf een shell script met de naam make.sh dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de /build-directory en maakt de binary game.bin in de root directory
clean: Verwijdert de binary en de object files in de build directory
run : Voert de binary uit (bouwt eerst als die nog niet bestaat) en geeft eventuele flags door (bv --hp 12)
Solution: Klik hier om de code te zien/verbergen🔽
#!/bin/bash
# Dit script ondersteunt drie commando's:# compile: Compileert de bronbestanden en maakt de binary# run: Voert de binary uit (bouwt eerst als die nog niet bestaat)# clean: Verwijdert de binary en de build directory# Variabelen (hardcoded voor eenvoud)SRC_DIR="src"BUILD_DIR="build"TARGET="game.bin"CFLAGS="-Wall -Wextra -std=c11"# Zorg dat er minstens één argument is meegegevenif["$#" -lt 1];thenecho"Gebruik: $0 {compile|run|clean} [--hp <waarde>]"exit1fiCOMMAND=$1# Shift the parameters so the second becomes the first etc.shiftif["$COMMAND"="compile"];thenecho"Bouwen van het project..."# Maak de build-directory als deze nog niet bestaatif[ ! -d "$BUILD_DIR"];then mkdir -p "$BUILD_DIR"fi# Compileer main.c en game.c naar objectbestanden in build/echo"Compileren van $SRC_DIR/main.c..." gcc $CFLAGS -c "$SRC_DIR/main.c" -o "$BUILD_DIR/main.o"echo"Compileren van $SRC_DIR/game.c..." gcc $CFLAGS -c "$SRC_DIR/game.c" -o "$BUILD_DIR/game.o"# Link de objectbestanden naar de uiteindelijke binary in de rootecho"Linken naar $TARGET..." gcc $CFLAGS -o "$TARGET""$BUILD_DIR/main.o""$BUILD_DIR/game.o"echo"Build succesvol: $TARGET is aangemaakt."elif["$COMMAND"="run"];then# Bouw de binary als deze niet bestaatif[ ! -f "$TARGET"];thenecho"Binary niet gevonden, eerst bouwen..." sh "$0" build "$@"fiecho"Uitvoeren van $TARGET..." ./"$TARGET""$@"elif["$COMMAND"="clean"];thenecho"Opruimen..."# Verwijder de binary en de build-directory rm -rf "$BUILD_DIR/*" rm -f "$TARGET"echo"Opruimen voltooid."elseecho"Onbekend commando: $COMMAND"echo"Gebruik: $0 {compile|run|clean} [--hp <waarde>]"exit1fi
Moeilijkheden
Bij het handmatig compileren van projecten kunnen er verschillende tekortkomingen optreden:
Een van de grootste uitdagingen is het beheren van afhankelijkheden tussen bestanden. Wanneer een bronbestand wordt gewijzigd, moeten alle gerelateerde bestanden opnieuw worden gecompileerd, wat moeilijk bij te houden is zonder een gestructureerd systeem.
Daarnaast kan het handmatig invoeren van compilatie- en linkcommando’s voor elk bestand tijdrovend en foutgevoelig zijn.
De if-else syntax voor de verschillende opties is ook niet zo een gracieuze oplossing.
Beter, een build system: Makefiles
Makefiles proberen een antwoord te bieden op de tekortkomingen van shell scripts door een gestructureerde en efficiënte manier te bieden om afhankelijkheden en compilatiestappen te beheren. Ze maken gebruik van regels en doelen om automatisch te bepalen welke bestanden opnieuw moeten worden gecompileerd wanneer een bronbestand wordt gewijzigd. Dit voorkomt onnodige hercompilatie en bespaart tijd. Bovendien kunnen Makefiles complexe build-processen eenvoudig beheren door verschillende taken zoals compileren, linken, testen en opruimen te automatiseren. Ze bieden ook flexibiliteit door het gebruik van variabelen en conditionele statements, waardoor dezelfde Makefile kan worden gebruikt voor verschillende configuraties en platformen.
Hoe zijn makefiles opgebouwd?
Makefiles zijn opgebouwd uit een reeks regels die beschrijven hoe verschillende bestanden in een project moeten worden gecompileerd en gelinkt. Elke regel in een makefile bestaat uit drie hoofdonderdelen: doelen, afhankelijkheden en commando’s.
Doelen (Targets): Dit zijn de bestanden die je wilt genereren, zoals objectbestanden of een uitvoerbaar bestand. Een doel kan ook een alias zijn voor een groep commando’s, zoals all of clean.
Afhankelijkheden (Dependencies): Dit zijn de bestanden waarvan het doel afhankelijk is. Als een van deze bestanden wordt gewijzigd, weet make dat het doel opnieuw moet worden gegenereerd.
Commando’s (Commands): Dit zijn de shell-commando’s die worden uitgevoerd om het doel te genereren. Ze MOETEN beginnen met een tab en worden uitgevoerd in de volgorde waarin ze zijn geschreven.
Het doel program hangt af van main.o en header.o. Als een van deze objectbestanden wordt gewijzigd, wordt program opnieuw gegenereerd.
De regel compile specificeert hoe de nodige .c-bestanden moeten worden gecompileerd naar de respectievelijke .o-bestanden.
Het doel clean verwijdert de gecompileerde bestanden, wat handig is voor een schone hercompilatie.
Syntax en Flow
Een ’naïve’ make file zou er kunnen uitzien zoals hieronder, met wat leuke syntax zoals variabelen:
# Declareer variabelen
SRCDIR= ./src
BUILDDIR= ./build
TARGET= program.bin
# Je kan zoals in de commando's simpelweg wildcards gebruiken
compile: gcc -c $(SRCDIR)/header.c -o ./build/header.o
gcc -c ./src/main.c -o ./build/main.o
gcc -o $(TARGET) ./build/*.o
clean: rm -rf program.bin $(BUILDDIR)/*
# @ suppresses outputting the command to the terminal
run: @echo "Running program ..." ./program.bin
Info
In Makefiles, you can use certain symbols as prefixes to control the behavior of commands:
@: Suppresses the command echo, so the command itself won’t be printed to the terminal.
-: Ignores errors from the command, allowing the Makefile to continue even if the command fails.
+: Forces the command to be executed even if make is run with options that normally prevent command execution (like -n, -t, or -q).
Hiermee bereiken we echter niets meer mee dan een gewoon shell script daarom gaan we van de rule en dependecy met wat syntactische suiker om de kracht van Makefiles te unlocken:
# Declareer variabelen kan met `=`, `:=` of `::=`
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
SRCDIR= ./src
BUILDDIR= ./build
# declareer alle .c files
CFILES=$(SRCDIR)/main.c $(SRCDIR)/header.c
# declareer de corresponderende .o files
OBJECTS=$(BUILDDIR)/main.o $(BUILDDIR)/header.o
TARGET= program.bin
# Het is een good practice om altijd een `all` rule te implementeren
# In dit geval is de `all` afhankelijk van onze TARGET
all:$(TARGET)# Maar waar is onze TARGET afhankelijk van ...
# van alle object files, want enkel dan kunnen we linken tot een binary
$(TARGET):$(OBJECTS)$(CC) -o $@ $^
# Hierboven verwijzen we met $@ naar alles links van de `:` en met $^ alle elementen er rechts van
# Maar onze OBJECTS zijn op hun beurt weer afhankelijk van hun corresponderende .c files ...
# we gebruiken hier regular expressions waardoor % een wildcard is
$(BUILDDIR)/%.o:$(SRCDIR)/%.c$(CC)$(CFLAGS) -c -o $@ $<
# Hierboven verwijzen we met $@ naar alles links van de `:` en met $< (het corresponderende element) er rechts van
compile:$(TARGET)clean: rm -rf $(TARGET)$(OBJECTS)run:$(TARGET) ./$(TARGET)
We declareren als eerst de all-rule omdat wanneer je standaard geen command meegeeft aan make, de eerste rule uitgevoerd zal worden.
Met deze structuur zal er wanneer je make run ingeeft enkel gecompileerd worden wat gewijzigt is! Voor mog meer info kan je hier terecht
Maar we kunnen nog beter
Nu moeten we nog manueel alle source-files gaan benoemen, maar hier bestaat echter ook wat makefile ‘magic’ voor om dit te automatiseren: zie voorbeeld hieronder:
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
SRCDIR= ./src
BUILDDIR= ./build
# declareer alle .c files en gebruik de * wildcard om simpelweg alle .c bestanden te selecteren in de SRCDIR
CFILES=$(wildcard $(SRCDIR)/*.c)# declareer de corresponderende .o files via subsititutie en renaming
OBJECTS=$(patsubst $(SRCDIR)/%.c,$(BUILDDIR)/%.o,$(CFILES))TARGET= program.bin
all:$(TARGET)$(TARGET):$(OBJECTS)$(CC) -o $@ $^
$(BUILDDIR)/%.o:$(SRCDIR)/%.c$(CC)$(CFLAGS) -c -o $@ $<
compile:$(TARGET)clean: rm -rf $(TARGET)$(OBJECTS)run:$(TARGET) ./$(TARGET)
Nog steeds niet perfect maar buiten scope van deze cursus
Makefiles blijven een aantal beperkingen hebben waaronder dat wanneer je een CONSTANT in een header file aanpast, make niet noodzakelijk doorheeft dat je de file die gebruik maakt van de constant moet updaten. Dit valt op te lossen met wat ’elbow grease’ aan de make-syntax maar dat valt buiten de scope van deze cursus. Later gaan we toch ook gebruik maken van meer advanced build systems.
Oefening
Maak nu een Makefile voor de game van hierboven die dezelfde functionaliteit biedt als je gemaakte shell script.
Solution: Klik hier om de code te zien/verbergen🔽
# Directories
SRC_DIR= src
BUILD_DIR= build
# Doel binary
TARGET= game.bin
# Compiler en flags
CC= gcc
CFLAGS= -Wall -Wextra -std=c11
# Alle bronbestanden en objectbestanden
SRCS=$(wildcard $(SRC_DIR)/*.c)OBJS=$(patsubst $(SRC_DIR)/%.c,$(BUILD_DIR)/%.o,$(SRCS))# Standaard doel: bouw de binary
all:$(TARGET)# Link de objectbestanden tot de uiteindelijke binary
$(TARGET):$(OBJS)$(CC)$(CFLAGS) -o $(TARGET)$(OBJS)# Compileer .c naar .o en plaats deze in de build map
$(BUILD_DIR)/%.o:$(SRC_DIR)/%.c|$(BUILD_DIR)$(CC)$(CFLAGS) -c $< -o $@# Zorg dat de build map bestaat
$(BUILD_DIR): mkdir -p $(BUILD_DIR)# Geef ook de optie om 'compile' als een commando mee te geven
compile:$(TARGET)# Voer de binary uit. Eventuele argumenten meegegeven met ARGS worden doorgegeven.
run:$(TARGET) ./$(TARGET)$(ARGS)# run as `make run ARGS="--your-flags"`
# Verwijder de binary en de build directory
clean: rm -f $(TARGET) rm -rf $(BUILD_DIR)
Breid de functionaliteit van je spel verder uit, door nieuwe Monsters te spawnen wanneer je een monster verslaat. Hou dan ook bij hoeveel monsters je verslagen hebt. Dat is je uitendelijke score wanneer je sterft.
Zoek op hoe je de library cJSON downloaden, toevoegen aan je applicatie en kan gebruiken in de main.c file.
Laat wanneer je sterft de applicatie de naam van de speler vragen en een JSON object aanmaken van de speler met naam en score en dit toevoegen aan een /resources/highscore.json bestand.
Voeg aan het begin van de game toe dat de huidige highscores van de json file geladen worden en getoond worden aan de speler.
(Geniet hierbij van het feit dat je een gemakkelijke makefile hebt om snel wijzigingen aan de code te testen.)
De cJSON-library is een voorbeeld van een dependency, we gaan hier nog dieper over in in het deel rond ‘Dependency management’
Klik hier om de code te zien/verbergen van een voorbeeld main.c programma dat gebruik maakt van cJSON🔽
#include<stdio.h>#include<stdlib.h>#include<string.h>#include"cJSON.h"// Function to read the JSON file
char*read_file(constchar*filename){FILE*file=fopen(filename,"rb");if(!file){returnNULL;}fseek(file,0,SEEK_END);longlength=ftell(file);fseek(file,0,SEEK_SET);char*data=(char*)malloc(length+1);fread(data,1,length,file);data[length]='\0';fclose(file);returndata;}// Function to write the JSON file
voidwrite_file(constchar*filename,constchar*data){FILE*file=fopen(filename,"wb");if(!file){perror("File opening failed");return;}fwrite(data,1,strlen(data),file);fclose(file);}intmain(){constchar*filename="scores.json";// Read the JSON file
char*json_data=read_file(filename);cJSON*root;if(!json_data){// File does not exist, create a new JSON object
root=cJSON_CreateArray();}else{// Parse the existing JSON data
root=cJSON_Parse(json_data);if(!root){printf("Error parsing JSON data\n");free(json_data);return1;}free(json_data);}// Create a new JSON object to add
cJSON*new_entry=cJSON_CreateObject();cJSON_AddStringToObject(new_entry,"name","Jane Doe");cJSON_AddNumberToObject(new_entry,"score",95);// Add the new entry to the JSON array
cJSON_AddItemToArray(root,new_entry);// Convert JSON object to string
char*updated_json_data=cJSON_Print(root);// Write the updated JSON data back to the file
write_file(filename,updated_json_data);// Clean up
cJSON_Delete(root);free(updated_json_data);return0;}
Dit is in principe iets wat je in het INF1 vak onbewust reeds uitvoerde door op de groene “Compile” knop te drukken van je NetBeans/IntelliJ IDE. Het is belangrijk om te weten welke principes hier achter zitten net als in C. Hieronder volgt dus een kort overzicht over het compileren van Java programma’s zonder een buildtool, later gaan we hier meestal een buildtool voor gebruiken om ons leven gemakkelijk te maken.
de Java Runtime Environment (JRE) om het commando java te gebruiken om gecompileerde Java programma’s te kunnen runnen.
de Java Development Kit (JDK) om het commando javac te gebruiken om Java broncode (.java-files) te compileren (en verzamelen in een jar-file.)
De Java Virtual Machine (JVM)
Waarom heb je nu toch een extra stukje software nodig om Java-applicaties te runnen? In C hebben we echter gezien dat we juist willen compileren naar een binary zodat we dit native kunnen uitvoeren. Java wil namelijk een oplossing bieden voor de ‘flaw’ in hoe C-programma’s werken. Zoals daar aangehaald compileer je een C-programma naar een bepaalde architectuur, daarom kan je een C-programma dat gecompileerd is voor een x86-cpu niet runnen op een arm-cpu bijvoorbeeld. Java lost dit probleem op door te compileren naar een speciale bytecode, die dan door de Java Virtual Machine (JVM) kan worden uitgevoerd op de onderliggende architectuur. De JVM vormt dus een laag tussen je bytecode en de hardware. Op die manier moet de gebruiker enkel één programma specifiek voor zijn/haar architectuur downloaden (de JVM) en kunnen de Java-binaries hetzelfde blijven. Je hoeft dan als developer geen meerdere verschillende binaries meer te voorzien. TOP!
LET OP: de Student klasse leeft in package student—die op zijn beurt wordt geïmporteerd in Main.java. Dat betekent dat we Student.java moeten bewaren in de juiste subfolder ofwel package. Dit zou je moeten herkennen vanuit INF1, waar de structuur ook src/main/java/[pkg1]/[pkg2] is. We hebben nu dus twee bestanden:
Alle files apart compileren levert .class files op in diezelfde folders. java Main zoekt dan nog steeds de student/Student.class file vanwege de import. Dit betekent dat je je programma moeilijker kan delen met anderen: er zijn nu twee bestanden én een subdirectory met juiste naamgeving vereist.
Gelukkig kan je met de juiste argumenten alle .class files in één keer genereren en die in een aparte folder—meestal genaamd build—plaatsen:
$ javac -d ./build *.java
$ cd build
$ ls
Main.class student
$ java Main
Heykes Jos
Java programma’s packagen
Omdat het vervelend is om verschillende bestanden te kopiëren naar andere computers worden Java programma’s typisch verpakt in een .jar bestand: een veredelde .zip met metadata informatie zoals de auteur, de java versie die gebruikt werd om te compileren, welke klasse te starten (die de main() methode bevat), … Indien deze metadata, in de META-INF subfolder, niet bestaat, worden defaults aangemaakt. Zie de JDK Jar file specification voor meer informatie.
We gebruiken een derde commando, jar, om, na het compileren naar de build folder, alles te verpakkken in één kant-en-klaar programma:
‘c’ voor “create” (aanmaken van een nieuwe JAR-file)
‘v’ voor “verbose” (gedetailleerde uitvoer)
‘f’ voor “file” (de naam van de JAR-file die je wilt maken).
Nu kunnen we programma.jar makkelijk delen. De vraag is echter: hoe voeren we dit uit, ook met java? Ja, maar met de juiste parameters, want deze moet nu IN het bestand gaan zoeken naar de juiste .class files om die bytecode uit te kunnen voeren: (In het onderstaande commando staat de -cp-flag voor Classpath. Hier geef je dus aan waar het java commando mag gaan zoeken naar .class-files naar de klasse die je wil uitvoeren)
$ java -cp "programma.jar" Main
Heykes Jos
Waarschuwing
Java classpath separators zijn OS-specifiek! Unix: : in plaats van Windows: ;.
Vanaf nu kan je programma.jar ook uploaden naar een Maven repository of gebruiken als dependency in een ander project. Merk opnieuw op dat dit handmatig aanroepen van javac in de praktijk wordt overgelaten aan de gebruikte build tool—in ons geval, gaan we dit eerst automatiseren met een Makefile.
Jar files inspecteren
Mocht je jar ooit niet goed werken kan het handig zijn om te inspecteren wat er juist allemaal in de jar-package zit. Je kan hier het volgende commando voor gebruiken: jar -tf naam.jar
Voorbeeld:
arne@LT3210121:~/ses/java-met-cli/build$ jar -tf programma.jar
META-INF/
META-INF/MANIFEST.MF
Main.class
student/
student/Student.class
Nu je de structuur ziet kan je ook makkelijk de main methode oproepen van de Student.class in de jar(als die methode zou bestaan) met java -cp "programma.jar" student.Student
Main class instellen
Merk op dat als je de jar wil runnen zonder een specifieke klasse mee te geven dan ga je nu een error krijgen in de vorm van no main manifest attribute, in programma.jar. We kunnen er wel voor zorgen dat automatisch de klasse Main gebruikt wordt. Hiervoor moeten we het attribuut Main-Class in de MANIFEST.MF file de waarde van de klassenaam meegeven (eventueel met packages ervoor).
Met het volgende commando kunnen we inspecteren hoe die MANIFEST file er nu uit ziet. unzip -q -c programma.jar META-INF/MANIFEST.MF. Voorlopig bestaat dat attribuut dus nog niet.
Met jar cvfe programma.jar Main * waar de ’e’ nu staat voor “entry point” (de Main-Class die je wilt specificeren).
Nu kan je je jar simpel runnen met java -jar programma.jar:
arne@LT3210121:~/ses/java-met-cli/build$ java -jar programma.jar
Hekyes Jos
Oefening
Extract alle files in dit zip bestand naar een directory naar keuze OF clone de repository. Schrijf een simpele makefile dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de /build-directory
jar : packaged alle klassen naar een jar genaamd ‘app.jar’ in de ‘build’-directory met entrypoint de ‘App’-klasse.
run : Voert de jar file uit
clean: Verwijdert de ‘.class’-bestanden en het ‘.jar’-bestand uit de ‘build’-directory
In tegenstelling tot programmeertalen waarvan de broncode eerst gecompileerd moet worden om te runnen (zoals Java en C), is Python een interpreted programming language. Dit betekent dat de broncode van Python direct wordt uitgevoerd door een interpreter, zonder dat er een aparte compilatiestap nodig is. De interpreter (de python software die je geïnstalleerd moet hebben) leest de broncode regel na regel en voert deze direct uit, wat het ontwikkelproces vaak sneller en flexibeler maakt. Dit komt omdat fouten direct tijdens het uitvoeren van de code kunnen worden opgespoord en gecorrigeerd, zonder dat de hele applicatie opnieuw gecompileerd hoeft te worden.
Het verschil met compiled languages is dat bij deze talen de broncode eerst wordt omgezet in machinecode door een compiler voordat de code kan worden uitgevoerd. Dit proces, bekend als compilatie, genereert een uitvoerbaar bestand dat direct door de computer kan worden uitgevoerd. Hoewel dit een extra stap toevoegt aan het ontwikkelproces, kan het resulteren in snellere uitvoeringstijden van de uiteindelijke applicatie, omdat de machinecode direct door de hardware wordt uitgevoerd zonder tussenkomst van een interpreter.
Een tussenoplossing tussen interpreted en compiled languages is Just-In-Time (JIT) compiling. JIT-compiling combineert aspecten van beide benaderingen door de broncode tijdens de uitvoering te compileren naar machinecode. Dit betekent dat de code aanvankelijk wordt geïnterpreteerd, maar dat veelgebruikte delen van de code tijdens de uitvoering worden gecompileerd naar machinecode om de prestaties te verbeteren. Talen zoals Java en C# maken gebruik van JIT-compiling om een balans te vinden tussen de flexibiliteit van interpreted languages en de snelheid van compiled languages.
Compilen naar .bin
Iedereen kan dus in principe door het python-commando te gebruiken je python bronbestanden runnen. We willen het de eindgebruiker echter zo simpel mogelijk maken, daarom gaan we met behulp van pinstaller al onze python files kunnen “compileren” naar een single binary, dat je dan kan runnen.
Je kan pyinstaller installeren met: sudo pip install pyinstaller --break-system-packages
Je kan nu met een simpel command je python applicatie compileren naar een binary: pyinstaller --onefile --name app.bin app.py
Je ziet meteen dat pyinstaller een build/<appname>-directory aanmaakt waar pyinstaller alle files zet die nodig zijn voor de omvorming tot een binary. Een tweede belangrijke file die aangemaakt wordt is de <appname>.spec, hierin kan je verschillende eigenschappen aanpassen zoals de targeted architecture bijvoorbeeld (target_arch)
Test nu eens je binary in de ./dist-directory met ./dist/app.bin.
Oefening
Extract alle files in dit zip bestand in een directory naar keuze OF clone de repository. Schrijf een simpele makefile dat de volgende dingen kan doen en plaats het in de root van je directory:
compile: Compileert de bronbestanden naar de single ‘monstergame.bin’ file