De transactie management scheduler (zie transacties - basics) is verantwoordelijk om verschillende transacties correct in te plannen zonder dat er data problemen of clashes optreden.
Problemen? Welke problemen?
Denk terug aan het bank transfer probleem van de vorige sectie. Veronderstel dat deze keer zowel Jens als Marianne €10 willen overmaken naar Jolien. Als we dat als volgt doen:
- Lees het huidige bedrag op de source rekening
- Verminder bedrag van source rekening
- Lees het huidige bedrag op de destination rekening
- Verhoog bedrag van destination rekening
Dan zou het kunnen dat bij het uitlezen van #3, Jolien’s rekening bij de transactie van Marianne al €110 uitleest omdat Jens zijn verhoging al is doorgekomen. Maar net dan canceled de transactie van Jens en wordt de rekening van Jolien en van Jens (terecht) terug op de vorige waarde ingesteld (dus €100 voor Jolien). De transactie van Marjanne check nie nog eens het startbedrag en werkt dus nog altijd onder de veronderstelling dat er €10 bij €110 moet worden opgeteld en is op het einde het eindtotaal van Jolien toch €120 en Jens heeft geen geld verloren. Oeps!
Hieronder volgen een aantal veel voorkomende concurrency problemen die de transaction scheduler uitdagen.
Dirty Read
Dit is exact bovenstaande situatie. Een dirty read probleem is het lezen van uncommited “dirty” data—data die eigenlijk voor de andere transactie nog niet zichtbaar mag zijn omdat het hier over uncommitted data gaat. Als Marianne’s read(bedrag) toch het juiste bedrag zou inlezen (110), voordat Jens’ transactie compleet is, maar op een of andere manier is die transactie teruggedraaid, dan spreken we over een dirty read, en krijgt Jolien onterecht toch €20, terwijl Jens zijn €10 mag houden. It prints money!
| time | T1 (Marianne) | T2 (Jens) | bedrag |
|---|---|---|---|
| 1 | begin trans | 100 | |
| 2 | read(bedrag): 100 | 100 | |
| 3 | bedrag = bedrag + 10 | 100 | |
| 4 | begin trans | write(bedrag) | 110 |
| 5 | read(bedrag): 110 | 110 | |
| 6 | bedrag = bedrag + 10 | ROLLBACK! | 120 (oeps) |
| 7 | write(bedrag) | 120 | |
| 8 | commit | 120 |
Lost Updates
Stel je nu voor dat bij het uitlezen, tijdens het verhogen van het bedrag op de destination rekening, Jolien’s rekening op €100 staat. Maar als de transactie van Marianne dit ook leest als €100, en niet wacht tot de €110 die het zou moeten zijn na de commit van de transactie van Jens, dan gaat in totaal Marianne slechts €10 rijker zijn in plaats van twee keer dat bedrag. Weer een oepsie!
Het UPDATE statement van Jens’ transactie (verhoog Jolien’s rekening met 10) is eigenlijk “verloren” gegaan, omdat Marianne hier tussen komt, en haar UPDATE die terug ongedaan maakt:
| time | T1 (Marianne) | T2 (Jens) | bedrag |
|---|---|---|---|
| 1 | begin trans | 100 | |
| 2 | begin trans | read(bedrag): 100 | 100 |
| 3 | read(bedrag): 100 | bedrag = bedrag + 10 | 100 |
| 4 | bedrag = bedrag + 10 | write(bedrag) | 110 |
| 5 | write(bedrag) | commit | 110 (oeps) |
| 6 | commit | 110 |
Dit voorbeeld illustreert dat, alhoewel beide transacties 100% correct zijn, er toch nog problemen kunnen optreden als transacties elkaar gaan storen. Het spreekt voor zich dat als T1 data zou lezen en schrijven uit een andere rij of tabel, dit geen probleem zou zijn—in dit specifieke voorbeeld.
Een lost update is dus een fout in een databasesysteem die optreedt wanneer twee of meer transacties tegelijkertijd eenzelfde record wijzigen, maar één van de wijzigingen onbedoeld wordt overschreven. Hierdoor gaat de update van één transactie “lost” of verloren, waardoor het eindresultaat niet alle beoogde wijzigingen bevat.
Non-repeatable reads
Er zijn nog verschillende andere mogelijkheden waarbij de scheduler de bal kan misslaan. Bijvoorbeeld door non-repeateable reads, dit doet zich voor wanneer een transactie dezelfde data meerdere keren leest en daarbij verschillende resultaten ontvangt, doordat een andere transactie in de tussentijd de data heeft gewijzigd en gecommit.
Als we naar het voorbeeld van Jolien kijken. Stel dat ze een verslag wil uittrekken van haar jaaroverzicht en ze wil het totale bedrag op haar rekening en de interest (2%) die ze krijgt op haar totale bedrag, samen met nog andere statistieken. Stel nu dat ze haar totale bedrag van €120 krijgt te zien als totale bedrag, maar net voordat de interest berekend wordt wordt er een andere transactie uitgevoerd die €20 wegneemt van haar totale bedrag. Dan krijgt Jolien een verslag waar op staat: Totale bedrag = €120, interest = €2. Wees maar zeker dat Jolien een kwade email zal sturen!
Het probleem hier is dat alles wat voor het verslag opgehaald moet worden consistent moet blijven voor dat hele verslag, er mogen tegelijk dus geen andere transacties updates doorvoeren.
| time | T1 (Verslag maken) | T2 (20 euro wegnemen) | bedrag |
|---|---|---|---|
| 1 | begin trans | 120 | |
| 2 | read(bedrag): 120 [om totaal bedrag te weten] | begin trans | 120 |
| 3 | … | bedrag = bedrag - 10 | 120 |
| 4 | … | write(bedrag) | 100 |
| 5 | read(bedrag): 100 [om interest te berekenen, oeps] | commit | 100 |
| 6 | commit | 100 |
Phantom read
Of wat dacht je van phantom reads: dit treedt op wanneer een transactie herhaaldelijk dezelfde query uitvoert en bij de tweede uitvoering extra records ziet (of juist records mist) die door een andere transactie zijn toegevoegd of verwijderd en al gecommit. Bijvoorbeeld: transactie T2 is bezig met rijen effectief te verwijderen, terwijl T1 deze toch nog inleest. Het zou kunnen dat hierdoor verschillende rijen ontstaan (T2 rollback, T1 die een nieuwe rij maakt), of dat voorgaande bestaande rijen verdwijnen door T2, waardoor de transactie van T1 mogelijks faalt.
Weer teruggrijpende naar ons Jolien voorbeeld, stel dat Jens Jolien €5 wilt betalen per klusje dat ze gedaan heeft. Klusjes worden opgeslagen in een aparte tabel, maar ondertussen kan Jolien een nieuw klusje afvinken, waardoor Jens’ transactie een phantom read krijgt:
| time | T1 (Jens) | T2 (Jolien) | klusjes |
|---|---|---|---|
| 1 | read 1: SELECT * FROM klusjes WHERE naam = 'Jolien' (2) | 2 | |
| 2 | … | 2 | |
| 3 | … | INSERT INTO klusjes ... | 3 |
| 4 | … | 3 | |
| 5 | read 2: SELECT * FROM klusjes WHERE naam = 'Jolien' (3, oeps) | 3 | |
| 6 | sort 3x5 op rekening (teveel) | 3 | |
| 7 | commit |
Bijgevolg verkrijgt T1 inconsistente data: de ene keer 2, de andere keer 3—vergeet niet dat het goed zou kunnen dat T2 nog teruggedraaid wordt.
Wat is het verschil tussen een non-repeatable read, een phantom read, en een dirty read? Dirty reads lezen foutieve uncommitted data van een andere transactie—het lezen van ‘in progress’ data. Non-repeateable reads en phantom reads lezen foutieve committed data van een andere transactie. Bij non-repeatable reads gaat het over UPDATEs, en bij phantom reads over INSERTs en/of DELETEs: rijen die plots verschijnen of zijn verdwenen sinds de transactie begon.
Meerdere fouten tegelijk
Bijvoorbeeld bij inconsistente analyse tussen twee transacties gaat het over een sequentie van verschillende dirty reads die de situatie alleen maar verergeren, zelfs zonder de eventuele rollback. Stel dat het over te schrijven bedrag in stukjes van €2 wordt overgeschreven, waarbij telkens tussenin een read(bedrag) plaats vindt—die natuurlijk de data van de andere transactie inleest. Het resultaat is, opnieuw, een veel te grote som, en een mogelijks erg blije Jolien.
We laten een schematische voorstelling van dit probleem als oefening voor de student.
Scheduler oplossingen
Wat is de simpelste manier om bovenstaande problemen allemaal integraal te vermijden? Juist ja—sequentieel transacties verwerken.
Serial scheduling
Met serial scheduling is T2 verplicht te wachten op T1 totdat die zijn zaakje op orde heeft. De lost update transactie flow van hierboven ziet er dan als volgt uit:
| time | T1 (Marianne) | T2 (Jens) | bedrag |
|---|---|---|---|
| 1 | begin trans | 100 | |
| 2 | read(bedrag): 100 | 100 | |
| 3 | bedrag = bedrag + 10 | 100 | |
| 4 | write(bedrag) | 110 | |
| 5 | commit | 110 | |
| 6 | begin trans | 110 | |
| 7 | read(bedrag): 110 | 110 | |
| 8 | bedrag = bedrag + 10 | 120 | |
| 9 | write(bedrag) | 120 | |
| 10 | commit | 120 |
Wat valt je op als je naar de time kolom kijkt? Serial scheduling duurt nu 10 ticks t.o.v. 6 bij de potentiële lost update—da’s een redelijk grote performance hit van 40%! Serial scheduling lost misschien wel alles op, maar daardoor verliezen we alle kracht van het woord parallel: dit is in essentie non-concurrency.
Wat zijn dan betere scheduling alternatieven?
Optimistic scheduling
Bij “optimistic” scheduling gaan we ervan uit dat conflicten tussen simultane transacties nauwelijks voorkomen. Met andere woorden, we benaderen het probleem (misschien te) optimistisch. Transacties mogen gerust tegelijkertijd lopen als ze bijvoorbeeld verschillende tabellen of stukken data in dezelfde tabel bewerken—zolang er geen conflict is, geniet paralellisatie de voorkeur.
Bij optimistische schedulers worden alle transactie operaties doorgevoerd. Wanneer deze klaar zijn voor een eventuele COMMIT, wordt er gecontroleerd op potentiële conflicten. Indien geen, success. Indien wel, abort en ROLLBACK.
Merk op dat rollback operaties erg dure operaties zijn: de manager moet graven in de logfile, moet beslissen of er UNDO/REDO operaties moeten worden uitgevoerd, er is mogelijke trage disc access (I/O), … Als je vaak rollbacks hebt/verwacht is optimistic scheduling nog steeds geen performant alternatief.
Pessimistic scheduling
Bij “pessimistic” scheduling gaan we van het omgekeerde uit: transacties gaan heel zeker conflicteren. De scheduler probeert transactie executies te verlaten om dit zo veel mogelijk te vermijden. Een serial scheduler is een extreem geval van een pessimistic scheduler.
Locking
In de praktijk wordt locking gebruikt op een pre-emptive manier (zie besturingssystemen: scheduling algorithms) om toch transacties waar mogelijk concurrent te laten doorlopen. Bij transacties die schrijven in plaats van die enkel lezen zullen locks eerder nodig zijn. Er bestaan uiteraard erg veel verschillende locking technieken/algoritmes.
We maken onderscheid tussen twee groepen:
- exclusive locks: als
T1een exclusieve lock neemt, kan er geen enkele andere transactie op die database worden uitgevoerd. Dit is een erg strict systeem, denk aan serial scheduling. - shared locks: zolang
T1een lock neemt op een object (zie onder), krijgt het de garantie dat geen enkele andere transactie dat object kan manipuleren totdat de lock terug wordt vrijgegeven (eventueel ook door middel van een rollback). Locks worden “gedeeld”:T1krijgt write access, enT2moet wachten met schrijven, maar mag wel lezen.
De database “objecten” waar een lock op genomen kan worden zijn onder andere (van kleine locks naar groot):
- row locks;
- column locks;
- page locks (delen van een tabel zoals stored in files);
- table locks;
- databas locks (bvb een file lock in SQLite);
Volgorde hierboven gaat ongeveer van minder wachttijd (1) naar meer wachttijd (2)
Een lock op één rij in beslag genomen door T1 betekent dat voor diezelfde tabel T2 nog steeds bedragen kunnen wijzigen van een andere rekening. Column locks kunnen tot meer wachttijd leiden. Page locks zijn “stukken” van een tabel (rijen voor x en erna). Een page is een chunk van een tabel die op die manier wordt opgeslaan. Dit verschilt van DB implementatie tot implementatie. Tenslotte kan een hele tabel gelockt worden—of de hele tablespace—wat meer pessimistisch dan optimistisch is.
Locks zijn onderhevig aan dezelfde nadelen als rollbacks: ze zijn duur. Als er erg veel row locks zijn op een bepaalde tabel kan dit veel CPU/RAM in beslag nemen. In dat geval kan de lock manager beslissen om aan lock escalation te doen: de 100 row locks worden één page of table lock. Dit vermindert resource gebruik drastisch—maar zou transacties ook langer kunnen laten wachten. You win some, you lose some…
Problemen bij oplossen van problemen: deadlocks
Stel dat Jens cash geld wilt deponeren, en Marianne hem ook geld wenst over te schrijven. Voordat Marianne dat doet koopt ze eerst nog een cinema ticket. Jens wil ook een ticket in dezelfde transactie. Het gevolg is dat T1 en T2 oneindig op elkaar blijven wachten. Dat ziet er zo uit:
De kruisende pijlen duiden al op een conflict:
| time | T1 (Jens) | T2 (Marianne) |
|---|---|---|
| 1 | begin tarns | |
| 2 | begin tarns | |
| 3 | update rekening (acquire lock R) | |
| 4 | update cinema (acquire lock C) | |
| 5 | poging tot update cinema (WACHT) | |
| 6 | poging tot update rekening (WACHT) |
Deze (simpele) deadlock kan gelukkig gedetecteerd worden door het DBMS systeem. Die zal één van beide transacties als “slachtoffer” kiezen en die transactie terugdraaien—meestal gebaseerd op welke het makkelijkste is om terug te draaien. Het probleem is dat de meeste applicaties niet onmiddellijk voorzien zijn op zo’n onverwachte rollback. Dit resulteert meestal in een negatieve gebruikerservaring.
Deadlocks en algoritmes om dit te detecteren en op te lossen zijn erg complexe materie. Het volstaat om bovenstaand eenvoudig voorbeeld te kennen, en te weten hoe dat aangepakt zou kunnen worden—bijvoorbeeld met:
- starvation: een transactie voortdurend als slachtoffer kiezen met als risico dat deze nooit de kans krijgt om succesvol af te ronden. In dit geval wordt de transactie steeds teruggedraaid terwijl andere transacties wel kunnen doorgaan, wat resulteert in oneerlijke behandeling en voortdurende vertraging van de starvende transactie.
- timeouts: een mechanisme om vastgelopen transacties op te sporen en af te breken. Wanneer een transactie langer dan een vooraf ingestelde tijd op een resource wacht, wordt deze afgebroken (rollback) om te voorkomen dat de deadlock het systeem blijft blokkeren.
- priority shift: een strategie waarbij de prioriteit van een transactie dynamisch wordt aangepast om deadlocks te helpen voorkomen of op te lossen. In plaats van dat een transactie telkens wordt gekozen als slachtoffer en teruggedraaid (wat kan leiden tot starvation), wordt de prioriteit verhoogd zodat deze transactie eerder de benodigde resources krijgt om haar bewerkingen af te ronden. Dit mechanisme zorgt ervoor dat starvende transacties uiteindelijk kunnen doorstromen en dat het systeem efficiënter functioneert bij het oplossen van conflicten.
Deze concepten komen ook terug in schedulers voor besturingssystemen en zie ook A beginners guide to DB deadlocks.
Isolation levels
Pessimistic locking kan veel problemen opvangen, maar ten koste van performantie—wat meestal belangrijker is. Voor veel transacties is het oké om met een minimum aan conflicten de throughput van transacties zo hoog mogelijk te houden. De meeste DBMS systemen zijn hier flexibel in: je kan wat we noemen isolation levels instellen, dat meestal bestaat uit de volgende vier opties (van low naar high isolation):
- Read uncommited—Dit laat toe om “uncommited” data te lezen (dat problemen geeft, zie boven), en wordt meestal gebruikt in combinatie met read-only transacties.
- Read committed—Gebruikt short-term read locks en long-term write locks, en lost zo het inconsistent analysis/dirty reads probleem op, maar is niet krachtig genoeg om phantom reads tegen te houden.
- Repeatable read—Gebruikt long-term read & write locks. Een transactie kan zo dezelfde rij verschillende keren opnieuw lezen zonder conflicten van insert/updates van andere transacties. Het phantom read probleem is echter nog steeds niet opgelost.
- Serializable—het krachtigste isolation level dat in theorie aansluit met serial scheduling.
Een short-term lock wordt enkel vastgehouden gedurende het interval dat nodig is om een operatie af te ronden, terwijl long-term locks een protocol volgen en meestal tot de transactie commited/rollbacked is, vastgelegd zijn.
Volgende tabel geeft een overzicht over wat elk Isolation level weer juist doet en welke read phenomena dit voorkomt. In de tabel gaat de snelheid omlaag hoe lager je gaat, maar stijgt wel de veiligheid!
| Isolation level | Dirty reads | Lost updates | Non-repeatable reads | Phantoms |
|---|---|---|---|---|
| Read Uncommitted No Isolation, any change from the outside is visible to the transaction | may occur | may occur | may occur | may occur |
| Read Committed Each query in a transaction only sees committed stuff | don't occur | may occur | may occur | may occur |
| Repeatable Read Each query in a transaction only sees committed updates at the beginning of transaction | don't occur | don't occur | don't occur | may occur |
| Serializable Transactions are serialized | don't occur | don't occur | don't occur | don't occur |
Merk op dat voor elke database implementatie de selectie van een isolation level andere gevolgen kan hebben! Zie de tabellen in https://github.com/changemyminds/Transaction-Isolation-Level-Issue. Het is dus van belang de documentatie van je DB te raadplegen, zoals deze van Oracle, waarin de volgende beschrijving staat voor TRANSACTION_SERIALIZABLE: “Dirty reads, non-repeatable reads and phantom reads are prevented.”.
We komen hier nog later op terug in concurrency in practice wanneer we bijvoorbeeld bij JPA of Hibernate aangeven welk isolation level gewenst is.
Pessimistic Scheduling VS Isolation Levels:
- Pessimistic Scheduling is een concrete strategie waarbij resources proactief worden vergrendeld om conflicten te vermijden.
- Isolation Levels bepalen via configuratie-instellingen in welke mate transacties elkaars wijzigingen mogen zien en welke anomalieën geaccepteerd worden.
Oefeningen
Geef voor onderstaande situaties welk read phenomena optreed. Geef ook twee mogelijke oplossingen waarmee je dit probleem kan oplossen en hoe die twee oplossingen van elkaar verschillen.
Oefening 1:
In deze oefening wordt door transactie TX2 de quantity van product 1 aangepast van 10 naar 15 en transactie TX1 wil enerzijds de inkomsten berekenen op elk product apart maar ook in het totaal.

Solution:
- read phenomena = Non-repeatable read. De quantity van product 1 wordt door eenzelfde transactie twee keer uitgelezen maar krijgt hier 2 verschillende waarden voor.
- oplossing: Twee mogelijke oplossingen hiervoor zijn de Repeatable Read en Serializable isolation levels.
- Bij Repeatable Read wordt ervoor gezorgd dat als een transactie een rij leest, geen andere transactie die rij kan wijzigen totdat de eerste transactie is voltooid. Dit voorkomt dat de waarde verandert tussen opeenvolgende leesoperaties binnen dezelfde transactie.
- Bij Serializable wordt een nog striktere controle toegepast, waarbij transacties volledig geïsoleerd worden uitgevoerd alsof ze sequentieel plaatsvinden, wat niet alleen non-repeatable reads voorkomt, maar ook andere problemen zoals phantom reads.
- Het belangrijkste verschil is dat Serializable een hogere mate van isolatie biedt, wat leidt tot betere gegevensintegriteit, maar mogelijk ook tot lagere prestaties door verhoogde kans op blocking en wachttijden.
Oefening 2:
In deze oefening wordt door transactie TX2 een product toegevoegd aan de SALES tabel en transactie TX1 wil enerzijds de inkomsten berekenen op elk product apart maar ook in het totaal.
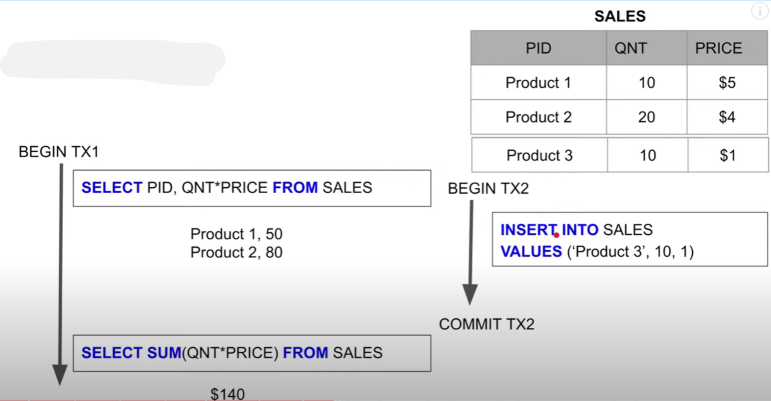
Solution:
- read phenomena = Phantom read. Het aantal producten waarvan de inkomsten worden berekend apart wordt uitgevoerd en daarna wordt de totaal inkomsten berekend op alle producten maar hiertussen is een extra product toegevoegd waardoor de waarden nu niet meer overeenkomen wat zou moeten aangezien de aparte inkomsten en totale inkomsten in 1 transactie berekend werden. (Waarom gebruik je nu niet gewoon de eerder berekende inkomsten om de totale inkomsten te berekenen. Als je aparte functies in je applicatie hebt geschreven om de aparte inkomsten en totale inkomsten queries uit te voeren zou dit voor meer werk zorgen als je nog een 3e functie moet schrijven die de totale inkomsten berekend op basis van de aparte queries. Dit is zot en moet het DBMS voor ons oplossen en moeten wij ons zo weinig mogelijk mee bezig houden bij het schrijven van onze applicatie: scheiding van verantwoordelijkheden)
- oplossing: Twee mogelijke oplossingen hiervoor zijn het gebruik van het Serializable isolatieniveau en het toepassen van range locks:
- Bij Serializable wordt strikte controle toegepast, waarbij transacties volledig geïsoleerd worden uitgevoerd alsof ze sequentieel plaatsvinden, wat non-repeatable reads voorkomt.
- Range locks daarentegen vergrendelen expliciet een specifiek bereik van rijen (bijv.
WHERE id > 100), waardoor concurrente transacties worden geblokkeerd om binnen dat bereik in te voegen of te wijzigen, maar dit vereist handmatige implementatie en kan deadlocks bevorderen als niet nauwkeurig afgestemd. - Het verschil ligt in de automatische vs. handmatige scope-beheersing en de balans tussen databasebrede consistentie (Serializable) versus gerichte controle (range locks) met bijbehorende prestatieafwegingen zoals throughput (het minste met Serializable).
Oefening 3:
In deze oefening wordt door transactie TX2 de quantity van product 1 aangepast van 10 naar 15 en transactie TX1 wil enerzijds de inkomsten berekenen op elk product apart maar ook in het totaal.
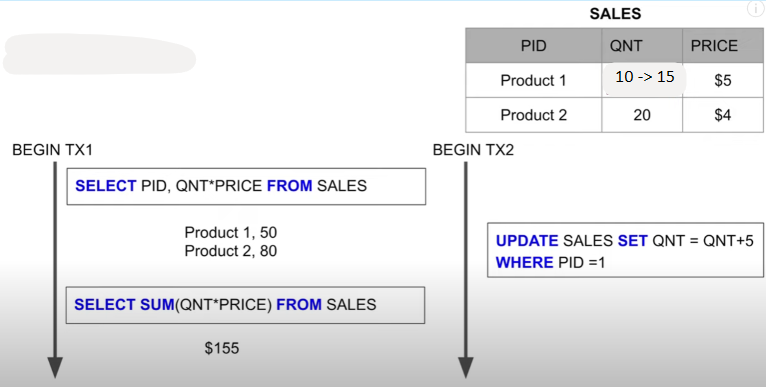
Solution:
- read phenomena = Dirty read. De quantity van product 1 wordt geupdate tijdens transactie 1 maar is nog niet gecommit. De berekening van de totale inkomsten kan dus fout zijn in het geval dat
TX2wordtgererolled. - oplossing: Twee mogelijke oplossingen hiervoor zijn de Read Committed en Repeatable Read isolation levels.
- Bij Read Committed worden dirty reads voorkomen door alleen gelezen data toe te staan die al is gecommit, wat automatisch werkt en transacties beperkt tot het lezen van stabiele gegevens, maar geen bescherming biedt tegen non-repeatable reads of phantom reads.
- Bij Repeatable Read wordt ervoor gezorgd dat als een transactie een rij leest, geen andere transactie die rij kan wijzigen totdat de eerste transactie is voltooid. Dit voorkomt dat een waarde wordt uitgelezen van een andere transactie die misschien gerollebacked wordt, aangezien die transactie moet wachten tot de eerste klaar is.
- Het belangrijkste verschil is dat Repeatable Read een hogere mate van isolatie biedt, wat leidt tot betere gegevensintegriteit, maar mogelijk ook tot lagere prestaties door verhoogde kans op blocking en wachttijden.
Denkvragen
Waarom is het phantom read probleem niet opgelost bij isolation level 3 (repeatable read)?
Solution:
- Hoewel het voorkomt dat rijen worden gewijzigd of verwijderd, staat het nog steeds toe dat nieuwe rijen worden toegevoegd die voldoen aan de zoekcriteria van een query. Als gevolg hiervan kan een transactie die herhaaldelijk een query uitvoert, verschillende resultaten zien vanwege toegevoegde rijen tussen de verschillende uitvoeringen van de query. Dit is het “phantom read” probleem.
Hoe weet je wanneer je best optimistic vs pessimistic scheduling gebruikt?
Solution:
- Start optimistisch door te vertrouwen op lage conflicten en minimale locks, maar als je merkt dat er frequent errors (zoals rollbacks of conflicten) optreden die de prestatie of data-integriteit schaden, schakel dan over naar een pessimistische aanpak door vooraf locks te plaatsen om concurrentie te beheersen en betere voorspelbaarheid te garanderen. Deze verschuiving is logisch bij schrijf-zware workloads of kritieke systemen waar preventie van conflicten prioriteit heeft boven flexibiliteit. Is het cruciaal voor je programma echter dat data-integriteit niet geschaad mag worden dan kies je best initieel al voor een pessimistische aanpak.
Kan je nog andere situaties verzinnen waarin een deadlock kan voorkomen? Welk isolation level of scheduling algoritme lost dit op?
Solution:
- Stel, twee banktransacties gebeuren tegelijk:
- Transactie A wil €100 van rekening X naar Y overmaken (vergrendelt eerst X, dan Y).
- Transactie B wil €50 van Y naar X overmaken (vergrendelt eerst Y, dan X).
- Als beide transacties hun eerste lock hebben maar wachten op de tweede, ontstaat een deadlock: beide kunnen niet verder.
- Om deadlocks op te lossen, kunnen verschillende isolation levels en scheduling-algoritmen worden gebruikt zoals “Serializable”. Dit kan deadlocks helpen voorkomen door transacties te dwingen in een serialiseerbare volgorde te worden uitgevoerd, waarbij conflicten worden voorkomen en de kans op deadlocks wordt verminderd. Het nadeel is natuurlijk performantie.
- Algemeen: Deadlocks los je op met preventie (voorkom inconsistente lock-volgordes via isolation levels) of detectie (forceer een rollback op basis van time-outs).
- Stel, twee banktransacties gebeuren tegelijk:
Wat is de verantwoordelijkheid van de DBMS’s transactie management systeem in verhouding tot de ACID eigenschappen?
Solution:
- Door het implementeren van transactiemanagementfunctionaliteiten zoals concurrency control, logging en herstelmechanismen, zorgt het systeem ervoor dat transacties consistent, geïsoleerd en duurzaam worden uitgevoerd, waardoor de betrouwbaarheid en integriteit van de database worden gewaarborgd.
- Atomicity en Durability: Transaction logs, herstelprocedures na crashes.
- Isolation: Pessimistische locks (bijv.
SELECT FOR UPDATE), Isolation levels. - (Consistency: Constraints (
UNIQUE,FOREIGN KEY), triggers.)
- Door het implementeren van transactiemanagementfunctionaliteiten zoals concurrency control, logging en herstelmechanismen, zorgt het systeem ervoor dat transacties consistent, geïsoleerd en duurzaam worden uitgevoerd, waardoor de betrouwbaarheid en integriteit van de database worden gewaarborgd.
Welke impact heeft lock granulariteit op transactie throughput?
Solution:
- Throughput is afhankelijk van het type fouten dat je gaat tegenkomen VS de isolation levels die rollbacks preventen maar ook wel traag kunnen zijn.
- Je moet dus steeds proberen de beste keuze te maken voor jouw specifieke geval.
Bedenk en teken zelf een situatie waar een
Lost Updatevoorkomt.