Het schaalbaarheid probleem
Het probleem met RDMS (relationele database management systems) is vaak schaalbaarheid. Gezien de ACID data validity voorwaarden is altijd de vraag: is dit schaalbaar?
Optie 1: Vertical scaling
De makkelijke oplossing is “scaling up”: meer storage, CPU, RAM, … voorzien zodat er meer cycles kunnen benut worden en hopelijk ook meer transacties concurrent kunnen worden verwerkt (zie transacties basics).

Je botst hier echter snel op hardware limitaties—niet alles is opgelost met een latje RAM.
Optie 2: Horizontal scaling
In plaats van “omhoog” te gaan en meer hardware in hetzelfde systeem te steken, kunnen we ook meer hardware op verschillende plaatsen in het netwerk zetten: scaling out in clusters. Dit noemen we horizontaal scalen: meer kleintjes die gedistribueerd hetzelfde doen.

Deze oplossing introduceert echter een ander probleem: data consistency is niet altijd gegarandeerd. Als ik iets in één server van een cluster bewaar, wordt dit dan onmiddellijk in de andere ook bewaard? Wat als er eentje uitvalt, en dat net mijn access point was? Op welke manier wordt die data verdeeld binnen de cluster? Enzovoort. Distributed computing is een erg complex domein binnen de informatica. We raken in dit vak enkel de top van de ijsberg aan.
Wat is een “cluster” precies?
Denk aan een verzameling van grote data centers: twee of meer fysieke centra waar enorm veel servers geplaatst worden. Eén server kan je eigen laptop zijn. Je kan ook verschillende virtuele servers op je laptop draaien: dat is een node. (We hanteren hier de hierarchie van elementen volgens Cassandara)
Cluster « Data Center « Rack « Server « Node
Een typische relationele database, met zijn ACID eigenschappen, maakt horizontaal schalen dus moeilijk. Consistentie en availability maakt partitioning tot een uitdaging. Dit is ook zichtbaar in het CAP probleem; of “Consistency, Availability, Partitioning Tolerance” probleem. Wil je inzetten op partitioning, dan is de kans groot dat je zal moeten inboeten op consistency en availability. De volgende figuur illustreert dit probleem:

Flexibiliteit van horizontal scaling krijgen we door af te stappen van een typische RDBMS, en te kijken naar wat er kan als de R (relational) wegvalt—ofwel noSQL databases. De populariteit hiervan groeide exponentieel sinds scalability een groter probleem werd: denk aan gigantische data warehouses van Amazon, Google’s zoek engine, Facebook pagina’s, enzovoort. NoSQL systemen garanderen ook consistentie—alleen niet onmiddellijk: dit heet eventual consistency.
Dus, horizontal scaling is eenvoudiger met NoSQL:
- Er is géén relationele data;
- Er is géén (onmiddellijke) consistentie—dus ook geen coordinatie overhead!;
- Dit is zeer goed scalable.
NoSQL basics
Een vergelijking van eigenschappen tussen een relationele en niet-relationele database systeem:
| Eigenschap | Relationeel | NoSQL |
|---|---|---|
| Data paradigma | relationeel | 4 types: key/val, docs, … (s3.2) |
| Distributie | Single-node | Distributed |
| Scalability | Vertical | Horizontal, replication |
| Structuur | Schema-based | Flexible |
| Querty taal | SQL | Specialized (JavaScript) |
| Transacties | ACID | BASE |
| Features | views/procs/… | basic API |
| Data vol. | “normal” | “huge amounts” |
*BASE staat voor Basically Available, Soft state, Eventual concistency
Merk op dat het niet altijd de beste oplossing is om naar een NoSQL DB te grijpen. Wanneer dan wel of niet? De volgende vragen kunnen hierbij helpen:
- Bevat data veel/weinig relaties?
- Komt er enorm veel data/sec. binnen?
- Replication vereisten?
- Scripting mogelijkheden?
- Bestaande kennis in bedrijf?
- …
Klassieke relationele databases zijn nog steeds een van de meestgebruikte ter wereld, maar dat wil niet zeggen dat er geen (populaire) alternatieven zijn. Kijk eens naar de db-engines.com ranking trends op db-engines.com:
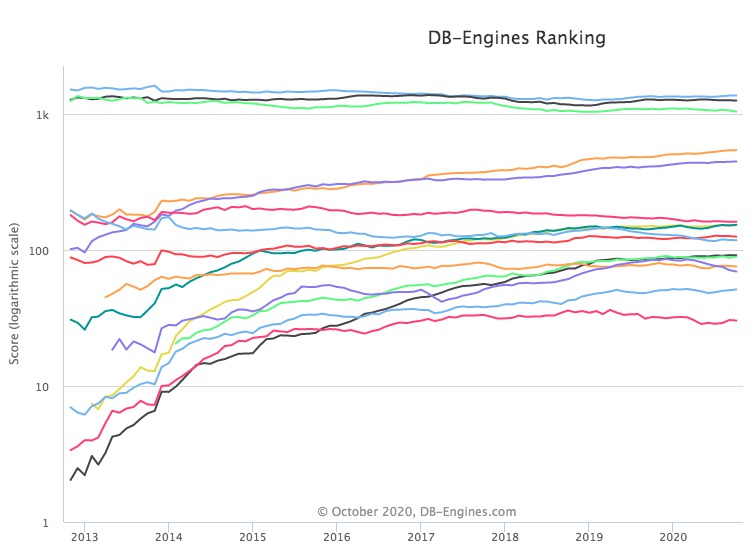
De drie bovenste lijnen zijn Oracle, MySQL en Microsoft SQL Server, de drie giganten die alledrie relationele DBMS systemen zijn. PostgresQL, de oranje stijgende lijn, is volgende—ook SQL. Maar daarnaast volgen MongoDB, Cassandra, Redis, DynamoDB, …—allemaal verschillende soorten noSQL alternatieven.
NoSQL Types

Er zijn, zoals bovenstaande figuur aangeeft, 4 grote groepen van NoSQL systemen:
1. Document stores.
Hier bewaar je een “document” in, dat meestal in JSON-formaat is, zoals:
{
"bedrag": 100.3,
"gebruiker": "Jos Klakmans",
"Stad": "Diepenbeek",
"certificaten": [{
"type": 1,
"naam": "Master in de bliebloe"
}, {
"type": 2,
"naam": "Bachelor in de blakkiela"
}]
}
Merk op dat hier geen relaties worden gelegd, alhoewel dat wel kan: bijvoorbeeld document 1 kan een property { id: 1 } hebben, en document 2 { id: 2, relatedDocumentId: 1 }. Dit echter veel gebruiken zal een performance hit geven: document stores dienen voornamelijk om gigantisch veel onafhankelijke data te bewaren, op een ongestructureerde manier. Er zijn geen table definities: een key meer of minder maakt niet uit.
NoSQL: { name: 'Jos' } -> { name: 'Jos', well-behaved: true }. Geen INSERT INTO student(name) VALUES ("Jos") dus! Ook hier wordt intern hashing gebruikt (zie onder): Het document { name: 'Jos' } wordt intern opgeslaan als { name: 'Jos', _id: 23235435 }. Data retrieval snelheid blijft belangrijk, dus extra indexen/views kunnen door de gebruiker zelf worden aangemaakt (zie volgende hoofdstukken).
Om documenten te ordenen worden soms wel collecties aangemaakt, maar dit is bijna altijd optioneel!
We zullen ons in deze cursus focussen op document stores. Zie NoSQL - document stores om een idee te hebben hoe dit in de praktijk gebruikt wordt.
2. Graph-based oplossingen.
Wat als we toch veel relationele gegevens hebben, maar het nog steeds over (1) ongestructureerde data gaat en (2) te veel is voor in één klassiek RDBMS systeem te bewaren? Als de relaties de data zelf zijn, dan hebben we een grafen-gebaseerde oplossing nodig. Hier zijn géén dure JOIN statements nodig om de relaties ad-hoc te maken. Een typische toepassing hiervan zou social graphs zijn.

Stel dat je alle boeken wilt ophalen geschreven door een bepaalde auteur (= de relatie). In SQL, waar de data typisch in twee tabellen leeft (book en author), heb je een (impliciete) JOIN nodig:
SELECT book, title FROM book, author, books_authors
WHERE author.id = books_authors.author_id
AND book.id = books_authors.book_id
AND author.name = "De Jos"
Maar in Cypher, de querytaal van grafendatabase Neo4J, ziet die query er als volgt uit:
MATCH (b:Book) <- [ :WRITTEN_BY]-(a:Author)
WHERE a.name = "De Jos"
RETURN b.title
Data wordt op basis van WRITTEN_BY relatie eigenschap opgehaald. Relationele data—de letterlijke relaties—zijn hier altijd expliciet, en niet verborgen in foreign key constraints.
3. Key-Value stores.
Dit is de eenvoudigste soort, waarbij gewoon blobs van data in een hash table opgeslagen worden, zoals jullie gewoon zijn in Java:
Map<String, Persoon> leeftijden = new HashMap<>();
leeftijden.put("Wilfried", new Persoon("Wilfried", 20));
leeftijden.put("Seppe", new Persoon("Seppe", 30));
leeftijden.put("Bart", new Persoon("Bart", 40));
leeftijden.put("Jeanne", new Persoon("Jeanne", 18));
Hash functies
In dit voorbeeld stopt de HashMap met bestaan zodra die out of scope gaat op je eigen machine, maar er zijn ook distributed hash tables. Hier is de hash functie het belangrijkste onderdeel, die de onderliggende key genereerd en dus bepaald in welke “bucket” een waarde wordt opgeslagen—en dus ook, op welke server in een cluster. Een goede hash functie moet (1) deterministisch zijn: atlijd dezelfde hash waarde voor dezelfe input genereren; (2) uniform zijn: er moet een goede verdeling zijn van de output range; en (3) een vaste grootte hebben zodat het makkelijker is voor de data structuur om de hash waarde te bewaren.
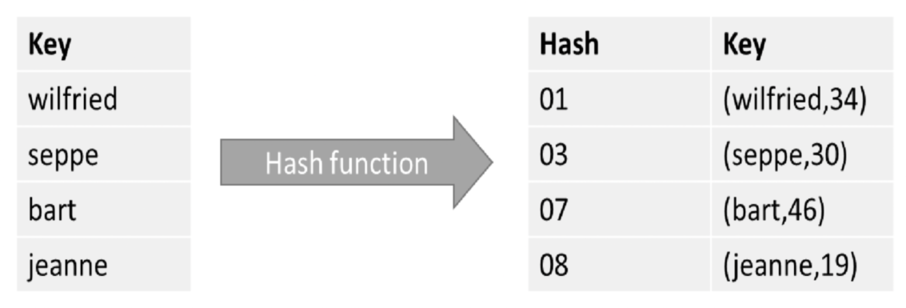
Vrijwel alle NoSQL databases gebruiken achterliggend hashing technieken om horizontal scalability makkelijker te maken. Als alle hash values mooi verdeeld worden, kan dit ook mooi over verschillende databases verdeeld worden.
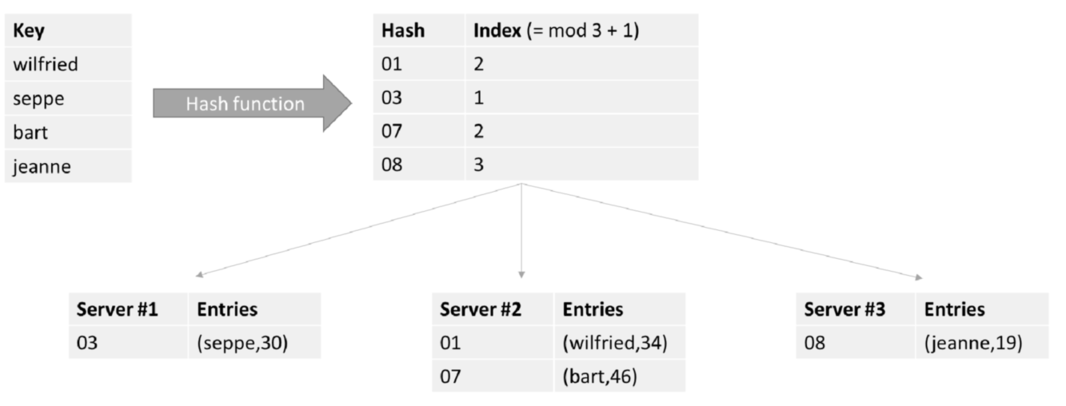
Partioning/sharding
In bovenstaand voorbeeld worden de persoonsgegevens verspreid over 3 verschillende servers door de hashing “index” (mod3 + 1). Data partitioning noemen we ook wel sharding waarbij een individuele partitie een shard is. Om zo efficient mogelijk te partitioneren schakel je best servers aan elkaar in een soort van “ring”, zoals in dit schema:
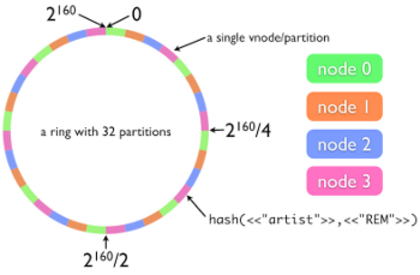
Ring partitioning vereist wel consistent hashing functies, anders klopt de node verdeling (de kleuren in het schema) niet meer. Om zo effient mogelijk data door te geven (replication, zie later NoSQL: replication) hebben nodes weet van elkaar. Het is echter nog steeds niet mogelijk om de ACID regels te volgen: een gedistribueerd systeem zoals deze ring kan nooit én consistent én available én partition tolerant zijn.
Wat is dan een oplossing voor NoSQL systemen? BASE in plaats van ACID:
- Basically Available (BA); elke (gebruikelijk HTTP-based) request ontvangt een respons, hetzij een
200(OK), hetzij een4xx/5xx(een externe/interne fout). Ook al zijn niet alle nodes geupdate, toch kan er al een201worden teruggegeven—asynchroon dus. - Soft state (S); sate kan wijzigen, ook zonder input! We weten dus nooit exact wat er in de shards zit. Read requests zijn soms out-of-date omdat een shard update in de ring partitie plaats aan het vinden was, maar dat één bepaalde shard nog niet bereikte…
- Eventually Consistent (E); NoSQL biedt de “ooit is het wel consistent” mode aan.
In de praktijk verschilt het van NoSQL database tot database systeem hoe dicht deze BASE regels tegen de ACID regels aanleunen. De document-based CouchDB, die we later zullen in detail bekijken, ondersteunt ook vormen van transacties en dergelijke, wat het eerder iets ACID-achtig maakt.
Memcached
Memcached is een distributed in-memory key/value store die op grote schaal gebruikt kan worden als caching mechanisme. Systemen als Memcached zijn enorm performant en worden vaak gebruikt als caching database die geplaatst wordt voor de eigenlijke RDBMS:
Het feit dat Netflix Memcached sponsort zegt genoeg. Memcached gebruiken is erg eenvoudig en gewoon een kwestie van de API in Java/Kotlin aan te spreken om data te feeden/op te halen.
Een simpel Memcached voorbeeld is terug te vinden onder key-value stores: memcached.
4. Wide-column databases.
Wide-column, of column-based databases, zijn eigenlijk relationele databases op zijn kop—letterlijk.
Wat is het grootste nadeel van het queryen van relationele databases? Deze zijn row-based: als je alle genres uit een BOEK tabel wilt halen, zal je alle rijen moeten afgaan en daar een DISTINCT op doen—alles behalve performant. Bijvoorbeeld:
id genre title price
1 Fantasy book bla 10
2 Fantasy another title 20
3 horror wow-book 10
Hoe haal ik hier alle genres op? SELECT DISTINCT(genre) FROM boeken. Wat is de gemiddelde prijs? SELECT AVG(price) FROM boeken—ook een erg dure operatie indien er miljoenen records aanwezig zijn. Een snelheidswinst valt te boeken door te werken met indexen, maar daar lossen we niet alles mee op.
Wat nu als je de kolommen als rijen beschouwt, op deze manier:
genre: fantasy:1,2 horror: 3
title: book bla:1, another title:2 wow-book: 3
price: 10:1,3 20:2
Wat is nu de gemiddelde prijs? Haal 1 “rij” op en deel door het aantal. Welke genres zijn er zoal? De eerste rij is al onmiddellijk het antwoord! We verzamelen hier dus vertical slices van data, wat erg belangrijk kan zijn voor Business Intelligence (BI): super-linked data tussen de “echte” row-based data.
De meest gebruikte column-DB is Cassandra. Op de website staat:
Manage massive amounts of data, fast, without losing sleep.
Cassandra komt met in-memory buffers, tracking & monitoring, …
ACID vs BASE
| Aspect | ACID (SQL) | BASE (NoSQL) |
|---|---|---|
| Consistentiemodel | Sterke consistentie (data is altijd correct en up-to-date) | Eventuele consistentie (data wordt uiteindelijk consistent) |
| Transactiefocus | Garandeert betrouwbaarheid (bv. banktransacties) | Prioriteit op beschikbaarheid en snelheid (bv. sociale media-platforms) |
| Gebruiksvoorbeelden | Financiële systemen, ERP, CRM | Big data, real-time analytics, IoT, schaalbare webapps |
| Schaalbaarheid | Verticaal schalen (krachtigere hardware) | Horizontaal schalen (meer servers toevoegen) |
| Datastructuur | Gestructureerd (tabellen met vaste schema’s) | On-gestructureerd/flexibel (documenten, key-value, grafieken, etc.) |
| Schema | Strict schema vooraf vereist | Schema-loos (flexibele data-modellering) |
| Complexe queries | Ondersteund via SQL (JOINs, aggregaties, etc.) | Beperkt, vaak afhankelijk van denormalisatie |
| Performantie | Lagere latentie voor complexe transacties | Hogere doorvoer voor grote datasets |
| Voorbeelden | MySQL, PostgreSQL, Oracle | MongoDB (document), Cassandra (wide-column), Redis (key-value) |
| Sterke punten | Data-integriteit, transactiegaranties, complexe relaties | Schaalbaarheid, flexibiliteit, hoge beschikbaarheid |
| Zwakke punten | Moeilijker horizontaal schalen, rigiditeit bij schemawijzigingen | Geen transactiegaranties, moeilijker voor relationele use cases |
Case Studies
Welke database systemen—of een combinatie ervan—denk je dat de volgende grote bedrijven hanteren voor hun producten?

- https://www.benl.ebay.be/
- Hint: https://www.slideshare.net/jaykumarpatel/cassandra-at-ebay-13920376 (2012)

- https://www.army.mil/
- Hint: https://go.neo4j.com/rs/710-RRC-335/images/Neo4j-case-study-US-army-EN-US.pdf (2019)

- https://spotify.com/
- Hint: https://engineering.atspotify.com/2015/01/09/personalization-at-spotify-using-cassandra/ (2015)

- https://uber.com/
- Hint: http://highscalability.com/blog/2016/9/28/how-uber-manages-a-million-writes-per-second-using-mesos-and.html (2016)
Denkvragen
- Is een RDBMS of een NoSQL database geschikter om aan “Big Data” te doen? Waarom wel/niet?
- Waarom vereist ring partitioning consistent hashing?
- Wat heeft een hashing functie te maken met het horizontaal kunnen schalen van data in een DBMS?
- Waarom gebruiken zo veel grote bedrijven een combinatie van verschillende DBMS systemen? Zie je hier ook nadelen in?
- Wanneer denk je dat een column-based database als Cassandra nuttig zou zijn?
- Leg het verschil tussen ACID en BASE uit in functie van de typische eigenschappen van een database.
- Waarom werkt vertical scaling niet? Waarom wel?